4 How does GPT Learn?
This chapter demystifies how large language models, like GPT, are trained and clarifies why calling this process “learning” can be misleading. Rather than acquiring knowledge like humans, these models are optimized mechanically through mathematics: a loss function measures how poorly the model performs, and gradient descent repeatedly tweaks billions of parameters to reduce that loss. Training proceeds in tiny steps, often using stochastic gradient descent and optimizers like Adam, which trade extra memory for faster, more reliable progress. The emphasis is on computability and efficiency, not understanding or reasoning.
A good loss must be specific, computable, and smooth; when direct objectives (such as accuracy) are not smooth, proxy losses like cross-entropy are used. GPT is trained to mimic human text via next-token prediction, receiving reward when its outputs resemble its training data. This creates an incentive mismatch: the model becomes better at producing plausible text, not necessarily truthful or logically consistent text, and can absorb biases or errors present in internet-scale data. Despite this, contextual pattern-matching across vast corpora enables strikingly coherent outputs that can appear like reasoning, even though the process is fundamentally predictive rather than deliberative.
These training dynamics explain common failure modes and practical guardrails. GPT struggles with novel or sparsely represented tasks, can misidentify what task is being asked, and cannot plan or pre-commit to hidden states, leading to brittle behavior in puzzles or multi-step games. Effective use focuses on well-scoped, familiar tasks; adding retrieval or citations, constraining inputs and prompts, and supplying structured exemplars can improve reliability. While scaling transformers generally improves performance (“bigger is better”), real-world deployment must balance accuracy against cost, latency, memory, and device constraints, guiding careful product design around where LLMs succeed and where they predictably fail.
Investment returns are not easy to predict partly because they are not smooth. Image modified under Creative Commons license from Forsyth, J. A., & Mongrut, S.. (2022). Does duration of competitive advantage drive long-term returns in the stock market?. Revista Contabilidade & Finanças, 33(89), 329–342. https://doi.org/10.1590/1808-057x202113660.
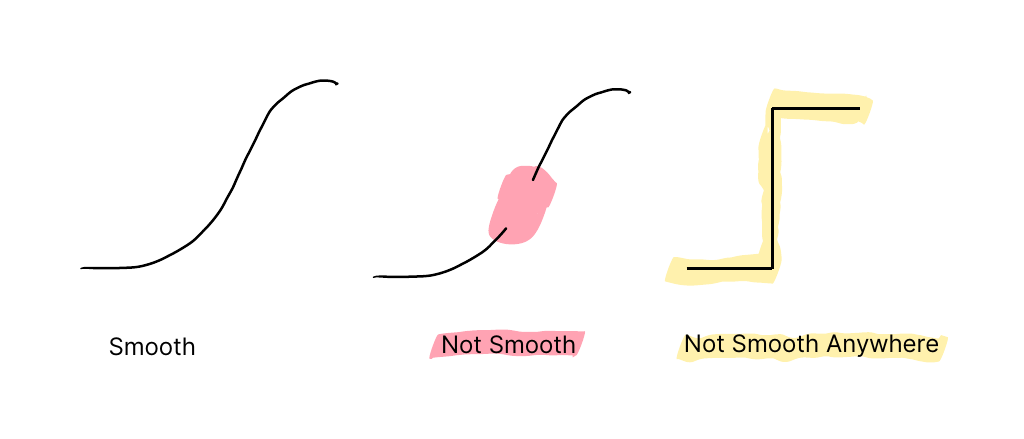
Examples of a smooth function on the left and two non-smooth functions on the right. The center example is mostly smooth, but there is a region where it is not smooth because the function has no value. On the right, the function is not smooth anywhere due to the hard change in value.
Inputs and labels (the known correct answer for each input) are used to tweak the neural network during gradient descent. A network is made of parameters that are altered a small amount each time gradient descent is applied. We eventually transform the network into something useful by applying gradient descent millions or billions of times.

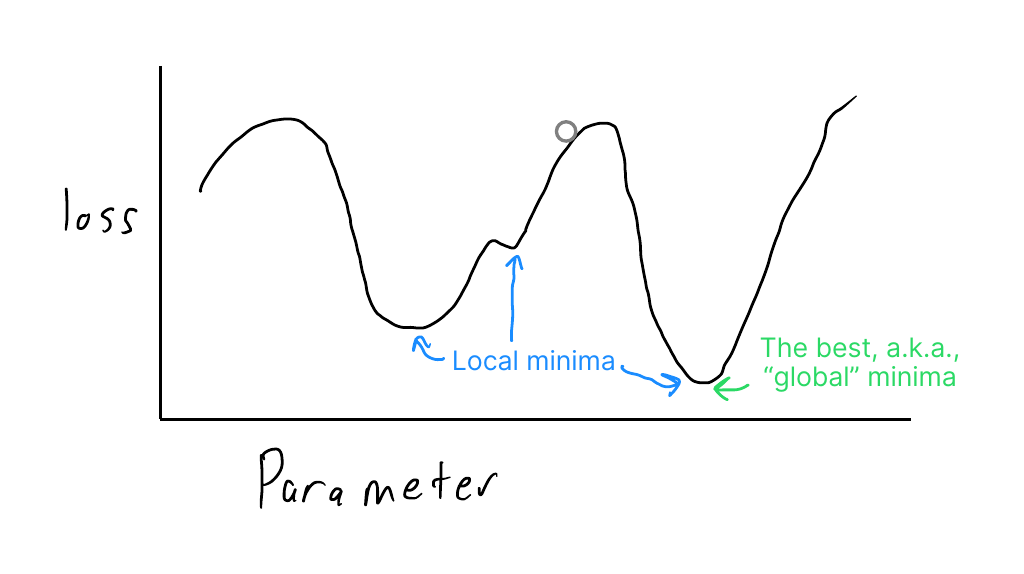
This shows the global big-picture of gradient descent applied to a single parameter problem. The curve illustrates the value of the loss function for a given parameter value. The ball’s location shows the loss for the current parameter value. The goal is to find the parameter values corresponding to a global minimum representing the ideal solution with the least loss.
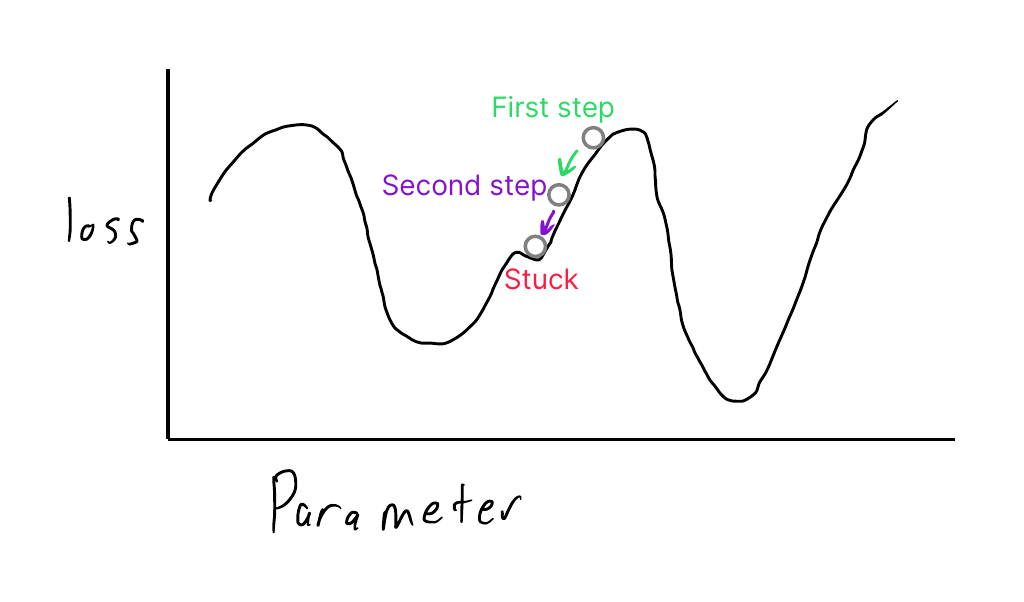
This figure shows the gradient descent algorithm taking steps to adjust parameters to find the optimal outcome with the least loss. Unfortunately, the algorithm gets stuck in a local minimum, an area of the graph that is not optimal because other parameter values correspond to areas with a lower loss.
GPT sees this sentence nine times, each time learning from the prediction of a single word at the end of each of the nine sequences.

Context can help you make decent predictions about the next word. As you move from left to right, additional text that might occur in a sentence is added. The images in the thought bubble for each sentence show how different the added context eliminates predictions.
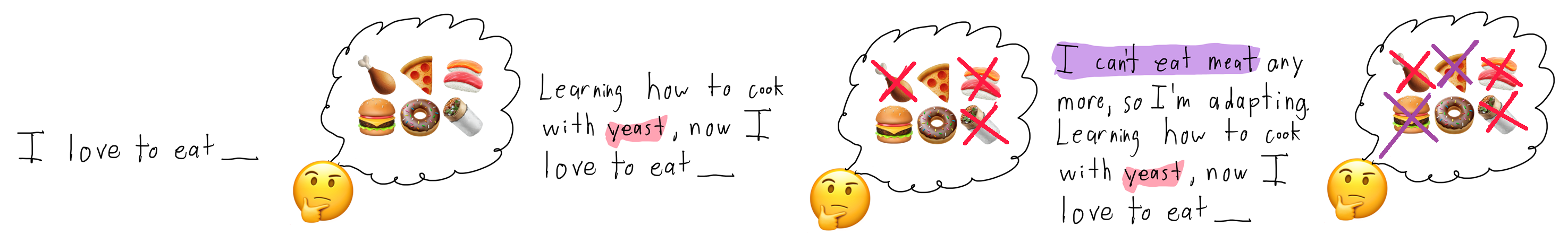
While predicting the next token is powerful, it doesn’t imbue the network with reasoning or logic abilities. If we ask Chat-GPT something absurd and untrue, it happily explains how it happens.

GPT fails to solve two modified versions of a classic logic puzzle. This is due to how LLMs are trained. Content frequently occurring in the same general form (e.g., a famous logic puzzle) leads the model to regurgitate the frequent answer. This can happen even when the content is modified in important ways that are obvious to a person.

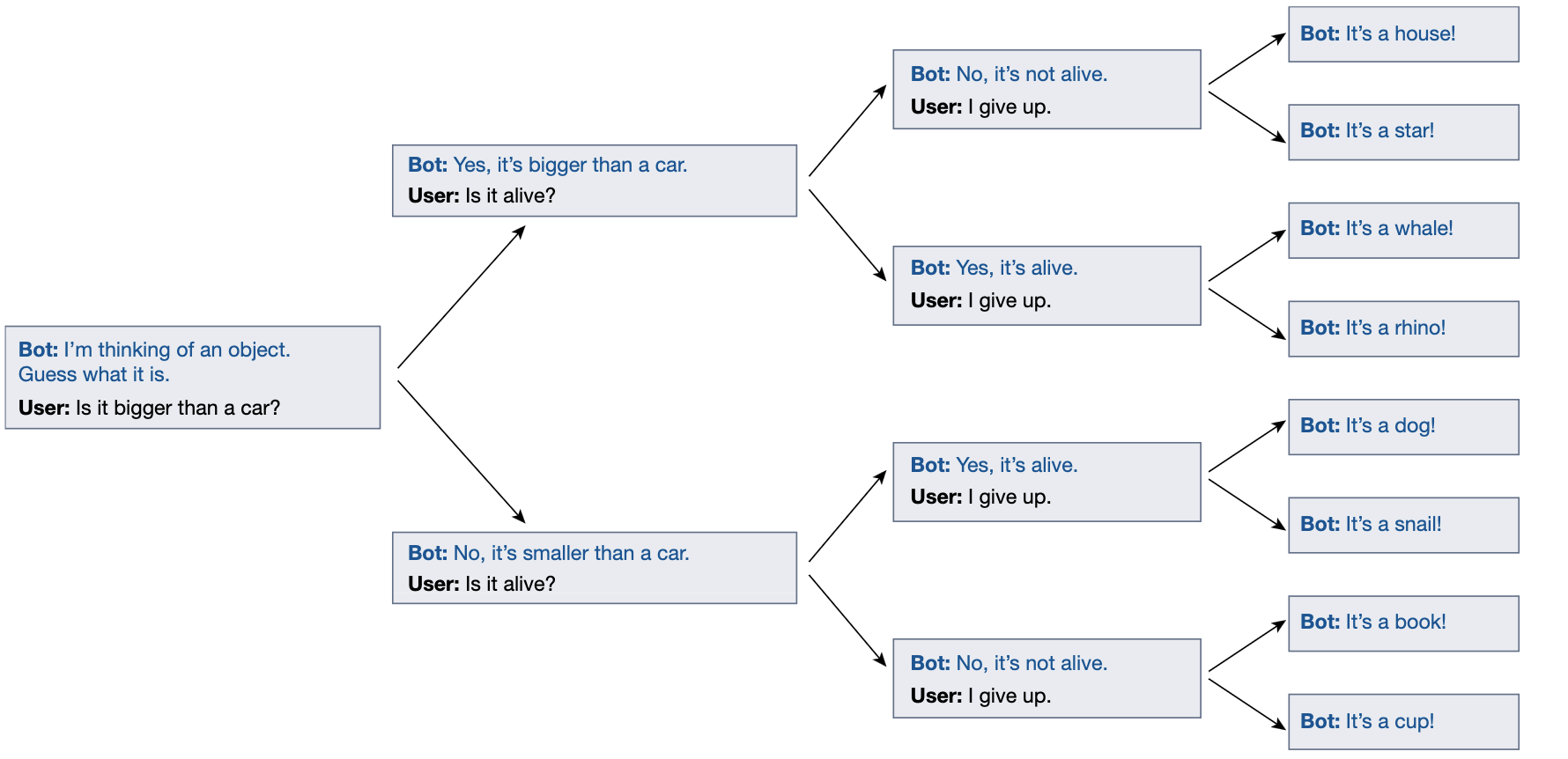
The dialogue agent doesn’t commit to a specific object at the start of the game.
Summary
- Deep learning needs a loss/reward function that specifically quantifies how “badly” an algorithm is at making predictions
- This loss/reward function should be designed to correlate with the overarching goal of what we want the algorithm to achieve in real life.
- Gradient Descent involves incrementally using a loss/reward function to alter the network’s parameters.
- GPT-like models are trained to mimic human text by predicting the next token. This task is sufficiently specific to train a model to perform it, but it does not perfectly correlate with high-level objectives like “reasoning”.
- GPT will perform best on tasks similar to common and repetitive tasks observed in its training data but will fail when the task is sufficiently novel.
 How Large Language Models Work ebook for free
How Large Language Models Work ebook for free