5 Misuse and adversarial attacks: Challenges and responsible testing
Since large language models became widely accessible, their strengths and weaknesses have been exposed in equal measure. This chapter surveys how generative AI can be intentionally abused and unintentionally misapplied, why models hallucinate, and why it is hard to reliably constrain behavior in open-ended systems. It emphasizes a layered response that combines technical safeguards, rigorous testing, and user education: aligning models to be more truthful, teaching them to express uncertainty or seek sources, and systematically stress-testing them through red teaming. The central message is that safer, more resilient AI requires both better models and better practices for how people build, deploy, and rely on them.
Intentional misuse spans cybersecurity, social engineering, and influence operations. Models can accelerate malware authoring, reconnaissance, and phishing, enable polished spear‑phishing at scale, and assist deepfake-enabled vishing and impersonation. Attackers also subvert guardrails via jailbreaking and prompt injection—including cross‑model bypasses and indirect injections hidden in external data—while criminal ecosystems market uncensored models and use AI to industrialize scams, extortion, and ransomware operations. Beyond cybercrime, generative tools amplify adversarial narratives and political manipulation, from fabricated media to persona-driven persuasion, exploiting the “liar’s dividend” to erode trust. Supply‑chain risks (like package hallucination and slopsquatting) and data poisoning further widen the attack surface. Defensive efforts—policy, provenance standards, detection and moderation, architectural isolation, and user training—help, but the landscape remains a fast-moving cat‑and‑mouse game.
Unintentional misuse centers on hallucinations and overreliance in high‑stakes domains. Because LLMs predict tokens rather than verify facts, they can produce confident falsehoods, fail to challenge faulty premises, and struggle to convey uncertainty—problems that become acute in law, medicine, and finance, where fabricated citations or plausible but wrong advice carry real harms. Mitigations include reinforcement learning for truthfulness and refusal, retrieval‑augmented generation with source citation, self‑consistency checks, careful prompting, temperature control, and emerging methods to quantify correctness. Red teaming complements benchmarks by proactively probing models with attacker mindsets—manually and at scale—to surface vulnerabilities in system prompts, context, and user inputs. Mitigations range from prompt and policy hardening to external classifiers and fine‑tuning, paired with monitoring for both intentional and accidental misuse. The chapter closes with a call for shared accountability: developers must set expectations and document limits; organizations must keep humans in the loop; and users must verify outputs—treating LLMs as powerful assistants, not unquestioned authorities.
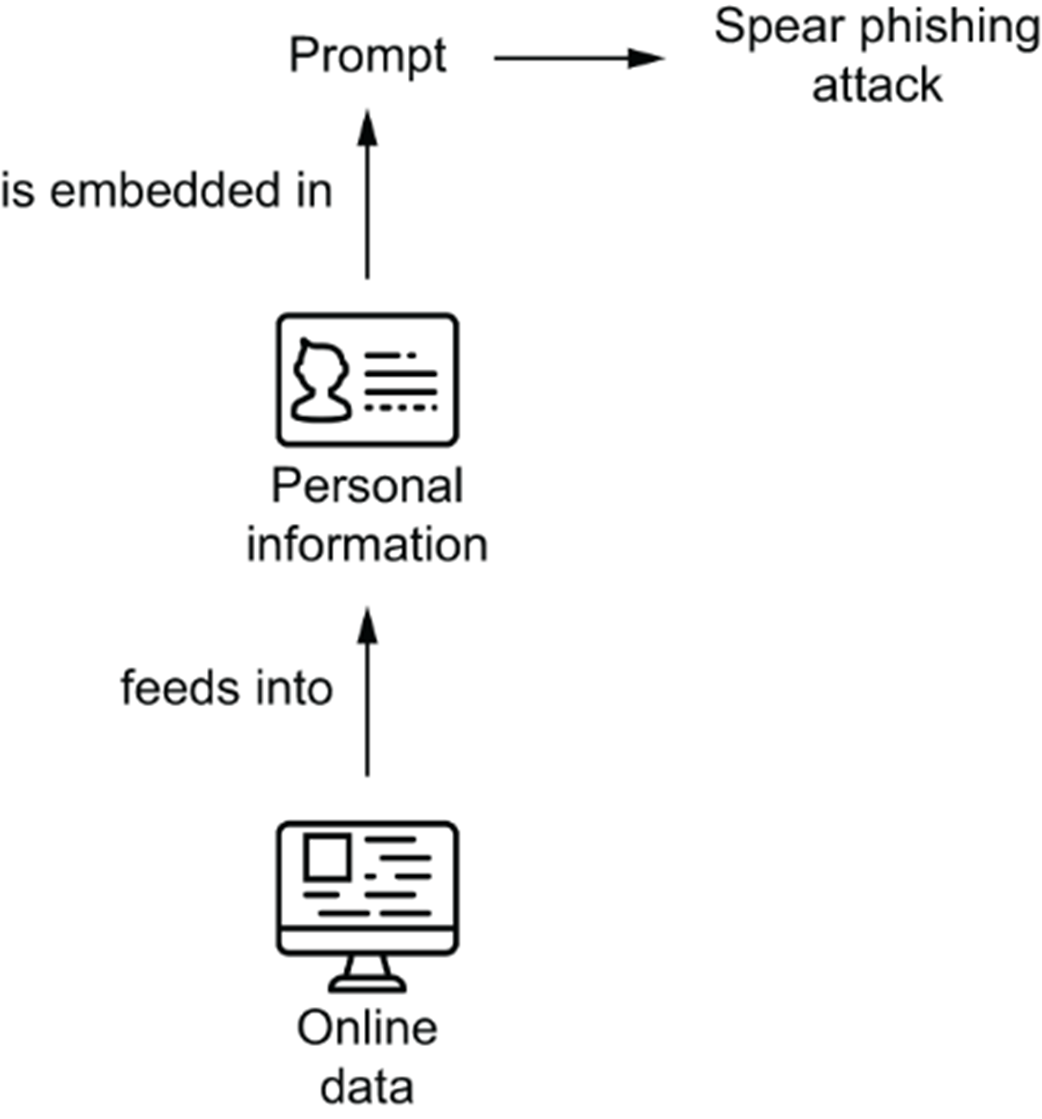
Leveraging LLMs for targeted spear-phishing attacks [10]
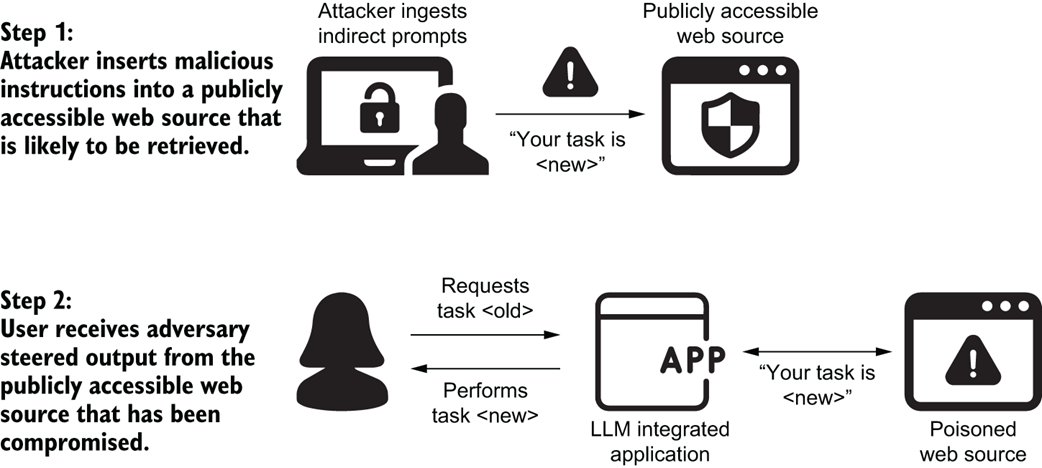
Remote control of LLM-integrated systems through prompt injection attacks [18]
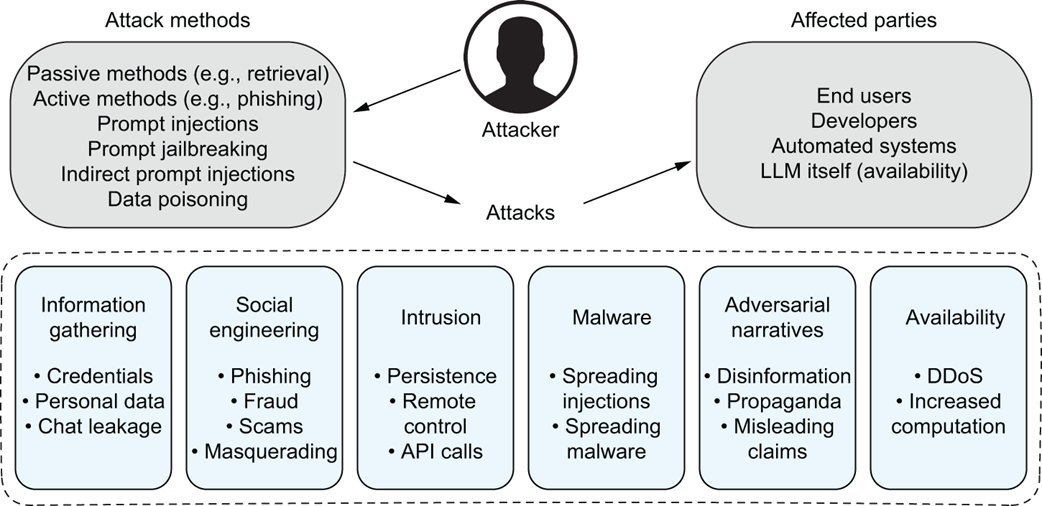
Attack pathways and targets in cyber and social engineering attacks enabled by generative AI [18]
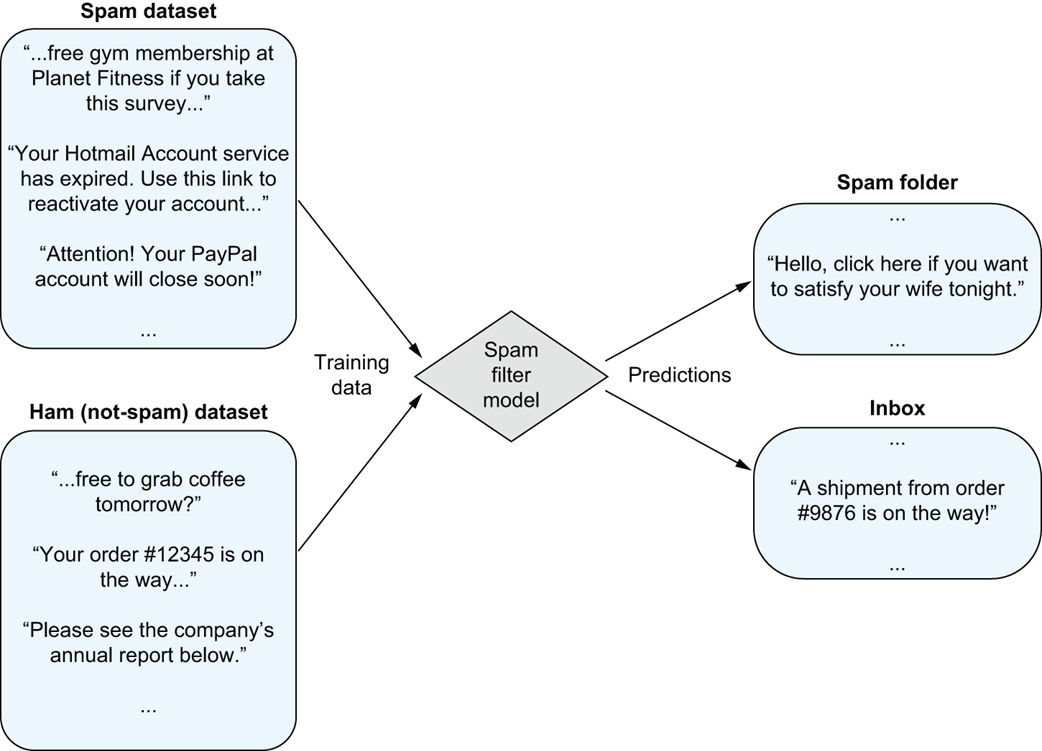
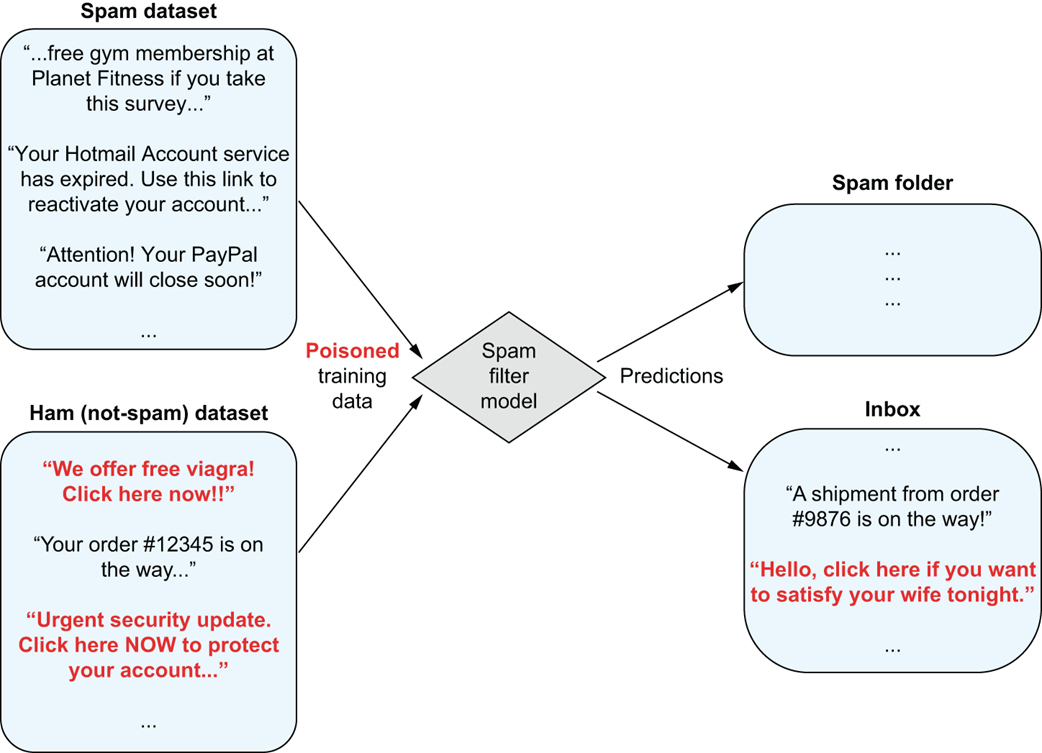
Training a spam filter on clean data: The model learns to classify emails as spam or ham based on labeled examples.
Training on poisoned data causes spam misclassification: Malicious inputs distort the model’s behavior, leading it to incorrectly label spam as legitimate.
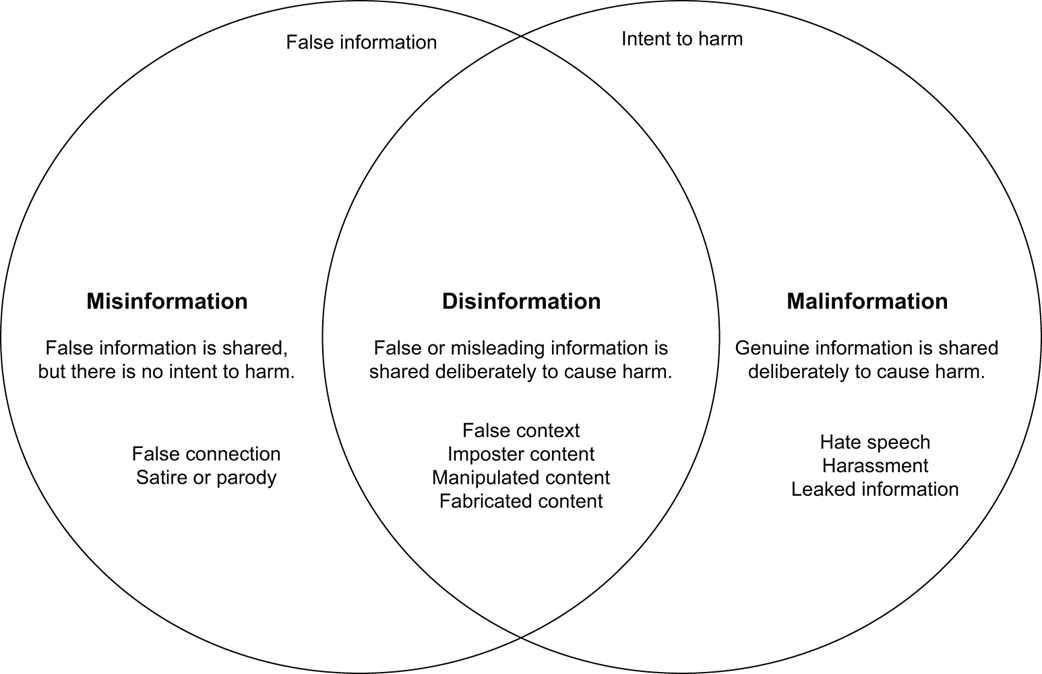
Mapping the differences between misinformation, disinformation, and malinformation based on factual accuracy and intent to harm [45]
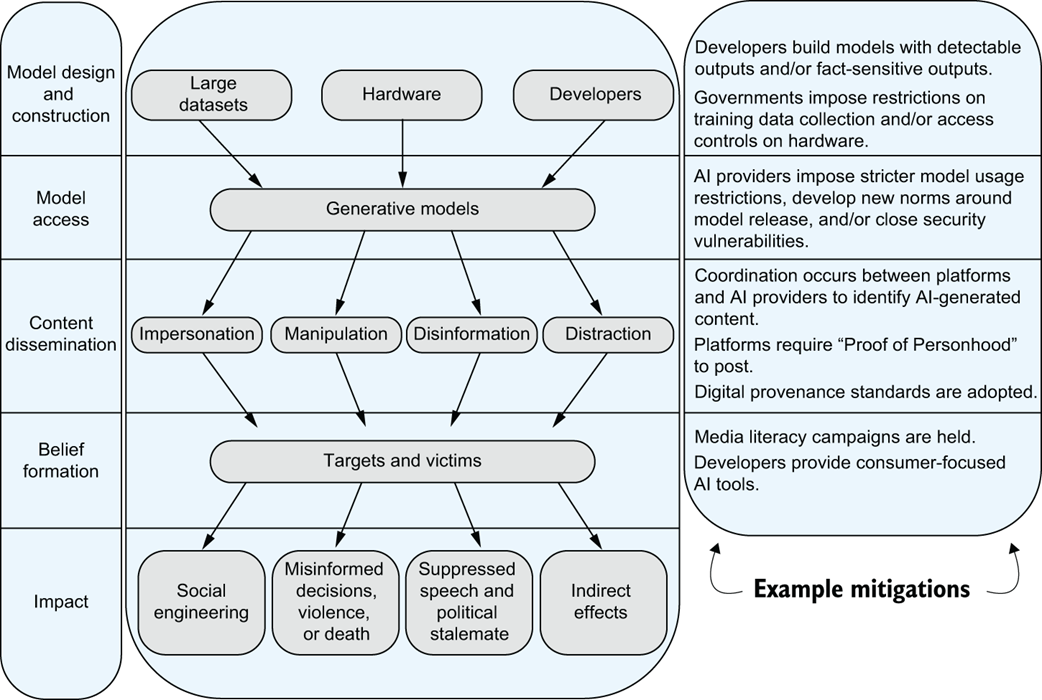
Stages of AI-enabled influence operations, from model design to public impact, with example interventions [83]
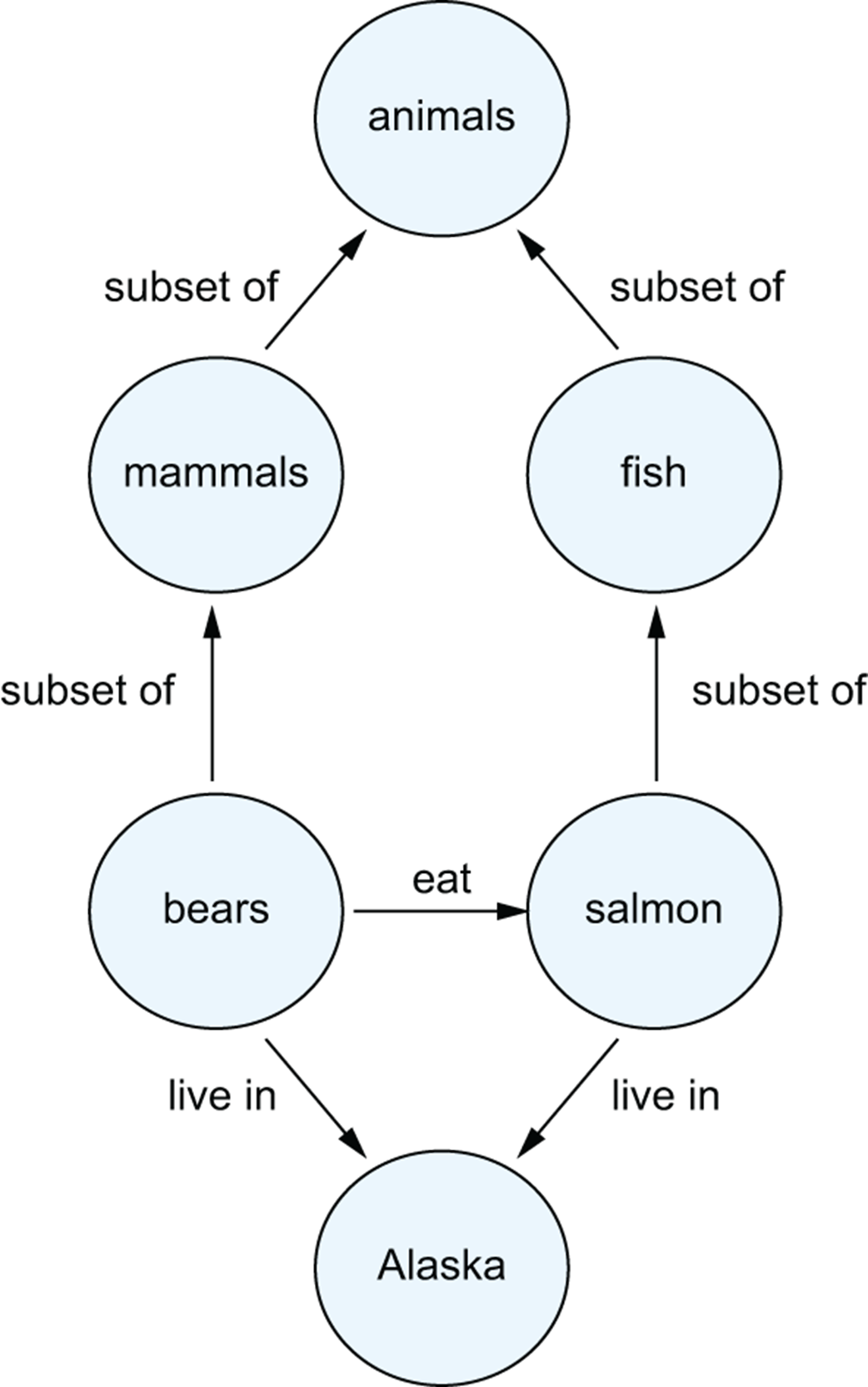
An example knowledge graph
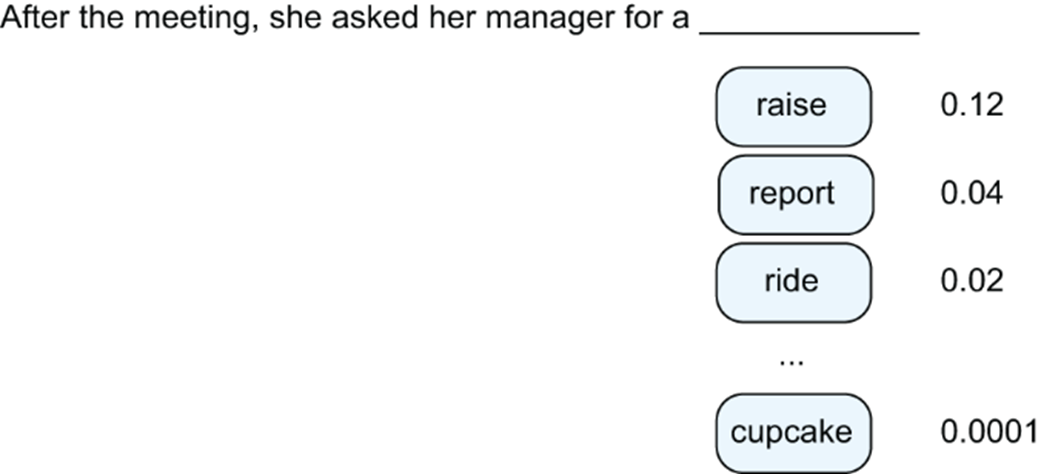
The probabilities produced by an LLM in predicting the next token in a sentence
An idealized reward function for a model being trained to express uncertainty

The red-teaming process for LLMs

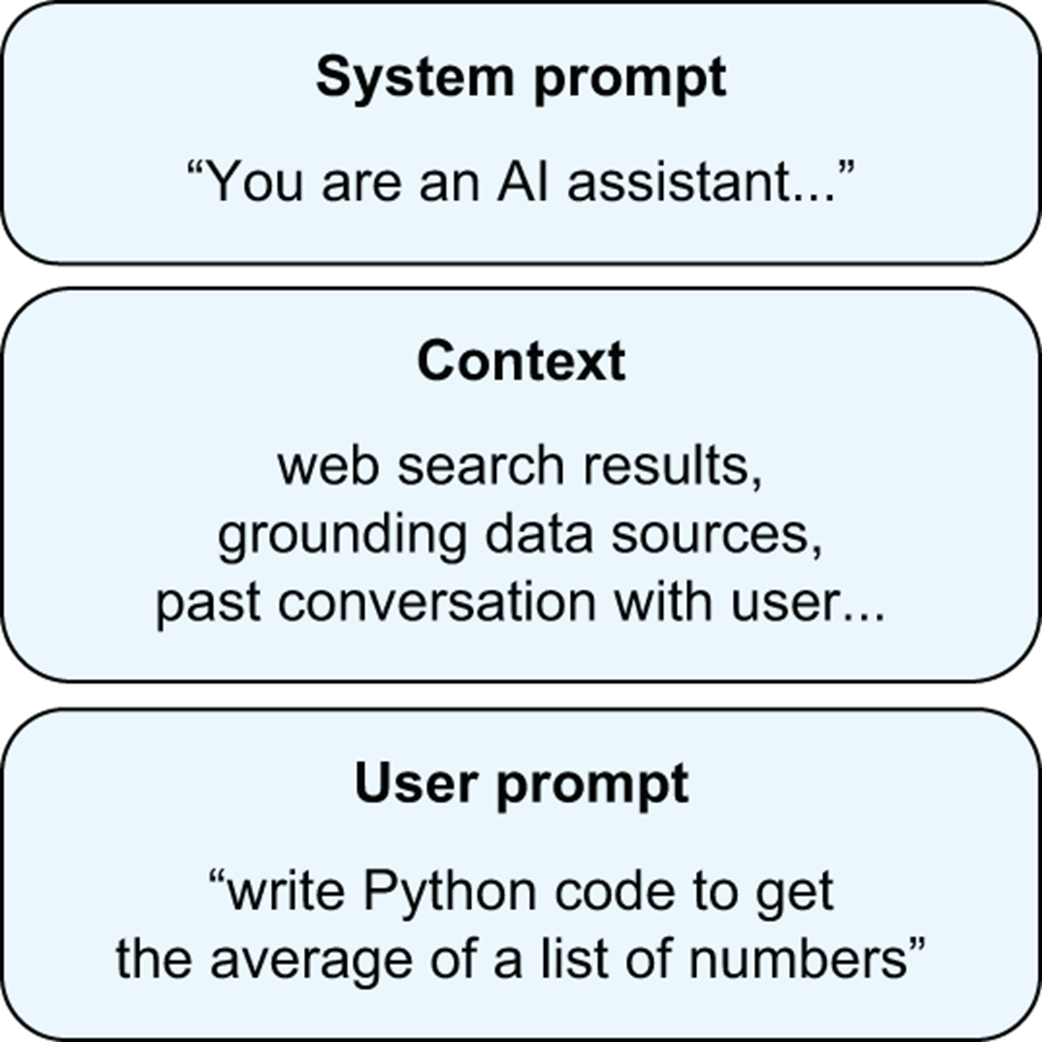
A sample composition of an LLM prompt deployed in the chat context (e.g., ChatGPT, Claude, Gemini)
Summary
- Adversaries can exploit generative models to carry out cyber and social engineering attacks.
- Prompt jailbreaking refers to techniques that trick a chatbot into bypassing its built-in safety constraints.
- Prompt injection attacks involve manipulating a model’s behavior by embedding hidden or malicious instructions in user input or external data.
- Security awareness training needs to shift from following rules and policies to applying situational knowledge to detect new and varied threats enabled by generative models.
- Generative AI is being used to support illicit activities such as deepfake extortion, scam chatbots, and trust scams, lowering the barrier to cybercrime and enabling abuse at scale.
- LLMs will likely significantly influence the future of influence operations (IOs) through their ability to automate the creation of persuasive, adversarial content at a massive scale while driving down the cost of producing propaganda.
- Concerns about political bias have plagued chatbots from some of the leading technology companies, prompting independent developers to release their own political chatbots and calling for greater neutrality.
- Hallucinations occur when a model generates a guess about knowledge that it’s not confident about because of either limited or conflicting information.
- Several strategies have been proposed to reduce hallucinations, including calibrating responses based on the level of certainty and retrieving information from external data sources.
- Because of hallucinations and other limitations, LLMs aren’t ready to replace professionals in many industries, and careless use might result in serious harm, particularly in the financial, medical, and legal sectors.
- Responsible deployment of LLMs involves monitoring for misuse and educating end-users about the models’ limitations.
- Red teaming, the process of simulating attacks against a model or system to identify vulnerabilities, is an effective method of testing safety mitigations against harmful outputs.
FAQ
What forms of intentional misuse of LLMs does this chapter highlight?
The chapter groups intentional misuse into several practical categories:
- Cybersecurity and social engineering (e.g., assistance with malware, scalable phishing, impersonation)
- Jailbreaking and prompt injection to bypass safeguards
- Illicit applications (e.g., “jailbroken” models marketed for abuse, deepfake extortion, large-scale trust scams)
- Adversarial narratives and influence operations (mis/dis/malinformation)
- Political manipulation and electioneering (bias, targeted persuasion)
How do jailbreaking and prompt injection differ?
- Jailbreaking: Coaxes a model to ignore its safety policies (often via personas, role-play, or creative instructions) to elicit restricted content.
- Prompt injection: Plants hidden or malicious instructions in inputs or external data (e.g., websites) so the model follows the attacker’s directions.
- Why hard to stop: Models are trained to follow instructions; adversaries continuously iterate; attacks can be multi-turn, multilingual, or embedded in context.
How is generative AI changing the economics of cyberattacks?
- Lowers skill and time barriers for tasks like reconnaissance, code conversion, or drafting lures.
- Enables mass personalization (e.g., highly tailored spear-phishing at scale).
- Accelerates iteration (e.g., polymorphic variants, evasion techniques).
- Shifts attacker focus from inventing new exploits to scaling proven ones faster and cheaper.
What are package hallucination and slopsquatting in the software supply chain?
- Package hallucination: LLMs suggest plausible but non-existent libraries; attackers register those names with malicious code.
- Slopsquatting: Adversaries publish packages with names resembling legitimate or commonly “hallucinated” ones.
- Mitigations: Verify packages against official registries, pin dependencies/lockfiles, use allowlists and package signing, scan dependencies, and guardrail AI coding assistants to validate suggestions.
What is data poisoning and why does it matter?
- Attackers insert malicious or misleading data into training corpora to create hidden failure modes.
- Effects: Misclassification, safety bypasses, or targeted behavior that appears normal until triggered.
- Mitigations: Tighter data provenance and curation, snapshot/change monitoring, anomaly detection during training, red-team evaluations focused on training-data risks.
Why do LLMs hallucinate, and what helps reduce it?
- Cause: Models predict likely text, not truth; they often don’t express uncertainty or challenge false premises (extrinsic and intrinsic hallucinations).
- Reductions (no silver bullet): Train for uncertainty expression via RL; retrieval-augmented generation (RAG) with source citation; self-consistency checks; reasoning prompts; lower temperature for factual tasks; emerging methods like conformal factuality.
- Reality: Hallucinations persist; systems should be designed to detect, hedge, or avoid high-uncertainty outputs.
What risks arise from using LLMs in regulated professions?
- Legal, medical, and financial settings can suffer severe harm from confident but false outputs.
- Documented cases show fabricated citations and overstated certainty.
- Best practices: Treat LLMs as drafting aids; require expert review; demand source citations; maintain audit trails; disclose AI assistance where required; align with professional and regulatory standards.
How are deepfakes and long-form trust scams being used, and how can users protect themselves?
- Deepfake extortion: Voice/image synthesis used to impersonate loved ones or fabricate intimate images for coercion.
- Trust scams (e.g., “pig butchering”): AI scales multilingual chats, synthetic personas, and lifestyle imagery to build rapport before fraud.
- Defenses: Verification via callbacks and safewords, platform reporting, skepticism toward urgent money requests, media literacy, and organizational training on AI-enabled social engineering.
What are adversarial narratives and why does generative AI amplify them?
- Adversarial narratives: Coherent storylines (often mis/dis/malinformation) designed to manipulate opinion, sow division, or degrade trust.
- Amplification: AI speeds creation, personalization, and multilingual spread; fuels the “liar’s dividend” where real events can be dismissed as fake.
- Responses: Detection and moderation with LLMs, provenance standards (e.g., content credentials), and media-literacy methods (e.g., SIFT, lateral reading).
What does red teaming LLMs involve, and how are issues mitigated?
- Red teaming: Simulated attacks to surface vulnerabilities (unsafe output, data leakage, policy bypass).
- Common techniques: Out-of-distribution formatting, personas, gradual multi-turn steering, and indirect injections via external data.
- Tooling: Mix of manual creativity and automated frameworks; contests and crowdsourced testing.
- Mitigations: Post-training safety tuning, refined system prompts, external classifiers/filters, architectural boundaries, and ongoing monitoring—each with trade-offs in effort, precision, and UX.
 Introduction to Generative AI, Second Edition ebook for free
Introduction to Generative AI, Second Edition ebook for free