1 Introduction
Reinforcement Learning from Human Feedback (RLHF) is presented as the key technique that turned large language models from next-token predictors into helpful, safe, and engaging assistants. Born from the need to solve hard-to-specify objectives where human preferences are subtle and context dependent, RLHF rose to prominence with ChatGPT and now sits inside a broader post-training stack alongside instruction/supervised fine-tuning and reinforcement learning with verifiable rewards. Its central contribution is shaping model behavior—style, tone, format, and reliability—so outputs align with what people actually want, while also improving generalization across domains compared with instruction tuning alone.
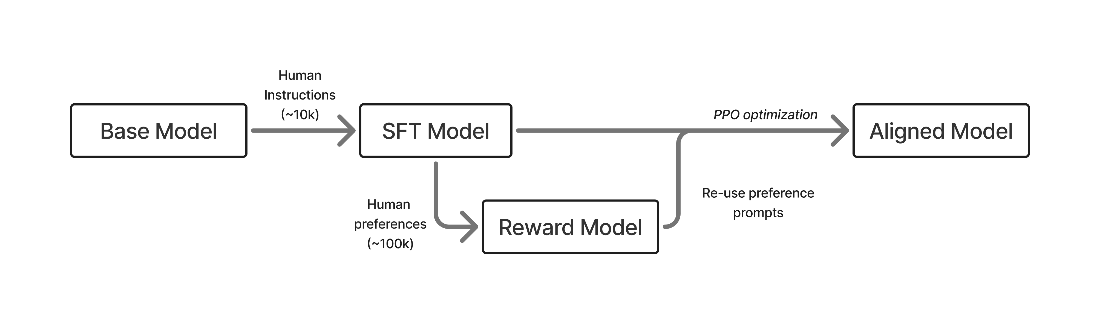
The canonical RLHF pipeline proceeds in three stages: first, instruction tuning teaches models to follow prompts in a question–answering format; second, human preference data trains a reward model that scores responses; third, reinforcement learning optimizes the policy to produce higher-scoring outputs. Unlike per-token learning in instruction tuning, RLHF updates at the response level using contrastive signals that highlight both preferable and undesirable behaviors. This flexibility delivers strong gains but introduces challenges: reward models are proxy objectives prone to over-optimization, regularization is essential, length bias can appear, costs are higher than simple fine-tuning, and success depends on starting from a capable base model and interleaving stages within a full post-training recipe.
The chapter traces the field’s evolution from early instruction-tuning recipes (e.g., Alpaca-era) and open skepticism about RLHF, through the widespread adoption of preference-tuning methods like Direct Preference Optimization, to today’s scaled, multi-stage post-training in frontier systems that increasingly emphasize reasoning and RL with verifiable rewards. It argues for an elicitation view of post-training—most capability is learned in pretraining, and post-training extracts and organizes it—while noting that modern RL-based methods now shape not just style but complex behaviors. Looking ahead, RLHF remains the foundation and bridge to richer RL-driven training, with the enduring goal of mapping human values and objectives into models, and the book aims to provide the concepts, trade-offs, and practical tools needed to do so.
A rendition of the early, three stage RLHF process: first training via supervised fine-tuning (SFT, chapter 4), building a reward model (RM, chapter 5), and then optimizing with reinforcement learning (RL, chapter 6).
Summary
- RLHF incorporates human preferences into AI systems to solve problems that are hard-to-specify programmatically, and became widely known through ChatGPT’s breakout, which made the capabilities of language models more approachable.
- The basic RLHF pipeline has three steps: instruction fine-tuning to teach the model to follow the question-answering format, training a reward model on human preferences, and optimizing the model with RL against that reward.
- RLHF is known to primarily change the style, tone, and format of model responses – making them more helpful, warm, and engaging. But it’s not “just style transfer”: RLHF also improves benchmark performance, though over-optimization (e.g., excessive length or chattiness) can harm capabilities in other domains.
- The elicitation theory of post-training suggests that base models contain latent potential, and post-training’s job is to extract and cultivate that intelligence into useful behaviors.
- RLHF is one component of modern post-training, alongside instruction fine-tuning (IFT/SFT) and reinforcement learning with verifiable rewards (RLVR), used together in an intertwined manner to craft particular training recipes.
FAQ
What is Reinforcement Learning from Human Feedback (RLHF) and what problems does it solve?
RLHF is a technique that incorporates human preference information into AI systems to tackle hard-to-specify objectives. It is especially useful when explicit task rewards are unavailable or user preferences are subtle or unexpressible, making it relevant across domains where humans interact directly with models.Why did RLHF become prominent after the release of ChatGPT?
RLHF was central to making large language models feel helpful, harmless, and engaging in real-world use. ChatGPT’s success showcased how aligning models to human preferences could transform base models from pure next-token predictors into general-purpose assistants, catalyzing rapid investment in post-training methods.What are the three main steps in the canonical RLHF pipeline?
- Supervised fine-tuning (SFT) to teach instruction-following and basic formatting- Collecting human preference data to train a reward model that scores responses
- Optimizing the model with RL by sampling completions, scoring them with the reward model, and updating the policy to make better responses more likely
How does RLHF change a model’s behavior compared to a base or SFT-only model?
Base models continue text in an open-ended way, often mimicking internet artifacts. SFT adds reliable Q&A behavior and formatting. RLHF further shifts responses to be concise, reliable, warm, and engaging by optimizing at the response level using comparative (contrastive) signals about what is better or worse, rather than just next-token prediction.Where does RLHF fit within modern post-training?
Post-training commonly includes three optimization types: (1) Instruction/Supervised Fine-tuning (IFT/SFT) to learn features and formats, (2) Preference Fine-tuning (PreFT) where RLHF dominates to align style and subtle human preferences, and (3) Reinforcement Learning with Verifiable Rewards (RLVR) to boost performance on verifiable tasks. RLHF is the core of the second stage.What is a reward model, and how is human feedback used in RLHF?
A reward model maps a response to a scalar score reflecting human preferences. It is trained on datasets of pairwise (or comparative) judgments across diverse prompts and labelers. During RL, this model ranks sampled completions so the policy can be updated toward higher-scoring behaviors.Why can RL-based post-training generalize better than instruction tuning alone?
RL-based methods optimize entire responses against a quality signal (human preferences or verifiable rewards), not just per-token likelihood. This response-level, comparative training yields broader generalization across domains and tasks than SFT alone.What are the main challenges and costs of doing RLHF?
- Training a robust reward model is nontrivial and application-dependent- Over-optimization risk due to proxy rewards, requiring careful regularization and controls
- Practical issues like length bias can emerge
- RLHF is more expensive in data, compute, and time, and it benefits from a strong starting model
 Reinforcement Learning from Human Feedback ebook for free
Reinforcement Learning from Human Feedback ebook for free