This chapter surveys the most common ways seemingly harmless SQL turns into wrong answers or slow queries in PostgreSQL, and how to avoid them. It emphasizes understanding SQL’s three-valued logic and type behavior, writing planner-friendly predicates, and staying alert to subtle semantics such as inclusivity, case sensitivity, and nullability. The overarching message is to prioritize correctness first, then performance, and to use the planner and supporting tools to validate assumptions instead of relying on intuition.
Key pitfalls include negative predicates and nulls (NOT IN collapses in the presence of NULL; favor NOT EXISTS/anti-joins), range filters (BETWEEN is inclusive and can double-count boundary events; prefer half-open ranges), and counting (COUNT(column) skips NULLs; COUNT(*) counts rows). Type issues surface with integer division truncation and division-by-zero (cast to non-integer types and guard with NULLIF/COALESCE). Naming and quoting matter: quoted, mixed-case identifiers are case sensitive and brittle; prefer unquoted lower case and use aliases for presentation. CTEs help readability, deduplication, and selective materialization; PostgreSQL can inline them for better plans. Upserts need care with composite keys that contain NULL; from PostgreSQL 15 onward, indexes defined with NULLS NOT DISTINCT allow correct ON CONFLICT behavior.
For performance, write sargable predicates so indexes can be used (avoid wrapping indexed columns in functions; move transformations to the constant side or consider expression indexes when appropriate), return only the columns and rows you need to reduce I/O and enable index-only scans, and confirm expectations with EXPLAIN/ANALYZE. Augment review with static checks and linters to catch style and semantic issues early, and use migration analyzers to preflight DDL risk. Generative AI can be a helpful brainstorming partner, but always validate its output, be mindful of privacy, and measure the actual behavior of the resulting SQL in your database.
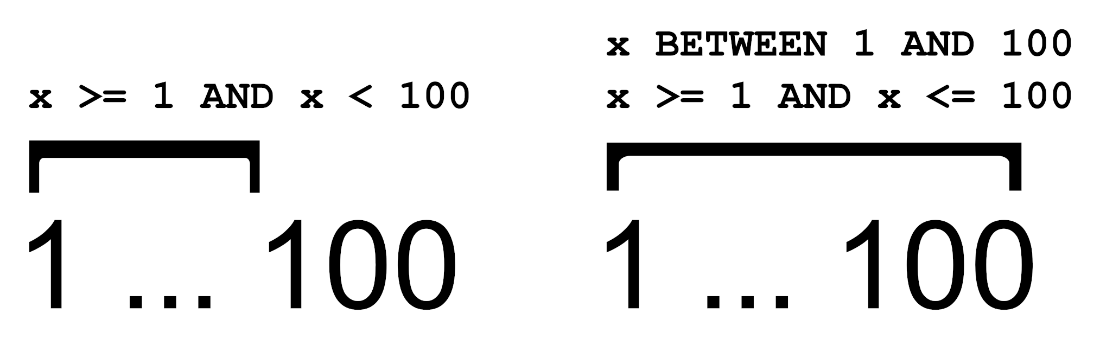
BETWEEN is inclusive
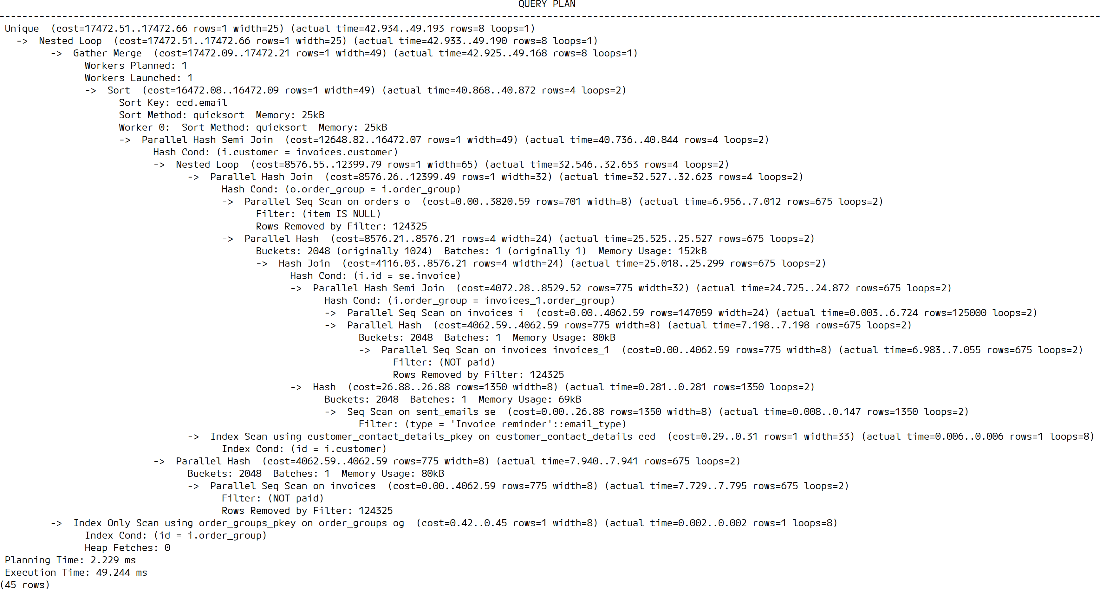
Non-CTE query plan
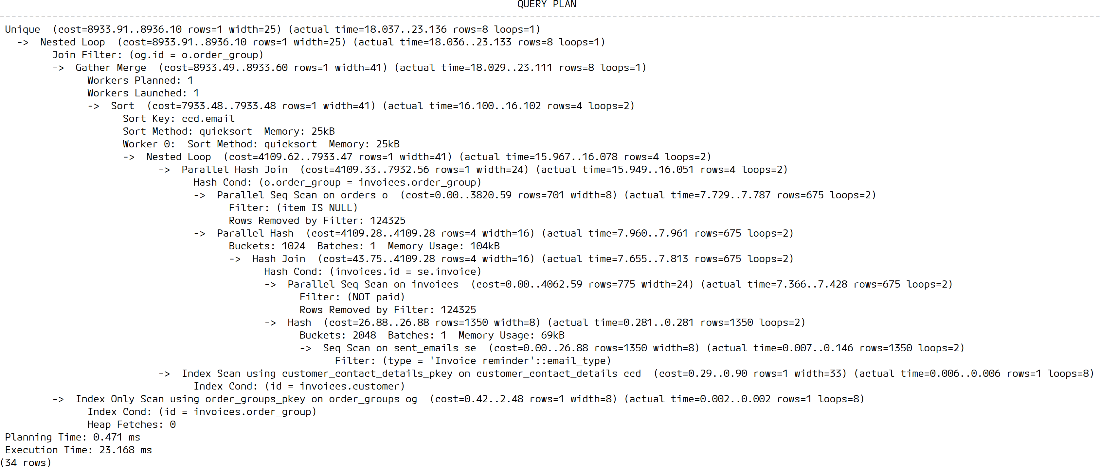
CTE query plan
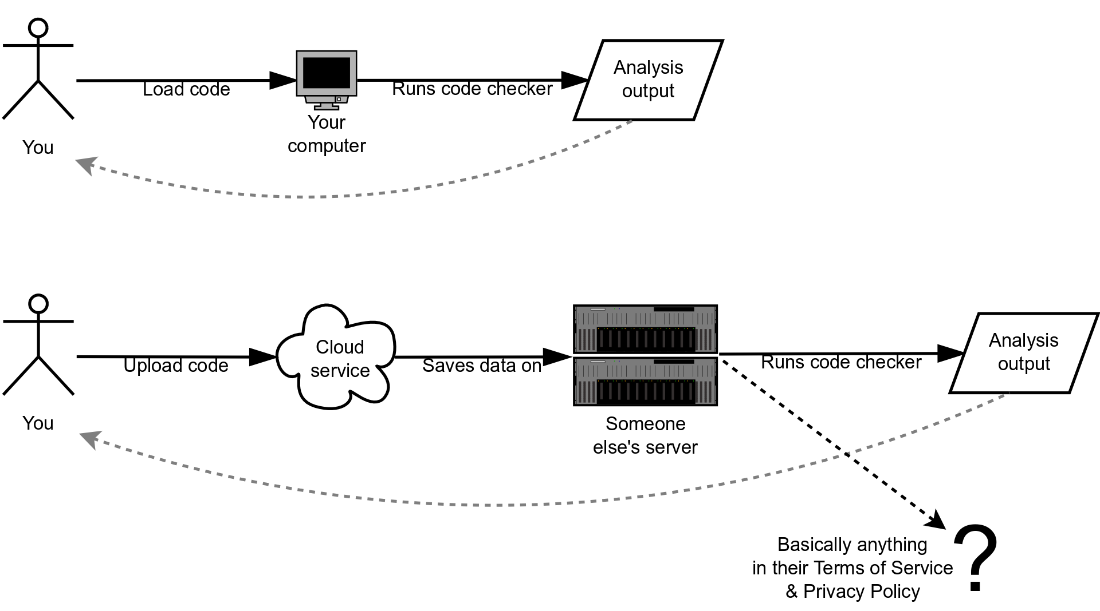
Your computer vs an online service
Summary
Don’t use NOT IN to exclude a list of values that can include even one null, because that will return an empty result set. Consider the use of NOT EXISTS.
Filtering with BETWEEN, for example between two timestamps, can return overlapping results in subsequent queries because its ranges are inclusive.
CTEs can not only improve readability of queries but also improve performance, by letting the optimizer decide to merge and reorder parts of the query.
Quoting identifiers makes them case-sensitive, while the Postgres convention is for all identifiers to be case-insensitive, and this can lead to reduced usability and errors.
Performing division between integers will yield an, often unexpected, truncated integer result.
count() ignores NULL values so if you count a nullable column, you won’t get the number of rows returned but the number of rows that didn’t have NULL in that field.
When you query indexed data that has had a data transformation applied to it, Postgres may not use the index at all.
Avoid using nullable columns in composite unique keys when possible. PostgreSQL 15 introduces NULLS NOT DISTINCT to address issues with upserts but you should probably use a cleaner design.
Don’t slow down your queries by selecting more than strictly necessary, and don’t fetch more data than you need to the application side — do your filtering and data management operations on the database side.
Use tools to check and lint your SQL for correctness and potential impacts to production, and take advantage of generative AI to make your work easier — but be aware of the limitations and always recheck and have the final say.
FAQ
Why can a NOT IN (subquery) filter return zero rows when I know matches exist?Because if the subquery returns even one NULL, the predicate x NOT IN (… NULL …) becomes unknown for every x and never evaluates to TRUE. In PostgreSQL, NULLs break NOT IN logic. Use NOT EXISTS or an anti-join instead, and explicitly handle NULLs when needed.What’s the safer and faster alternative to NOT IN (SELECT …)?Use an anti-join with NOT EXISTS or LEFT JOIN … WHERE right.side IS NULL. These forms produce correct results with NULLs and allow PostgreSQL to plan a Hash Anti Join (or similar), which is typically much faster than the hashed/plain subplans chosen for NOT IN.Why does BETWEEN on timestamps sometimes double-count boundary rows?BETWEEN is inclusive on both ends. For consecutive time windows (like “yesterday”), a value exactly at the upper bound (e.g., midnight) will be counted in both windows. Prefer half-open ranges: tstamp >= start AND tstamp < end.How do Common Table Expressions (CTEs) help with complex queries?CTEs improve readability by breaking queries into named steps and can be referenced multiple times. PostgreSQL can inline CTEs for optimization and you can force early evaluation with MATERIALIZED when it’s beneficial. They also make testing parts of a query easier.Why are quoted or uppercase identifiers a bad idea in PostgreSQL?PostgreSQL lowercases unquoted identifiers. Quoted identifiers are case-sensitive and must be quoted everywhere, causing errors and inconvenience. Prefer unquoted, lowercase names in schema objects. If you need “Pretty Column Names” for reports, use query aliases instead.Why did my percentage math come out as 0 when dividing integers?Integer division truncates toward zero in PostgreSQL. Cast at least one operand to a floating type (e.g., ::double precision) before dividing, then round as needed. Also guard against divide-by-zero with NULLIF and optionally COALESCE.Why does an index get ignored when I wrap the indexed column in a function?Expressions like func(indexed_column) prevent matching the index’s raw values, so PostgreSQL can’t use the index and may full-scan. Push transformations to the other side (rewrite as ranges like col >= a AND col < b), or create an expression index that exactly matches the function/cast you query with.Why doesn’t ON CONFLICT work when a composite unique key includes NULL?By default, NULLs are distinct, so rows that only differ by a NULL key column don’t conflict, leading to inserts instead of updates. From PostgreSQL 15, create the unique index with NULLS NOT DISTINCT to make upserts work as expected, or avoid NULL in the key (use a sentinel value or redesign).What’s wrong with SELECT * and filtering on the application side?It increases I/O, network transfer, memory usage, and time-to-first-result, and can block index-only scans by forcing table fetches. Always select only the needed columns and filter/sort in SQL so the planner can use optimal access paths.Which tools can help me avoid bad SQL mistakes?- Linters/formatters: SQLFluff for SQL style issues and common mistakes. - PL/pgSQL checker: plpgsql_check validates server-side functions with PostgreSQL’s parser. - Migration checker: squawk reviews DDL for risky operations. - LLMs: can inspire solutions, but verify with EXPLAIN and tests; be mindful of privacy and correctness.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!
 PostgreSQL Mistakes and How to Avoid Them ebook for free
PostgreSQL Mistakes and How to Avoid Them ebook for free