4 Designing reliable ML systems
This chapter presents a pragmatic path from ad‑hoc experimentation to reliable, production‑grade ML, emphasizing reproducibility, traceability, and consistent data/feature access. It assembles a “mini” ML platform around core responsibilities—experiment tracking, model versioning, feature management, deployment, and monitoring—so teams can collaborate safely, compare results rigorously, and promote models with confidence across environments. The narrative keeps a real‑world lens, showing how to stitch together focused tools into a coherent workflow that supports both batch and real‑time use cases while remaining flexible to project needs.
The workflow begins with exploratory analysis and iterative modeling, then formalizes it with MLflow for experiment tracking and model governance. Runs capture artifacts, datasets, parameters, and metrics; object storage backs dataset lineage; and autologging reduces boilerplate across libraries like scikit‑learn and XGBoost. With metrics centralized, the team can query past runs to select the best candidate and register it in the MLflow Model Registry, enabling versioned promotion (e.g., Staging to Production), reproducibility of training conditions, and clear answers to “what’s in production” and “how was it trained.”
To guarantee feature consistency across training and inference, the chapter introduces Feast as a feature store. Features are organized into entities and feature views, stored in an offline repository (e.g., files in MinIO) and materialized to an online store (e.g., Redis) for low‑latency lookups. Feast’s point‑in‑time joins, TTLs, and SDK/API access ensure reproducible training datasets and up‑to‑date online features, promoting reuse and collaboration. Rounding out the platform, the chapter situates batch inference with Kubeflow Pipelines, real‑time serving with BentoML, and drift monitoring with Evidently, laying a reliable foundation that can be automated and scaled in subsequent chapters.
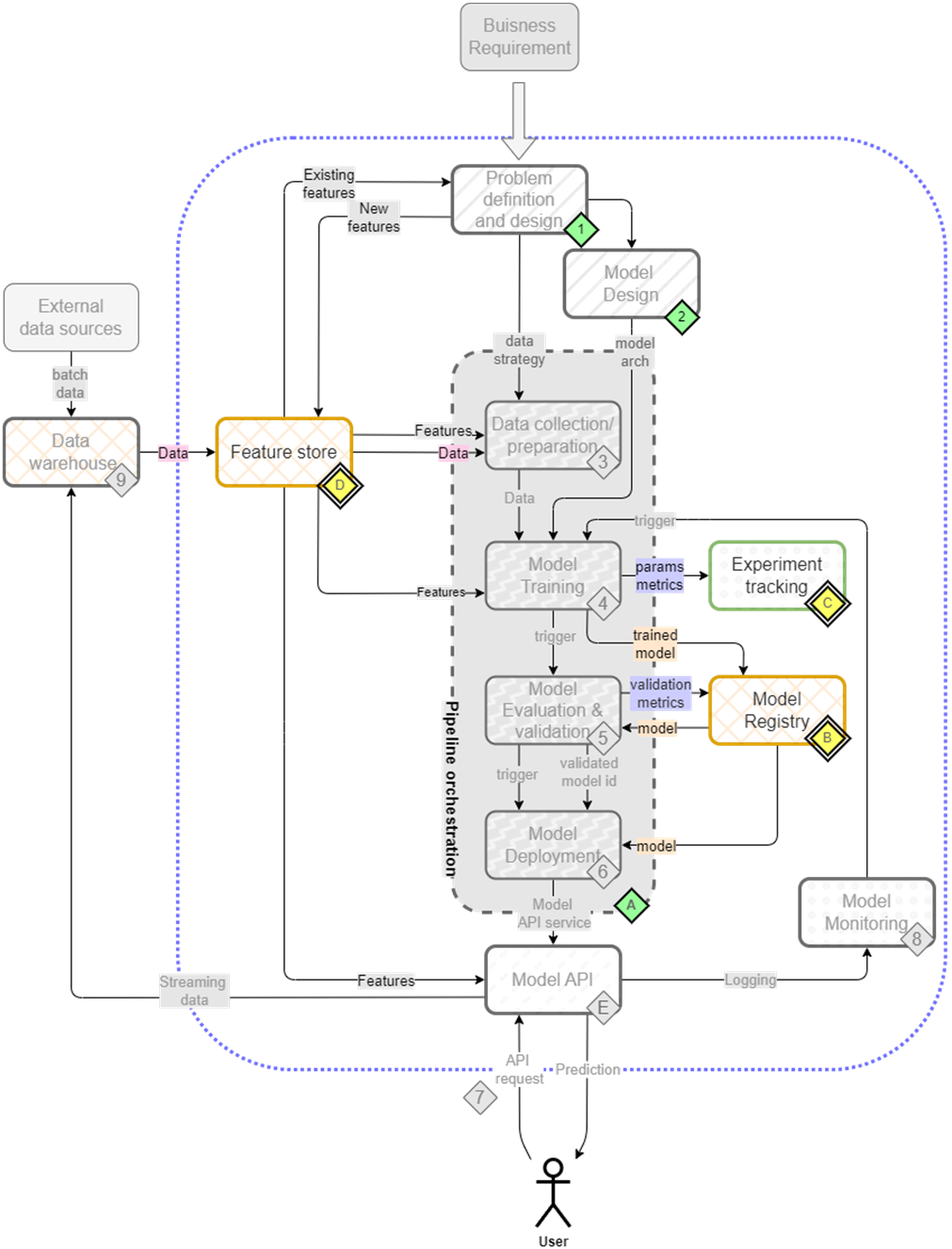
The mental map where we are now focusing on feature store(D), experiment tracking(C) and model registry(B).
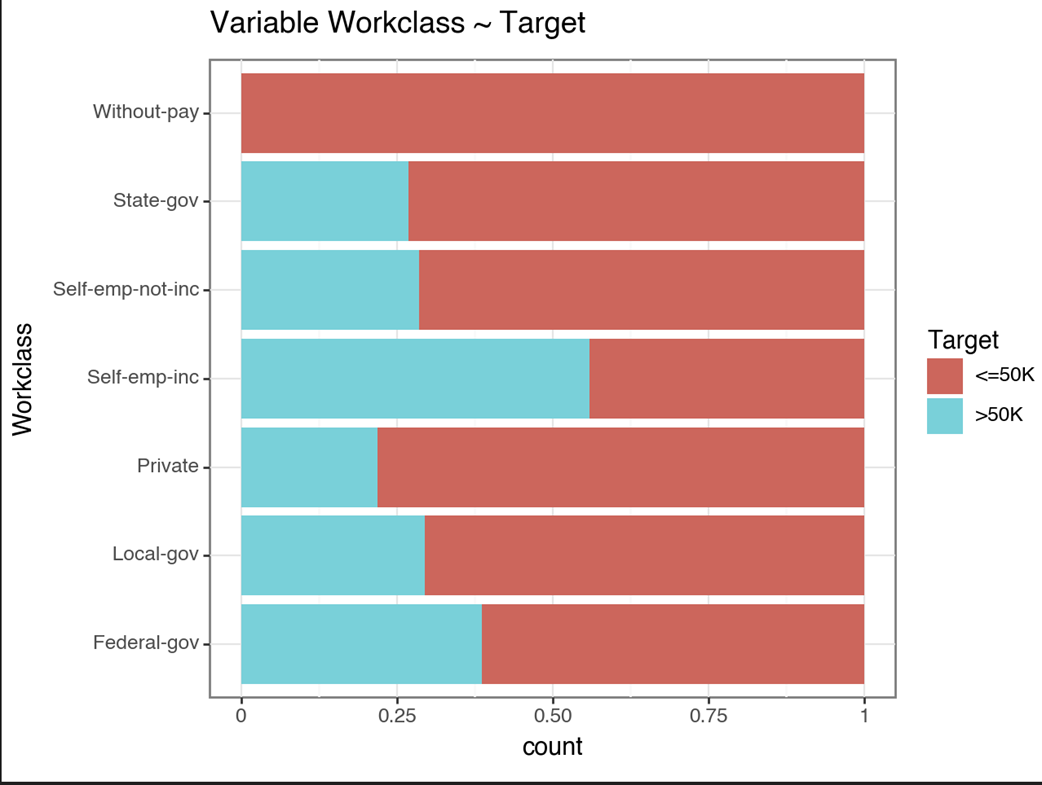
A plot comparing the workclass categories distribution with the target variable. For example self-employed people are more likely to be earning greater than 50k.
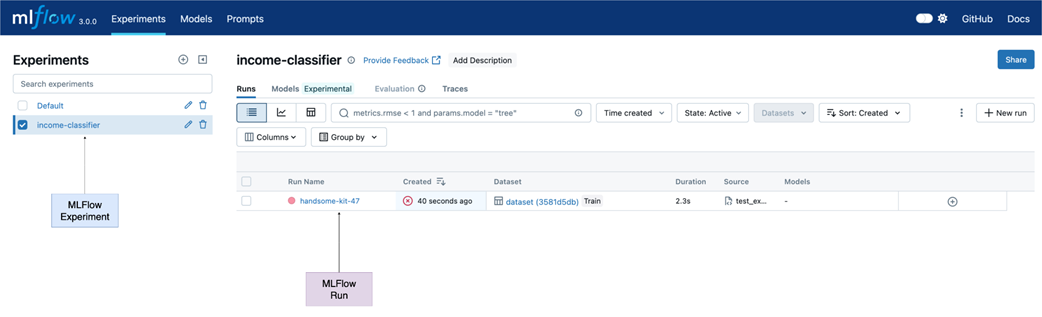
MLflow UI - On the left we have the list of experiments which shows our newly created income-classifier experiment. After starting a MLflow run and saving the plots we can see a new entry under Run Name.
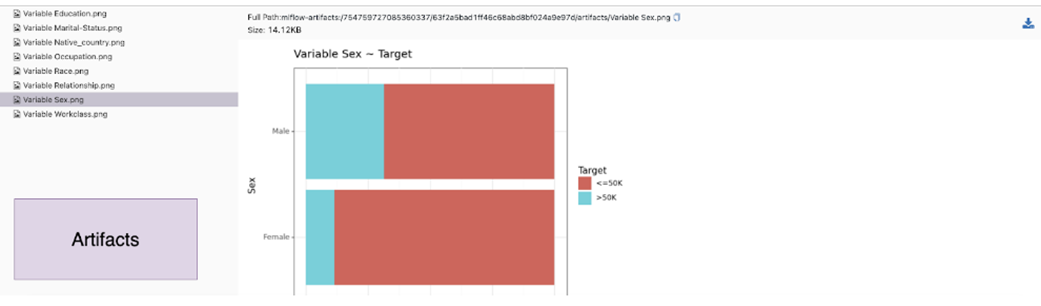
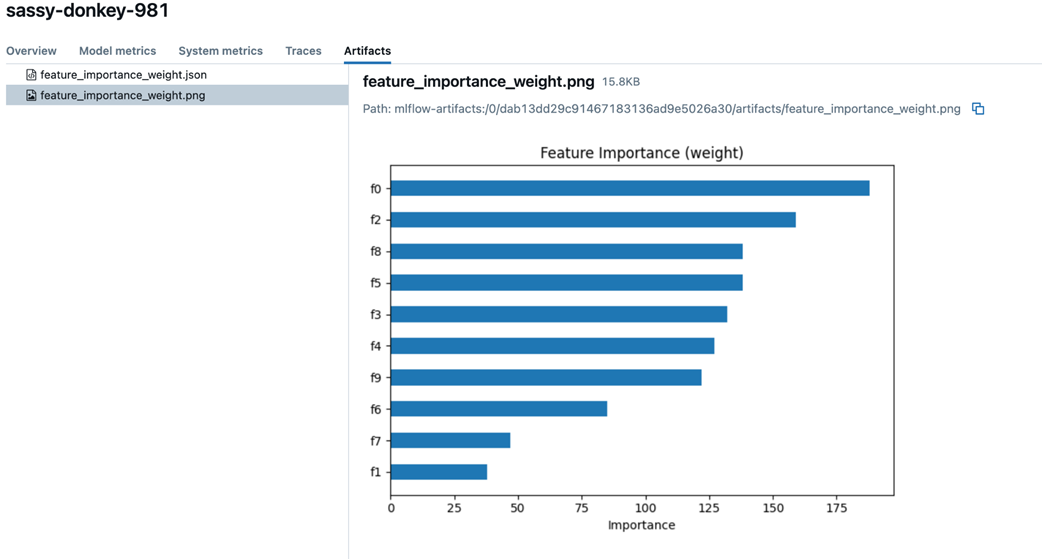
All the plots are present under artifacts. Run artifacts can include plots, files, and any object that can be saved on a disk.
The model metrics, and artifacts can all be seen under their respective tabs.
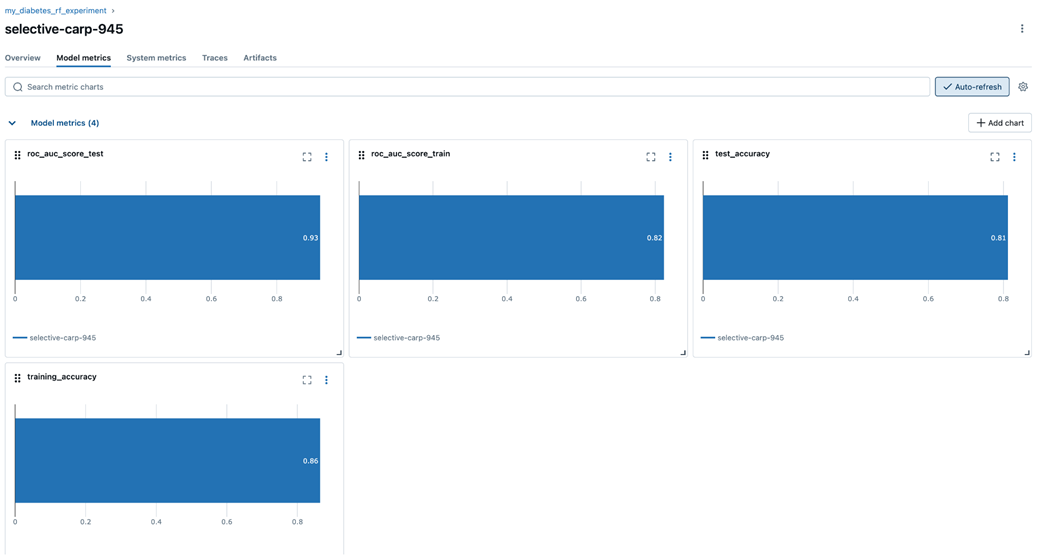
Auto-logging logs the model parameters and datasets without explicit logging. We even get feature importance plots automatically.
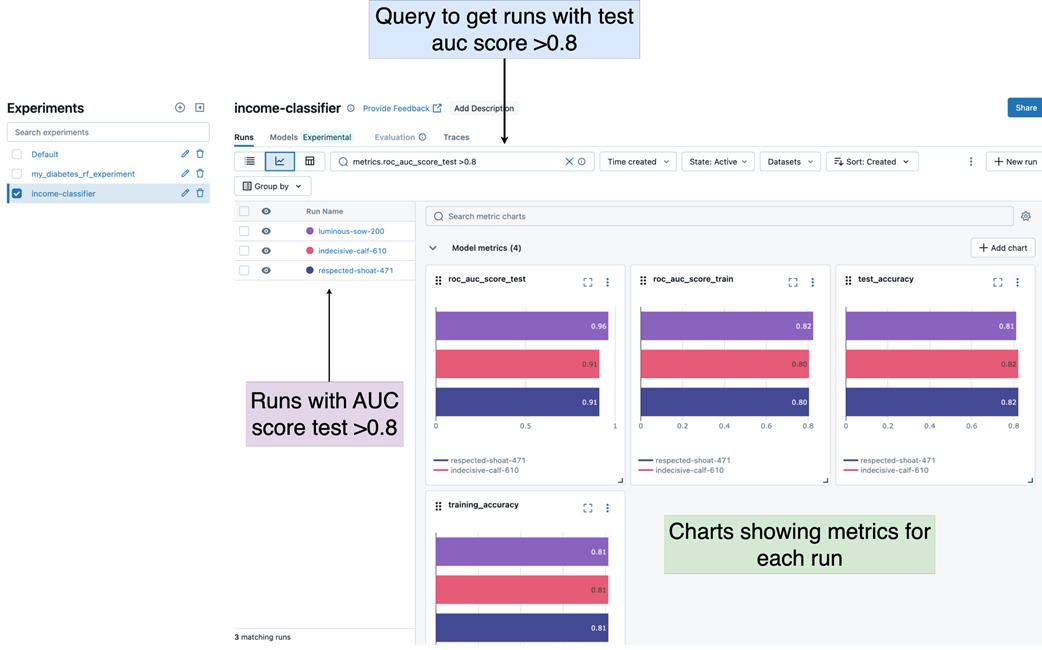
Using the MLflow UI to query runs that have a test AUC score < 0.8. Displaying the results in a chart view.
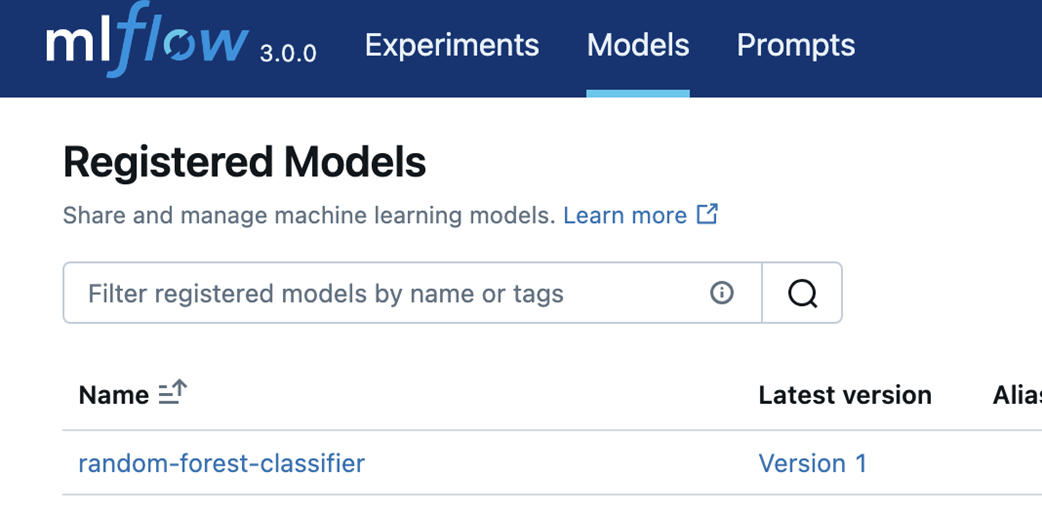
MLflow registered models can be seen under the models tab of the UI. Our Random Forest model can be seen here.
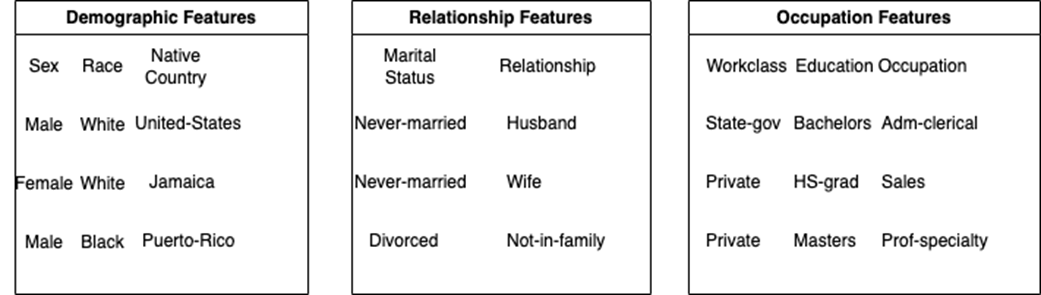
We split our single file into three files that represent three separate feature categories - demographic, relationship, and occupation.
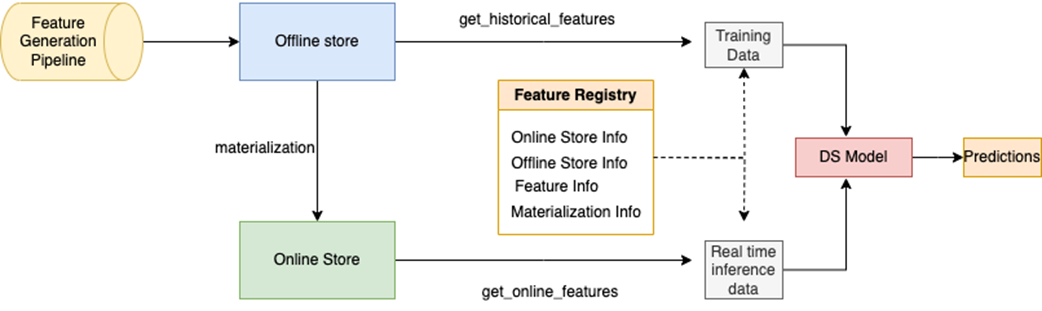
Feast feature store design involves a feature pipeline populating the offline store and periodically Feast materializes the offline features to the online store. Feature registry holds feature definitions along with online and offline store information. Feast SDK provides methods to retrieve features from online and offline stores which can be used for training and inference purposes.
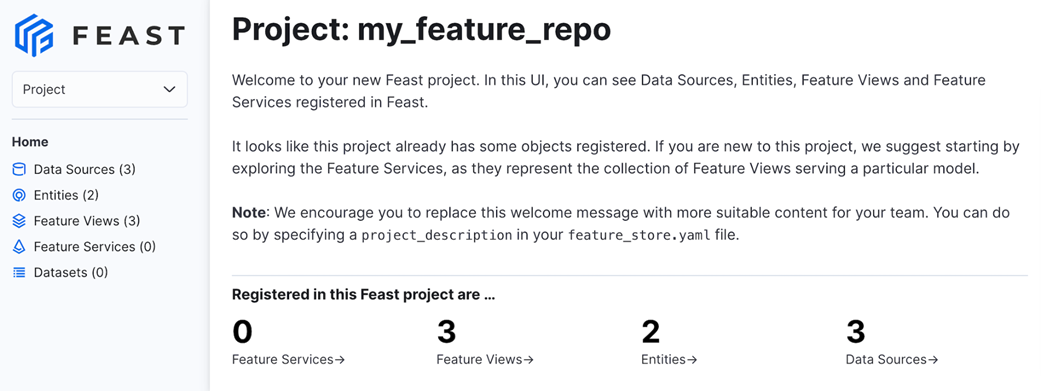
Feast UI gives us an easy way to visualize the details of feature views and entities for all our projects.
Summary
- An experiment tracker such as MLflow can be used for tracking model performance and hyperparameters during model training and evaluation
- MLflow Model Registry is a platform for managing, organizing, and versioning machine learning models, facilitating collaboration and deployment.
- Feast the feature store streamlines the management and sharing of curated, ready-to-use features for machine learning, enhancing model development and deployment.
- Feast enables point-in-time join to ensure the freshness of features at inference time
- Feast supports both historical feature retrieval using offline stores and low-latency retrieval using online stores.
 Machine Learning Platform Engineering ebook for free
Machine Learning Platform Engineering ebook for free