2 Formulate business problems with Markov decision process
This chapter frames complex business optimization as a sequential decision-making problem and shows how Markov decision processes (MDPs) provide the structure to both decompose and reassemble it coherently. It begins by contrasting analysis with synthesis, arguing that breaking problems into parts only works if we can reconnect them under uncertainty and dynamics. The Markov property is introduced through Markov chains as the key simplification: if the present state captures all relevant information, the future depends only on now, not on the full past. That insight makes modeling tractable and elevates state design—what to include and how to summarize history—into a first-class concern for making real processes effectively Markovian.
Building on that foundation, the chapter formalizes the core MDP components—state, action, transition dynamics, and reward—and explains how policies map states to actions to optimize long-term outcomes rather than short-term gains. It illustrates the stakes of good state engineering with concrete domains such as dynamic pricing, call-center staffing, preventive maintenance, and customer retention, highlighting how omitting critical variables (e.g., inventory, fatigue, maintenance age, or engagement recency) breaks the Markov assumption and degrades decision quality. The message is consistent: durable performance comes from policies that look ahead, respect uncertainty and constraints, and balance competing objectives over time.
A hands-on production-planning case ties it all together: a factory chooses daily whether to produce scooters, bikes, or idle under stochastic demand, with a reward that nets revenue against production, setup, holding, and backorder costs. Several intuitive policies (greedy, always-produce, never-switch, setup-aware) are compared, showing that strategies mindful of switching costs and future risk consistently outperform myopic rules. The chapter then codifies practical reward engineering and constraint-handling tactics: prefer stepwise feedback over sparse returns, expose constraints in the state, use graded penalties for soft limits, apply action masking for hard constraints (optionally with gentle penalties near boundaries), normalize and balance reward scales, and avoid proxy incentives that invite shortcuts. These practices prepare the ground for building realistic environments and, ultimately, for learning scalable, high-quality policies automatically in subsequent chapters.
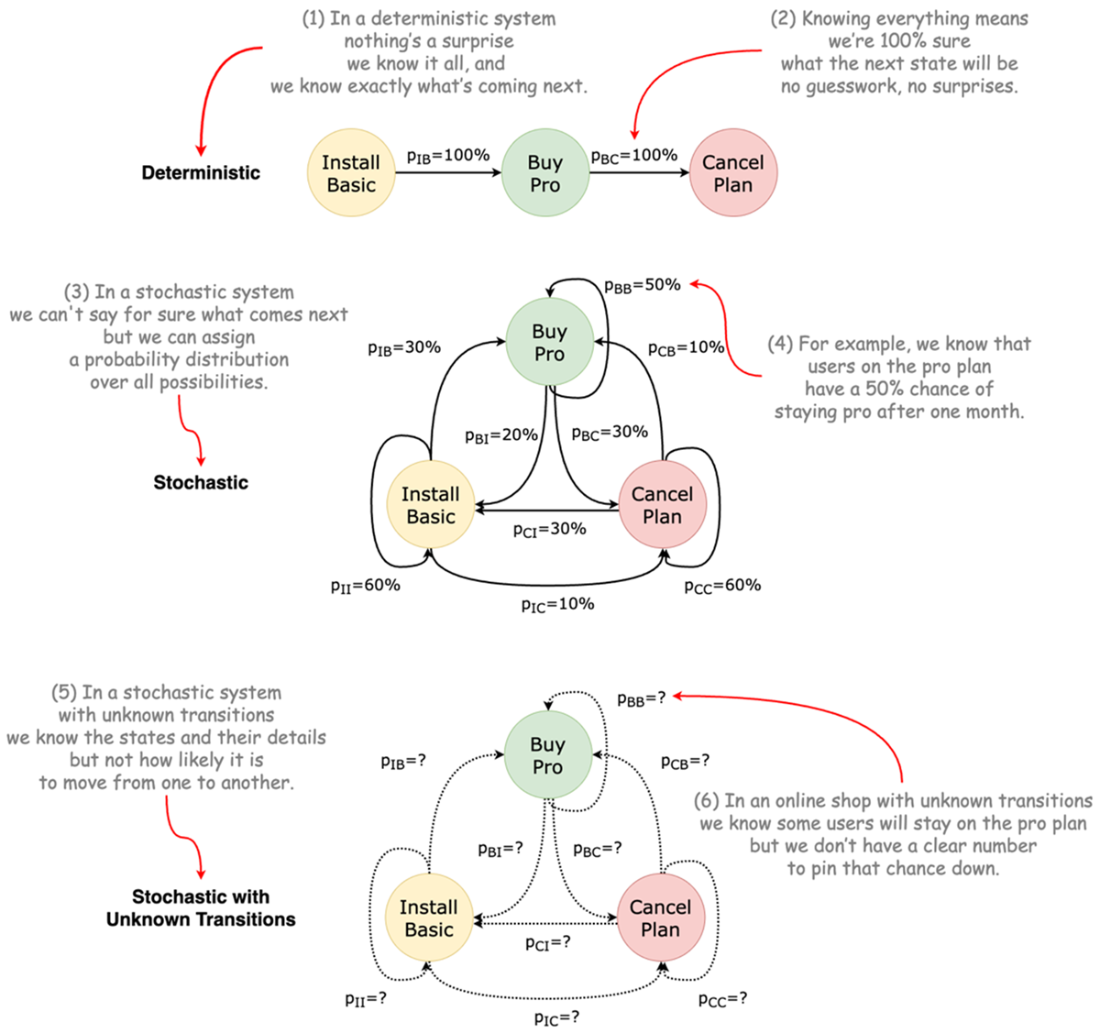
Three different types on how a system can evolve moving from one state to another.
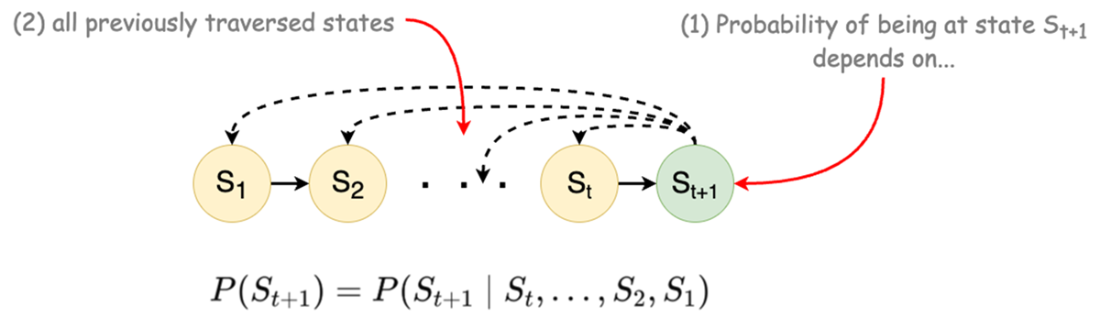
Conditional probability of dependency of next state to all previous states.
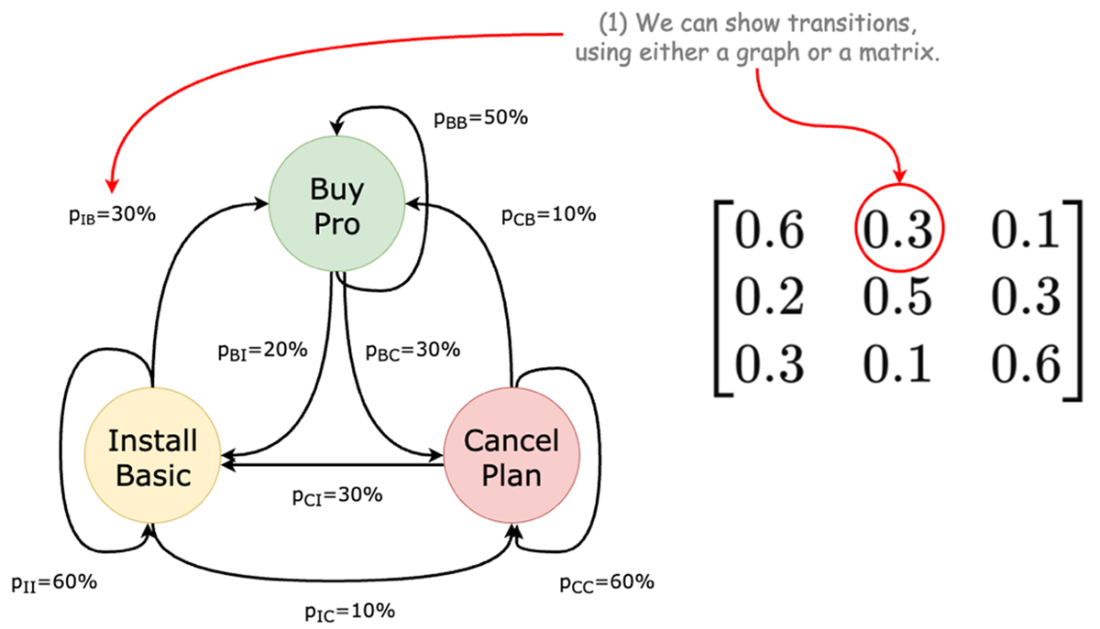
Software service transitions graph and its matrix representation.
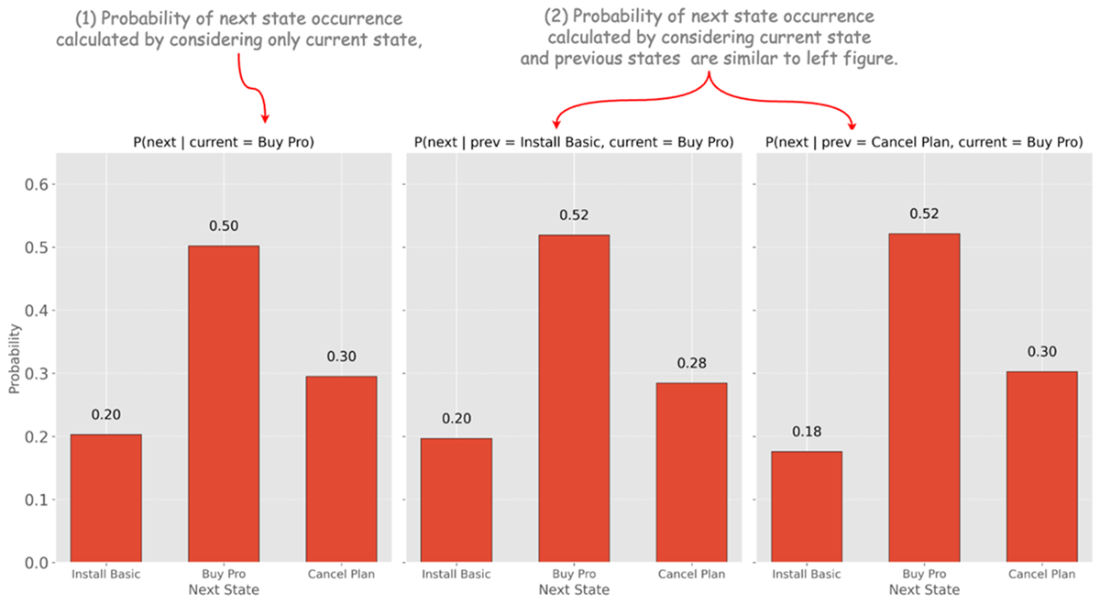
Transition distributions in three different scenarios
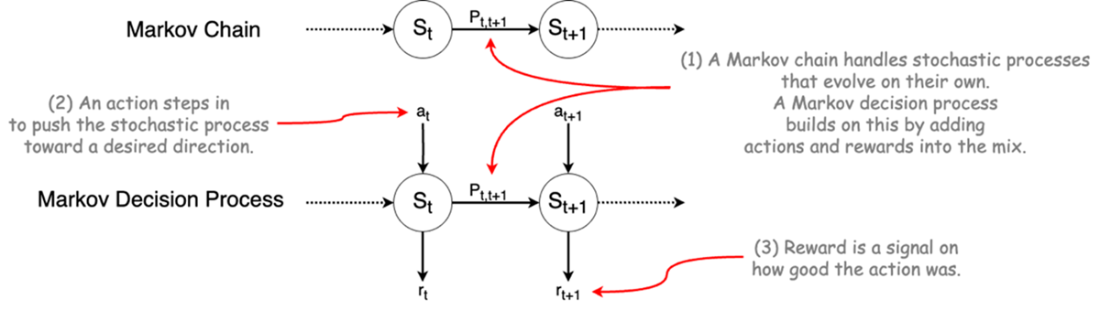
Markov chain and Markov decision process.
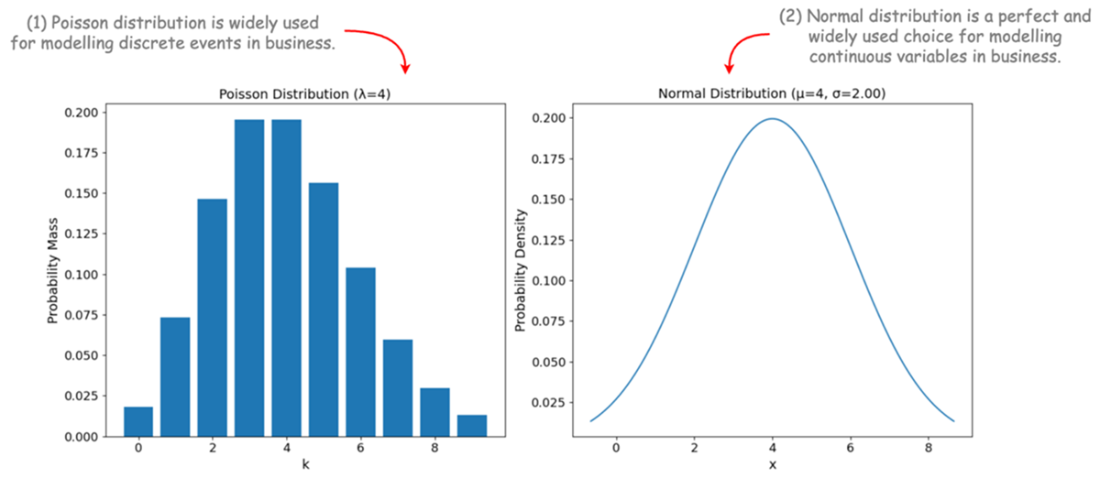
Two important probability distributions widely used for modeling business processes.
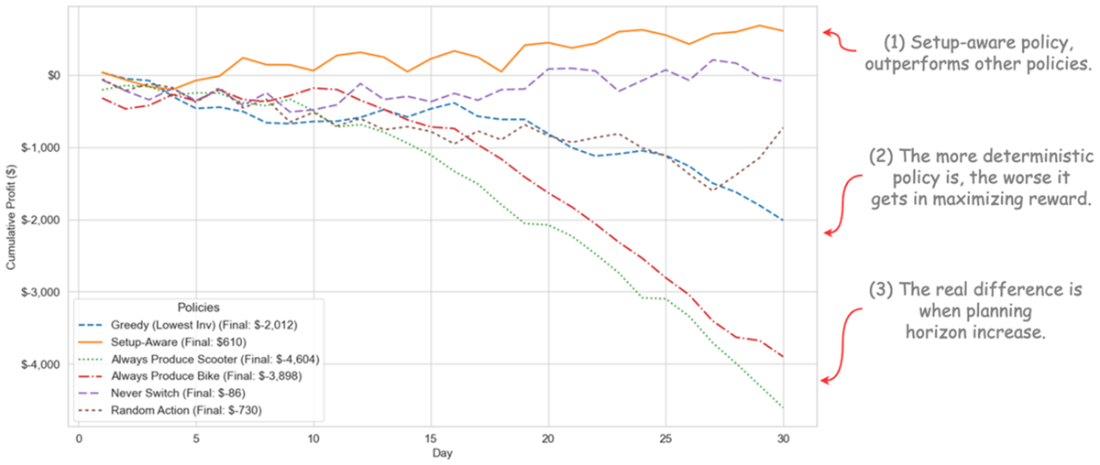
Cumulative profit ($) of following each policy in the planning horizon.
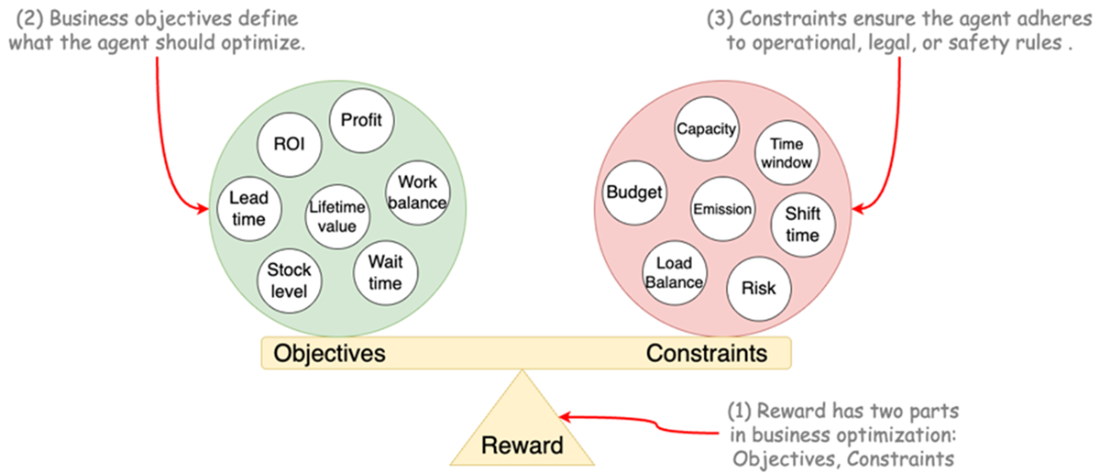
Two sides of reward function and some examples for each part.
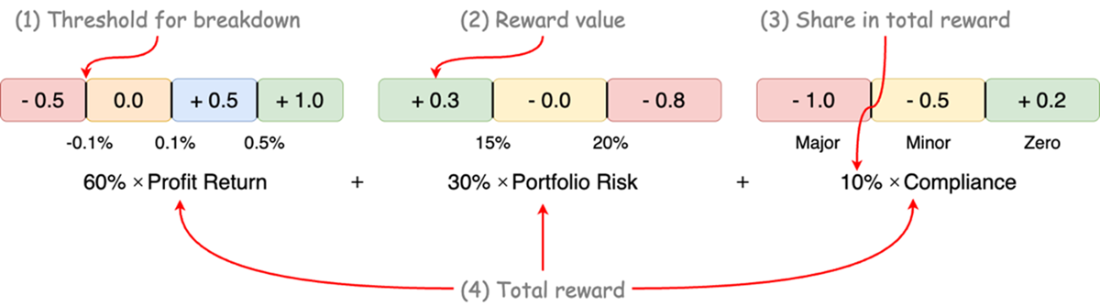
An example of reward normalization for a multi objective portfolio optimization
Summary
- Complex business problems require more than decomposition — they demand structured reassembly, and Markov decision processes offer just that.
- Markov decision processes break decision-making into states, actions, rewards, and transitions, enabling sequential decision making under uncertainty.
- State design is the key: a good state captures all essential information to predict what happens next (Markov property). Poor state design breaks predictive power.
- Markov chains model how systems evolve probabilistically; Markov decision processes extend this by adding control — letting agents make decisions that influence outcomes.
- A policy maps each state to an action, not for short-term gains but for long-term success — balancing current choices against future consequences.
- Markov decision process modeling requires clear thinking about business objectives and constraints, which together guide optimal decisions.
- Most real-world business problems can be modeled as Markov decision processes if states are crafted wisely.
- Reward functions in business must encode multiple objectives and penalties — they are not just feedback signals but behavioral steering tools.
- Effective reward engineering means giving feedback at the right time (stepwise rewards), balancing objective and constraint terms, and avoiding scale mismatches.
- Hard constraints should be enforced using action masking and penalty, while soft constraints can be handled just by penalties and dynamic trade-offs.
- Designing rewards requires careful monitoring to avoid unintended shortcuts, where agents optimize proxy metrics instead of real goals.
FAQ
What problem does an MDP solve for business optimization?
An MDP gives a structured way to make sequential decisions under uncertainty. It breaks a complex business process into states (snapshots), actions (choices), transition dynamics (how the world evolves), and rewards (feedback). Unlike passive prediction with Markov chains, MDPs let you intervene to shape outcomes and optimize long-term performance across routing, pricing, inventory, staffing, retention, and more.
What is a “state” and how do I make it Markovian?
A state is the minimal snapshot that contains all information needed to choose an action and predict what comes next. To make it Markovian, embed all critical internal and external factors (e.g., inventory, setup status, capacity, demand context, time index). If past information changes the next-state probabilities after conditioning on your current state, your state is missing features. Use domain knowledge first; statistical tests can help confirm sufficiency.
How do systems evolve in this framework: deterministic vs. stochastic transitions?
- Deterministic: Next state is fixed given the current state (rare in business).
- Stochastic with known transitions: You know or estimate transition probabilities (e.g., from data).
- Stochastic with unknown transitions: Most realistic; you learn/estimate dynamics as you go.
Markov chains model stochastic evolution compactly by assuming the next state depends only on the current state, not the full history.
What is the Markov property and how can I check it in practice?
The Markov property means the future depends only on the present state, not on past states. Practically, you can simulate or analyze data to compare next-state distributions conditioned on (a) the current state vs. (b) current + previous states. If they’re statistically the same, your state is sufficient. If not, add the missing variables (e.g., time-since-last-maintenance, backlog, recency) to the state.
What are the core components of an MDP in business terms?
- State (S): Current situation (e.g., inventory, capacity, open tickets, budget, time).
- Action (A): Decision you control (e.g., dispatch, restock level, price, schedule).
- Transition (P): How uncertainty moves you to a next state given the action (e.g., demand variability, delays, failures).
- Reward (R): Immediate outcome signal (e.g., profit, cost, penalties, retention).
- Policy (π): Strategy mapping states to actions to maximize long-run return.
How do I model transitions—probability matrices or stochastic simulators?
Small problems can use transition matrices. Real business problems are large and dynamic, so you typically write transition functions and sample from distributions (e.g., Poisson for discrete event counts like orders; Normal for aggregated continuous variability). This keeps models tractable while capturing key uncertainties.
What is a policy and why is long-term thinking essential?
A policy is a rule that picks an action in each state to maximize future cumulative reward. Good policies trade off immediate gains against future costs/risks (e.g., setup costs, backorders, churn). Myopic “greedy” choices often look good now but underperform over a horizon. The chapter’s factory case shows setup-aware, forward-looking policies winning over simplistic ones.
How should I design rewards (reward engineering) for business MDPs?
- Prefer stepwise (dense) rewards to guide learning each step, not just at the end.
- Encode objectives and constraints: revenue minus production/holding/backorder costs; penalties for violations.
- Normalize/balance components (e.g., to a common scale or [-1,1]) to avoid dominance by one term.
- Avoid deceptive proxies (e.g., clicks without revenue) that the agent can game.
- Advanced: Lagrangian methods and potential-based shaping to balance multiple goals.
How do I handle constraints: soft vs. hard?
- Expose constraints in the state (capacity, availability, temperatures, budgets) so the agent can plan around them.
- Soft constraints: use graded, stepwise penalties (e.g., lateness bands, mild energy overuse penalties).
- Hard constraints: use action masking to hide illegal moves (e.g., overweight loads, unavailable staff) and optionally add gentle penalties near limits to encourage safer choices.
What were the key takeaways from the production planning case study?
- State: (day, scooter inventory, bike inventory, current setup) captured essential information to be Markovian.
- Transitions: stochastic demand via Poisson; functional transitions instead of massive matrices.
- Reward: revenue minus production, setup, holding, and backorder costs to reflect real trade-offs.
- Policies: setup-aware outperformed greedy/random/always-one-product by balancing short-term sales with future costs.
- Process: define S/A/P/R, encode constraints, simulate, baseline with heuristics, then scale to learning optimal policies.
 Applied Reinforcement Learning ebook for free
Applied Reinforcement Learning ebook for free