10 The Nature of Preferences
Reinforcement learning from human feedback centers on modeling human preferences in domains where explicit reward design is hard. The chapter argues that “better” is often irreducibly subjective—illustrated by judging two poems—so human judgments are used as indirect reward signals to align models with what people tend to prefer. Because preferences are psychologically, socially, and philosophically complex, RLHF sits at the intersection of philosophy, psychology, economics and decision theory, optimal control and reinforcement learning, and modern deep learning. In practice, today’s systems prioritize empirical alignment on concrete tasks and style, while research continues on pluralistic alignment across populations and personalization to individuals.
Historically, RLHF draws on ideas that link preferences, rewards, and costs to a quantitative notion of utility under uncertainty. Modern reinforcement learning inherits tools from optimal control—Bellman equations, reward-to-go, discounting, and the Markov decision process—and from operant conditioning’s notion of reward as a signal of desirability. With temporal-difference learning and Q-learning, these methods achieved notable success in games and control. However, their guarantees assume stable, well-specified rewards and closed environments. When RLHF compresses diverse, multimodal human judgments into a single scalar reward model, it departs from those assumptions, and related strands like inverse reinforcement learning remain underused in large-scale language settings.
The chapter details why optimizing preferences is inherently harder than optimizing fixed rewards. Human preferences drift over time, depend on context and presentation, and are embedded in social relations. While the Von Neumann–Morgenstern utility theorem licenses utility-based modeling, its assumptions rarely hold cleanly in open-ended, partially observed language tasks; human-computer interaction shows interface framing can alter choices, and social choice theory proves no aggregation satisfies all fairness desiderata. Assumptions enabling interpersonal utility comparison invite principal–agent framings but create tensions with corrigibility. Practically, RLHF must contend with nontransitive or incomparable judgments, proxy feedback signals, choice-set and ordering effects, and low inter-rater agreement. The upshot is that RLHF will never be a fully solved problem; it is a useful approximation that demands careful dataset engineering, explicit acknowledgment of uncertainty and pluralism, and evaluation tailored to real-world use.
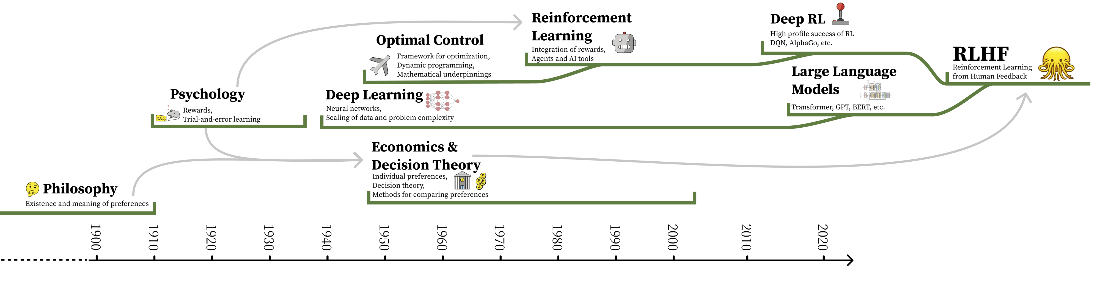
The timeline of the integration of various subfields into the modern version of RLHF. The direct links are continuous developments of specific technologies, and the arrows indicate motivations and conceptual links.
Summary
- RLHF sits at the intersection of philosophy, economics, psychology, reinforcement learning, and deep learning – each bringing its own assumptions about what preferences are and how they can be optimized.
- Reinforcement learning was designed for domains with stable, deterministic reward functions, but human preferences are noisy, context-dependent, temporally shifting, and not always transitive – a fundamental mismatch that shapes the limitations of RLHF.
- The Von Neumann-Morgenstern utility theorem provides theoretical license for modeling preferences as scalar functions, but its assumptions (transitivity, comparability, stability) are routinely violated in practice. Impossibility theorems in social choice theory further show that no single aggregation method over preferences can satisfy all fairness criteria simultaneously.
- These challenges explain why RLHF will never be fully “solved,” but they do not prevent it from being useful. In practice, RLHF operates on more tractable problems of style and performance rather than attempting to resolve the full complexity of human values.
- The practical mechanics of collecting and structuring preference data in light of RLHF’s complex motivations are covered in Chapter 11.
FAQ
What is RLHF and why are human preferences central to it?
Reinforcement learning from human feedback (RLHF) trains models using human judgments when explicit reward functions are hard to specify. Early work called it “reinforcement learning from human preferences” because human preferences supply the comparisons, ratings, and other signals that reward models learn to predict, which then guide policy optimization.Why is “Which poem is better?” a good example for RLHF?
Unlike factual questions with a single correct answer, evaluating creative outputs (like poems) is subjective and context-dependent. This lack of ground truth motivates using human feedback as an indirect reward signal to align models with what people tend to prefer.Why will RLHF never be a fully solved problem?
Human preferences are plural, dynamic, and context-sensitive. Aggregating them raises conflicts from social choice theory (e.g., not all fairness criteria can be met simultaneously), introduces measurement bias, and depends on presentation and timing effects—so any solution is inherently approximate and contingent.Which assumptions from classic RL conflict with real human preferences?
- Stationary, deterministic reward functions vs. non-stationary, context-shifting human preferences
- Markovian state assumptions vs. rich histories and partial observability in language tasks
- Single scalar utility maximization vs. multiple, sometimes incompatible human values
- Clear optimality notions vs. ambiguity and disagreement among annotators
How do “preference,” “reward,” and “cost” relate in RLHF?
They are different formalisms for “relative goodness.” Economics and decision theory motivate preferences; control and RL operationalize goals via rewards (maximize) or costs (minimize). RLHF compresses messy, multi-criteria human judgments into a scalar reward model that a policy can optimize.What’s the difference between empirical alignment and value alignment in RLHF?
Empirical alignment optimizes for observable performance on tasks (e.g., helpfulness, harmlessness) using human feedback. Value alignment aims to reflect deeper, often contested human values across people and contexts. RLHF in practice emphasizes empirical alignment, while research continues on pluralistic alignment and personalization.What role do Bellman equations and MDPs play, and what are their limits here?
Modern RL algorithms rely on Bellman recursions within Markov Decision Processes to estimate reward-to-go and improve policies with theoretical guarantees. Open-ended language settings violate many MDP assumptions (stationarity, full observability), so these guarantees rarely carry over cleanly to RLHF on LLMs.How does the Von Neumann–Morgenstern (VNM) utility theorem relate to RLHF?
VNM shows that, under certain axioms, preferences can be represented as expected utility—licensing scalar reward modeling. In practice, its assumptions are strained: preferences shift over time, can be intransitive, and depend on framing and interface design, especially in partially observed, high-dimensional language tasks.How do social choice results affect preference aggregation for RLHF?
Arrow-style impossibility theorems imply no aggregation method can satisfy all desirable criteria at once. Workarounds (e.g., interpersonal utility comparisons, principal–agent framing, multi-principal settings) help but can clash with goals like corrigibility. This makes global “one-size-fits-all” alignment inherently limited.What data and measurement pitfalls should RLHF practitioners watch for?
- Low inter-annotator agreement masking genuine pluralism
- Presentation and UI effects that alter expressed preferences
- Preference drift during sequential labeling
- Overreliance on proxy signals (e.g., dwell time) that entangle deployment and data collection
- Choice set design (binary vs. multiple options) and timing/context effects
 The RLHF Book ebook for free
The RLHF Book ebook for free