3 Transformers: How Inputs Become Outputs
Large language models treat text as tokens and generate outputs by repeatedly converting those tokens into numbers, transforming them, and mapping the results back to new tokens. This cyclical, statistical process is unlike human language use but is highly effective for predicting what comes next in a sequence. Modern models implement this with Transformers, architectures built to predict tokens rather than “understand” language in a human sense, and the chapter constructs a practical mental model for how inputs flow through the system to become coherent text.
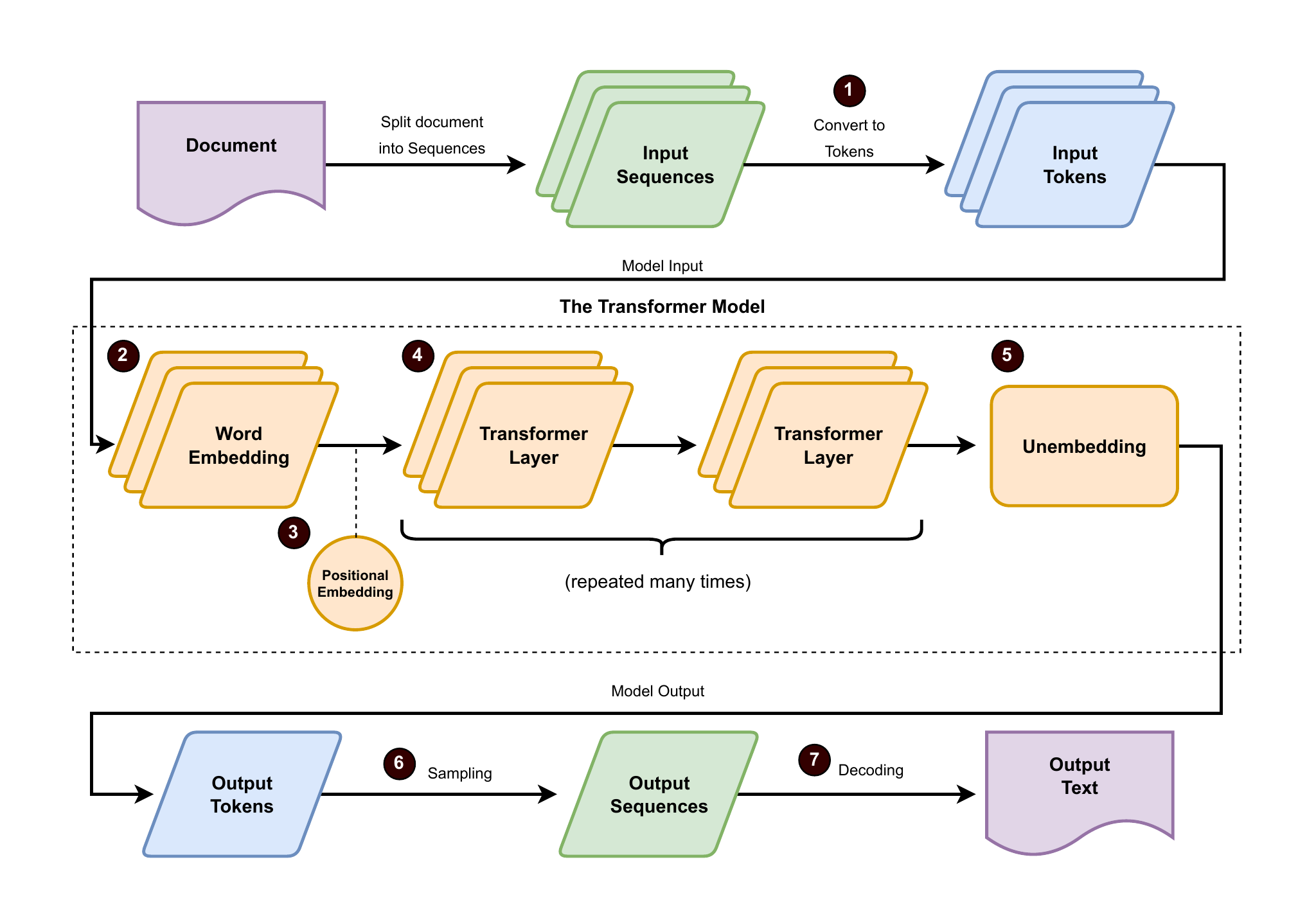
The pipeline begins with an embedding layer that turns tokens into high-dimensional vectors capturing meaning, augmented with positional information so order matters. Stacked transformer layers then apply attention, using queries, keys, and values to highlight the most relevant context and refine representations across many steps. Finally, an output (unembedding) layer converts internal vectors into a probability distribution over tokens; sampling selects the next token, making generation autoregressive—each new choice depends on the prior ones—until an end-of-sequence signal stops the loop. This probabilistic decoding explains why the same prompt can yield different valid continuations.
Transformers come in three main styles: encoder-only models that produce rich representations for tasks, decoder-only models that continue text by next-token prediction, and encoder-decoder models that map one passage to another, excelling at tasks like translation and summarization. Embedding spaces enable useful semantic relationships but bring trade-offs: more dimensions increase expressivity and cost, and patterns in data can imprint unwanted biases. During decoding, controls like temperature adjust the balance between conservative, on-topic responses and creative, surprising ones. Together, these components and choices explain how LLMs convert tokenized inputs into fluent outputs.
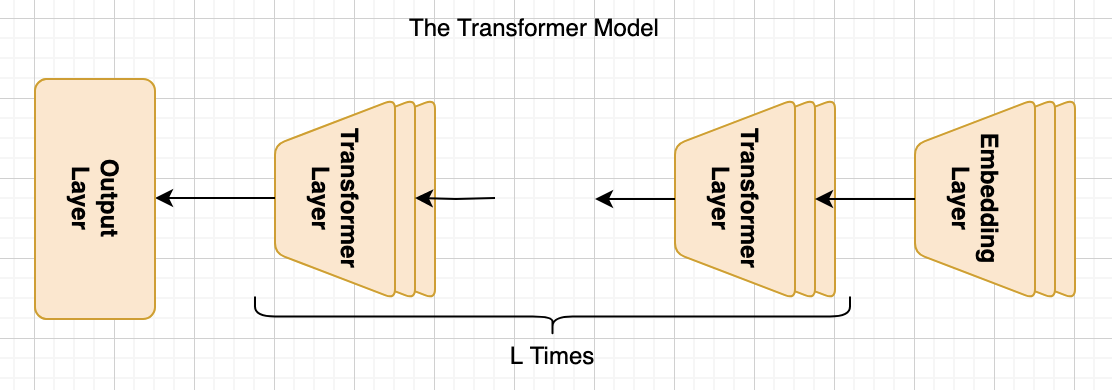
The basic components of the transformer model, consisting of the embedding layer, multiple transformer layers, and the output layer
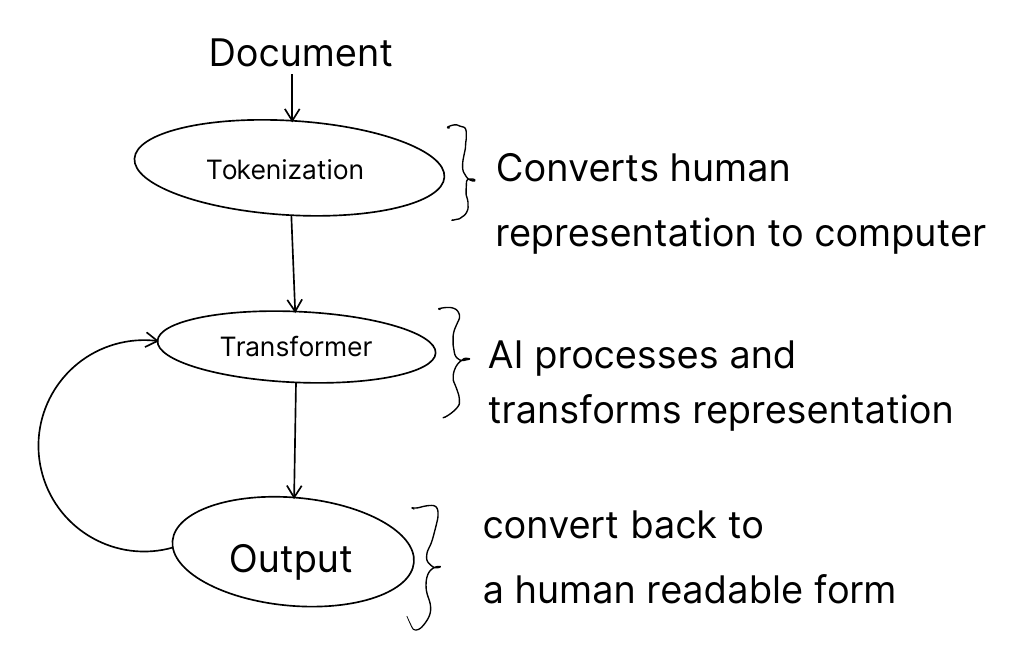
The full process going from a document to a transformer output
If you use just one number to represent a token, you quickly encounter problems where similar/dissimilar words can not be made to “fit” each other. Here we see how trying to represent simple synonym/antonym relationships quickly becomes nonsensical even with just a handful of words.

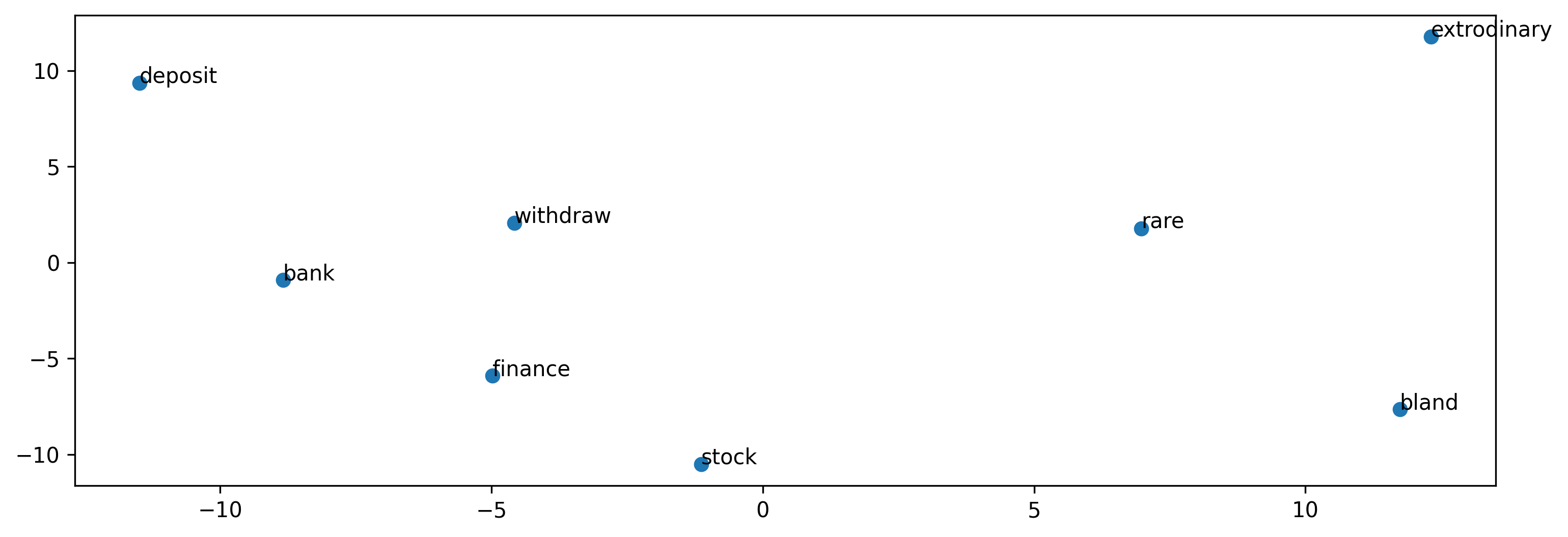
Adding another dimension to our token representation allows us to represent a more diverse arrangement of semantic relationships. Here, we see how different dimensions can capture relationships for multiple meanings of the same word
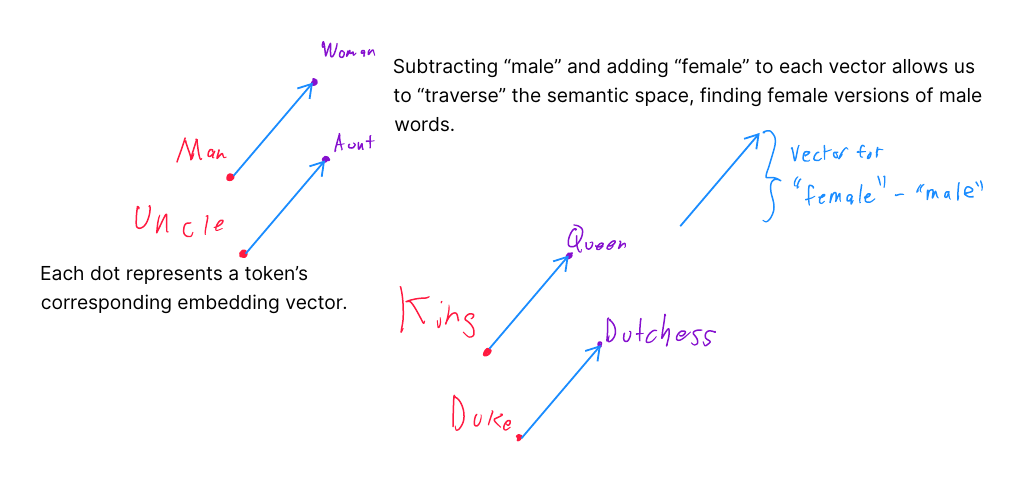
Demonstration of how the relationships are sufficiently useful makes the embeddings a “semantic space”. Words with similar meanings are near each other, but a single transformation of a word can be applied to multiple words to yield a similar result. In this instance, a transformation for finding the female version of a word.
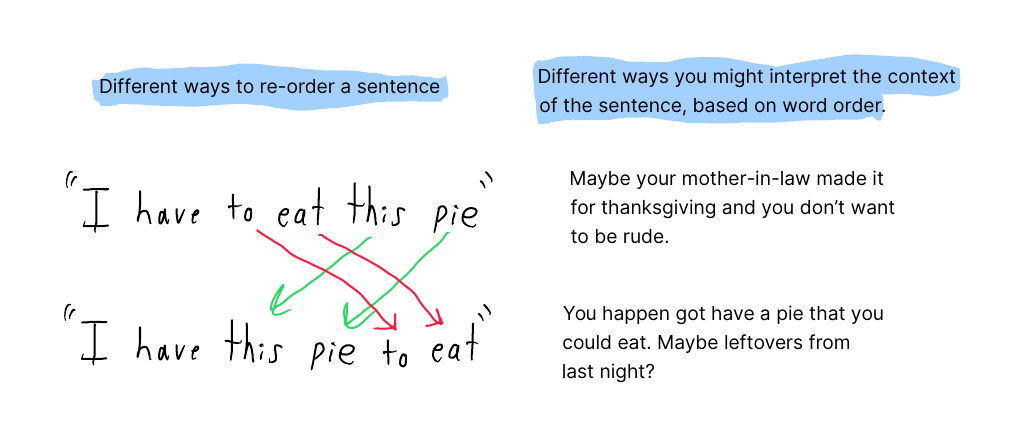
Because Transformers do not understand that their inputs have a specific order, all possible re-organizations of the tokens “look” identical to the algorithm. This is problematic because word order can change the word’s context or, if done randomly, become gibberish.
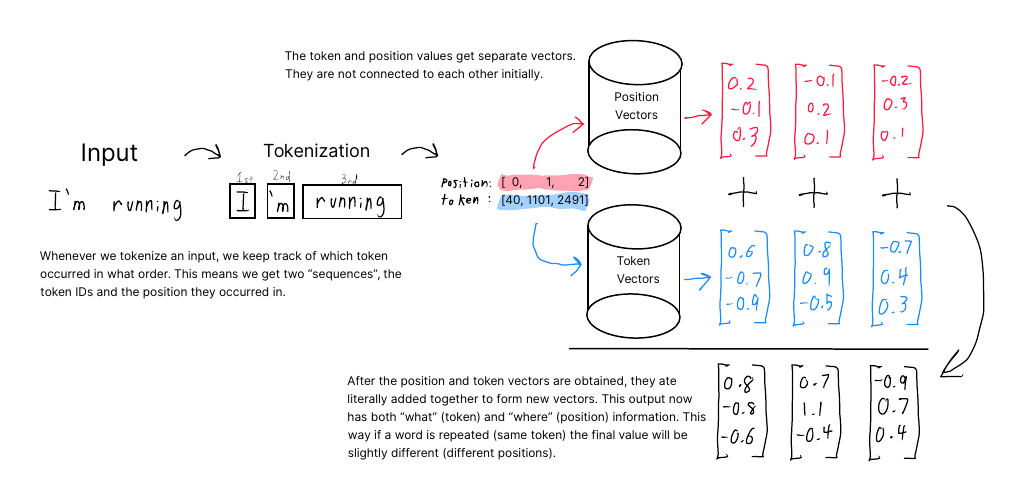
Transformer layers do not understand that the inputs have a specific order. This information about the order of tokens is endowed via a second “positional” encoding. The position embeddings work the same way as token embeddings and are added together. This provides the information the model needs on the order of tokens.
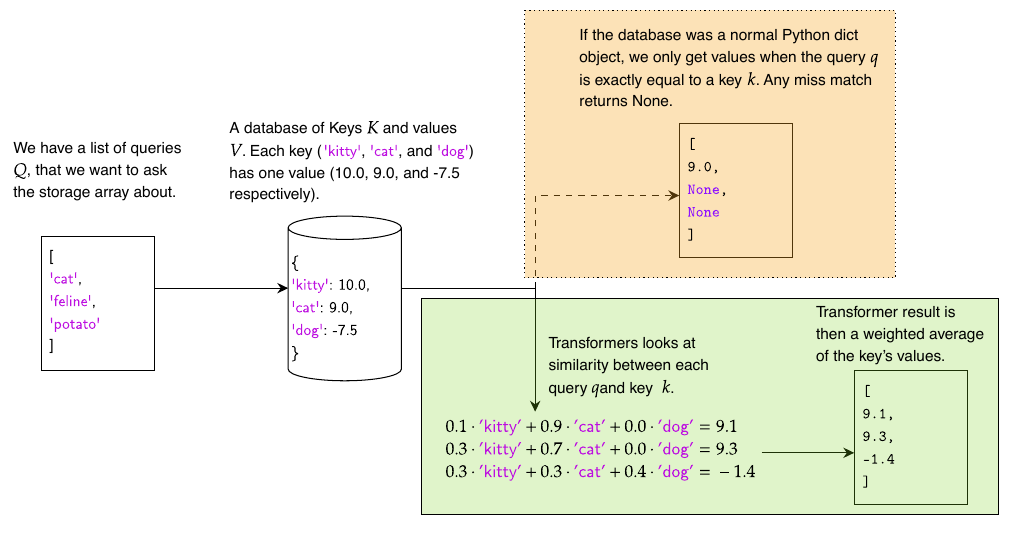
An example of how queries, keys, and values work inside a transformer compared to a Python dictionary. When a Python dictionary matches queries to keys, it needs an exact match to find the value, or it will return nothing. A transformer always returns something based on the most similar matches between queries and keys.
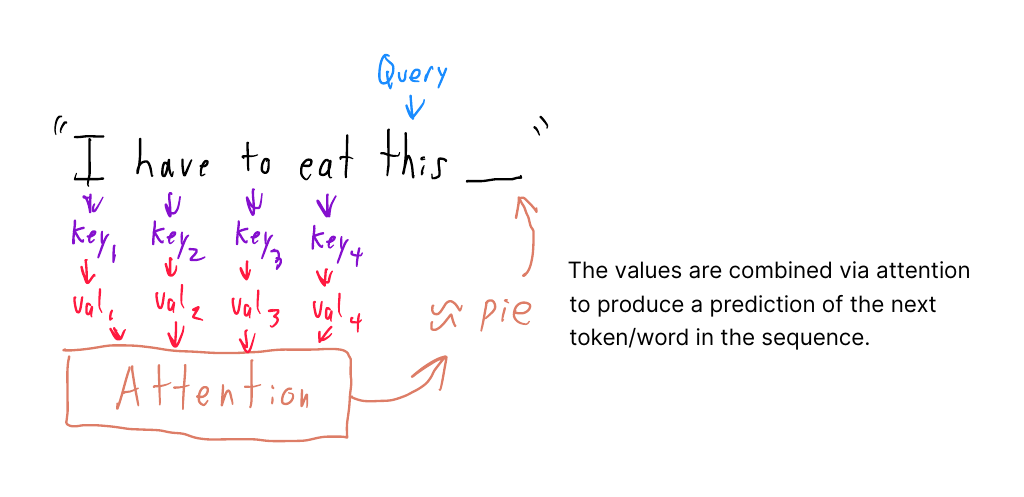
The next token in a sentence is predicted by using the current token as the “query” and calculating matches with the preceding words as the “keys”. The individual values themselves do not need to exist in the semantic space; the output of the attention mechanism produces something similar to one of the tokens in the vocabulary.
Producing output from LLMs involves converting from documents to tokens and then using the model to produce output. We loop through this process to both consume text and generate human-readable output
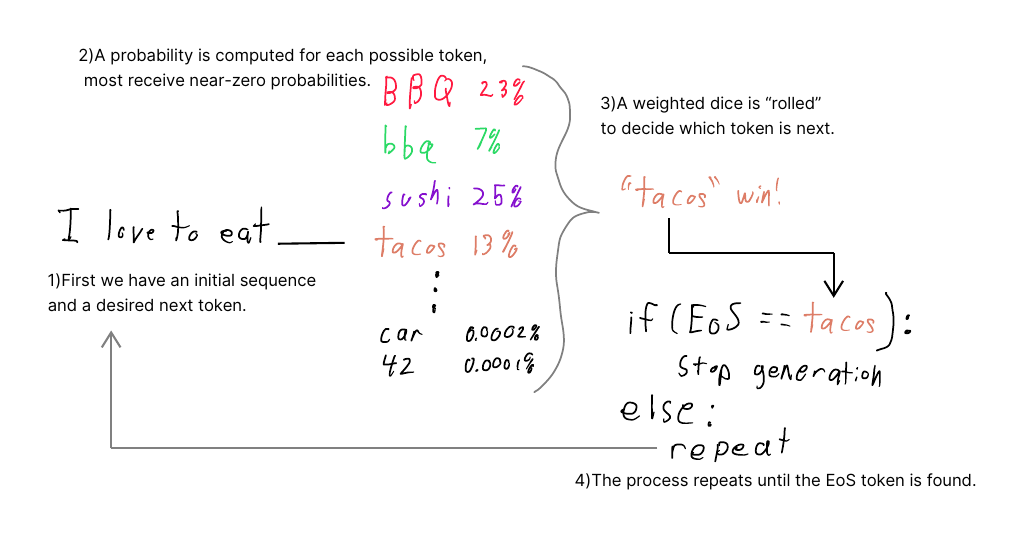
We demonstrate text generation by starting with the phrase "I love to eat" and then showing some possible completions that are foods, such as barbeque and sushi, have high probabilities, while a car and the number ’42’ have low probabilities. Weighted random selection chooses the word ’tacos’. The generation loop is stopped when the EoS token appears.
Summary
- While GPTs use tokens as their "basic unit of semantic meaning," they’re mathematically represented within the model as embedding vectors rather than as strings. These embedding vectors can capture relationships about nearness, dissimilarity, antonyms, and other linguistic descriptive properties.
- Position and word order do not come naturally to transformers and are obtained via another vector representing the relative position. The model can represent word order by adding the position and token embedding vectors.
- Transformer layers act as a kind of fuzzy dictionary, returning approximate answers to approximate matches. This fuzzy process is called attention and uses the terms Query, Key, and Value as analogous to the key and value in a Python dictionary.
- GPTs are examples of decoder-only transformers, but encoder-only transformers and encoder-decoder transformers also exist. GPTs are best at generating text, but other types can be better at other tasks.
- GPTs are autoregressive, meaning they work recursively. All previously generated tokens are fed into the model at each step to get the next token. Simply put, autoregressive models “predict the next thing using the previous things”.
- The output of any transformer isn’t tokens; instead, the output is a probability for how likely every token is. Selecting a specific token is called Unembedding or sampling and includes some randomness.
- The strength of this randomness can be controlled, resulting in more or less realistic output, more creative or unique output, or more consistent output. Most LLMs have a default threshold for randomness that is “reasonable looking,” but you may want to change it for different uses.
 How Large Language Models Work ebook for free
How Large Language Models Work ebook for free