7 AI and Advanced Data Transformations
This chapter moves from data quality to advanced data transformations that are common in production pipelines, arguing that AI can serve as a unifying, conversational interface to reduce tool sprawl and context switching. It surveys four transformation domains—complex text parsing, hierarchical/nested data handling, entity resolution, and time series/date-time work—showing each first with traditional code and then with AI-driven, schema-enforced workflows. Across examples, the pattern is consistent: define the target structure (for example with Pydantic), provide clear task instructions, and let the model generate structured outputs, while maintaining rigor through validation and testing.
For text processing, the chapter demonstrates how regex can reliably extract fields from messy logs but demands specialized syntax knowledge and breaks under shifting formats; an AI alternative can generate or bypass regex altogether to return structured fields, provided you enforce schemas and guard against pitfalls like hallucinated fields, incorrect patterns, inconsistent outputs, and overfitting to examples. Handling nested JSON likewise contrasts manual flattening logic with a model that maps directly to a declared class, making schema evolution simpler: change the class, not the parsing code. The overarching guidance is to pair AI’s flexibility with strong output constraints and validation, treating the model as a junior engineer whose work must be checked.
Entity resolution highlights the limits of traditional fingerprinting and fuzzy matching—useful but opaque—versus an AI approach that produces a best match with confidence and explicit reasoning, contingent on well-designed prompts that encode business rules and feature weighting. Time series transformations show how timezone conversion, custom fiscal calendars, business-day due dates, and contribution percentages are achievable with pandas but require domain-specific functions and care; the AI pattern streamlines this with a consistent loop and response schema, plus minimal precomputation (such as account totals). A capstone lab combines these skills on messy CRM and transactions data to parse text, flatten nested structures, resolve duplicates, compute time-based metrics, and assemble golden records for downstream B2B analysis.
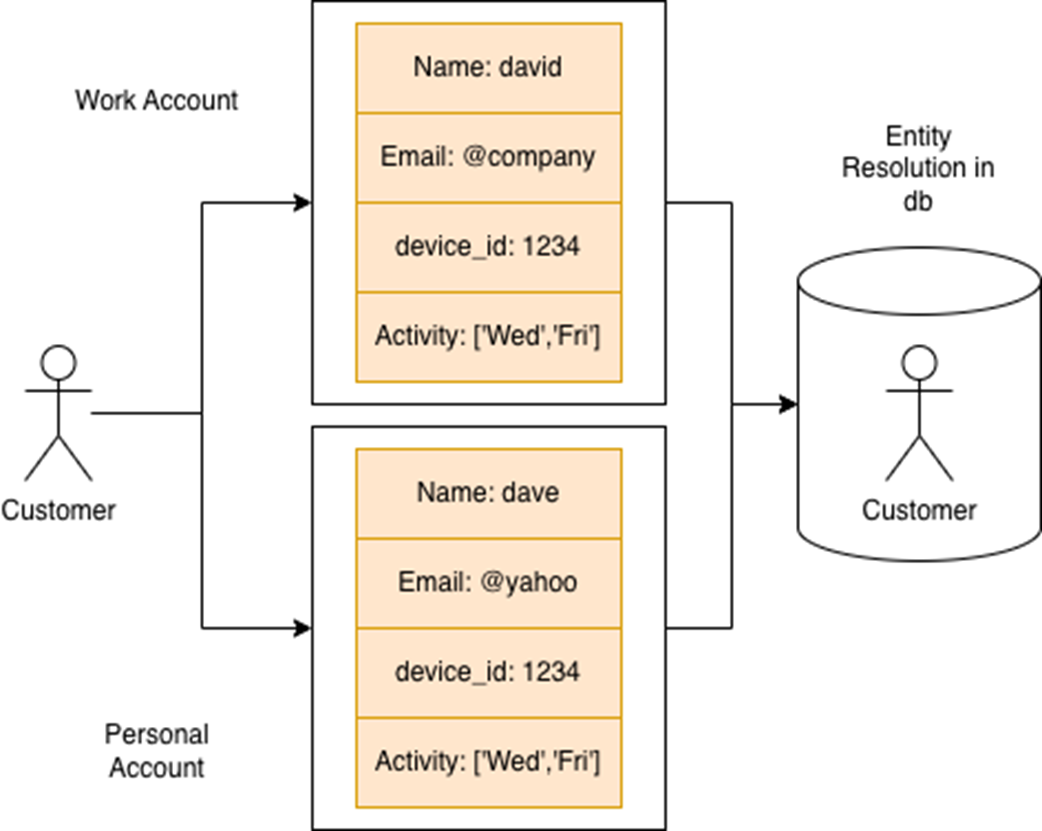
A single user appears under two separate accounts—one personal, one professional. Despite differences in name and email domain, shared signals like device ID and activity reveal an underlying connection. Entity resolution helps unify these records to build a complete view of the customer.
Lab Answers
Refer to the Chapter 7 Lab Jupyter Notebook for full answers.
1. Flattening Nested JSON with AI
The AI approach uses structured response parsing to extract nested data reliably:
This approach handles schema changes gracefully—if new nested fields are added, you simply update the prompt and data class without rewriting complex extraction logic.
2. Complex Text Processing with AI
AI excels at parsing messy text formats that would require complex regex patterns:
The AI approach adapts to format variations automatically and can handle new subscription types like ENTERPRISE3xHYBRID without code changes.
3. AI-Powered Entity Resolution
Instead of rule-based matching, AI performs sophisticated entity resolution by considering multiple factors:
The AI evaluates each customer against all others, providing confidence scores and detailed reasoning for matches. This handles edge cases like nickname variations and email format differences that rule-based systems often miss.
4. Time Series Transformations with AI
AI handles complex date-time transformations and business logic:
The AI correctly handles timezone conversions, business day calculations, and custom fiscal calendars without requiring complex date manipulation libraries.
5. Extra Credit: Build a Golden Account List
AI creates comprehensive B2B account profiles by analyzing combined customer and transaction data:
This produces actionable B2B intelligence by synthesizing customer demographics, spending patterns, and engagement metrics into prioritized account lists.The key advantage of the AI approach throughout this lab is adaptability—as data formats change, new subscription types are added, or business rules evolve, you update prompts rather than rewriting complex parsing and transformation logic. This makes AI-driven data engineering pipelines more maintainable and scalable for production environments.
FAQ
What is the main focus of Chapter 7 and why use AI for advanced transformations?
Chapter 7 tackles real-world transformations that go beyond basic cleaning: complex text parsing (logs with regex), nested/hierarchical data (JSON), entity resolution, and time-series/date-time work. Traditionally this requires many tools and bespoke code. AI offers a conversational, schema-driven alternative that reduces context switching and adapts as formats change—often with less code and added explainability.When should I use traditional regex vs. an AI-driven approach for log parsing?
- Use regex when formats are stable, performance must be predictable, and you can precisely define patterns (e.g., r"(ERROR|INFO|WARNING)\s(\d{4}-\d{2}-\d{2})\s(\d{2}:\d{2}:\d{2})").- Use AI when formats vary across sources, edge cases abound, or you need to evolve fields rapidly without maintaining many patterns. AI shines when combined with a schema to enforce consistent outputs and when you want natural-language tweaks instead of regex rewrites.
How do I extend the AI log extraction (Listing 7.2) to include the message text?
1) Add message: Optional[str] to the LogExtraction model.2) Update the prompt to instruct the model to extract the text after the timestamp as message.
3) Rerun the loop; verify structured outputs contain log_type, date, time, and message. This leverages schema enforcement to keep results consistent across lines.
How does schema-enforced structured output reduce AI variability?
By defining a Pydantic model and passing it as the response format, the model is steered to return a strict shape (fields, types, and nullability). This mitigates inconsistent formats, prevents extra fields, and makes parsing deterministic. If the model deviates, parsing raises an error you can catch, log, and retry, improving reliability in pipelines.What pitfalls should I watch for with AI-based extraction and how do I mitigate them?
- Hallucinated fields: Enforce a strict schema, instruct “only extract fields present,” and validate post-hoc.- Incorrect patterns/assumptions: Provide examples for all log levels and date formats; include negative examples when possible.
- Inconsistent outputs: Use response schemas, keep prompts explicit and concise, set temperature low.
- Overfitting to examples: Include diverse samples and add instructions about variability. Always validate against a test set.
What’s the trade-off between flattening nested JSON with pandas vs. using an AI schema mapping?
- pandas/json_normalize or custom loops: Fast and explicit, but requires intimate knowledge of the structure, manual edge-case handling, and code rewrites as schemas evolve.- AI with a data class (e.g., LibraryBook): Less code for traversal/mapping, easier to evolve—update the class and prompt. You still attach shared attributes (e.g., library_name) and validate outputs via the model/schema.
How should I design prompts for entity resolution so results are reliable and explainable?
Specify: the task, all fields to consider (names, emails, device_id, IP, language), how to weigh them (e.g., “salesforce_id is canonical; prioritize email domain over IP”), how to treat ambiguity, and require an output schema with confidence and a short reasoning string. This yields traceable decisions and tunable behavior without rewriting code.Can I combine fuzzy matching and AI to improve entity resolution?
Yes. A practical pattern is a two-stage workflow: 1) Candidate generation with fast heuristics/fuzzy scores (e.g., RapidFuzz on normalized fingerprints) to shortlist records; 2) Send the shortlist plus instructions to the AI for final selection with reasoning and confidence. This improves speed, reduces cost, and increases accuracy and explainability.What are common gotchas in time series transformations and how does AI help?
- Time zones and DST: Convert from UTC to required zones carefully; verify offsets around DST changes.- Business-day math: Use BusinessDay calendars; document whether holidays apply.
- Fiscal calendars: Custom quarters must be encoded consistently (e.g., Q1=Feb–Apr).
- AI can compute these from instructions when provided with clear definitions, but you should include examples, enforce schemas, and cross-check a sample against a canonical Python implementation.
How should I operationalize this chapter’s workflows (env, dependencies, testing)?
- Dependencies: Use ch07/requirements.txt; pin versions for reproducibility.- Secrets: Load API keys via .env and environment variables; never hardcode.
- Testing/validation: Create golden test sets; validate AI outputs against Pydantic models; add unit tests for regex and date logic.
- Throughput/costs: Batch requests, reuse context sparingly, set rate limits/retries. Log prompts/outputs for observability and drift detection.
 Learn AI Data Engineering in a Month of Lunches ebook for free
Learn AI Data Engineering in a Month of Lunches ebook for free