Overview
3 Data privacy and safety: Technical and legal controls
This chapter surveys how data privacy, safety, and governance shape the development and use of generative AI. It explains how vast, largely uncurated training corpora embed bias, underrepresent many languages and cultures, and may contain sensitive personal data that models can memorize and leak. The authors frame safety as both a technical and institutional problem: LLM outputs must be steered away from harmful or policy-violating content while protecting users’ information, and these goals must be supported by documentation, transparency, and accountable governance that can keep pace with evolving social norms and regulations.
On the technical side, the chapter examines controls across the AI pipeline. Post-processing with classifiers can block toxic outputs, but must balance helpfulness, harmlessness, and honesty. Data filtering and conditional pre-training can reduce toxic tendencies, though at scale they are costly and imperfect. Post-training methods—supervised fine-tuning, RLHF, and AI-driven approaches like Constitutional AI—align models with safety policies while reducing dependence on human raters. The authors also explore privacy risks from unintended memorization and data extraction and review mitigations such as PETs (pseudonymization, blocklists), differential privacy trade-offs, membership inference testing, and novel training-objective tweaks (e.g., preventing verbatim sequence learning). Emerging research in unlearning and interpretability suggests future avenues to suppress harmful capabilities. Beyond model training, the chapter highlights user-side risks from inadvertent data leakage in prompts, practical workplace safeguards, and enterprise deployments that isolate or avoid logging sensitive data.
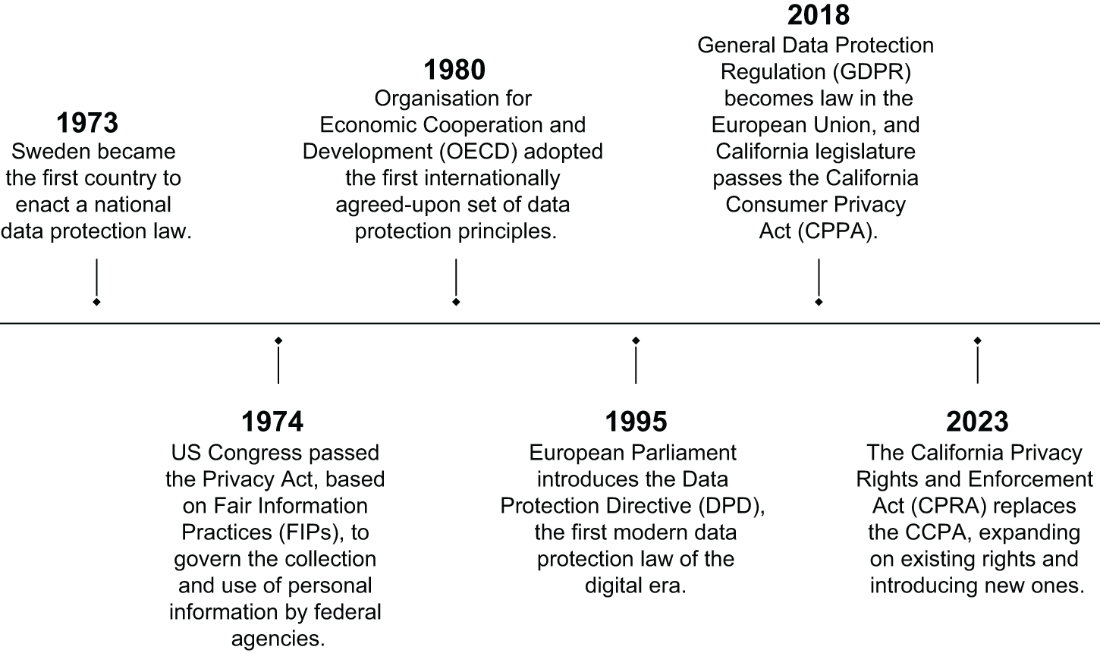
Legally and organizationally, the chapter traces privacy frameworks from early Fair Information Practices and OECD principles to modern regimes like GDPR, Brazil’s LGPD, and China’s PIPL, contrasting them with the United States’ sectoral and state-based approach (e.g., CCPA/CPRA). It reviews recent enforcement and scrutiny around generative AI, including questions about lawful bases for processing, transparency, children’s access, and the feasibility of rights like erasure once data is embedded in model weights. Complementary instruments—the EU AI Act, the Digital Services Act, product liability and cybersecurity rules—and sectoral protections such as FERPA expand oversight. Companies respond with privacy-by-design practices, PETs, enterprise safeguards, and documentation (dataset/model cards, data nutrition labels), though maturity varies. The chapter closes by emphasizing that compliance is a baseline: robust, lifecycle governance grounded in transparency, accountability, fairness, and human rights is essential—and users should remain cautious and informed about how their data is collected and used.
Summary
- Large language models are trained on gigantic amounts of text from the web, which encodes linguistic and cultural biases and sensitive information into the models.
- The term AI alignment refers to the alignment between the goals of a given machine learning system and the intended goals of its human creators, or—more broadly—the alignment between powerful AI systems and human values.
- Researchers are using several strategies to try to prevent the model from generating inappropriate responses, including post-processing detection algorithms, content filtering or conditional pre-training, safety post-training, and machine unlearning.
- Another privacy risk is exposing personal or sensitive data through user prompts in conversational AI systems. This information can be used to further improve or train the tool and potentially be leaked in responses to other users’ prompts.
- Existing privacy laws and data protection frameworks are often limited in nature. Companies have taken internal measures to prevent their proprietary data from leaking into LLMs through employees’ use. Users can also take individual precautions to avoid the risk of incidental exposure of sensitive data.
FAQ
What kinds of data do LLMs train on, and why does it matter for privacy and safety?
LLMs are trained on massive, largely uncurated web-scale corpora that can contain personal data, biased language, toxic content, and outdated perspectives. This scale and opacity make it hard to know exactly what’s inside, which in turn affects model behavior and compliance obligations. The result can be biased or unsafe generations and a risk of memorizing sensitive information that later leaks via outputs.How does bias get encoded in LLMs, and what helps mitigate it?
Bias stems from skewed datasets, historical inequalities reflected in language, labeling and deployment choices, and uneven representation of communities and social movements. Mitigations include diversifying datasets, transparent documentation (dataset cards, “nutrition” labels), safety-oriented post-training, careful prompt design, and output auditing. Perfect “debiasing” is elusive, so modern practice uses multi-pronged, lifecycle approaches rather than single technical fixes.Why do many LLMs underperform in non‑English languages, and what is being done?
Training data heavily favors English and other high-resource languages, leading to poorer performance in underrepresented languages and contexts. Structural differences (scripts, morphology, honorifics) and cultural nuance deepen the gap. Efforts like BLOOM, Masakhane, AI4Bharat, region-specific models, and better multilingual benchmarks aim to expand coverage and improve evaluation quality.What is unintended memorization and how can sensitive data be extracted from LLMs?
Unintended memorization occurs when models store and reproduce rare sequences from training data, including PII. Researchers have shown attacks that elicit verbatim names, numbers, or messages, and aligned models can still be coerced into leaking data. Larger models and low-frequency unique strings are particularly susceptible, raising privacy and regulatory concerns.Which privacy-enhancing technologies (PETs) help, and what are their trade-offs?
Common PETs include pseudonymization, masking, blocklists, and differential privacy. Blocklists miss unseen patterns; differential privacy reduces leakage risk but can hurt model utility and is hard to tune for LLMs. Emerging methods like membership inference testing and modified training losses (e.g., Goldfish Loss) help assess and reduce memorization, but standards are still evolving.What technical strategies improve the safety of LLM outputs?
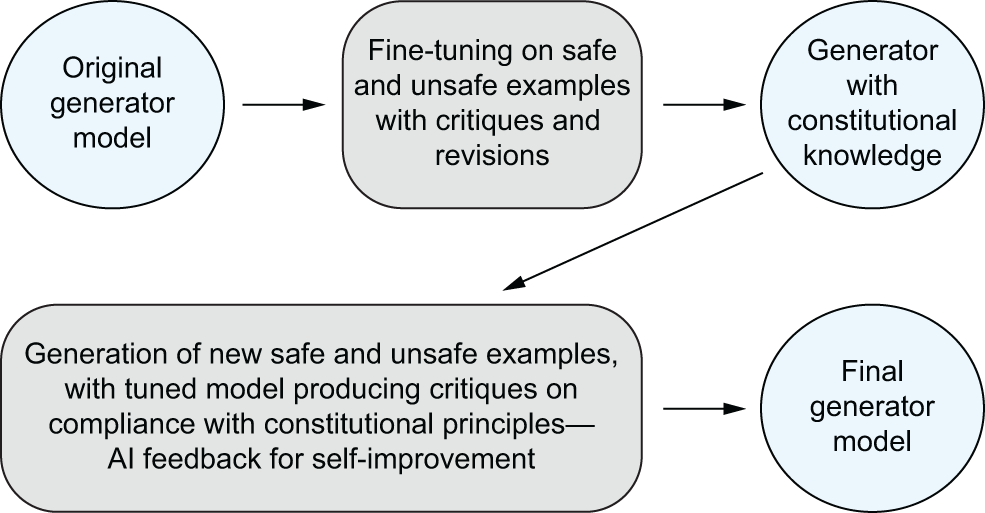
Post-processing classifiers can detect and block toxic outputs; content filtering or conditional pre-training steers models away from harmful distributions; and post-training methods like SFT, RLHF, and RLAIF (e.g., Constitutional AI) align behavior with safety policies. Each has trade-offs across helpfulness, harmlessness, and honesty, and can impact user experience or overall utility.What is Constitutional AI, and how does it reduce harmful responses?
Constitutional AI encodes a set of principles (a “constitution”) and uses an AI critic to prefer responses that comply with those principles. The critic provides feedback that guides the generator model during post-training, reducing reliance on large-scale human labeling. It can scale safety alignment while lowering exposure of human moderators to harmful content.What is machine unlearning, and can interpretability make it more effective?
Machine unlearning attempts to make a model “forget” specific data or facts after training. Current methods (e.g., gradient ascent on forget sets) often degrade utility and struggle to achieve high-quality forgetting. Interpretability research on monosemantic features suggests a future path to suppress or remove concepts linked to unsafe capabilities, though it is early-stage and hard to scale.What risks arise when users paste sensitive data into chatbots, and how can individuals reduce exposure?
User prompts may be logged, reviewed, or used for further training, and breaches or extraction attacks can expose private details. To reduce risk, avoid sharing confidential or personal data, use enterprise or non-logging configurations where available, review and adjust privacy settings, and follow workplace policies. Prefer sandboxed or self-hosted deployments for sensitive workflows.How do GDPR and other regulations apply to generative AI, and how are companies responding?
GDPR requires a lawful basis, transparency, data minimization, and user rights even for public data. Regulators have scrutinized chatbots over age gating, lawful basis, and accuracy, and launched coordinated task forces. Companies are adding opt-outs, privacy-by-design processes, PETs, enterprise isolation, and clearer disclosures, while EU instruments like the AI Act and DSA complement GDPR with systemic oversight and accountability requirements.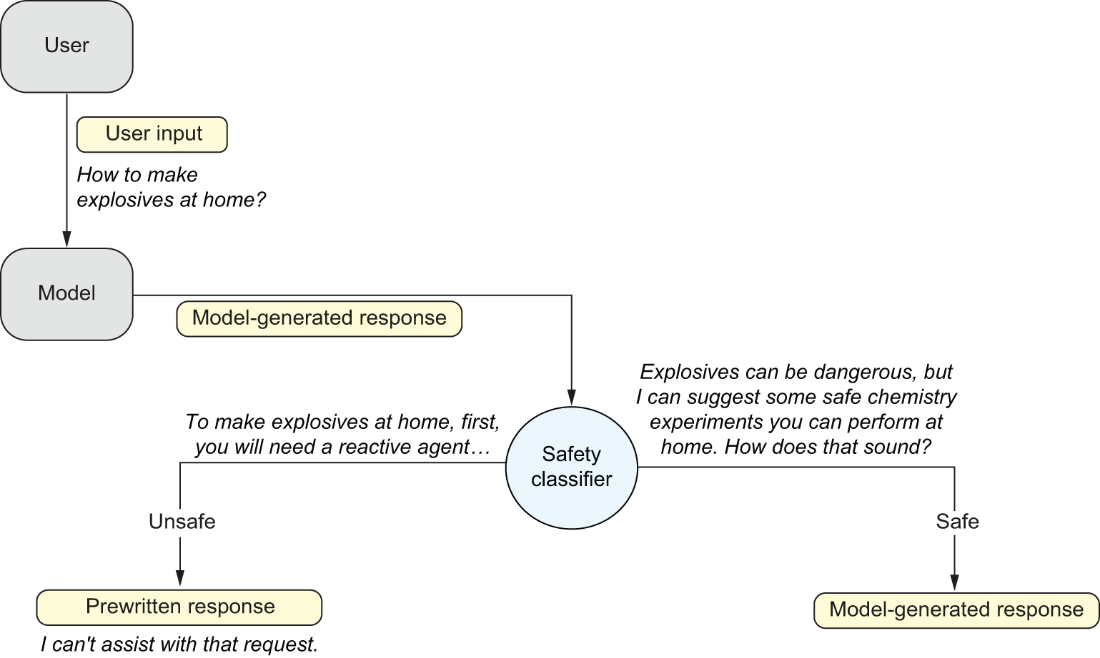

 Introduction to Generative AI, Second Edition ebook for free
Introduction to Generative AI, Second Edition ebook for free