14 Ask a KG with natural language
This chapter presents a practical blueprint for asking a knowledge graph with natural language by emulating expert behavior rather than relying solely on Retrieval-Augmented Generation. Using a law enforcement scenario, it motivates why domain experts need direct, intuitive access to KGs and sets out a framework with four pillars: detecting and routing user intent, extracting and enriching schema/metadata for LLM use, applying expert-like reasoning to construct precise queries, and transforming raw results into concise, actionable summaries. The approach is integration-first, designed to feed a front-end that can render graphs, tables, charts, or maps, and to deliver clear textual explanations alongside visual outputs.
The chapter explains where RAG breaks down in complex, high-stakes settings: answers hinge on retrieval completeness and granularity, and missing or fragmented context can flip conclusions. It proposes a shift from “generating an answer” to “asking the right question,” translating user intent into schema-aware, constrained traversals that mirror how experts query graphs (for example, mapping natural language to specific nodes, relationships, and filters). To do this reliably, the system classifies intent both by desired presentation (graph/table/chart/map) and by request type (data-related, system documentation, schema questions, or feedback), using simple, debuggable prompts that can evolve from a single broad classifier to multi-stage routing as needs grow.
To enable expert emulation, the system converts a technical database schema into a concise, conceptual, LLM-ready representation and enriches it with annotations (terminology, codes, relationship semantics) managed via a YAML configuration for skipping noise and adding descriptions. Query generation is then guided by a structured, reasoning-first prompt: the model lists intended relationships, writes out its plan, and produces a Cypher statement that follows the annotated schema, optionally incorporating current user selections and execution error feedback to iterate. Finally, a summarization component turns graph results into focused narratives (and light analysis when requested), filtering out incidental data and complementing the visual interface. The result is a robust, domain-aware question-answering workflow that scales beyond policing to any field where expert reasoning over complex graph structures is essential.
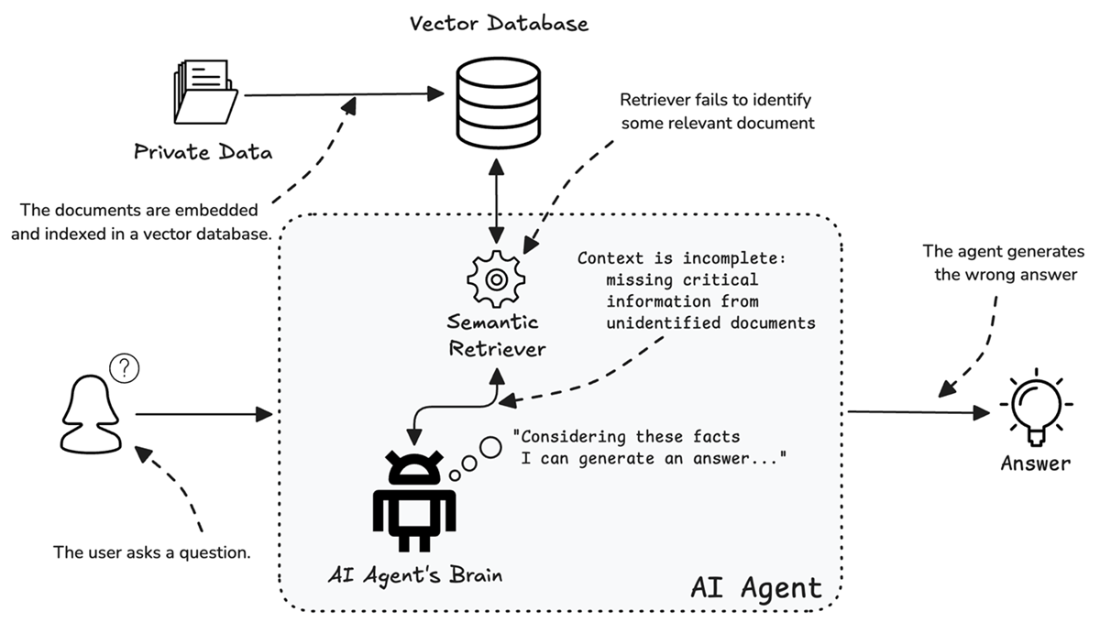
RAG System Limitations. The diagram illustrates how a RAG system can produce incorrect answers when the retriever fails to identify critical documents.
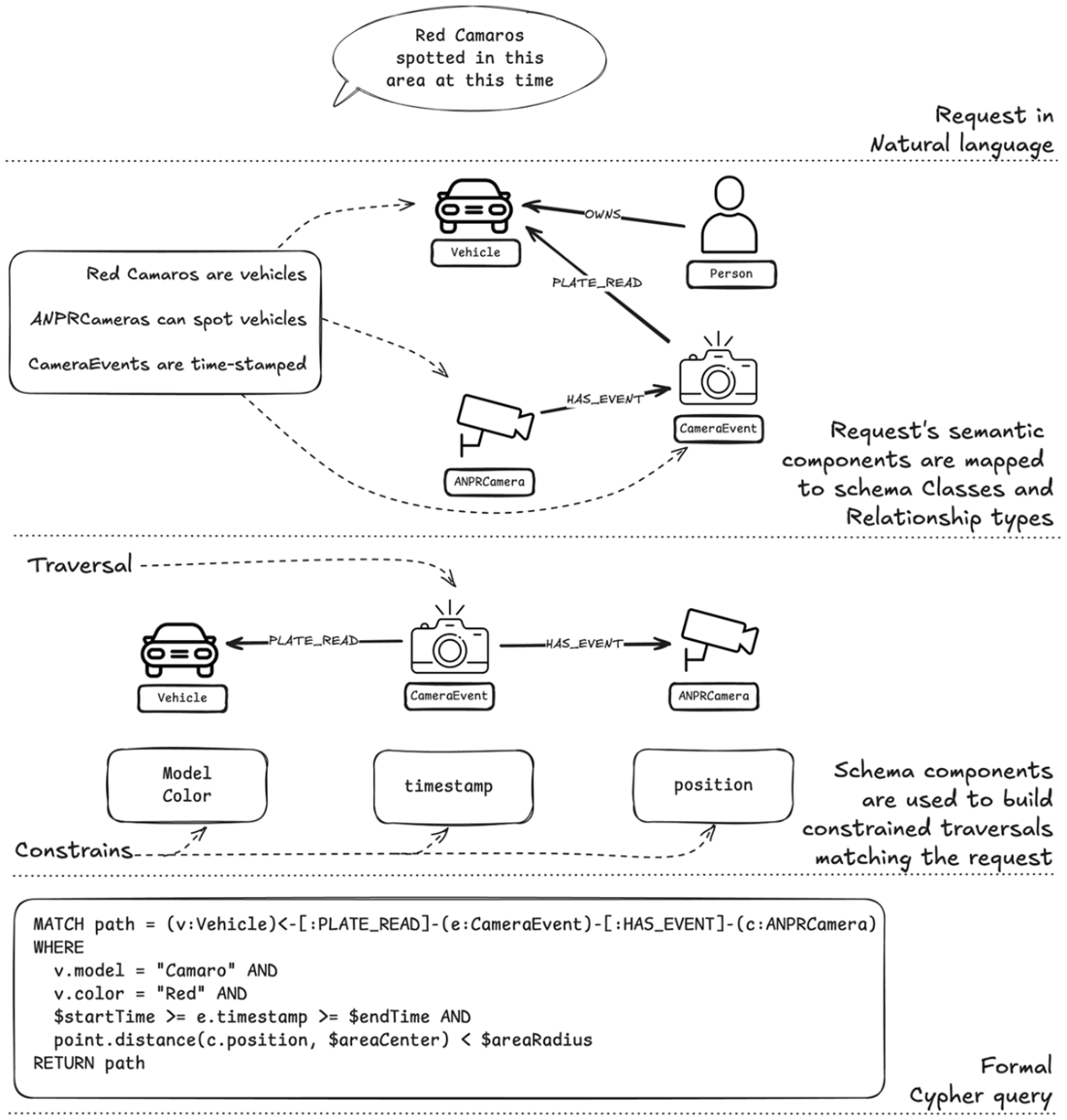
Translation Process from Natural Language to Cypher Query. This diagram illustrates the step-by-step process of translating a natural language query ("Red Camaros spotted in this area at this time") into a formal Cypher query. The translation occurs through three main stages: (1) parsing the natural language request into semantic components, (2) mapping these components to schema elements (Vehicle, CameraEvent, and ANPRCamera nodes with their relationships), and (3) constructing a formal Cypher query with the appropriate traversal patterns and constraints. The diagram shows how domain concepts are systematically transformed into graph database operations, demonstrating the bridge between user intent and executable queries.
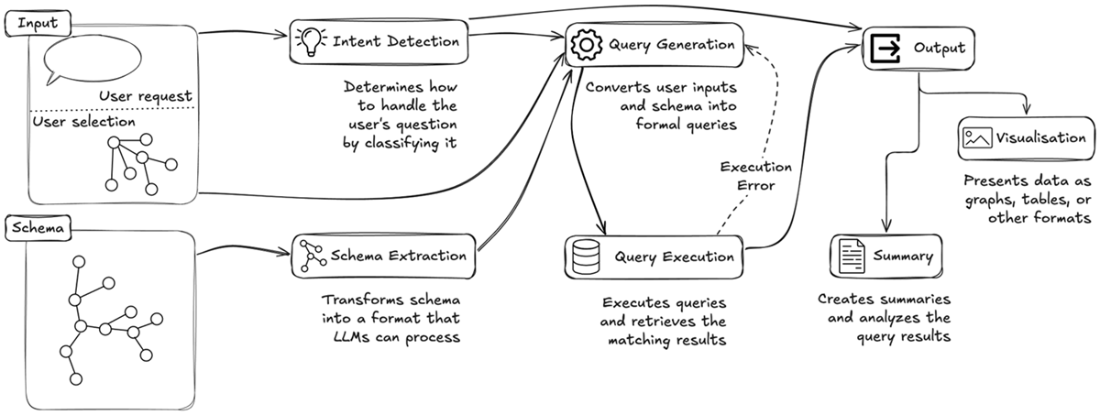
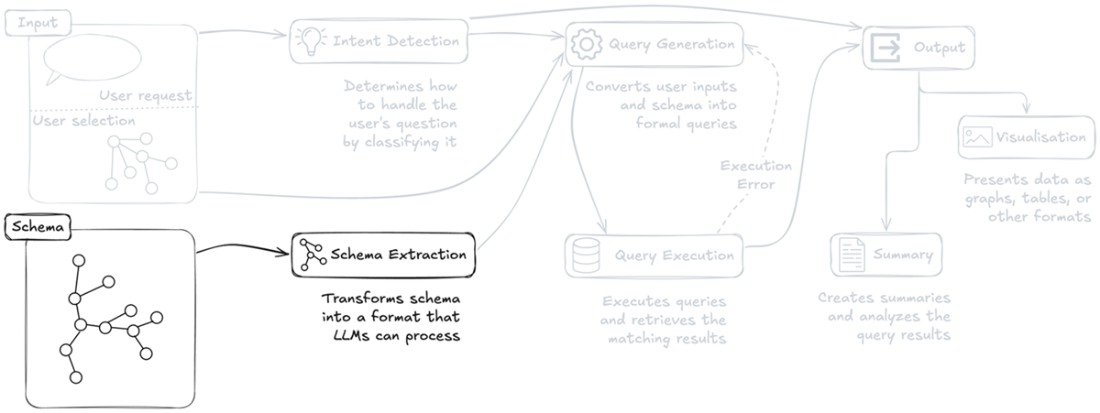
Overview of the system highlighting the main components: Intent Detection, Schema Extraction, Query Generation, Query Execution, Visualization and Summary generation. The system processes user questions and selection inputs, while supporting error feedback during query execution.
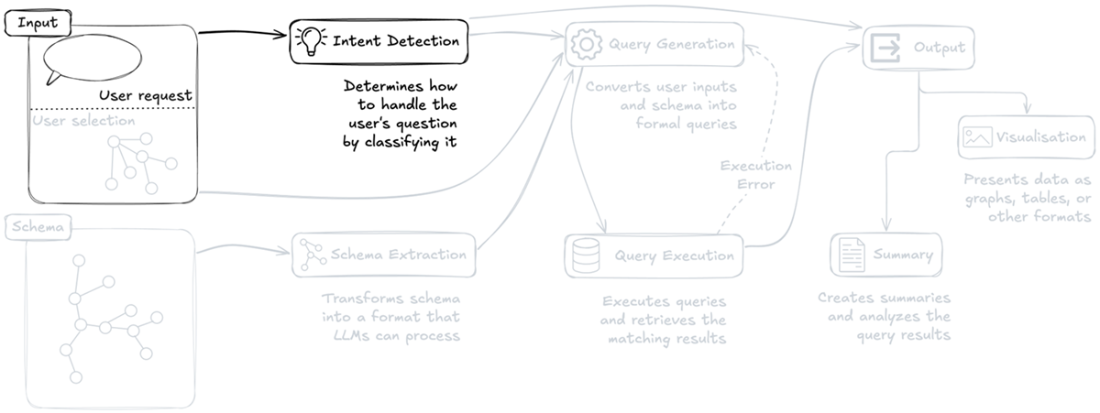
The Intent Detection component analyzes user inputs to determine how to appropriately handle and classify the user's question, representing the first critical step in the request processing.
Intent detection system architecture for data visualization requests, showing how user requests are mapped to appropriate visualization formats (graph, chart, table, or map).
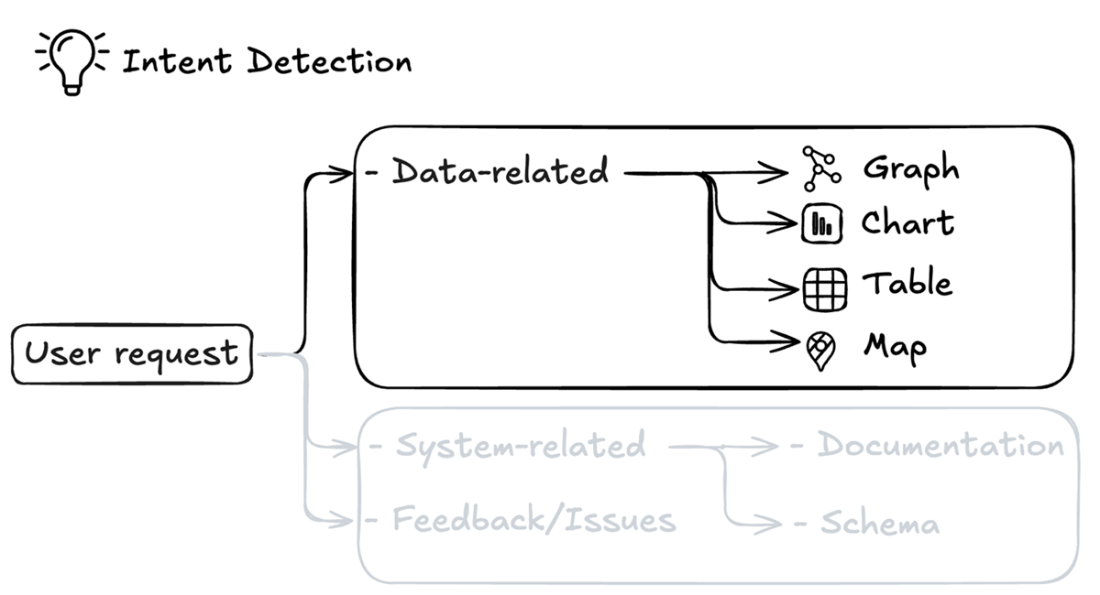
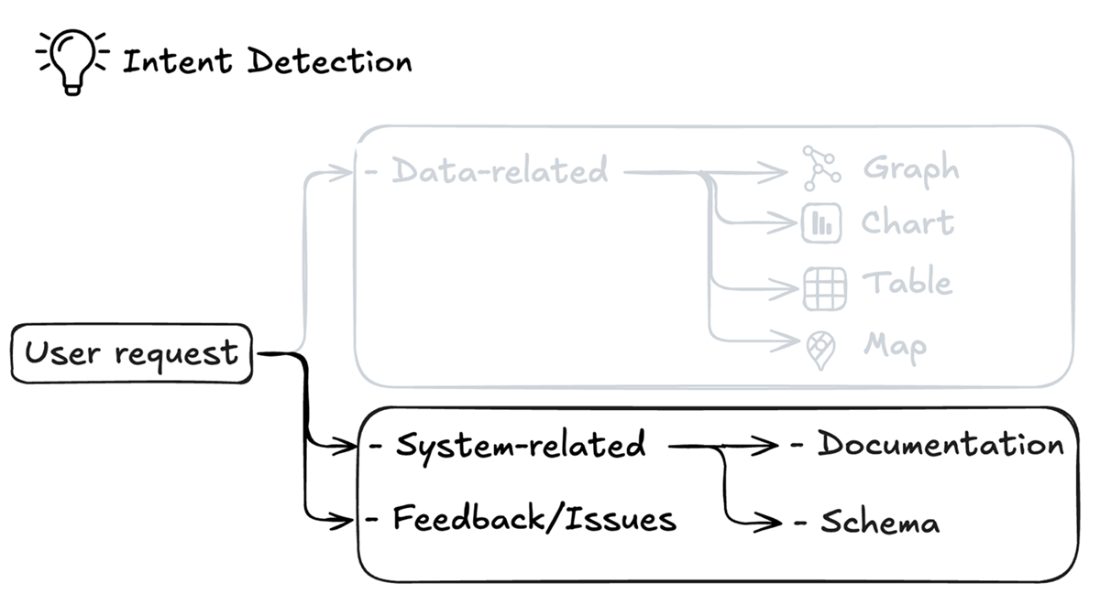
Classification of system-related questions in the intent detection system, showing how requests are routed to either documentation (for system functionality and feature questions) or schema (for knowledge graph structure queries). The system also identifies feedback and issues as a separate category for user complaints or enhancement requests.
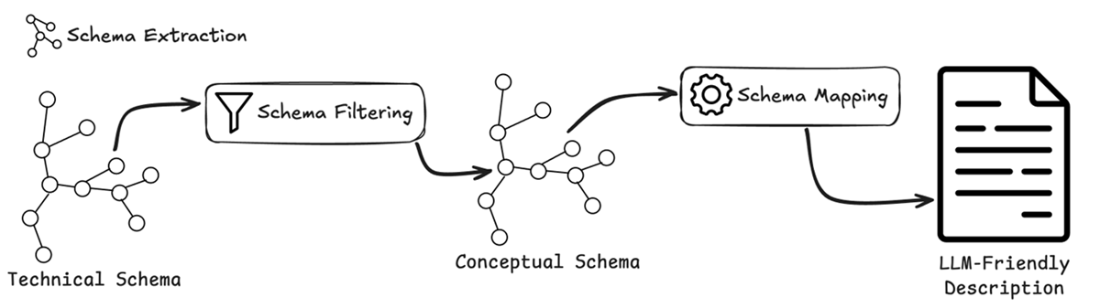
Schema processing pipeline, highlighting the transformation of database schema into LLM-compatible formats. The diagram illustrates how raw schema structures are processed through Schema Extraction to create representations that LLMs can effectively process.
The technical schema obtained through APOC call is filtered so it is reduced to the conceptual graph schema representation. The conceptual schema is then mapped into a textual format that can be effectively understood by LLMs.
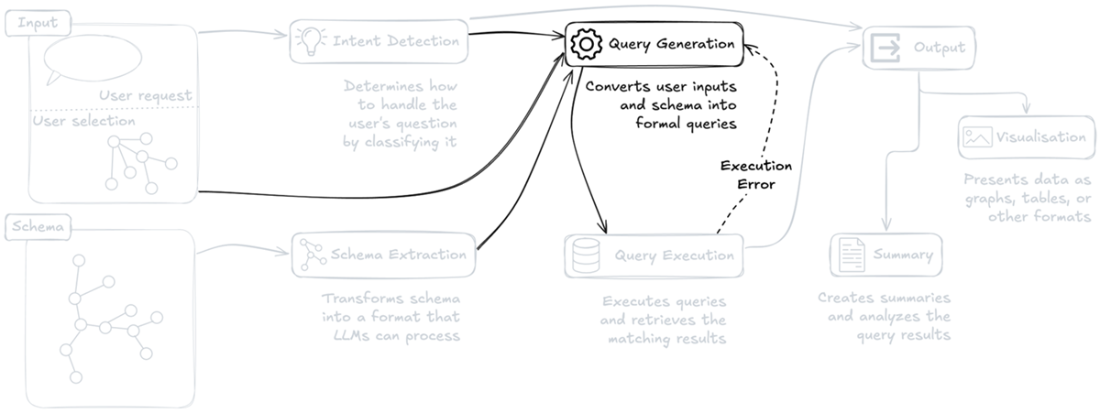
Query Generation stage of the system architecture, highlighting its central role in converting user inputs and schema information into formal database queries.
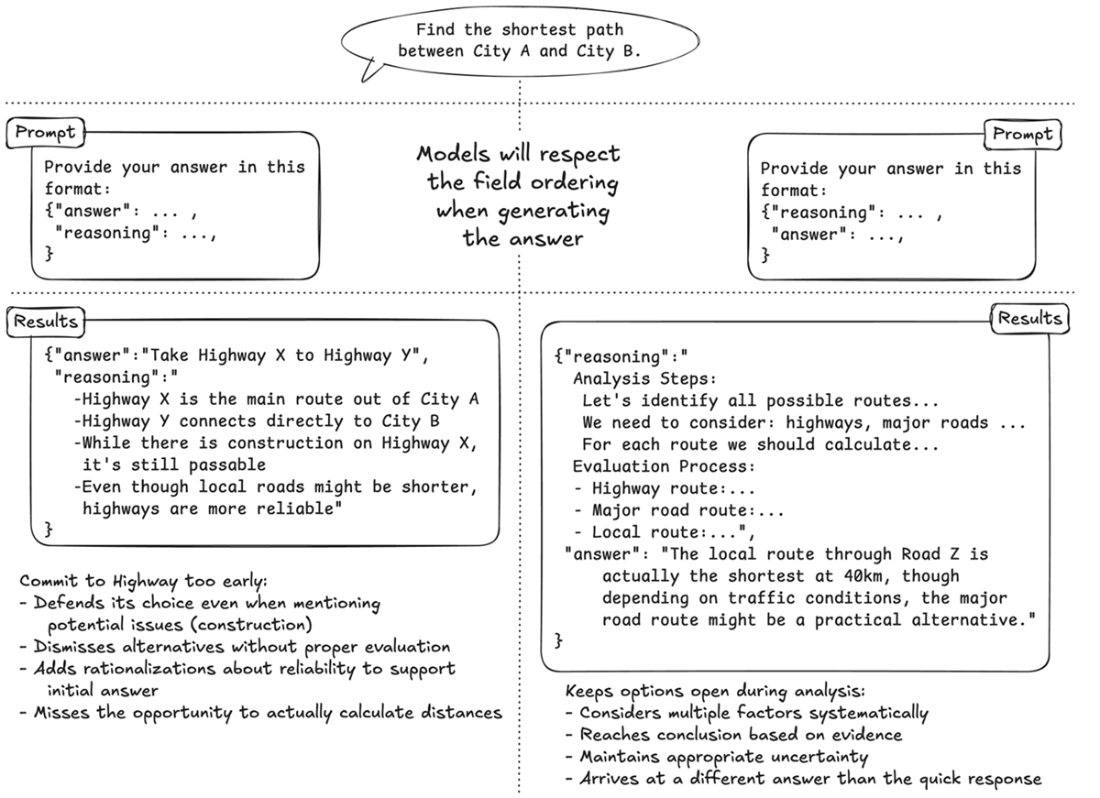
Comparison of two prompt structures for the same path-finding task. Left: The Answer-First approach encourages quick, potentially biased responses with post-hoc justification. Right: The Reasoning-First approach promotes systematic analysis before reaching a conclusion. Note how the JSON structure in each prompt guides the LLM's thinking process.
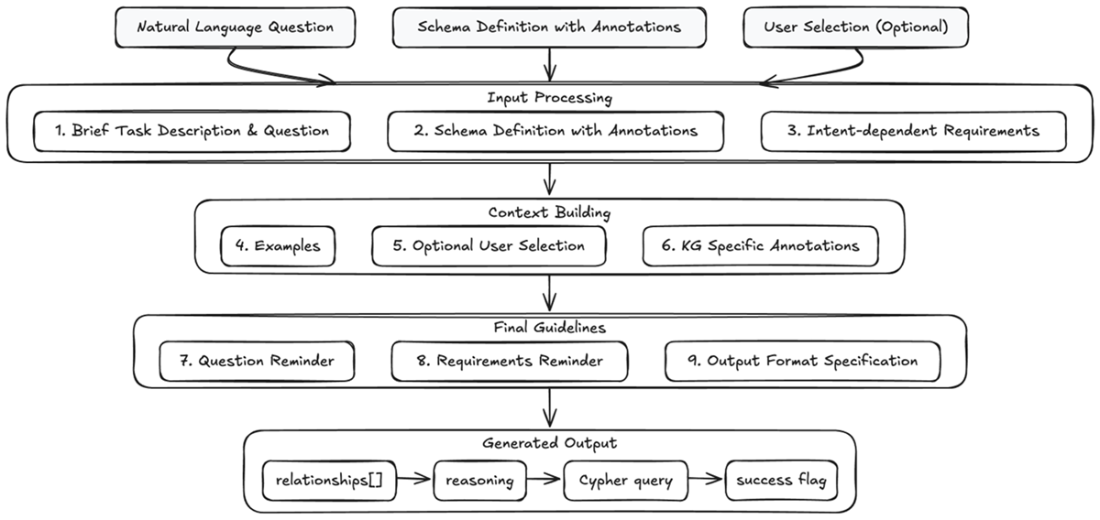
Query Generation Pipeline. The diagram illustrates the complete flow of transforming a natural language question into a Cypher query, showing how three inputs are processed through structured prompt components. The process is organized into three main stages (Input Processing, Context Building, and Final Guidelines) that culminate in a structured JSON.
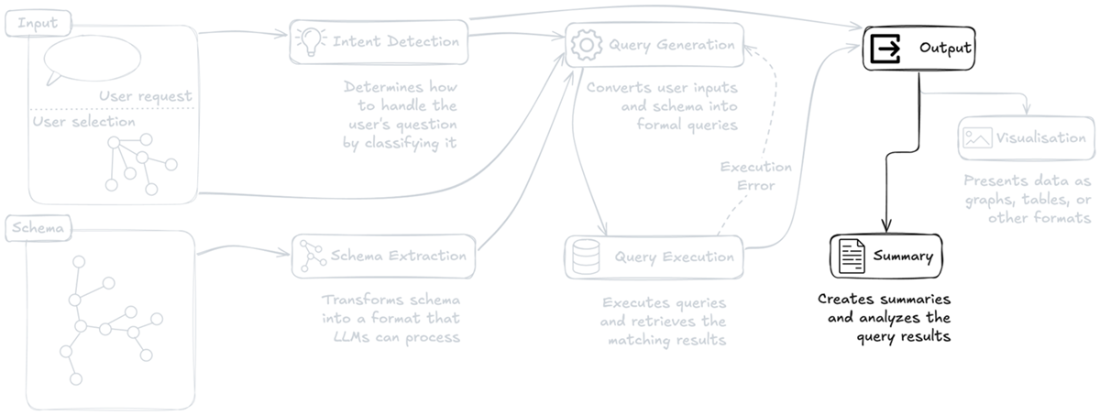
Output generation pipeline, highlighting the system's final stages of data presentation and analysis. The diagram shows how processed query results are transformed into both visual presentations and analytical summaries, demonstrating the dual output approach of visualization and summarization of query results.
Summary
- Expert emulation provides a systematic framework for building, improving and extending knowledge graph systems. When facing any challenge - whether implementing new features, fixing issues, or enhancing existing capabilities - we can find solutions by asking "what would an expert do?" and breaking down their approach into implementable steps.
- A well-structured intent detection system requires two layers of classification. The first layer handles broader query categories (data-related, system-related, feedback) while the second identifies the visualization needs.
- Converting technical database schemas into LLM-friendly formats involves more than just reformatting - it requires carefully filtering unnecessary elements, adding contextual annotations, and structuring information in ways that align with how LLMs process and understand data.
- Prompt engineering for LLMs requires giving them "time to think." This means structuring prompts to encourage reasoning before answers and using techniques like chain-of-thought prompting to improve response quality and reliability.
- Query generation prompts need several key elements to work effectively: comprehensive schema context, current user selection state, intent-specific requirements, and carefully chosen examples that demonstrate desired patterns.
- Result summarization works best as a complement to visualization. Rather than repeating what's visible in the graph, effective summaries highlight insights and patterns that might not be immediately apparent visually.
- Neo4j APOC Library: apoc.meta.schema https://neo4j.com/docs/apoc/current/overview/apoc.meta/apoc.meta.schema/
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., & Zhou, D. (2023). "Chain of Thought Prompting Elicits Reasoning in Large Language Models." arXiv:2201.11903
- Nye, M., Andreassen, A. J., Gur-Ari, G., Michalewski, H., Austin, J., Bieber, D., Dohan, D., Lewkowycz, A., Bosma, M., Luan, D., Sutton, C., & Odena, A. (2021). "Show Your Work: Scratchpads for Intermediate Computation with Language Models." arXiv:2112.00114
- Raj, H., Gupta, V., Rosati, D., & Majumdar, S. (2023). "Semantic Consistency for Assuring Reliability of Large Language Models." arXiv:2308.09138
FAQ
What are the main limitations of RAG when answering complex questions on a knowledge graph?
RAG is only as good as its retriever. If key passages are missed or too coarse/fine-grained, the LLM receives fragmented context and can produce confident but wrong answers. Answers often span multiple documents, some relevant docs may not contain the explicit answer, and even the omission of a single critical piece (like one witness statement) can flip conclusions. These issues are amplified in KG tasks that require understanding relationships and constraints.How does the expert-emulation approach differ from traditional RAG?
Instead of “generating an answer,” it focuses on “asking the right question.” It translates natural language into precise graph traversals by:- Understanding the graph schema and mapping domain concepts to entities, relationships, and constraints
- Mimicking expert reasoning patterns for query construction
- Leveraging metadata/annotations to disambiguate terms
- Producing formal Cypher queries and presenting results meaningfully via the UI
Why start with intent detection, and how are intents classified?
Intent detection routes requests to the right pipeline and output format, improving relevance and visualization. Two layers are common:- Visualization type: graph (default), table (aggregations/stats), chart (distributions), map (locations)
- Broader categories: Data-Related; System-Related (Documentation-Related or Schema-Related); Feedback/Complaints
What is a conceptual schema, and why prefer it over the raw technical schema (e.g., apoc.meta.schema)?
A conceptual schema filters out helper/admin nodes, internal/unused properties and relationships, and redundant labels to keep only domain-relevant entities and connections. Benefits:- Aligns with human/LLM reasoning
- Reduces cognitive load and hallucinations
- Minimizes query errors from implementation details
- Improves interpretability and mapping from NL to Cypher
How should a schema be represented so an LLM can use it effectively?
Use a concise, consistent, LLM-friendly text format:- List nodes with key properties and types
- List relationships with direction and property types
- Add inline comments describing semantics, codes, and constraints
- Optionally drive generation via a YAML config to skip irrelevant elements and inject descriptions
Which annotations/metadata help prevent query errors?
Descriptive annotations clarify how data is encoded and how relationships should be used, e.g.:- Value encodings (e.g., Vehicle.color uses BLK, GRY, SIL, WHI)
- Relationship semantics (COMMITTED vs CO_OFFENDS_WITH)
- Property meanings and formats (dates, IDs, geospatial)
How do you structure the prompt to generate reliable Cypher queries?
Use a structured, reusable prompt that includes:- Task definition and the user question
- LLM-friendly, annotated schema
- Intent-dependent requirements (graph/table/chart/map)
- Few-shot examples aligned to the output format
- Optional current selection from the UI
- Graph-specific notes/annotations
- Reminder of the question (and prior error messages if retrying)
- Strict JSON output schema: relationships (to traverse), reasoning (scratchpad), query (Cypher), success (bool)
Why ask for reasoning before the final answer, and what techniques help?
LLMs tend to post-hoc justify early answers due to semantic consistency. Requesting step-by-step reasoning first (Chain-of-Thought, scratchpad) encourages deliberation and reduces biased or rushed conclusions. Listing potential relationships to traverse before query generation further curbs hallucinations and aligns the final Cypher with the schema.How does the system integrate with a front-end and choose visualizations?
Intent detection selects the presentation:- Graph: return nodes and relationships (avoid anonymous relationships; aggregate traversals)
- Table: select and rename properties for tabular display
- Chart: support distributions/aggregations
- Map: include locations/geometry for GIS views
What is the purpose of the summarization step, and how is it prompted?
Summarization turns raw query results into actionable insights that complement the visual graph. The prompt:- Provides the original question, executed query, results, and (optionally) current selection
- Instructs the model to filter irrelevant path details and keep factual, question-relevant points
- Asks whether analysis is requested; if yes, include brief insights
- Returns strict JSON with results_analysis (bool), reasoning, and a concise summary
 Knowledge Graphs and LLMs in Action ebook for free
Knowledge Graphs and LLMs in Action ebook for free