12 Synthetic Data
This chapter explains how synthetic data has moved from a curiosity to a cornerstone of modern post-training. As models improved from early RLHF-era systems to GPT-4-class capabilities, they became reliable enough to generate prompts, completions, preferences, and filters at scale—often surpassing human annotators for many instruction-following tasks. While concerns like model collapse exist, the chapter argues that diverse teachers, deduplication, quality filters, and mixing in human data keep training regimes healthy. The upshot is a broader “post-training” paradigm in which synthetic data accelerates iteration, expands coverage, and enables large, longer-response datasets (from Alpaca-scale to Tülu 3 and OpenThoughts 3) that power today’s top models, even as humans remain crucial for ground truth, capability frontiers, and evaluation design.
The chapter then surveys the main ways synthetic data is used. Distillation—training smaller models on outputs from stronger “teacher” models—serves both as a general data engine (for instructions, preferences, and verification) and for targeted skill transfer (e.g., math and code). AI feedback (RLAIF) leverages LLM-as-a-judge to generate scalable preference labels and evaluations at a fraction of human cost, with practical tradeoffs: human data is high-noise/low-bias, while synthetic preference data is low-noise/high-bias. In practice, hybrid pipelines route hard or sensitive cases to humans and rely on AI for volume. The chapter also discusses judge calibration, including inconsistencies and self-preference bias, and notes that while specialized critic or judge models exist, leading general models—combined with techniques like repeated sampling or tournament ranking—tend to suffice for most workflows.
Finally, the chapter details Constitutional AI and rubric-based rewards as influential frameworks for AI-generated supervision. Constitutional AI uses a written set of principles to guide synthetic critiques of instruction data and to produce principle-grounded preference pairs for RLHF, seeding much of today’s RLAIF practice. Rubrics extend this idea by turning task-specific criteria—hard rules and graded principles—into near-verifiable signals for RL, enabling meaningful gains in domains like scientific reasoning and factuality. Although these methods now underpin many state-of-the-art post-training pipelines, the chapter emphasizes that synthetic data complements rather than replaces human input: people remain essential for setting objectives, creating benchmarks, and handling the toughest, most novel problems, while synthetic pipelines provide scalable, fast, and increasingly reliable supervision everywhere else.
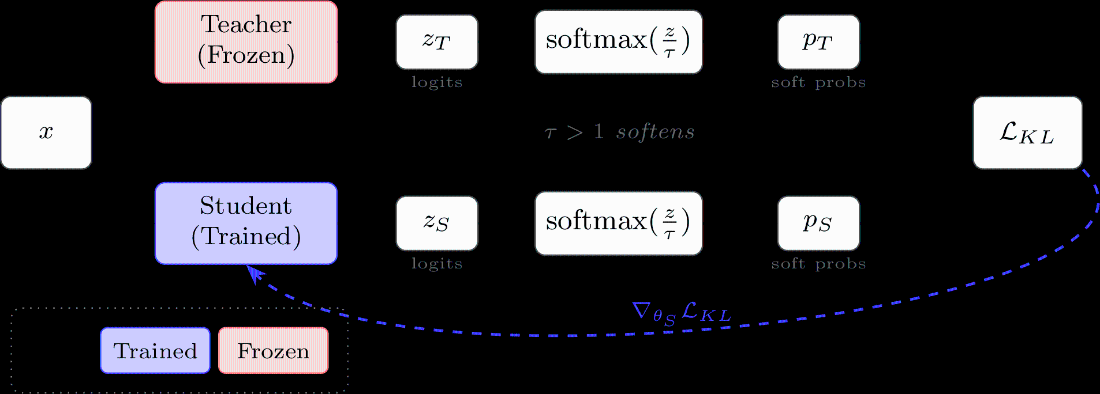
Traditional knowledge distillation trains a smaller student model to match the soft probability distribution of a larger teacher model using KL divergence loss. Both models process the same input simultaneously, and temperature scaling (\(\tau > 1\)) softens the distributions to reveal more information about class relationships.
Synthetic data generation in LLM post-training: prompts are passed through a strong model to generate completions, which are paired to create a training dataset. This dataset is then used to fine-tune smaller models via standard supervised learning. More complex pipelines may involve multiple models editing completions, generating preference pairs, or filtering for quality.

Summary
- Synthetic data has become essential to modern post-training – language models are used to generate training prompts, write completions, provide preference labels, and filter data at every stage of the pipeline.
- Distillation, using outputs from a stronger model to train a smaller one, is the most common form of synthetic data usage and has largely replaced human-written completions for instruction tuning, though human data remains important at capability frontiers and for establishing ground truth answers.
- AI feedback can approximate human preference labels at a fraction of the cost within the RLHF pipeline, denoted RLAIF. A useful rule of thumb: human data is high-noise and low-bias, while synthetic preference data is low-noise and high-bias – making AI feedback easier to start with but prone to systematic second-order effects.
- Constitutional AI (CAI) was the earliest large-scale use of synthetic data for RLHF, using a set of written principles to guide both instruction data revision and synthetic preference data generation.
- Rubric-based rewards extend RL training to domains without clearly verifiable answers by using LLM judges to score completions against per-prompt evaluation criteria, enabling RL-style training on tasks like scientific reasoning, creative writing, or model personality.
 The RLHF Book ebook for free
The RLHF Book ebook for free