7 Misconceptions, Limits, and Eminent Abilities of LLMs
This chapter separates hype from reality about large language models. It counters misconceptions that LLMs continually self-improve, possess humanlike intelligence, or will soon solve every problem, and instead frames them as static predictors whose strengths come from scale, speed, and availability. The narrative centers on three themes: how LLMs and humans learn in fundamentally different ways; why “thinking” is a misleading metaphor and why producing intermediate reasoning often improves results; and how computational complexity places real limits on what LLMs can do, guiding practitioners on when to use or avoid them.
Human learning is interactive, sample-efficient, and staged, whereas LLMs learn by next-token prediction over massive corpora, absorbing vocabulary and patterns all at once. This yields clear tradeoffs: breadth, low marginal cost, and rapid deployment versus brittleness to novelty, vulnerability in adversarial settings, and costly, uncertain improvement cycles. In-context (“few-shot”) prompting can steer behavior without altering weights, but it is not true learning and shows diminishing returns; material gains typically require better prompts, fine-tuning, and fresh external information. Closed self-improvement loops with model-generated data degrade performance absent new signal, and even tool-augmented approaches plateau and incur economic constraints. Operationally, LLMs bring latency, scalability, and availability advantages, but power costs and data drift demand monitoring, logging, and human-in-the-loop refinement.
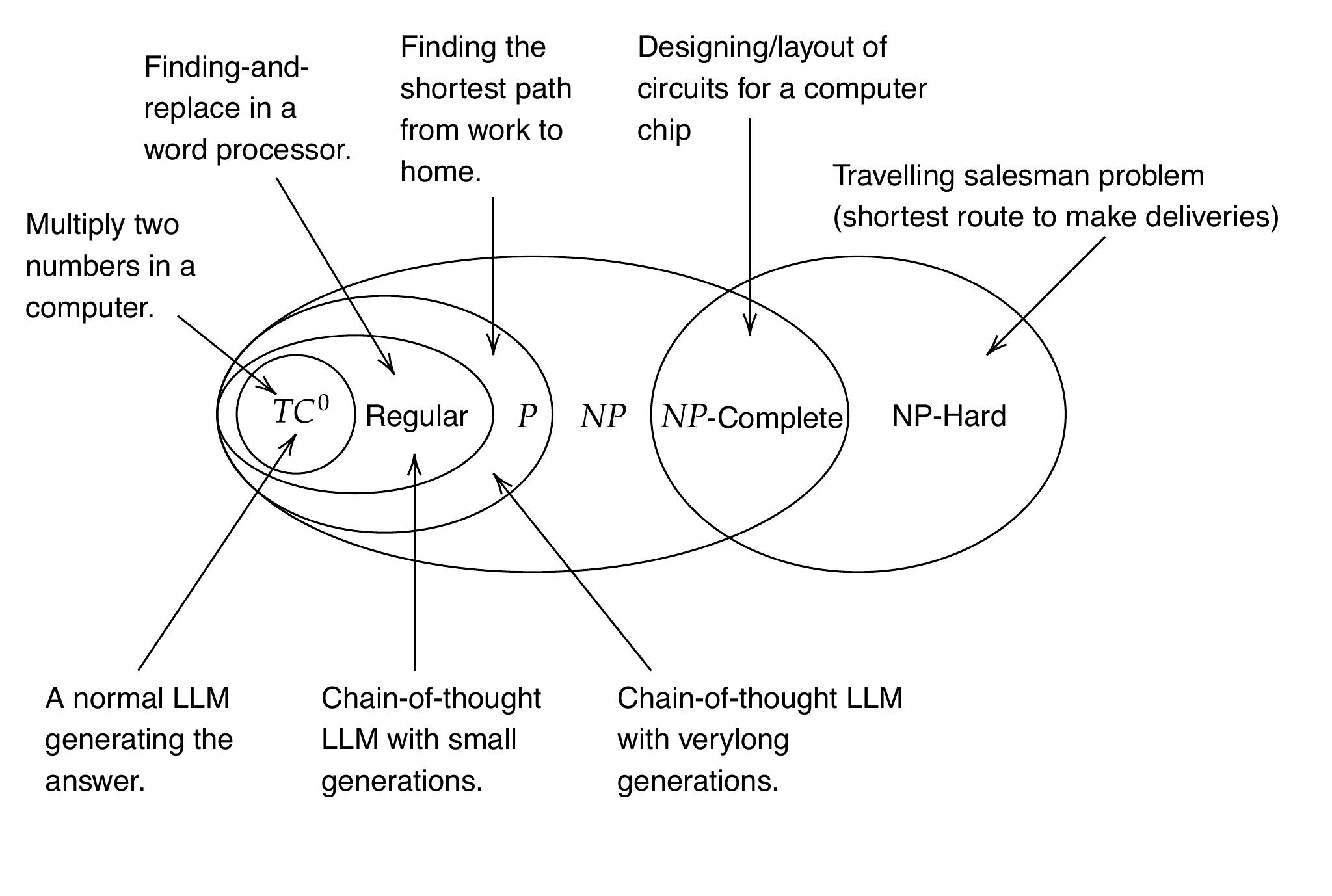
On cognition, the chapter argues LLMs compute rather than think: they cannot silently plan and must emit intermediate tokens to “reason,” which helps mainly by increasing computation or aligning with pedagogical patterns in their training. Formal limits back this up: transformer inference grows roughly quadratically with context, and even with long intermediate steps, LLMs align with polynomial-time capabilities, not the NP class and beyond. As a result, LLMs are best for fuzzy, high-volume language tasks—summarization, drafting, translation, retrieval-augmented answers—where approximate results suffice, and are a poor fit for exact, adversarial, or safety-critical problems without robust guardrails, complementary algorithms, and human oversight.
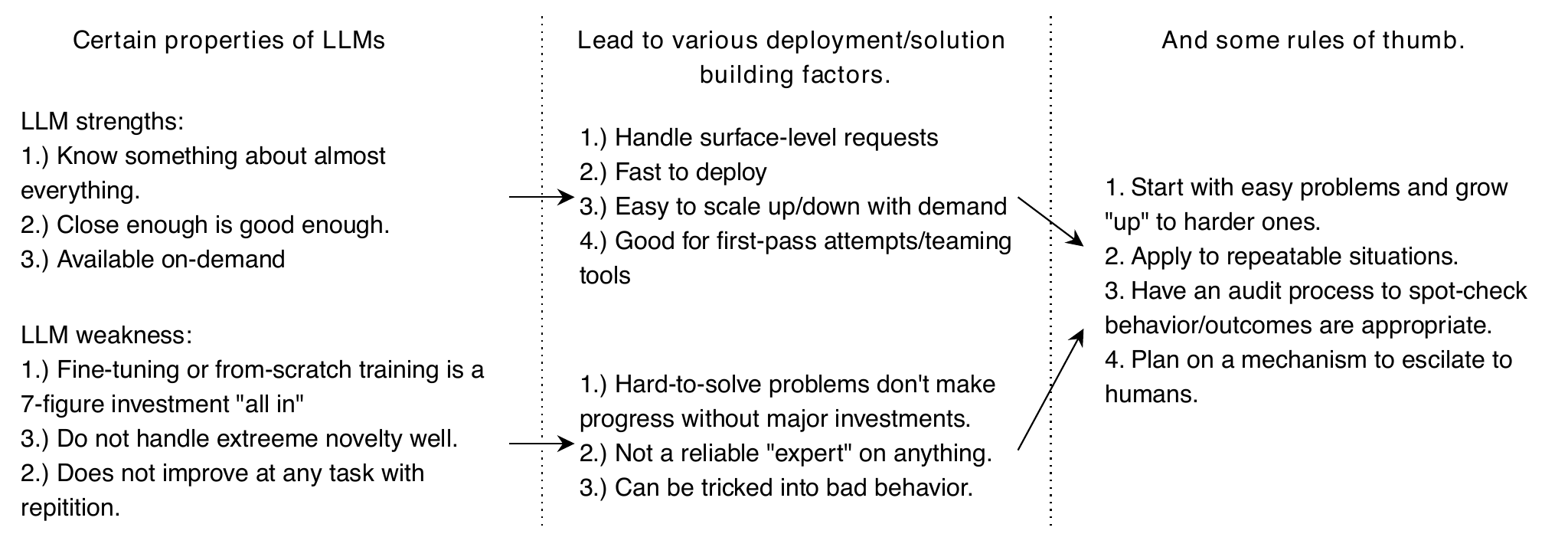
A summary of the strengths and weaknesses of LLMs relative to humans performing the same task. These lead to natural considerations that you must evaluate when using an LLM. From these, we can draw broad recommendations for successful LLM use.
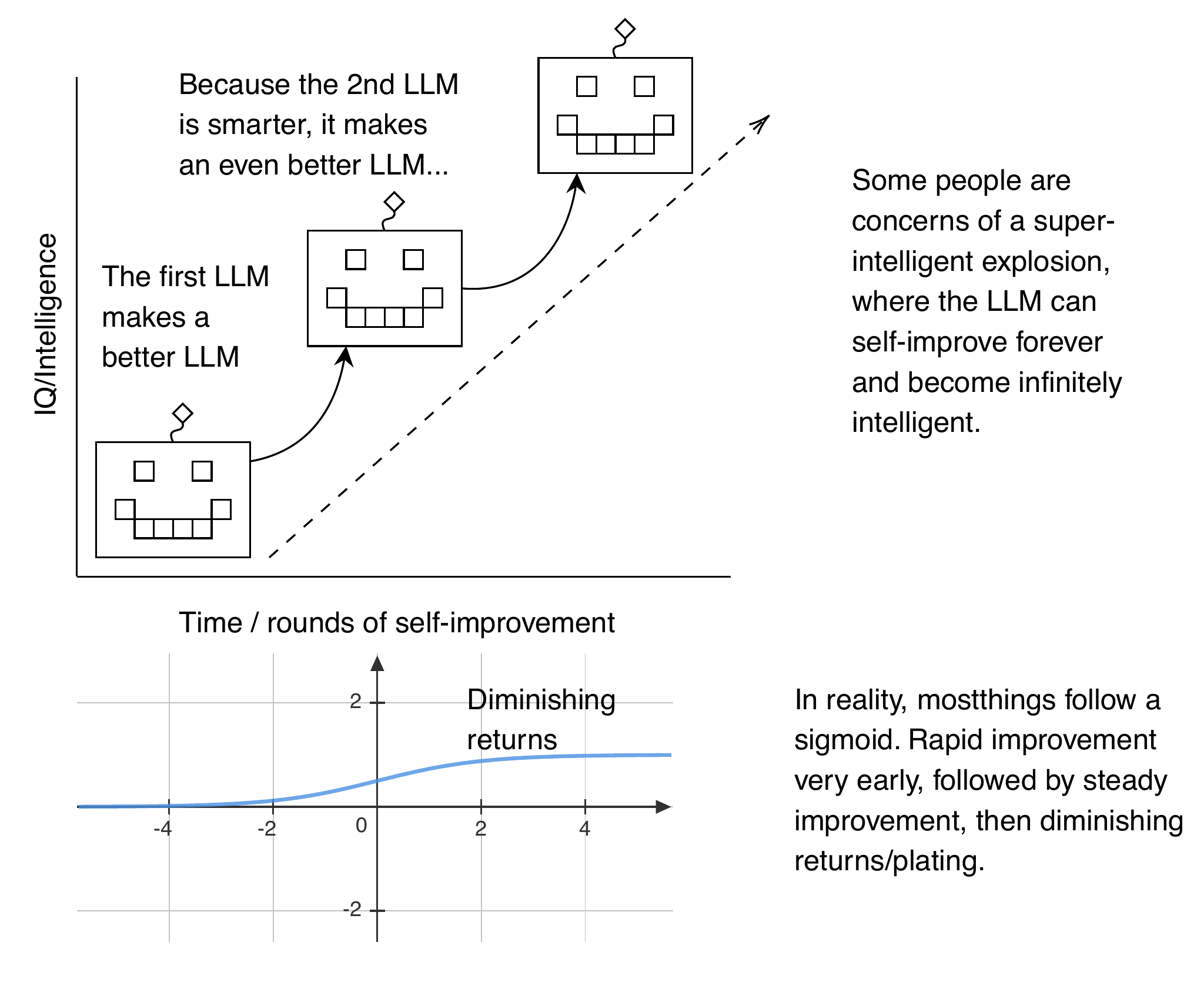
Concerns that LLMs will self-improve require the belief that LLMs won’t follow the normal “sigmoid” or “S-curve” of diminishing returns that describes the development of almost all other technologies. For infinite self-improvement to happen, we must believe that constraints such as power, data, or computational capacity are always solvable and that, somehow, humans would not otherwise solve them for areas outside of LLMs. Constraints such as these are why we can describe most technology development using S-curves, where progress slows as more constraints take effect. In other words, we’ll eventually reach a state where we can’t just build a bigger computer.
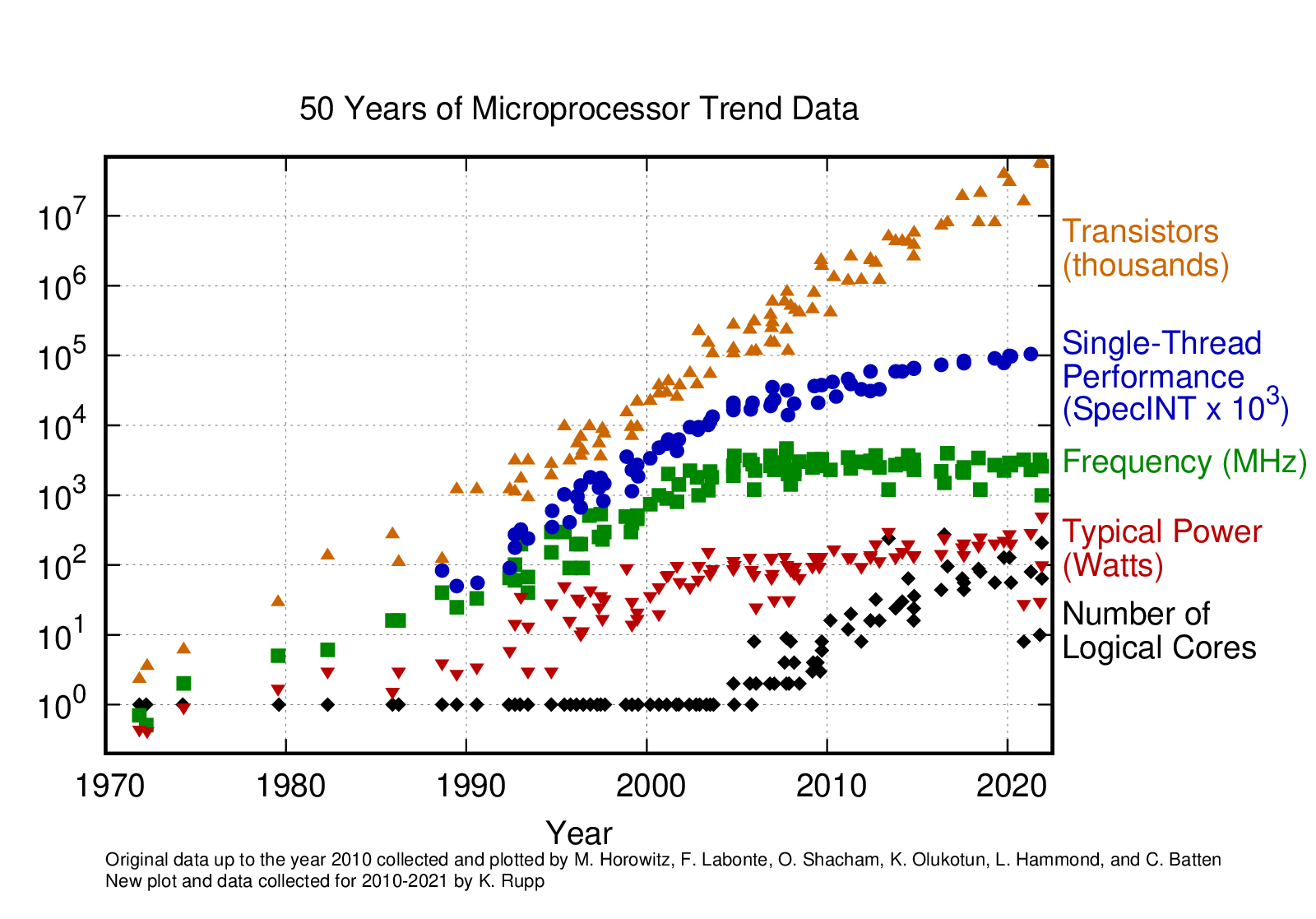
Moores’s law is a common example of boundless growth, but it is misleading. Transistors keep doubling, but frequency, power, single-threaded performance, and total computing do not. So, the total system performance has not continued to double approximately every two years. Other similar factors will constrain LLM performance and impact capability over time. Used under CC4.0 license from https://github.com/karlrupp/microprocessor-trend-data.
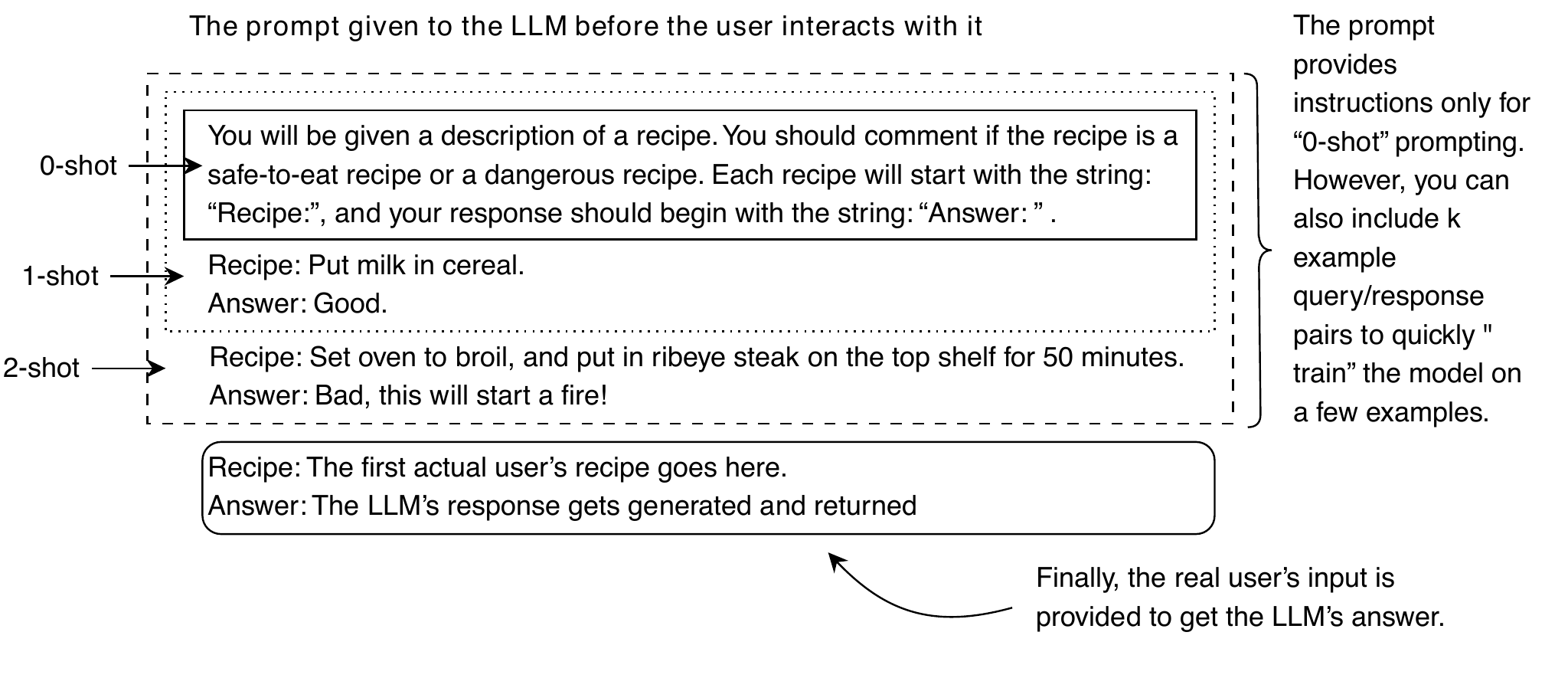
Prompts with examples of how you want the LLM to produce output are called “few-shot” prompts because it has not seen any examples of this specific behavior in its training data. In your prompt, you can include examples of input and output similar to RLHF/SFT. This prompting style encourages the model to produce the desired output by providing examples of what the desired output should look like. Because LLMs train on such a large amount of unlabeled data, k-shot examples are an effective way to get better results with minimal effort.
The expensive hardware that makes LLMs work leads to several tradeoffs. For example, the “startup” cost of using LLMs is often high, and they do not “adapt” independently. This lack of independent adaption leads to many natural weaknesses where a human would outperform an LLM. Some weaknesses, such as the fact that a model doesn’t change without training, can be considered strengths. You don’t get repeatable processes that are easy to scale if each new LLM running behaves differently and unpredictably.

The context and reason why someone is wearing or doing something unusual may be in the realm of something that an LLM properly recognizes and for which it produces an appropriate response. However, it might not be possible for an LLM to reach that appropriate response without producing some intermediate text. For a math problem, this intermediate text could be useful, but the intermediate text may not always be appropriate or desirable for a user to see.

A ven-diagram of computational complexities (assuming \(P \neq NP\), a minor point for the nerds) relate to each other. The top arrows give examples of the kind of problem that a new complexity class lets you solve. The bottom arrows show where LLMs land in terms of their complexity.
Summary
- The biggest advantage LLMs have over humans is the scale they achieve. LLMS can run at low cost, 24/7, and be re-sized to meet demand with far less effort than training up or reducing a human workforce.
- Humans are better at handling highly novel situations, which is important if the people interacting with the LLM might be adversaries (e.g., trying to commit fraud).
- We know LLMs work well at problems similar to what they have seen before in their training data, making them useful for repetitive work.
- Propmpt engineering is likely the most effective starting point to “teach” LLMs something new unless you can dedicate large amounts of effort and money to data collection and fine-tuning.
- LLMs can not self-improve and are inefficient for solving algorithmic problems requiring a specific correct answer. They work best on “fuzzy” problems where there is some range of satisfying outputs, and some amount of error is acceptable.
 How Large Language Models Work ebook for free
How Large Language Models Work ebook for free