1 Why rearchitecting LLMs matters
Large language models are powerful because they are broad, but that same breadth makes them costly and inefficient when they are applied to narrow business problems. In practice, companies often rely on the same general-purpose model for very different tasks, using prompt engineering to shape outputs, yet this only changes behavior at the surface. It does not reduce the model’s size, improve its fit for the task, or create meaningful differentiation from competitors who can access the same systems.
The chapter argues that the real issue is a mismatch between generic model architectures and specialized deployment needs. Costs can spiral in production, especially when token usage grows, outputs are unpredictable, and oversized infrastructure is kept running for limited workloads. At the same time, organizations in regulated or high-stakes sectors need explainability and stability, which black-box API models do not provide. Even fine-tuning and retrieval-based approaches have limits if the underlying model remains general and overbuilt for the task.
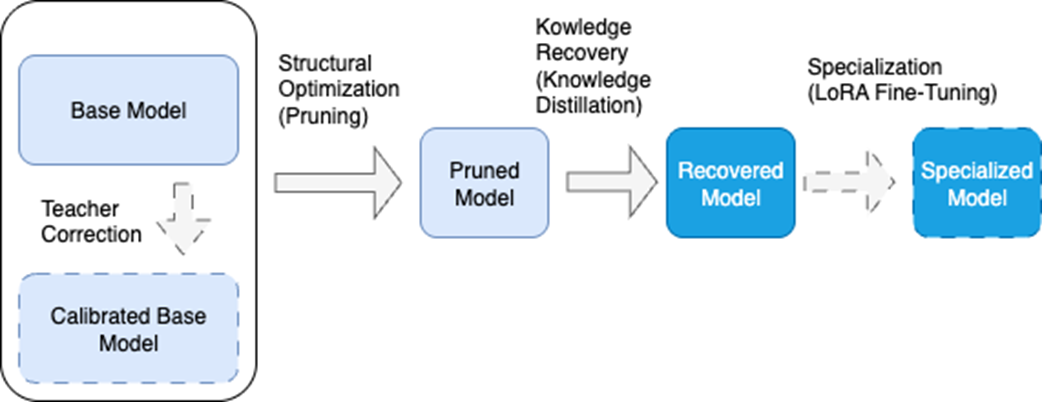
The proposed answer is model rearchitecting: a pipeline that structurally adapts a pretrained model to a specific use case. The process typically begins with pruning to remove unnecessary parts, continues with knowledge distillation to recover lost capability, and then uses parameter-efficient specialization such as LoRA; an initial calibration step can also help align the base model. Domain data guides every stage, making it possible to build smaller, faster, more efficient models that are better suited to a target domain, while the book prepares readers to learn both the practical methods and the internal workings needed to become model architects.
The model tailoring pipeline consists of core phases (shown with solid arrows) and optional phases (shown with dashed arrows). In the first phase, we adapt the structure to the model's objectives through pruning. Next, we recover capabilities it may have lost through knowledge distillation. Finally, we can optionally specialize the model through fine-tuning. An optional initial phase calibrates the base model, via a brief fine-tuning pass on the target dataset.
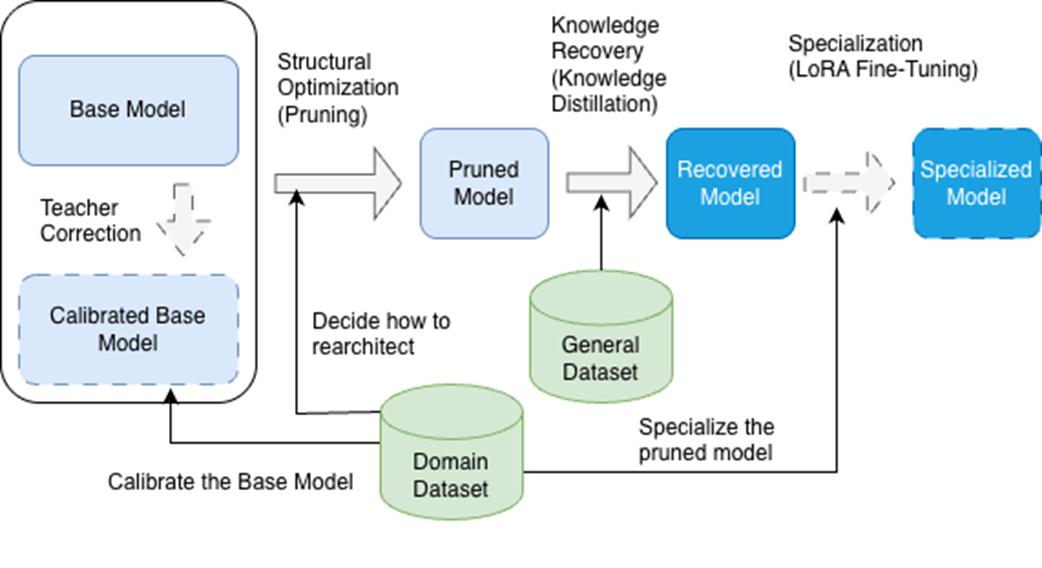
Dataset integration in the rearchitecting pipeline. The domain-specific dataset guides calibration of the base model, informs structural optimization decisions, and enables final specialization through LoRA fine-tuning. A general dataset supports Knowledge Recovery, ensuring the pruned model retains broad capabilities before domain-specific specialization. This dual approach optimizes each phase for the project’s objectives.
Summary
- The use of oversized, generic LLMs can lead to high production costs, little differentiation from competitors, and no explainability of decisions.
- Models become more effective and efficient by adapting their architecture to a specific domain and task.
- The model-architecting process consists of three phases: structure optimization, knowledge recovery, and specialization.
- The domain-specific dataset is a key element and common thread throughout the process, ensuring each optimization and specialization phase aligns with the final objective.
- Knowledge distillation transfers capabilities from the original teacher model to the pruned student model, enabling the student to learn not only the correct answers but also the reasoning process that leads to them.
- Fine-tuning techniques such as LoRA allow domain specialization by training only a small number of parameters, drastically reducing cost and time.
- Modern architectures like LLaMA, Mistral, Gemma, and Qwen share structural traits that make them well suited to rearchitecting techniques.
- By mastering these techniques, developers can go from being model users to model architects.
 Rearchitecting LLMs ebook for free
Rearchitecting LLMs ebook for free