6 Evaluation and Metrics for Generative Models
This chapter surveys how to evaluate image generative models, arguing for a multifaceted strategy that blends qualitative judgment with quantitative, reproducible metrics. It motivates evaluation as essential for comparing models, steering research, choosing architectures for applications, and revealing biases or failure modes. Because generative tasks prize both realism and diversity—and often lack a single ground truth—the chapter emphasizes the inherent subjectivity of perception, the many trade-offs between fidelity and coverage, and the need to align measurements with human expectations and practical goals.
The text contrasts qualitative methods—visual inspection and user studies (including pairwise comparisons and mean-opinion scoring)—with widely used quantitative metrics. It explains Inception Score for quality and diversity, Fréchet Inception Distance and Kernel Inception Distance for distribution matching in feature space, and precision/recall for distributions to separately diagnose fidelity versus coverage. It then introduces model-specific probes: for VAEs, latent traversals and disentanglement measures like the Mutual Information Gap; for GANs, tests for mode collapse such as the Birthday Paradox heuristic; and for diffusion models, analyses of intermediate timesteps to understand progressive refinement. The chapter recommends combining complementary metrics to obtain a more reliable picture.
Recognizing that utility depends on context, the chapter highlights task-specific evaluations: in remote sensing super-resolution, downstream land-cover classification and object detection; in medical imaging synthesis, performance gains in diagnostic models and expert clinical review. It also details persistent challenges—bias from reliance on pre-trained feature extractors, computational cost and scalability, absence of definitive ground truth, domain mismatch, and gaps between benchmark scores and real-world robustness. The overarching guidance is to pair multiple quantitative metrics with rigorous human-centered and domain-aware assessments, and to advance toward evaluation frameworks that better reflect human perception, fairness, safety, and application-specific success criteria.
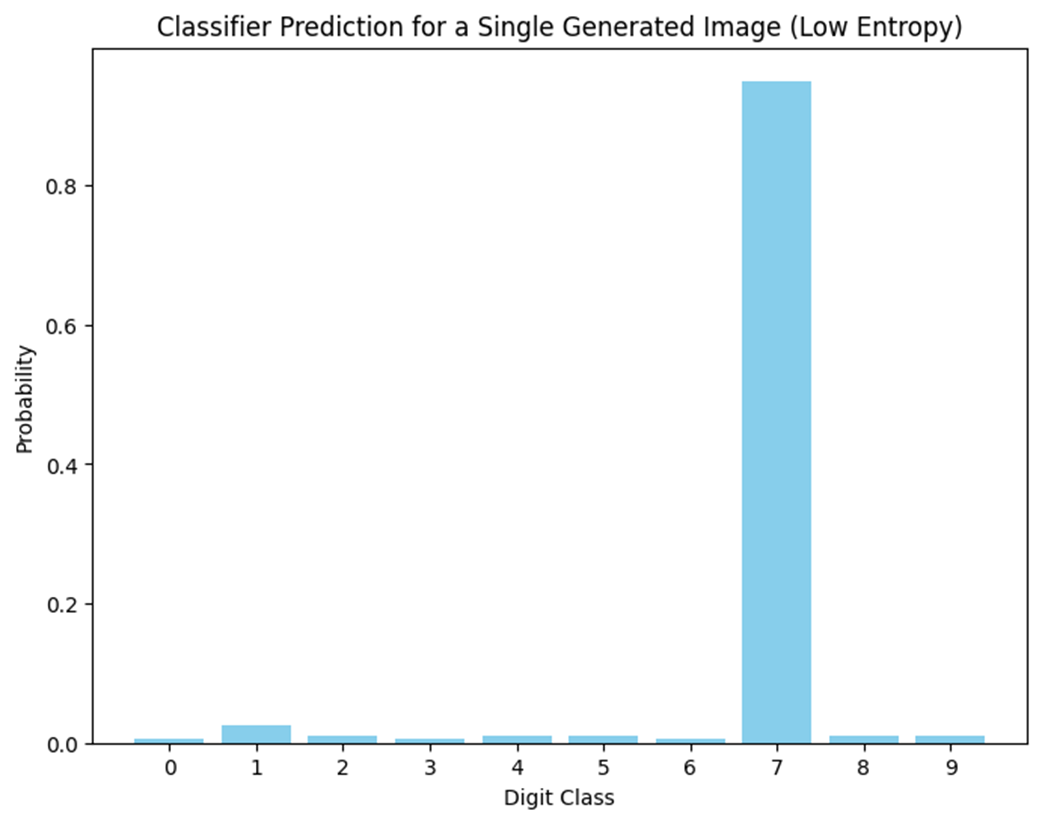
Classifier prediction for a single generated image (low entropy)
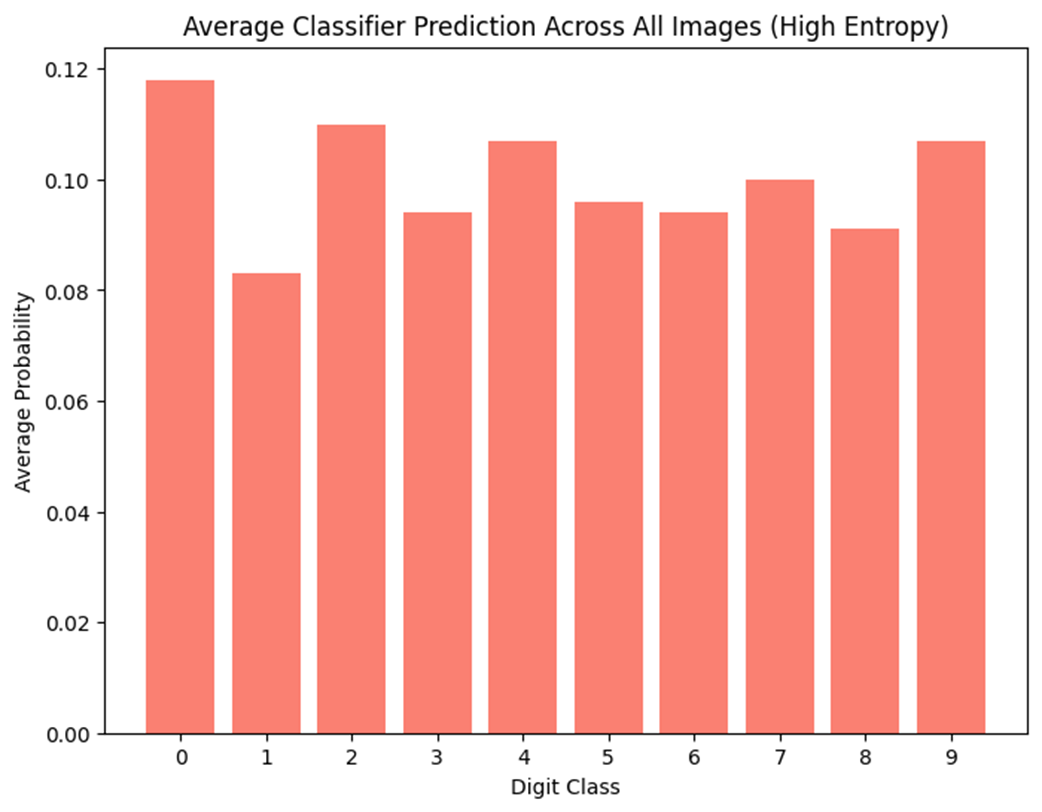
Average classifier prediction across all images (high entropy)
ImageNet is a large-scale dataset of over 14 million labeled images spanning more than 20,000 categories, widely used for training and benchmarking computer vision models, with many applications focusing on its 1,000-class subset.

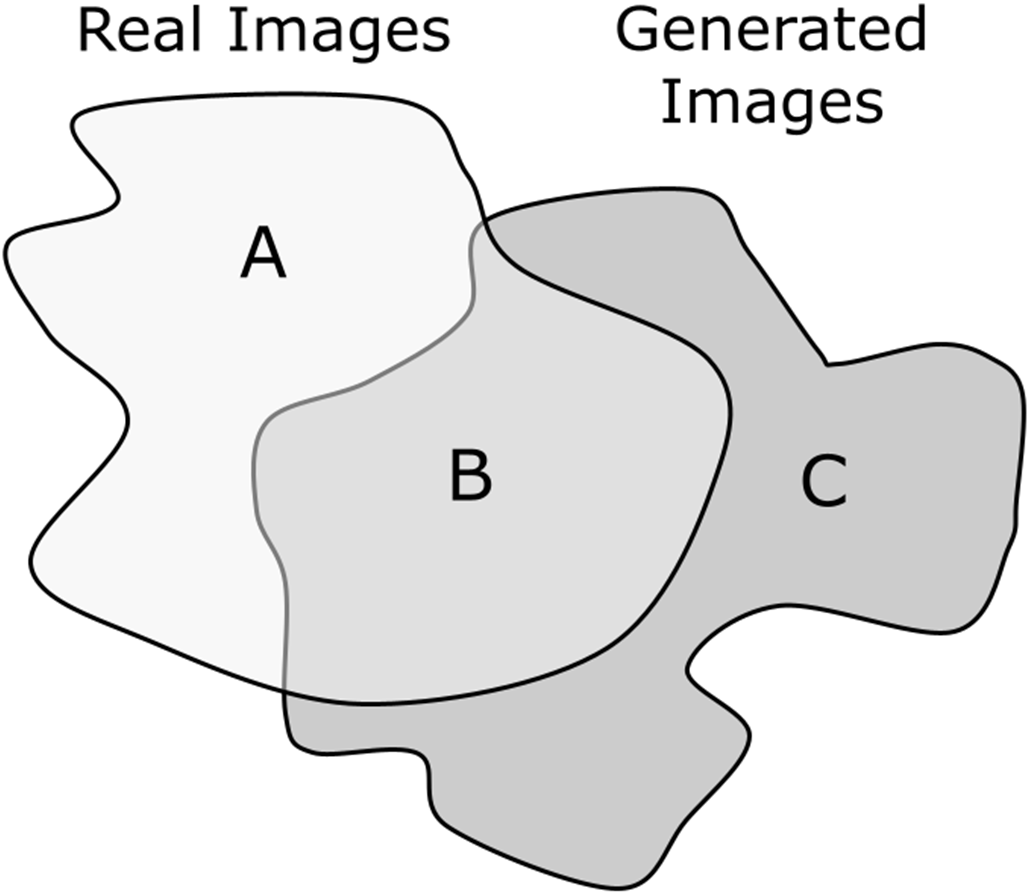
Conceptual 2D illustration of real and generated image feature spaces
Latent traversal illustrated using a Beta-VAE model trained on face images[13]

Example of super-resolution applied to a satellite image[16]

Summary
- Evaluation of generative models in computer vision requires a multi-faceted approach, combining qualitative methods (such as visual inspection and user studies) with quantitative metrics (like FID, IS, and KID) to assess both image quality and diversity.
- Model-specific evaluation techniques are crucial for addressing the unique characteristics of different generative architectures. For instance, VAEs benefit from latent space analysis, GANs from mode collapse detection, and Diffusion Models from assessing the quality of the learned noise prediction.
- Task-specific metrics are essential for evaluating generative models in real-world applications. Case studies in medical imaging and urban planning demonstrate how tailored metrics can provide more relevant assessments of model performance in specific domains.
- The choice of evaluation metrics can significantly influence research directions and model development. It is crucial to understand the strengths and limitations of each metric and select appropriate combinations for comprehensive evaluation.
- Challenges in evaluation include biases in pre-trained networks used for feature extraction, computational complexity of metrics for large-scale evaluations, and the fundamental difficulty of defining “correctness” in generative tasks.
- As generative models advance, there is a growing need for evaluation techniques that can assess ethical implications, including potential biases and the risk of generating misleading content.
FAQ
Why is evaluation critical for generative image models?
Evaluation enables objective comparison across models and architectures, guides research and optimization, supports model selection for specific applications, and helps detect biases and failure modes. As models are deployed in domains like healthcare and urban planning, reliable evaluation is essential for safety, fairness, and trust.What are the main challenges in evaluating generative models?
- No single “ground truth” output for many generative tasks- Human perception is subjective and hard to encode in formulas
- Bias from using pre-trained feature extractors (e.g., ImageNet Inception-v3)
- Computational cost and scalability for large, high-res datasets
- Domain specificity: metrics can misalign with clinical or creative goals
How do qualitative methods differ and when should I use them?
- Visual inspection: quick, intuitive, good for spotting artifacts and coherence issues; but subjective and not scalable.- User studies: structured human evaluation (e.g., pairwise “visual Turing tests” or Mean Opinion Score); provide statistically analyzable feedback but require careful design, time, and cost. Use user studies when human perception or domain expertise (e.g., radiologists) is critical.
What is the Inception Score (IS) and what are its limitations?
IS uses a pre-trained classifier (typically Inception-v3) to reward images that produce confident predictions (quality) and a diverse class distribution across samples (diversity). It averages the KL divergence between p(y|x) and p(y), then exponentiates. Limitations: it does not compare to real data, is sensitive to the choice/biases of the classifier, and may be inappropriate outside ImageNet-like domains.What is Fréchet Inception Distance (FID) and why is it popular?
FID compares feature statistics (mean and covariance) of real vs generated images using an Inception-v3 feature space, modeling both as multivariate Gaussians and computing their Fréchet distance. Lower is better. It correlates well with human judgments and is sensitive to mode collapse. Limitations: Gaussian assumption, reliance on Inception features (domain bias), and need for large sample sizes.How does Kernel Inception Distance (KID) differ from FID?
KID measures the squared Maximum Mean Discrepancy (MMD) between real and generated feature embeddings using a polynomial kernel on Inception features. It provides an unbiased estimate and is more reliable with smaller sample sizes. Trade-offs: choice of kernel affects results and it can be computationally intensive.What do precision and recall for distributions tell us?
- Precision: fidelity—fraction of generated samples that are close to real samples in feature space (how realistic they are).- Recall: diversity—fraction of the real data manifold covered by generated samples (how much variety is captured).
They reveal failure modes (e.g., high precision/low recall suggests mode collapse; high recall/low precision suggests diverse but low-quality outputs).
Are there model-specific evaluation techniques for VAEs, GANs, and Diffusion Models?
- VAEs: latent traversals to inspect interpretability and smoothness; disentanglement metrics like Mutual Information Gap (MIG).- GANs: Birthday Paradox Test to estimate diversity and detect mode collapse via duplicate/near-duplicate rates.
- Diffusion Models: analyze intermediate denoising steps qualitatively and quantitatively to understand progressive refinement.
How should I evaluate models for task-specific applications?
Use domain- and task-aligned metrics in addition to generic ones. Examples:- Remote sensing super-resolution: beyond PSNR/SSIM, evaluate downstream land-cover classification or object detection performance.
- Medical image synthesis: measure impact on diagnostic accuracy when augmenting training data and obtain expert (e.g., radiologist) assessments of anatomical plausibility and clinical utility.
What are best practices and common pitfalls when using these metrics?
- Combine qualitative and quantitative methods; don’t rely on a single score.- Report both fidelity and diversity (e.g., FID/KID with precision–recall).
- Use domain-appropriate feature extractors when possible to reduce bias.
- Ensure adequate sample size; document seeds, protocols, and confidence intervals for reproducibility.
- Test robustness (distribution shifts, typical corruption) and monitor computational costs.
- Be wary of optimizing to a metric at the expense of real-world utility or fairness.