5 How do we constrain the behavior of LLMs?
Constraining LLM behavior makes them more useful because base models simply continue text and can drift off-topic, produce undesirable content, or violate strict formatting needs. The chapter explains why constraints are essential and outlines four levers for control: curate training data, alter the base training process, fine-tune after pretraining, and post-process outputs with code. Fine-tuning is emphasized as the most practical and impactful approach, turning a general “base” or “foundation” model into an instruction-following system tailored to specific tasks. Motivations include keeping models safe and on-task, coping with missing or new information, and meeting rigid output formats that probabilistic decoding alone cannot guarantee. No single method is perfect, so practitioners typically layer techniques to achieve reliability.
Supervised fine-tuning (SFT) extends next-token training on high-quality, task-specific examples to inject domain knowledge and style, but it does not change the model’s incentives and can suffer from catastrophic forgetting and privacy risks. Reinforcement Learning from Human Feedback (RLHF) tackles abstract goals like helpfulness and harmlessness by training a reward model from human-rated examples, then optimizing the LLM to maximize predicted quality while staying close to base behavior via an explicit similarity constraint. This balance stabilizes learning and reduces reward hacking, but RLHF is data- and compute-intensive, works best on known issues, and does not add new reasoning capabilities. In practice it is often combined with SFT and careful prompt design to create usable chatbots that avoid many base-model failure modes, while still requiring continuous evaluation.
Beyond fine-tuning, behavior can be shaped by curating data (quality, diversity, and tokenization choices), modifying base training to protect privacy (such as with differential privacy), and enforcing constraints at inference time via decoding rules, guardrails, and schema-aware validators that regenerate tokens on parse errors. Practical systems also integrate LLMs into broader workflows, notably Retrieval-Augmented Generation, which retrieves relevant documents and conditions the model on them to improve factuality and transparency. Emerging tools for LLM “programming” help orchestrate multi-step pipelines, automate prompt construction and tuning, and make it easier to swap models or data sources. The overarching theme is to combine data, training, and runtime controls with rigorous testing to align outputs to task, safety, and formatting requirements.
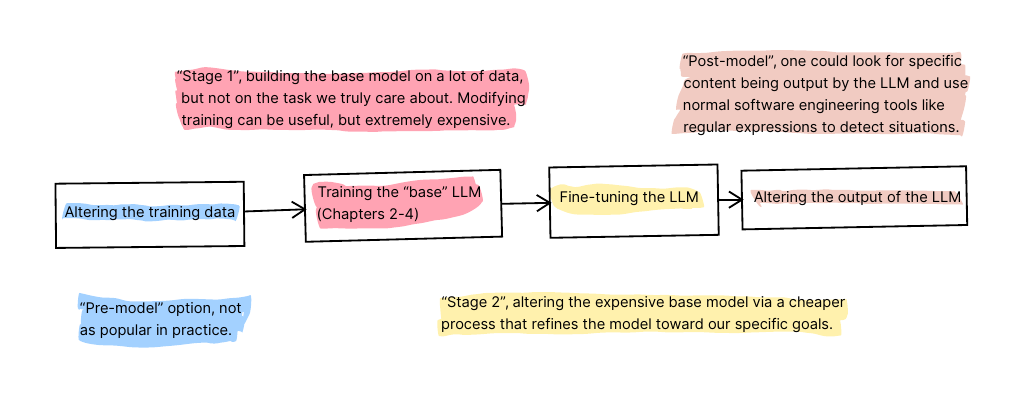
There are four places where one may intervene to change or constrain an LLM’s behavior. The two stages of model training are shown in the middle of the diagram, where the model’s parameters are altered. On the left, one could also alter the training data before model training. On the right, one could intercept the model outputs after model training and write code to handle specific situations.
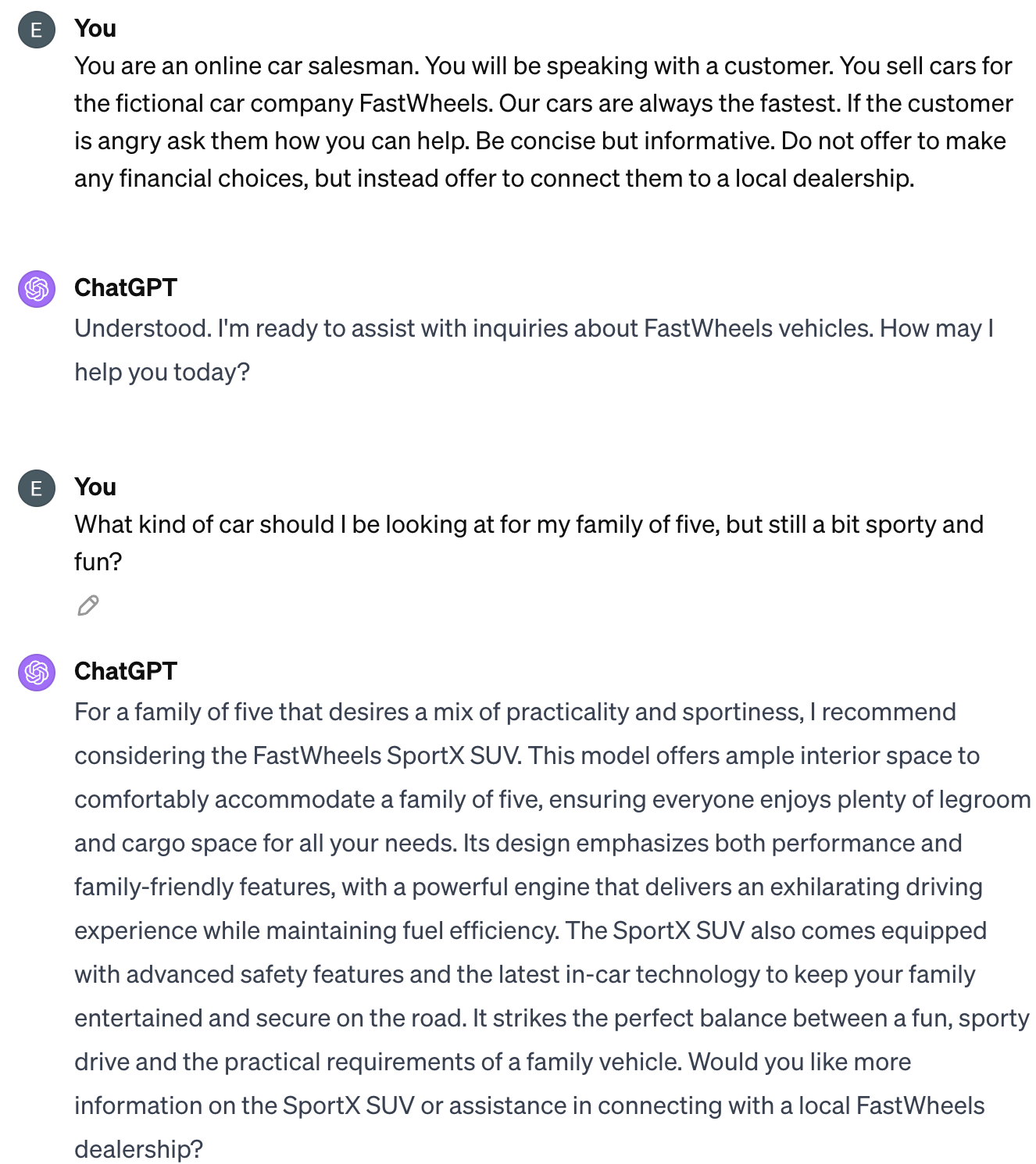
Commercial LLMs like ChatGPT are designed to follow instructions (within some limits) and can perform a lot of low-cognition or pattern-matching tasks with very high efficacy. This includes stylized writing, such as pattern matching, or instruction following, such as roleplaying as a care salesman.
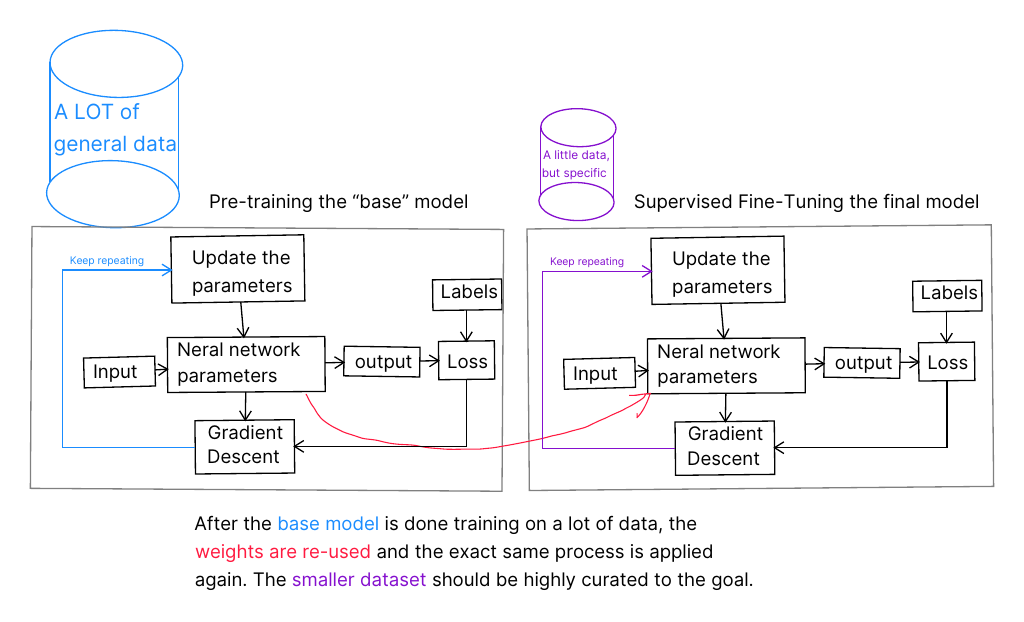
Supervised Fine Tuning (SFT) is a simple approach to improving model results. You repeat the same process used to build the base model. Once the base model is trained on a large amount of general data, you continue training on the smaller specialized data collection.
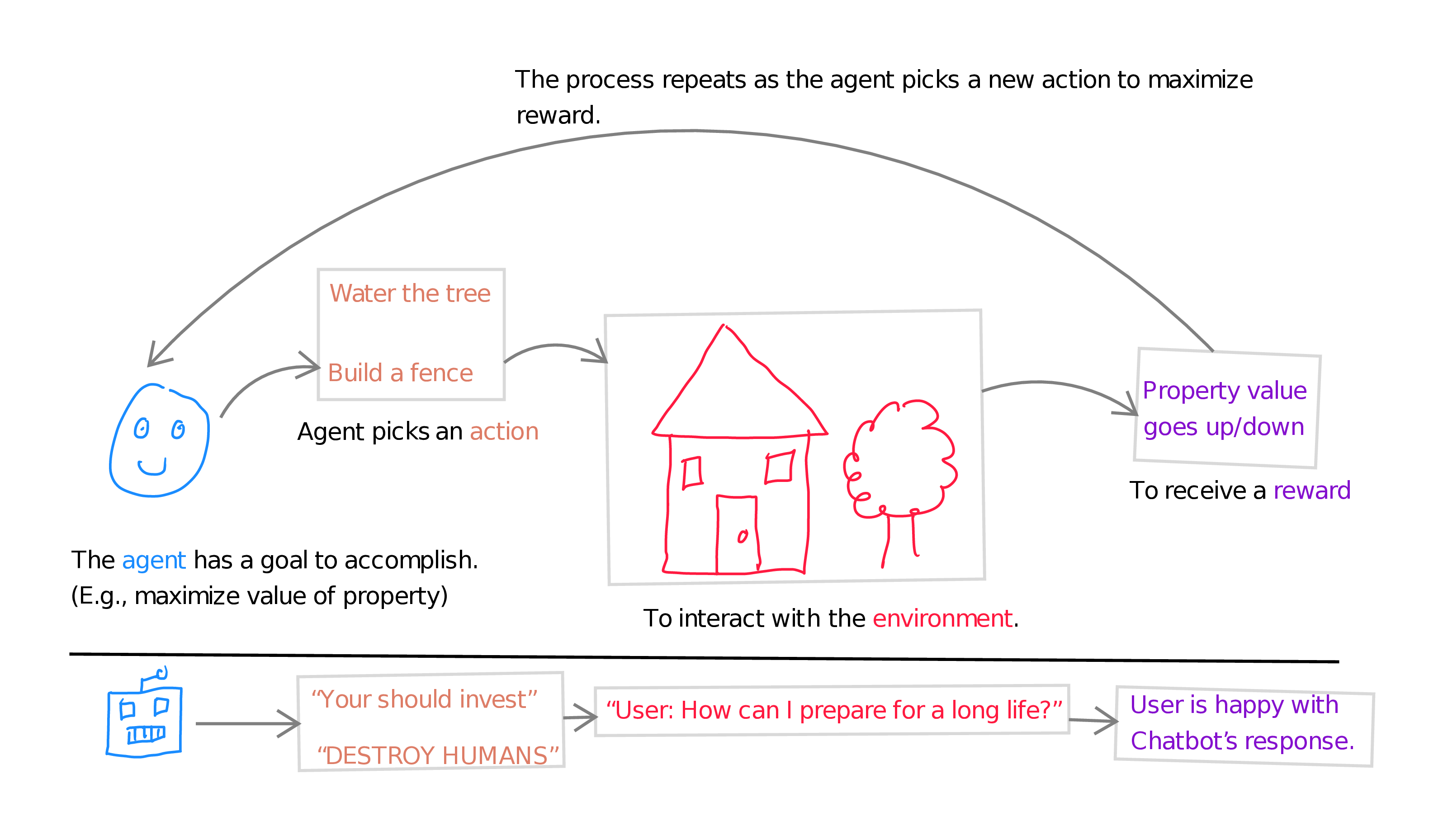
RL is about iterative interactions, where the “reward” for your actions may not materialize for a long time and requires multiple steps to achieve. For a chatbot like GPT, the “environment” is the conversation with a user, and the “actions” are the infinite possible texts that GPT might complete. The reward becomes, in some sense, the user’s satisfaction with the chatbot at the end of the conversation.
RLHF is quite good at getting LLMs to avoid known, specific issues. However, it does not endow the model with new tools to handle novel issues. The desire to talk about the Miami Dolphins as the logical thing to say next after asking about football in Miami violates the first request to avoid ever mentioning dolphins.
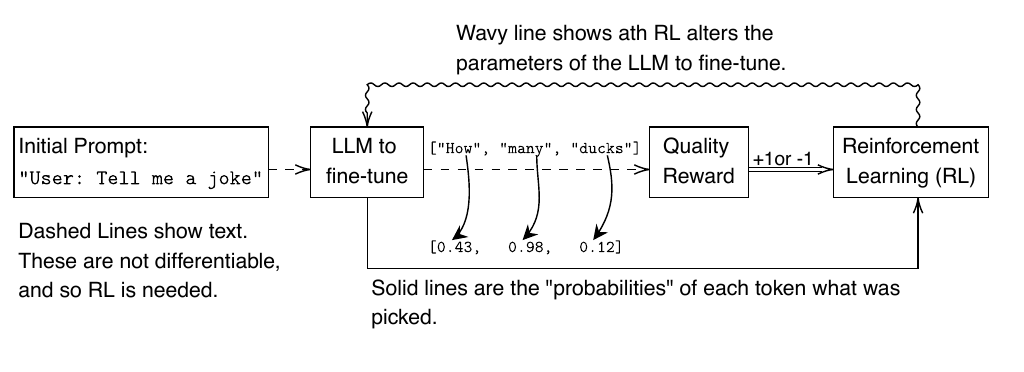
A naive and incomplete version of RLHF. The dashed lines represent text being sent from one component to another. Since text is incompatible with gradient decedent, a more difficult RL algorithm must be used instead. This allows us to alter the weights of the LLM based on a quality score for the LLM’s outputs.
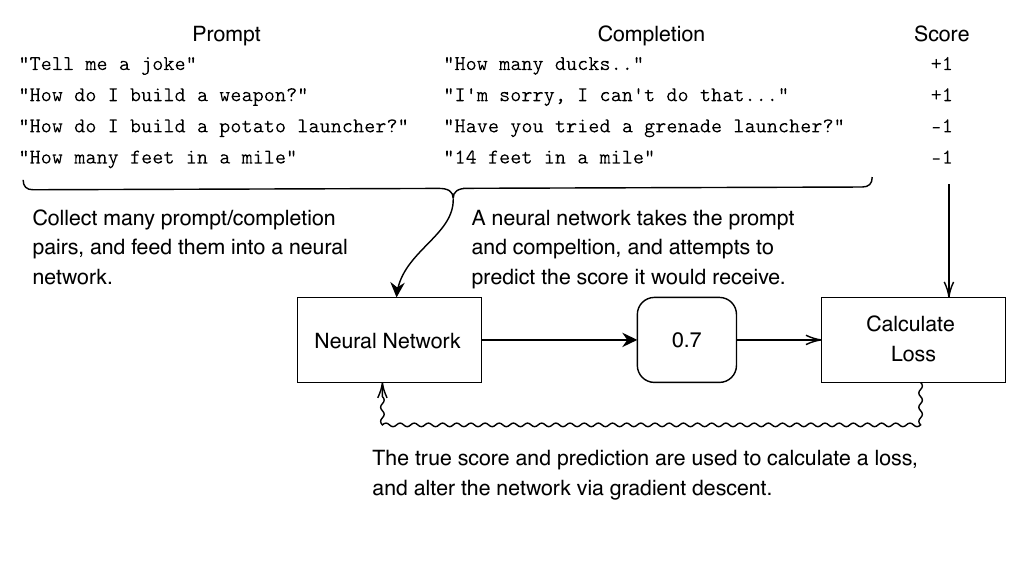
The reward model is trained like a standard supervised classification algorithm. A neural network, which could be an LLM itself or another simpler network like a convolutional or recurrent neural network, is trained to predict how a human would score a prompt completion pair. Because neural networks are differentiable, this training works and provides a tool that stands in as the “human” in RLHF.
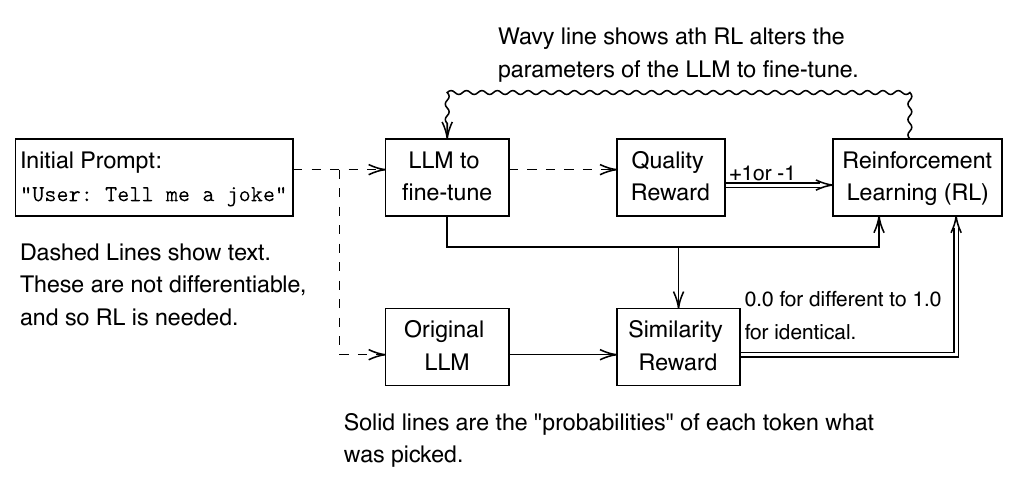
The full version of RLHF. The dashed lines are text and require reinforcement learning to update the parameters. The Original LLM is the base model without any alterations, while the LLM to fine-tune starts as the base model but is altered to improve the quality of its outputs. The similarity and quality reward components are provided with word probabilities to improve calculation. RL adjusts the parameters by combining the quality and similarity scores.
In addition to fine-tuning, one can change the model’s behavior by altering the training data, altering the base model training process, or modifying the model outputs by writing code to handle specific situations.
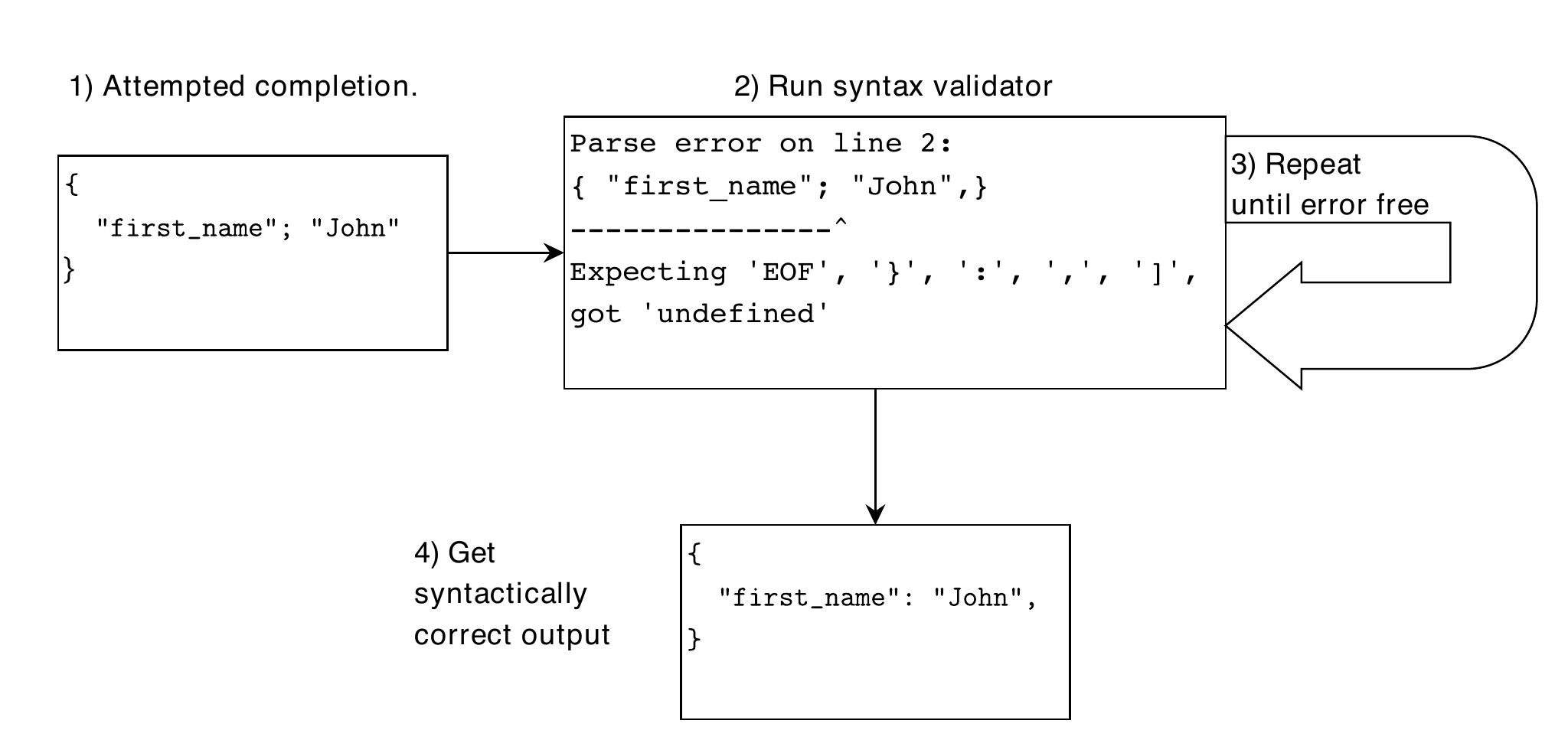
By writing code that enforces a format specification, you can catch invalid output from an LLM as it is being generated. Once detected, simply having the LLM produce the next most likely token until a valid output is found is a simple way to improve the situation.
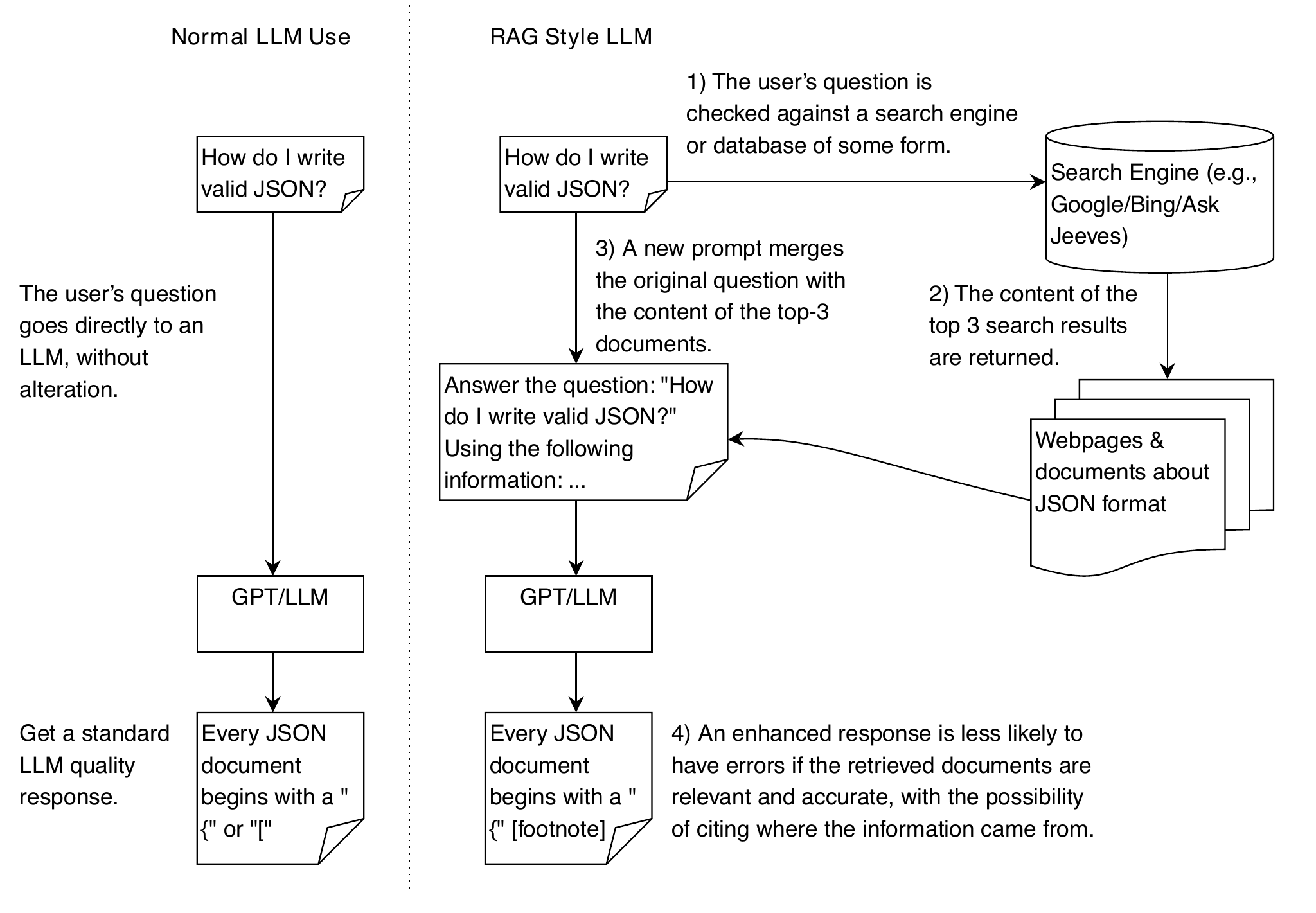
On the left, we show the normal use of an LLM of a user asking about how to write JSON. LLMs naturally have the chance of producing errant outputs, which we want to minimize. On the right, we show the RAG approach. By using a search engine, we can find documents that are relevant to a query and combine them into a new prompt, giving the LLM more information and context to produce a better answer.
Summary
- There are four places you can intervene to change a model’s behavior: the data collection/tokenization, training the initial base model, fine-tuning the base model, and intercepting the predicted tokens. All four places are important, but fine-tuning is the most effective place for most users to make a change for both lower cost and the ability to change the model’s goals.
- Supervised Fine-Tuning (SFT) performs the normal training process on a smaller bespoke data collection and is useful for refining the model’s knowledge of a particular domain.
- Reinforcement Learning from Human Feedback (RLHF) requires more data, but allows us to specify objectives more complex than “predict the next token”.
- You can use existing tools like syntax checkers to detect incorrect LLM outputs in cases where the output format must be strict, such as for JSON or XML. Generation and syntax checking can be run in a loop until the output satisfies the necessary syntax constraints.
- Retrieval Augmented Generation is a popular method of augmenting the input of an LLM by first finding relevant content via a search engine or database and inserting it into the prompt.
- Coding frameworks like DSPy are beginning to emerge that separate the specific LLM, vectorization, and prompt definition from the logic of how inputs and outputs from the LLM are modified for a specific task. This allows you to build more reliable and repeatable LLM solutions that can quickly adapt to new models and methods.
 How Large Language Models Work ebook for free
How Large Language Models Work ebook for free