9 High availability bad practices
PostgreSQL’s reputation for resilience only holds when high availability is treated as a first-class design goal. The chapter underscores that HA means keeping the database accessible through failures while minimizing downtime and data loss, with acceptable targets defined by each organization’s RPO and RTO. Complacency, cost-cutting, or misunderstanding of PostgreSQL’s internals commonly lead to dangerous gaps: hardware redundancy is mistaken for data safety, replication is assumed to be a backup, and ad‑hoc operations are trusted over automation and testing. The antidote is proactive planning, explicit backups, redundancy, and the right automation and tooling.
Several backup antipatterns recur. Relying on RAID or filesystem snapshots does not protect against logical corruption or user mistakes, and replication can faithfully propagate both accidental drops and corrupted WAL; even delayed replicas are not a guarantee. Proper backups must be PostgreSQL-aware: base backups with archived WAL enable Point-in-Time Recovery, allowing restoration to the precise moment before damage. Using pg_dump as a primary safety net is inadequate for HA because it is logical, slow to restore, and cluster-wide consistency can’t be guaranteed across interdependent databases; instead use pg_basebackup (including incremental backups in newer releases) and continuous archiving. Manual backup routines and storing backups on the same host are recipes for loss; automate schedules, keep off-host/offsite copies, and regularly test restores. Verification should be routine: rehearse recovery, validate base backups with pg_verifybackup, inspect WAL with pg_waldump, and, if needed, use page-level checks—then automate those checks and alerts.
Redundancy is essential to meet tight RTOs: maintain one or more standbys via streaming replication (asynchronous or synchronous), use cascading to offload the primary, and understand features like replication slots and timelines. Just as with backups, avoid homegrown failover scripts; they often miss edge cases such as promoting a lagging replica or split-brain during network partitions. Prefer mature HA tooling that coordinates the cluster, enforces quorum/witness and fencing, manages promotions, keeps replicas in sync (including pg_rewind when timelines diverge), and integrates with monitoring and connection management. In combination, tested backups with PITR, automated verification, multiple replicas, and a proven HA orchestrator are the foundation for avoiding downtime and data loss.
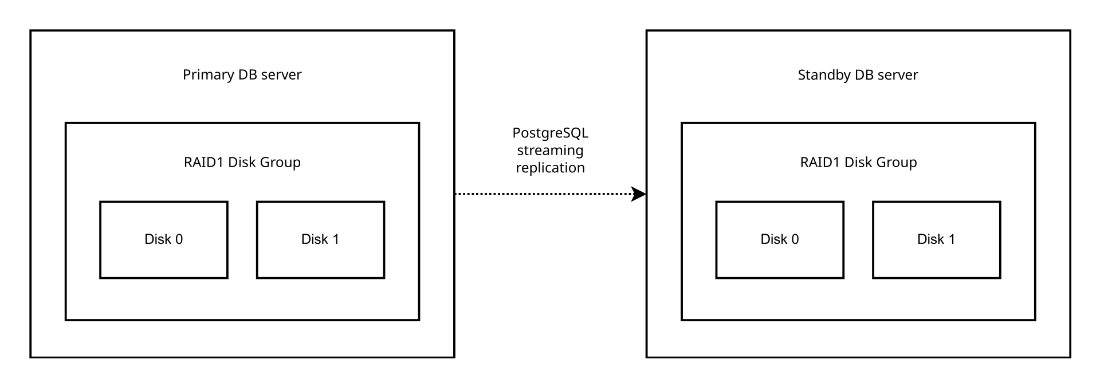
A PostgreSQL installation layout, demonstrating the double physical redundancy of having a standby server but also RAID1 mirrored disks in each of the servers.
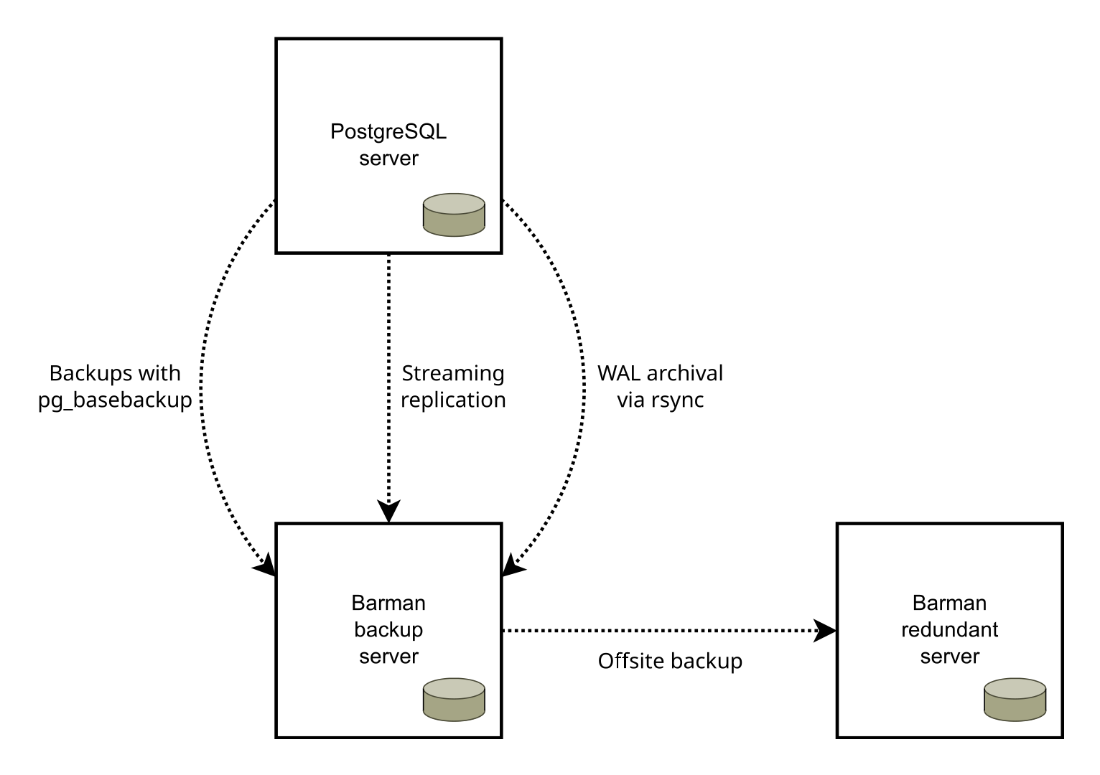
A sample PostgreSQL backup setup with a dedicated Barman server and geographical redundancy, showing the possible transfer paths.
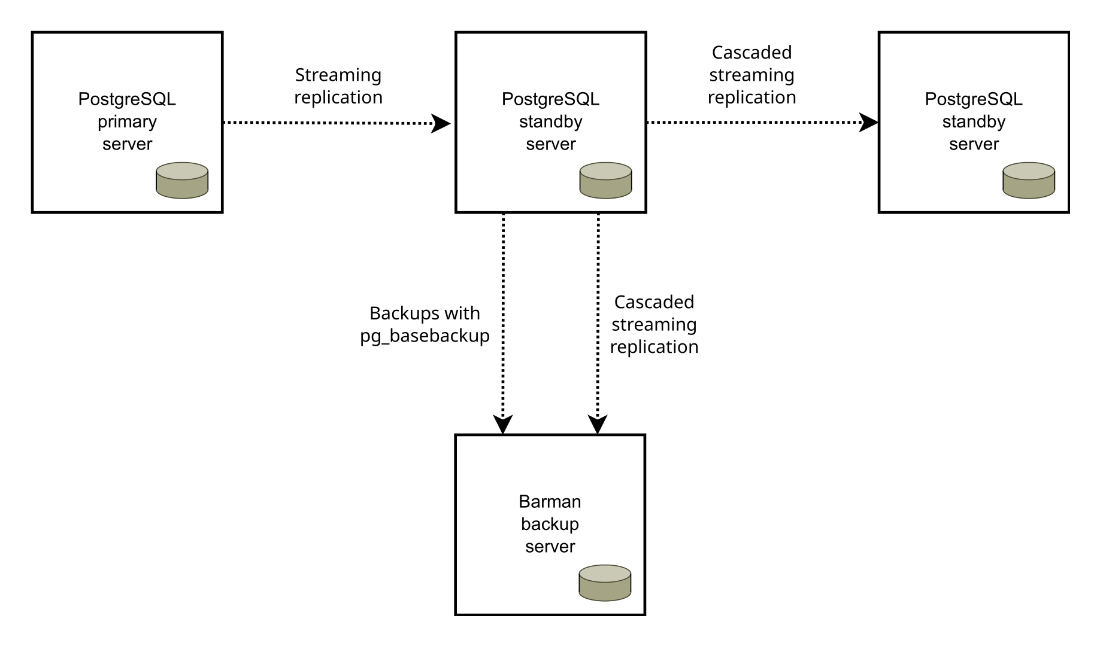
A sample PostgreSQL HA setup with a cascaded replication setup for redundancy and backup.
Summary
- RAID and filesystem snapshots can’t help you reliably recover from corruption, human error or malicious activity. The best way to guarantee your data is safe is to take backups using appropriate tools like
pg_basebackup. - Taking full backups only makes you vulnerable to data loss between backups. Leverage Point-in-time recovery with continuous archiving to be able to restore your database to the point before it was damaged.
- Taking backups manually is not robust or reliable, you should instead schedule automated backups, preferably using dedicated software that is PostgreSQL-aware (such as Barman or pgBackRest) and ensuring that you have a redundant copy of the backups in a second location.
- Untested backups can fail when you need them the most so to ensure that they work correctly always attempt a full restore to test your backups. Do not rely solely on automation but verify every step. Avoid using homegrown scripts and prefer tried-and-tested solutions.
- Having a single database server with no provision for failover inevitably leads to downtime. Ensure redundancy by setting up standby nodes via replication.
- Manual failover or custom scripts are risky because of the potential for extended downtime, data divergence or loss. Prefer proven high availability tools such as RepMgr, Patroni or CloudNativePG for Kubernetes to ensure reliable and effective management of your HA cluster.
FAQ
Does RAID and a streaming replica mean I don’t need backups?
No. RAID mirrors failures above the hardware layer, so filesystem or data corruption is duplicated to the mirror. Streaming replication also mirrors mistakes and corruption: a DROP TABLE, bad writes, or corrupt WAL on the primary will be replayed on the standby. Even delayed replicas can still miss the detection window. Only proper backups let you recover to a clean point independent of what happened to the primary or its replica.
Are filesystem snapshots a safe way to back up PostgreSQL?
Only if they are coordinated and truly atomic across all tablespaces. PostgreSQL requires WAL and data files to be in sync. Safe options are to take the snapshot after a clean shutdown, or quiesce with pg_backup_start() and pg_backup_stop(). Never restore a snapshot over a running cluster. Even with atomic snapshots, a restore starts crash recovery and is not a substitute for PostgreSQL-aware backups.
Why isn’t pg_dump/pg_dumpall enough for HA-grade backups?
They create logical backups, not physical copies. That means:
- No point-in-time recovery (PITR) between full dumps.
- Cluster-wide consistency isn’t guaranteed across multiple databases while they are active.
- Restores can be slow because indexes and on-disk structures are rebuilt, and planner stats are lost.
Use physical base backups plus archived WAL for HA and PITR.
What is Point-in-Time Recovery (PITR) and how do I set it up?
PITR lets you restore the database to an exact moment before a failure or mistake.
- Enable WAL archiving with archive_command in postgresql.conf.
- Take a base backup with pg_basebackup and keep all WAL generated from backup start to completion.
- To restore, place the base backup, provide the archived WAL, and set a recovery target (for example recovery_target_time) to the desired point.
- Timelines allow you to branch and try multiple recovery points without losing prior states.
- PostgreSQL 17 adds incremental backups with pg_basebackup to reduce full-backup cost.
Can I use pg_dump together with WAL files for PITR?
No. You can’t mix logical backups (pg_dump/pg_dumpall) with WAL for PITR. PITR requires physical base backups plus the corresponding archived WAL. Use tools like pg_basebackup and a WAL archive, often orchestrated by Barman or pgBackRest.
Why must backups be automated and stored off the database server?
Manual processes are error-prone and inconsistent, and people are unavailable or forget. Keeping backups on the same server or storage risks total loss if that host fails. Automate schedules and monitoring, and store copies on independent and preferably offsite media. Tools like Barman and pgBackRest handle base backups, WAL archiving, retention, parallel transfer, and multi-destination storage.
How do I verify that my backups and WAL archives actually restore?
Regularly perform test restores in a separate environment. At minimum:
- Copy the base backup to a fresh PGDATA.
- Verify it with pg_verifybackup.
- Provide all required WAL since the backup; sanity-check with pg_waldump.
- Start PostgreSQL and confirm it reaches a consistent state and that data is present.
For maximum assurance, use pageinspect to read and validate pages, and automate the entire verification with alerts on failure.
What do RPO and RTO mean, and how do backups and replicas affect them?
RPO (Recovery Point Objective) is the acceptable data loss. PITR with archived WAL can reduce RPO to near zero relative to your last saved WAL. RTO (Recovery Time Objective) is the acceptable downtime. Redundancy with standbys reduces RTO by enabling rapid failover without waiting to provision hardware and restore full backups. Synchronous replication can push RPO toward zero at the cost of write latency.
Why should I use a proven HA tool instead of custom failover scripts?
Edge cases are hard: replication lag can promote a behind replica; network partitions can cause split-brain; diverging timelines require careful reconciliation. HA tools coordinate cluster state, WAL positions, and promotion, using mechanisms like witness/quorum/fencing, and utilities such as pg_rewind to realign replicas. Use Patroni, repmgr, or CloudNativePG (for Kubernetes) instead of reinventing the wheel.
How many replicas should I run, and when should I use cascading replication?
To maintain redundancy during maintenance or a failure, run at least two standbys. Cascading replication lets a standby stream to other standbys and to a backup server, reducing load on the primary. This topology improves availability, supports fast failover, offloads read traffic to hot standbys, and keeps backups current without overburdening the primary.
 PostgreSQL Mistakes and How to Avoid Them ebook for free
PostgreSQL Mistakes and How to Avoid Them ebook for free