1 What Is Generative AI and Why PyTorch?
Generative AI has rapidly moved from research to mainstream since late 2022, reshaping workflows and creative processes across industries. This chapter sets the stage by clarifying what generative AI is, how it differs from non-generative (discriminative) systems, and why its ability to synthesize new text, images, audio, and more is so disruptive. It frames the core questions behind the technology’s mechanism and impact, then positions Python and PyTorch as the practical foundation for learning and experimentation throughout the book.
The chapter introduces the main families of models you will build: Generative Adversarial Networks (GANs) and Transformers, along with variational autoencoders and diffusion models. GANs pair a generator and a discriminator in a competitive loop to learn data distributions and produce convincing new samples, enabling tasks from image synthesis to style and attribute translation. Transformers, powered by the self-attention mechanism, handle sequences efficiently, capture long-range dependencies, and scale via parallel training—properties that underpin large language models and modern multimodal systems. Diffusion models and text-to-image pipelines illustrate how iterative refinement and conditioning unlock high-quality visual generation.
To make these ideas concrete, the book adopts a build-from-scratch approach using Python and PyTorch. PyTorch’s dynamic computation graph, clear syntax, GPU acceleration, and rich ecosystem make it well suited to rapid prototyping, transfer learning, and integration with familiar scientific libraries. By implementing models end to end, readers develop intuition for architectures, learn to control outputs (for example, selecting attributes through latent variables), and gain the skills to adapt or fine-tune pre-trained models for downstream tasks. This deeper understanding not only improves practical effectiveness but also equips readers to evaluate the capabilities and risks of generative AI with greater rigor and responsibility.
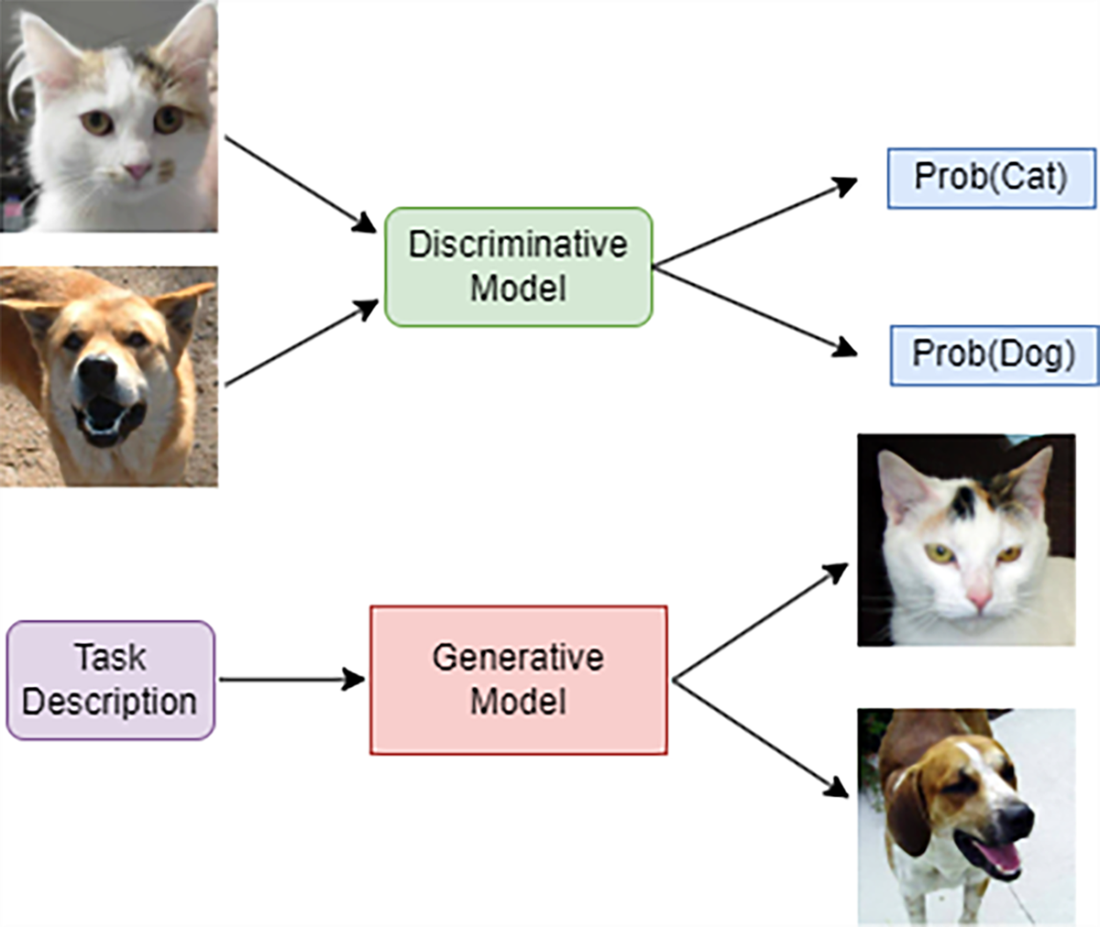
A comparison of generative models versus discriminative models. A discriminative model (top half of the figure) takes data as inputs and produces probabilities of different labels, which we denote by Prob(dog) and Prob(cat). In contrast, a generative model (bottom half) acquires an in-depth understanding of the defining characteristics of these images to synthesize new images representing dogs and cats.
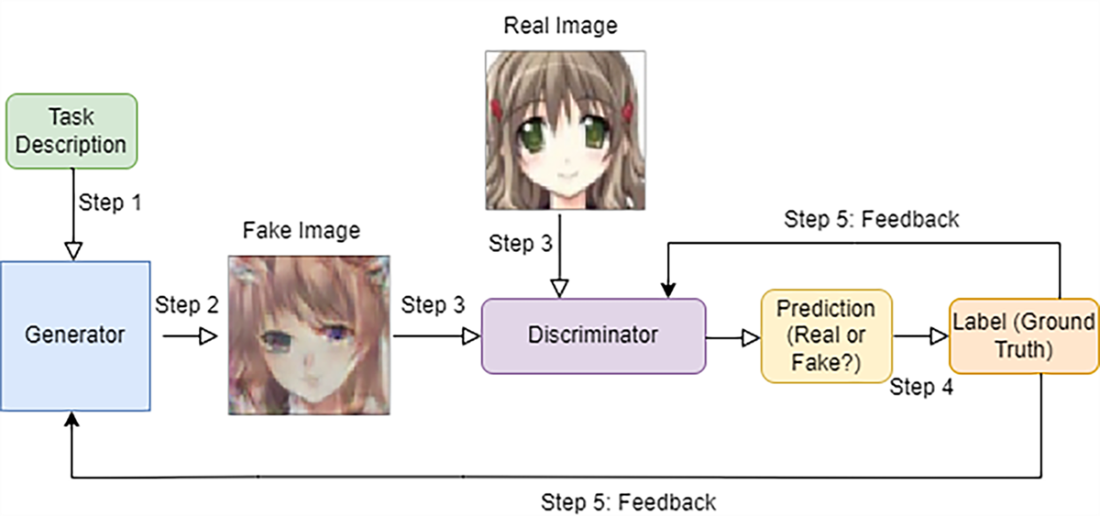
Generative Adversarial Networks (GANs) architecture and its components. GANs employ a dual-network architecture comprising a generative model (left) tasked with capturing the underlying data distribution and a discriminative model (center) that serves to estimate the likelihood that a given sample originates from the authentic training dataset (considered as "real") rather than being a product of the generative model (considered as "fake").
Examples from the Anime faces training dataset.

Generated Anime face images by the trained generator in DCGAN.

Changing hair color with CycleGAN. If we feed images with blond hair (first row) to a trained CycleGAN model, the model converts blond hair to black hair in these images (second row). The same trained model can also convert black hair (third row) to blond hair (bottom row).

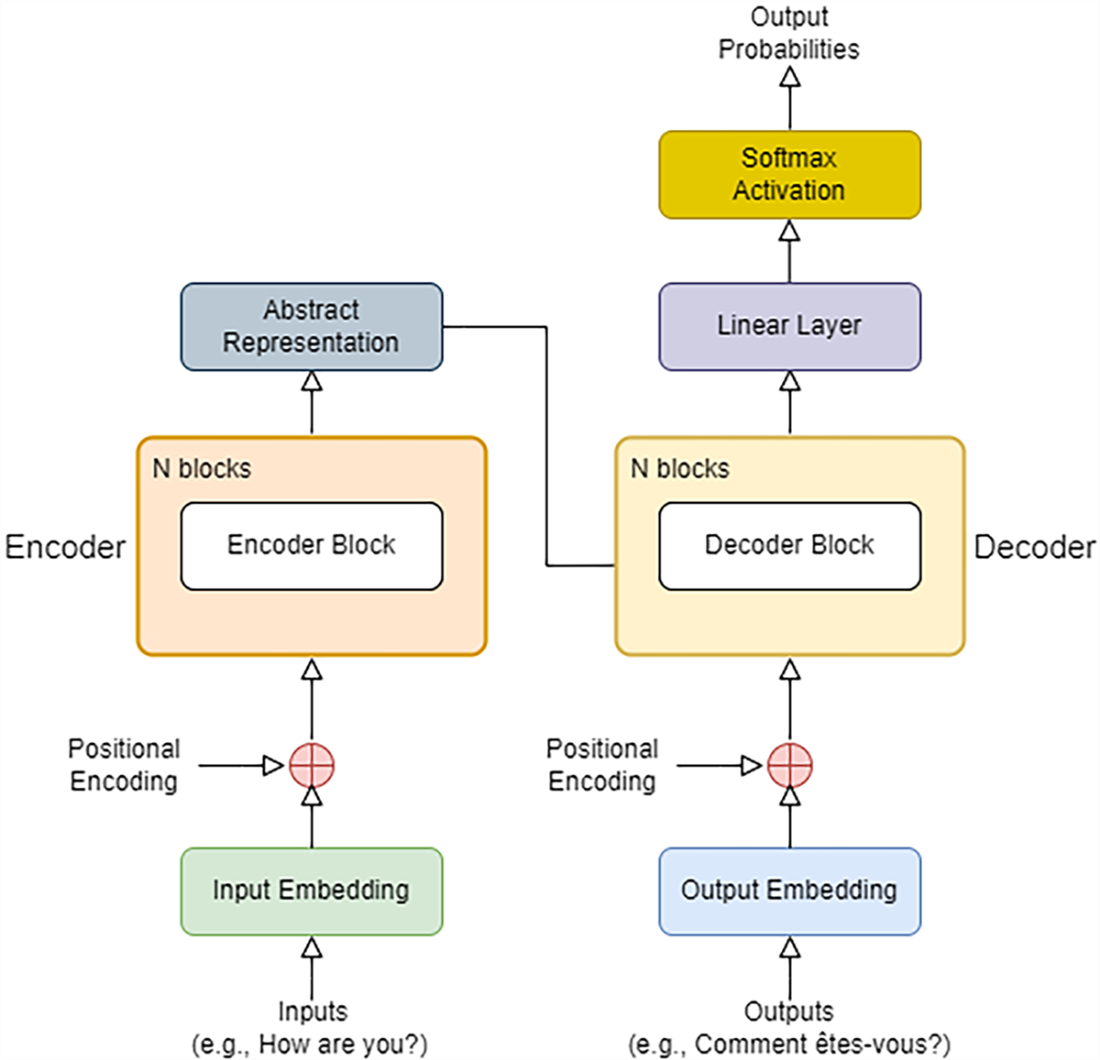
The Transformer architecture. The encoder in the Transformer (left side of the diagram) learns the meaning of the input sequence (e.g., the English phrase “How are you?”) and converts it into an abstract representation that captures its meaning before passing it to the decoder (right side of the diagram). The decoder constructs the output (e.g., the French translation of the English phrase) by predicting one word at a time, based on previous words in the sequence and the abstract representation from the encoder.
The diffusion model adds more and more noise to the images and learns to reconstruct them. The left column contains four original flower images. As we move to the right, some noise is added to the images in each step, until at the right column, the four images are completely noisy images. We then use these images to train a diffusion-based model to progressively remove noise to generate new data samples.

Image generated by DALL-E 2 with text prompt “an astronaut in a space suit riding a unicorn”.

Summary
- Generative AI is a type of technology with the capacity to produce diverse forms of new content, including texts, images, code, music, audio, and video.
- Discriminative models specialize in assigning labels while generative models generate new instances of data.
- PyTorch, with its dynamic computational graphs and the ability for GPU training, is well suited for deep learning and generative modeling.
- GANs are a type of generative modeling method consisting of two neural networks: a generator and a discriminator. The goal of the generator is to create realistic data samples to maximize the chance that the discriminator thinks they are real. The goal of the discriminator is to correctly identify fake samples from real ones.
- Transformers are deep neural networks that use the attention mechanism to identify long-term dependencies among elements in a sequence. The original Transformer has an encoder and a decoder. When it’s used for English-to-French translation, for example, the encoder converts the English sentence into an abstract representation before passing it to the decoder. The decoder generates the French translation one word at a time, based on the encoder’s output and the previously generated words.
 Learn Generative AI with PyTorch ebook for free
Learn Generative AI with PyTorch ebook for free