1 Facing the Efficiency Wall
Modern machine learning inference has reached an efficiency wall: the main constraint is no longer raw compute, but the cost of moving data through memory. Large transformers have grown in parameter count, context length, and generated-token workloads, turning inference from a simple application concern into an infrastructure, power, and bandwidth problem. Even powerful GPUs can appear underutilized because arithmetic is relatively cheap while fetching weights and KV-cache data from memory consumes far more energy and time.
The chapter explains why quantization is a practical response to this bottleneck. By representing weights and activations with fewer bits, such as moving from FP16 or FP32 to INT8 or INT4, quantization directly reduces the number of bytes stored, transferred, and powered per token. Other optimizations, including better kernels, batching, caching, sparse architectures, or distillation, can help, but many either do not reduce the dominant memory traffic directly or require changing the model. Quantization stands out because it often preserves the same model structure while lowering memory footprint, bandwidth demand, and energy cost in a nearly linear way.
The chapter also introduces the numerical shift from floating point to integer representation. Floating point is expressive and flexible, using exponents and mantissas to represent a wide range of magnitudes, but that flexibility carries memory and hardware costs that are often unnecessary during inference. Integers use a fixed grid of representable values, sacrificing some range and resolution in exchange for simpler arithmetic, lower power, and higher throughput. The central tradeoff of quantization is therefore deciding how much numerical expressiveness a model actually needs in order to maintain acceptable quality while minimizing energy and deployment cost.
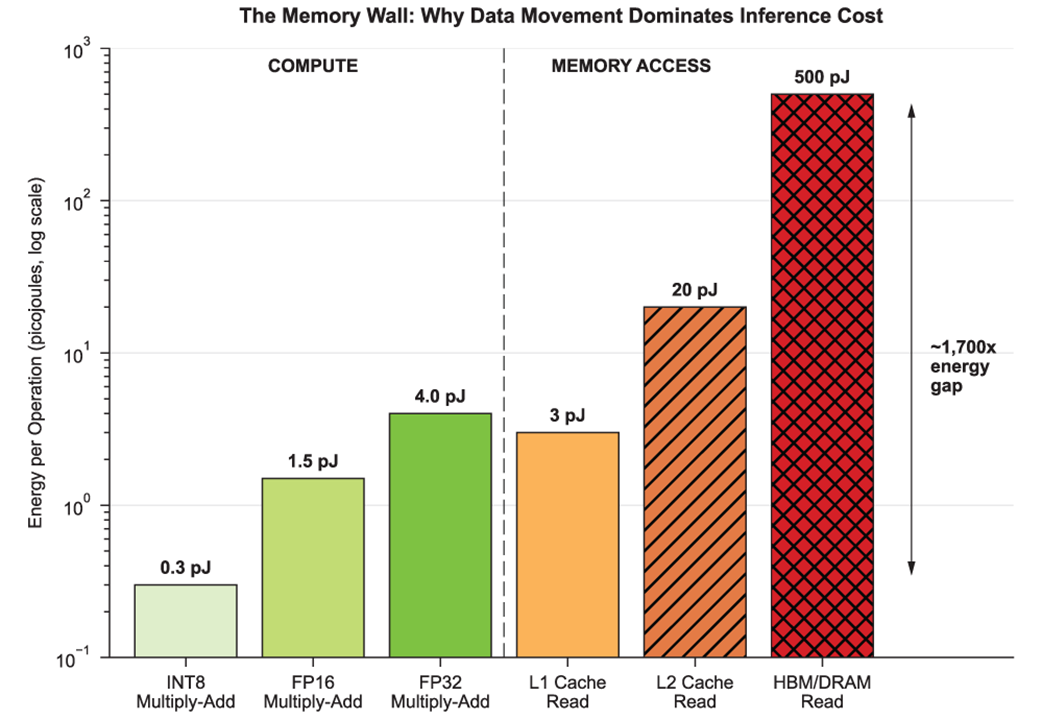
Fetching data from HBM costs roughly 1,700× more energy than an INT8 multiply-add. This gap explains why inference systems are bottlenecked by memory, not compute.
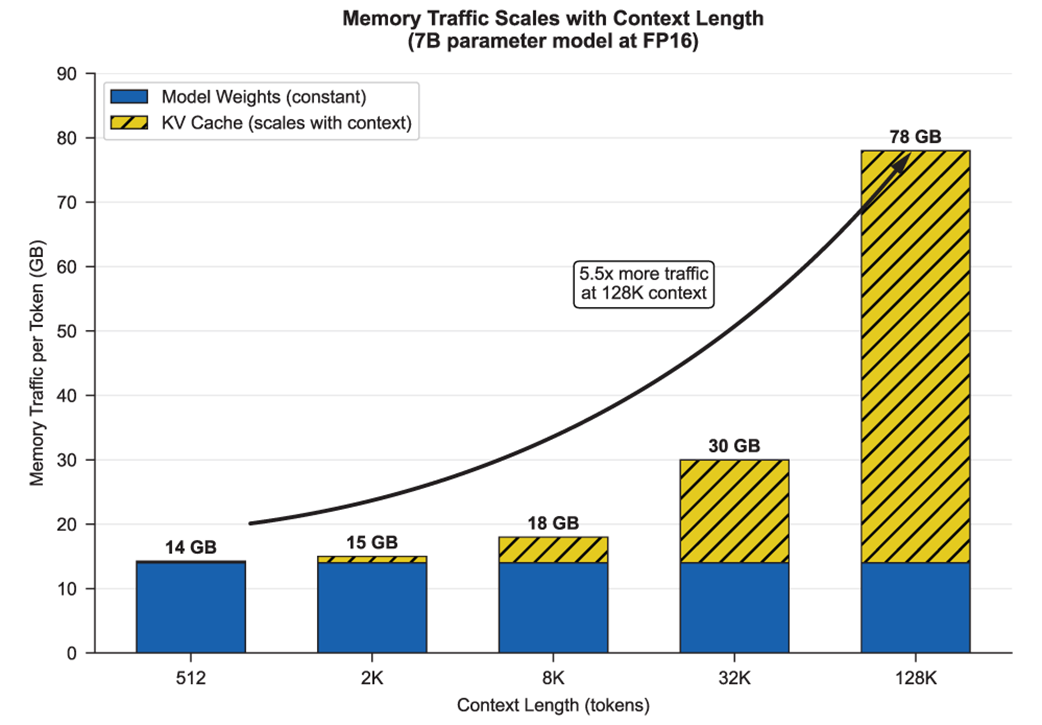
Memory traffic per token as context length grows. Model weights (filled) stay constant, but the KV cache (hatched) scales linearly with context. At 128K tokens, total memory traffic reaches 78 GB per token—5.5× more than at 512 tokens.
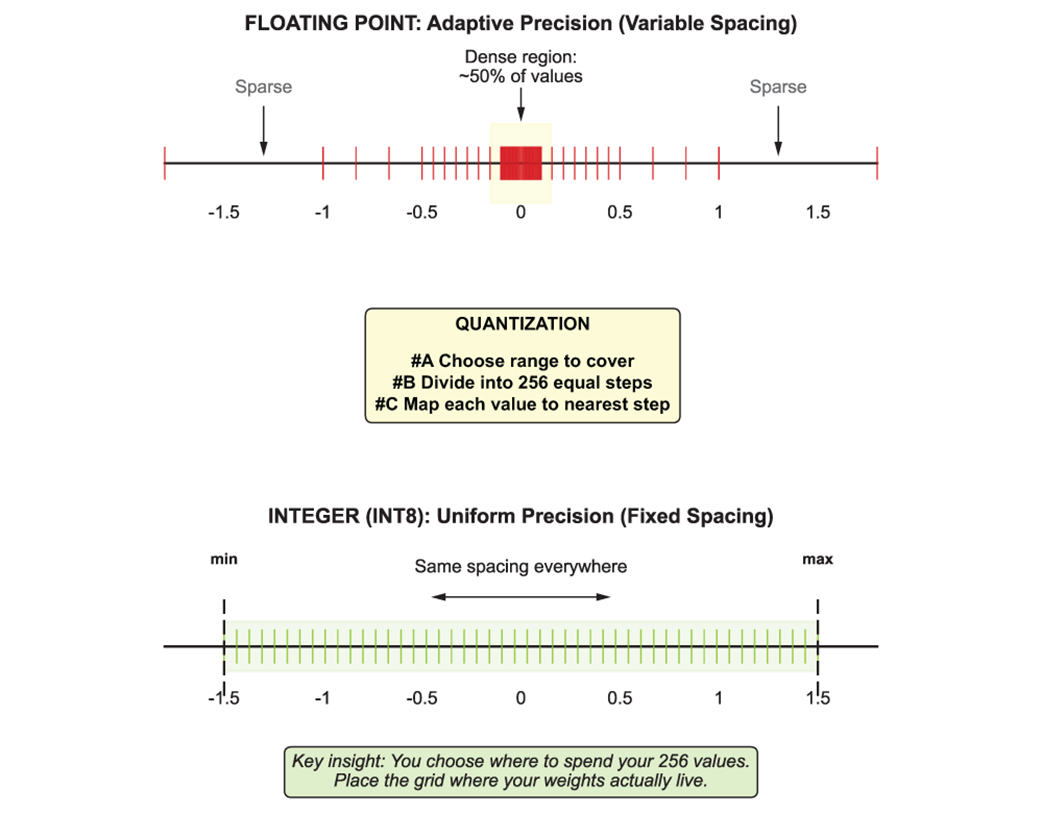
Floating point concentrates precision near zero (top), leaving large values sparsely represented. Integers use uniform spacing across your chosen range (bottom). Quantization is the act of deciding where to place that fixed grid.
Summary
- Modern LLM inference is constrained by memory bandwidth and power consumption, not raw compute; a 7B parameter model moves roughly 15 GB through memory for every token generated, consuming nearly 2 joules of energy per token.
- Lowering precision from 16-bit floats to 8-bit or 4-bit integers cuts memory footprint, bandwidth, and energy in roughly the same proportion as the bit reduction; that direct, linear scaling is what makes quantization the practical lever rather than a theoretical one.
- Neural networks tolerate quantization because they encode directions and correlations rather than exact values; their inherent redundancy absorbs the bounded approximation error that lower precision introduces.
- The core tradeoff in quantization is range versus resolution: integers force you to choose a fixed grid where every number must fit, unlike floating point which auto-scales at the cost of hardware complexity.
FAQ
Why has efficiency become a central problem for modern LLM inference?
Modern LLMs have crossed a scale threshold: parameter counts have grown rapidly, context lengths have expanded, and production workloads now behave more like infrastructure than ordinary applications. As a result, latency, power draw, and memory bandwidth often become the limiting factors rather than raw arithmetic throughput.
What is the main bottleneck in modern LLM inference?
The main bottleneck is usually memory movement, not compute. GPUs may have enormous arithmetic capacity, but inference repeatedly reads model weights, KV cache entries, and intermediate data from memory. Moving those bytes, especially from HBM or off-chip DRAM, costs far more energy than performing multiply-add operations.
Why is data movement more expensive than arithmetic?
Arithmetic operations are relatively cheap: an INT8 multiply-add may cost roughly 0.2–0.5 picojoules, while fetching data from HBM or off-chip DRAM can cost roughly 300–1000 picojoules. That means accessing memory can cost two to three orders of magnitude more energy than computation, making bytes moved the dominant cost.
How much memory does a 7B-parameter model require at different precisions?
A 7B-parameter model requires about 28 GB at FP32, about 14 GB at FP16 or BF16, and about 7 GB at INT8. This reduction matters not only for storage, but also because those weights must be repeatedly moved through memory during inference.
What contributes to memory traffic per generated token in a transformer?
For each generated token, a transformer moves data mainly through three sources: model weights, the KV cache, and activations or intermediate buffers. In a realistic 7B-parameter transformer with a roughly 2,048-token context, FP16 model weights may contribute about 14 GB of traffic, the KV cache about 1 GB, and activations only about 0.5 MB.
What is the KV cache, and why does it matter for efficiency?
The KV cache stores the attention keys and values for every token generated so far. During generation, the model rereads this cache to maintain context. Because its size grows linearly with sequence length, longer contexts can make KV-cache traffic a major contributor to memory bandwidth and energy cost.
Why does quantization directly address the dominant inference cost?
Quantization represents weights and activations with fewer bits, such as moving from 16-bit floating point to 8-bit or 4-bit integers. Since the dominant cost is moving bytes through memory, reducing the number of bytes directly reduces memory footprint, memory bandwidth, and energy per token.
Why not just wait for faster hardware instead of using quantization?
Hardware progress tends to improve compute density faster than it improves the energy cost of moving data from memory. Faster GPUs and more FLOPs help, but they do not eliminate the structural mismatch: off-chip memory access remains much more expensive than arithmetic. Quantization helps because it reduces how much data must move.
Why does quantization usually not destroy model quality?
Neural networks are redundant and approximate by nature. Their weights encode directions, correlations, and relative influence rather than exact scientific measurements. Small, bounded perturbations from quantization are often absorbed by the model, so quality typically degrades gradually rather than catastrophically, especially at moderate bit-widths like INT8 or well-designed INT4.
What is the key difference between floating point and integer representation?
Floating point acts like a zoom lens: it uses exponents and mantissas to adapt precision across a wide range of magnitudes. Integers act like a fixed grid: values are evenly spaced within a chosen range. Quantization is the process of choosing where to place that grid, trading numerical expressiveness for efficiency.
 Quantization and Fast Inference ebook for free
Quantization and Fast Inference ebook for free