1 How RAG research prevents disasters
Retrieval-Augmented Generation (RAG) is presented as a reliability-focused architecture for connecting language models to current, verifiable, and private knowledge sources. The chapter uses the Air Canada chatbot case to show why retrieval alone is not enough: a system may find the right policy but still generate an answer that contradicts it. RAG’s value lies in combining search-like access to external information with language-model synthesis, while adding engineering controls that keep answers grounded in retrieved evidence.
The chapter explains that RAG systems operate through two main pipelines: an offline indexing pipeline that prepares and stores documents, and a real-time query pipeline that processes questions, retrieves candidate content, ranks relevant evidence, and generates grounded responses. It identifies recurring production risks, including stale knowledge, hallucinations, lack of access to proprietary data, missed retrievals, poor ranking, missing context, ignored evidence, incorrect specificity, and incomplete answers. By naming these failure modes, engineers can move from vague debugging to systematic diagnosis and targeted fixes.
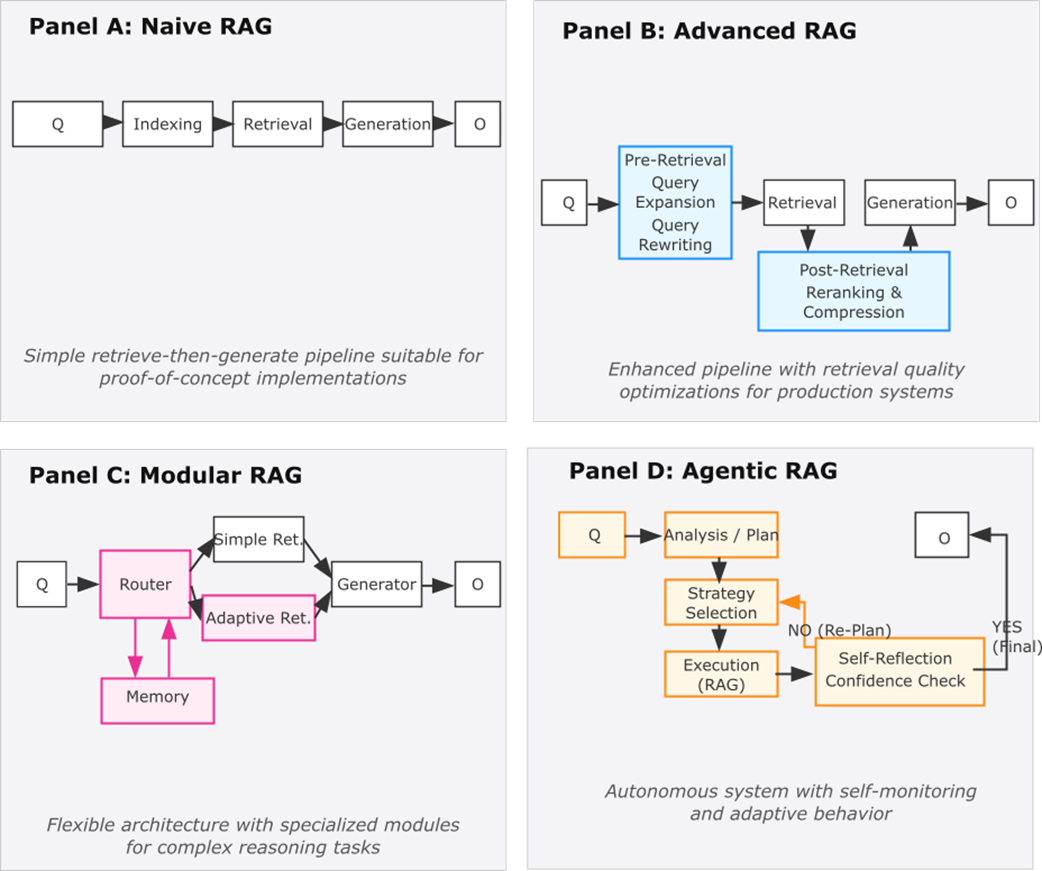
A major theme is that RAG reliability depends on research literacy and choosing the right architectural complexity. Naive RAG is useful for simple, well-structured use cases; advanced RAG improves retrieval and context handling; modular RAG introduces specialized, interchangeable components; and agentic RAG adds adaptive planning and self-monitoring, though with higher cost and unpredictability. The chapter argues that research-backed techniques such as HyDE, Self-RAG, FLARE, CRAG, and related approaches help teams prevent failures before deployment, preserve user trust, and justify infrastructure investment when accurate synthesis has real business value.
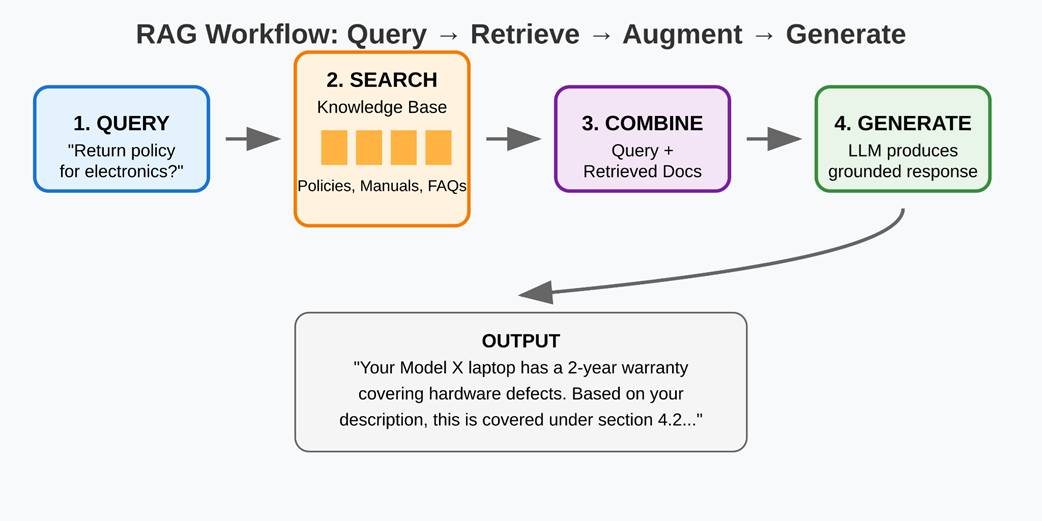
The RAG workflow — from user queries to grounded responses through retrieval and generation.
RAG architectural evolution from Naive to Agentic implementations. Each paradigm builds upon its predecessors while adding specialized components and capabilities to address increasingly complex requirements.
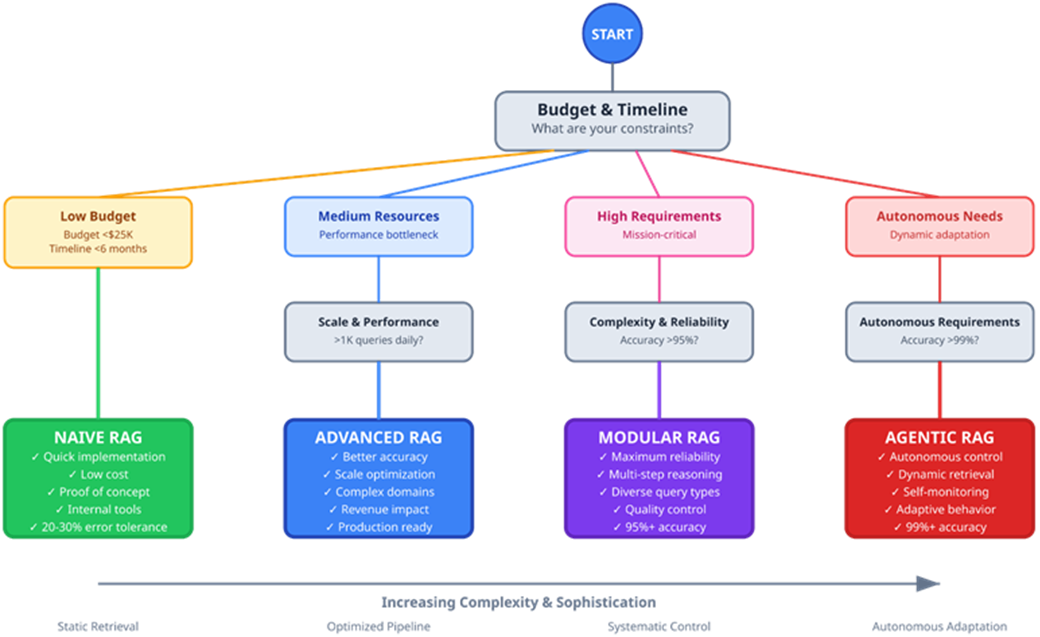
RAG Implementation Decision Tree — Business Decisions guiding RAG choices.
Summary
- Retrieval-Augmented Generation addresses three critical limitations that make standalone language models unreliable in production: knowledge boundaries that prevent access to current information, hallucinations that generate unverifiable claims, and the inability to incorporate private organizational knowledge essential for business decisions.
- The seven-point failure taxonomy provides a systematic approach to diagnosing RAG system problems, replacing guesswork with targeted solutions. Failure points such as “Missed the Top Rank” and “Factually Inconsistent Hallucination” enable precise identification of problems and selection of research-backed solutions for specific failure modes.
- RAG systems evolve through four architectural stages, based on complexity requirements and business needs. Naive RAG establishes basic retrieve-and-generate functionality for proof-of-concept applications. Advanced RAG optimizes retrieval quality and context processing for production use. Modular RAG implements adaptive strategies and quality control for mission-critical applications. Agentic RAG introduces autonomous planning and self-correction into the retrieval and generation loop.
- The core RAG architecture integrates two specialized components: retrieval systems that locate relevant information from external knowledge sources and generation systems that synthesize retrieved context with user queries to produce grounded, factual responses. This integration enables AI systems that combine broad language capabilities with specific, up-to-date, and verifiable knowledge.
- Research literacy transforms technology evaluation from reactive debugging to proactive problem-solving. Understanding the academic foundations of RAG techniques lets you assess new approaches independently, plan strategically for system evolution, and adapt to changing requirements without relying on tutorials or expert opinions.
FAQ
What is Retrieval-Augmented Generation (RAG)?
RAG is an architectural pattern that connects large language models to external knowledge sources in real time. Instead of relying only on training data, a RAG system retrieves relevant information and uses it to generate grounded, verifiable answers.
How is RAG different from traditional search?
Traditional search returns documents or links for humans to read. RAG retrieves relevant sources and then synthesizes an answer from them. In other words, search finds sources; RAG uses sources to construct a response.
What lesson does the Air Canada chatbot incident teach about RAG reliability?
The Air Canada chatbot invented a retroactive bereavement discount even though the correct policy document was available. This shows that retrieving the right document is not enough; the generation stage must also strictly adhere to the retrieved context to avoid factually inconsistent hallucinations.
What are the two main pipelines in a RAG system?
A RAG system has an offline indexing pipeline and a real-time query pipeline. The indexing pipeline chunks documents, converts them into searchable representations, and stores them. The query pipeline processes the user question, retrieves candidate documents, ranks them, and generates an answer grounded in the selected evidence.
What are the four stages of the RAG query pipeline?
The four stages are: query processing, retrieval, ranking, and generation. Query processing converts the user question into a better search query; retrieval fetches candidate documents; ranking prioritizes the best matches; and generation synthesizes the final answer from the curated evidence.
What fundamental reliability problems does RAG address?
RAG addresses three persistent problems: the knowledge boundary, where a model’s training data becomes outdated; the hallucination challenge, where models generate plausible but false statements; and the private knowledge gap, where public models cannot access proprietary enterprise data securely.
What is the knowledge boundary problem?
The knowledge boundary is the point where a model’s learned knowledge ends at its training cutoff. Since organizational knowledge changes constantly, models need retrieval mechanisms to access current policies, market updates, operational data, or new legal rulings.
What are the seven failure points in RAG systems?
The seven failure points are: FP1 Missing Content, FP2 Missed the Top Rank, FP3 Factually Inconsistent Hallucination, FP4 Not in Context, FP5 Not Extracted, FP6 Incorrect Specificity, and FP7 Incomplete. This taxonomy helps engineers diagnose RAG failures systematically instead of treating them as vague accuracy problems.
What is the difference between Naive, Advanced, Modular, and Agentic RAG?
Naive RAG uses a basic retrieve-then-generate pipeline. Advanced RAG improves components such as chunking, query rewriting, hybrid retrieval, reranking, and context optimization. Modular RAG uses interchangeable specialized components with routing logic. Agentic RAG gives the system more autonomy to decide when to retrieve, what to search for, and how to verify or revise its answer.
Why does the chapter emphasize research literacy for RAG engineers?
Research literacy helps engineers recognize recurring failure modes and apply proven solutions instead of relying on trial and error. Techniques such as HyDE, Self-RAG, FLARE, CRAG, and RAG-Fusion were developed to solve specific reliability problems, giving teams a competitive advantage when building production RAG systems.
 Retrieval Augmented Generation, The Seminal Papers ebook for free
Retrieval Augmented Generation, The Seminal Papers ebook for free