2 Tokenizers: How Large Language Models See The World
Large language models cannot work directly with raw text; they rely on tokenization to convert sentences into numeric sequences the model can process. Tokens are typically sub-words that balance the granularity of letters with the semantic coherence of words, allowing models to generalize to unfamiliar terms while keeping vocabularies manageable. Because models “see” only token IDs—without inherent relationships like capitalization or morphology—tokenization becomes the core feature engineering step for LLMs, shaping both model size and the kinds of patterns it can learn.
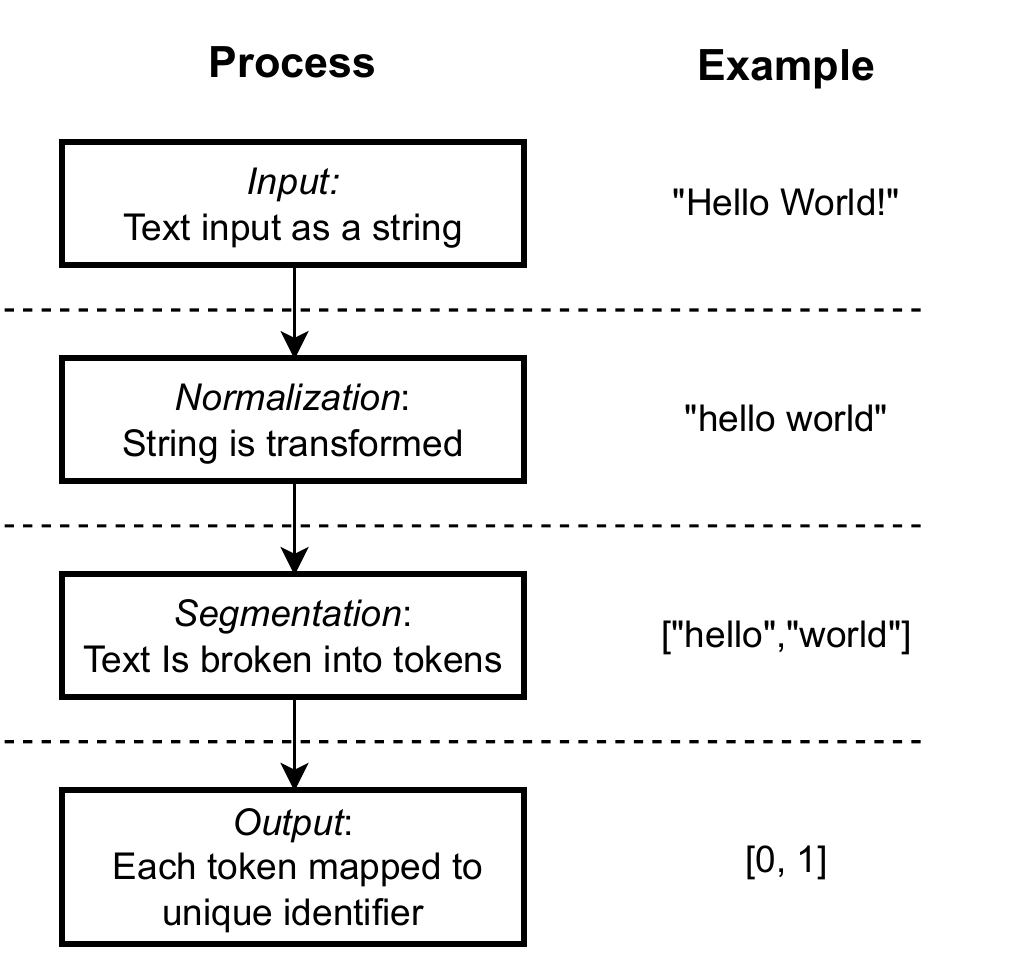
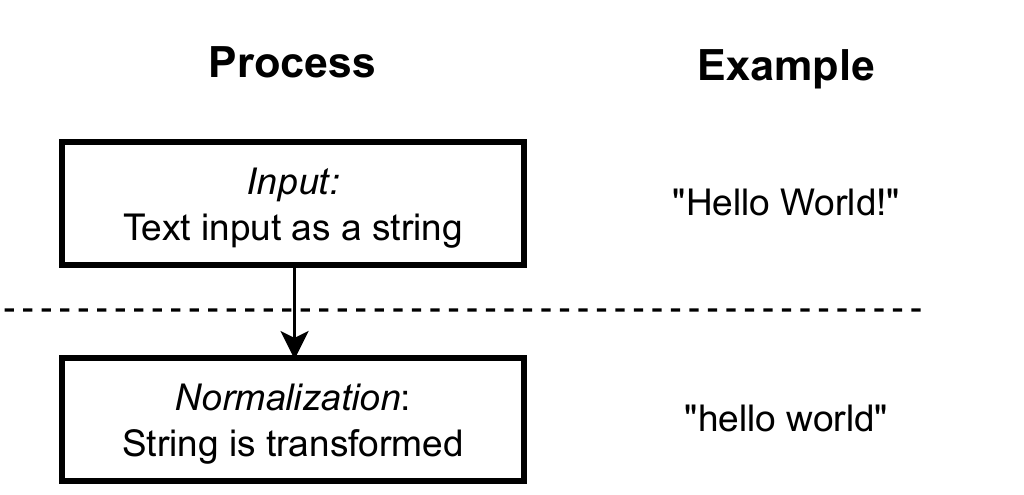
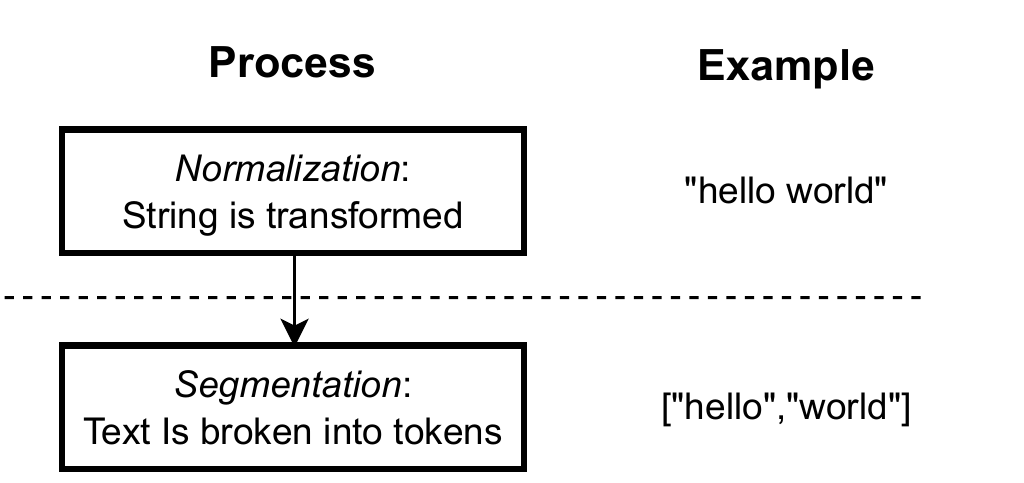
The tokenization pipeline involves four steps: receiving text, normalizing it, segmenting it into tokens, and mapping each token to a unique identifier while building the vocabulary. Normalization (e.g., lowercasing, punctuation handling) can shrink vocabularies and reduce ambiguity from typos, but it may also erase meaning (such as proper nouns) and reduce a model’s ability to correct errors. Modern systems therefore use minimal normalization and data-driven segmentation, most commonly via Byte-Pair Encoding, which learns frequent sub-word units to optimize coverage and efficiency. Vocabulary design includes tradeoffs in accuracy, speed, and memory, handling special tokens, and guarding against pitfalls like inconsistent tokenization, homoglyphs, and other encoding quirks that can create security and reliability issues.
Tokenization choices have direct consequences for model capabilities and equity. Tasks that depend on exact character sequences—word games, rare or misspelled drug names, poetry constraints—are challenging when models lack letter-level visibility. Math improves when digits are tokenized individually, illustrating how tailored token design can boost reasoning performance. Across languages, tokenization efficiency varies, affecting latency and cost: languages underrepresented in tokenizer training often require more tokens for the same content, increasing usage and potentially amplifying economic inequities. In practice, tokenization determines what an LLM can represent, how well it learns, and how fairly and efficiently it operates.
To understand text, LLMs must break text into tokens. Each unique token has a numeric identifier associated with it.

Generically, tokenization involves processing input to produce numeric identifiers for tokens.
The normalization process commonly involves changing text to remove upper-case characters and punctuation.
The segmentation process breaks normalized text into words or tokens so that each can be processed independently
A simplified Byte-Pair Encoding algorithm for creating tokens: First, find the most frequent pair of characters “ng”. Next, replace all instances of “ng” with a placeholder token “T”, and “ng” to the vocabulary. Repeat the process until no common byte pairs remain.

Tokenizing two different sentences.

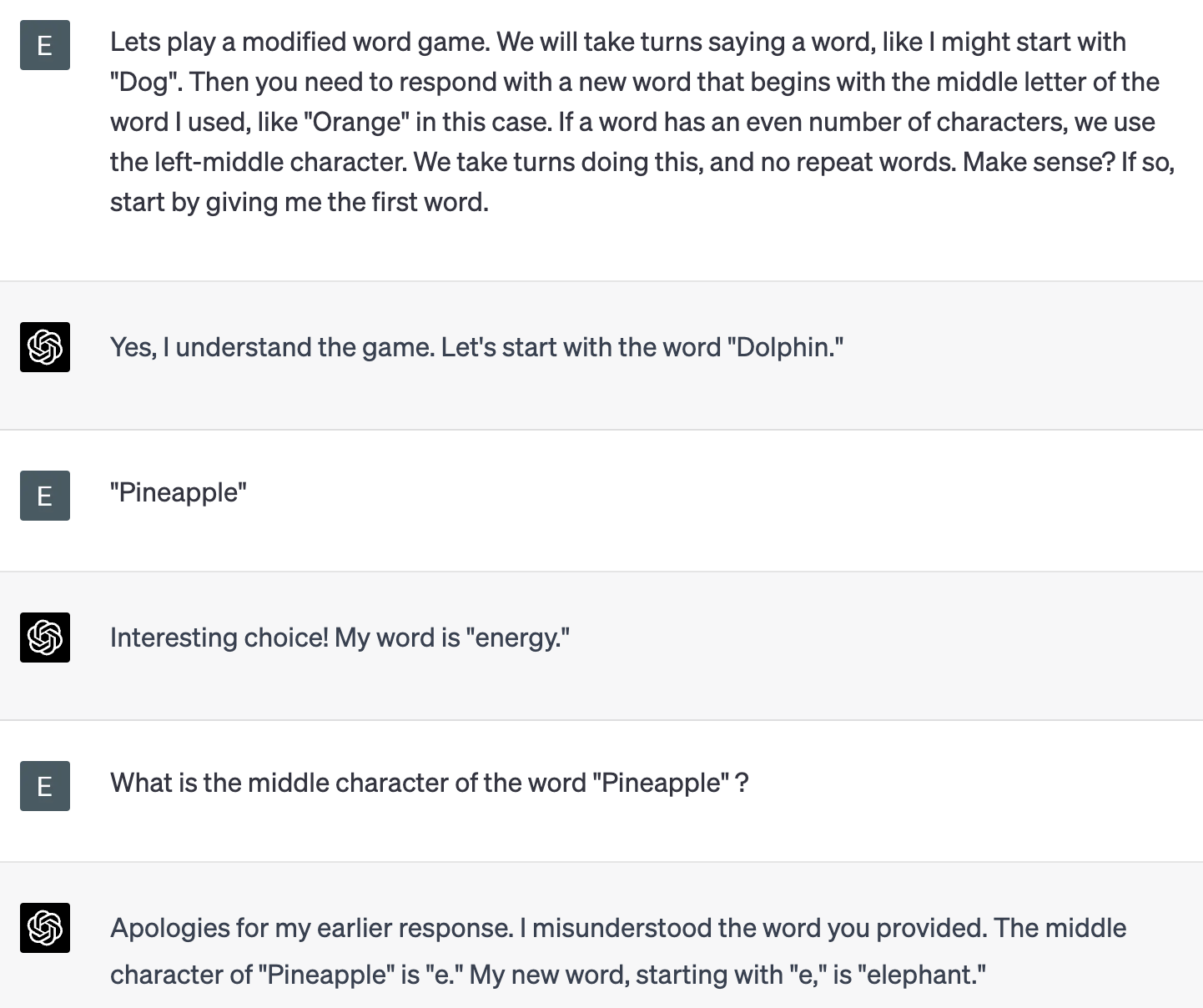
The tokenization approach means that GPT can not really “see” single characters or word lengths. If you ask questions that require sub-character identification and change them in a unique and unusual way, GPT starts to fail. The correct middle character is “a”, but GPT insists that the letter “e”. What GPT sees is three tokens, representing P, ine, and apple, respectively.
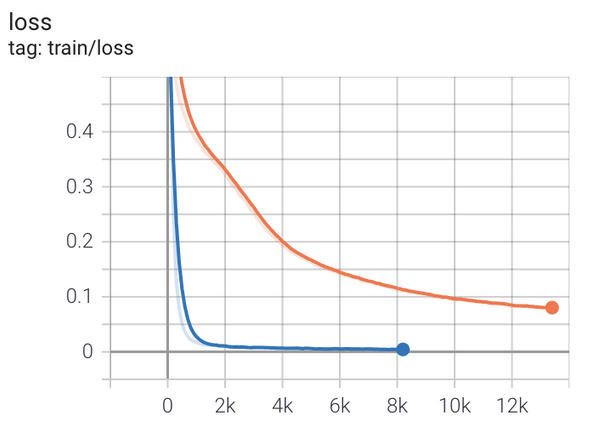
A comparison of how two LLMs learn to perform arithmetic computations over time. Time is shown on the x-axis. The upper curve is a typical BPE tokenizer, while the lower curve is the same tokenizer modified to use tokens that represent individual digits. The y-axis describes the ability of the LLM to perform accurately, where a smaller number means fewer errors. The bottom line is that LLMs that use digit-level tokenization can learn how to do math better and faster.
Summary
- Tokenization is the fundamental process that Large Language Models use to understand text by converting sentences into tokens.
- Tokens are the smallest units of information in text that represent content. Sometimes, they correspond to full words, but often, they represent pieces of words or sub-words.
- Tokenization involves normalizing text into a standard representation, which may involve converting characters to lowercase or translating the byte encoding of Unicode characters so that visibly identical characters employ the same encoding.
- Tokenization also involves segmentation, which is breaking up text into words or sub-words. Algorithms like Byte-Pair Encoding (BPE) provide a mechanism to automatically learn how to efficiently segment text based on the statistical occurrence of combinations of letters in a training data set.
- The result of building a tokenizer is known as a vocabulary, which is the unique collection of word and sub-word tokens that a tokenizer can use to represent text that it has processed.
- The size of a tokenizer’s vocabulary affects the LLM’s ability to accurately represent data and the storage and computational resources required to understand and predict text.
- Internally to the LLM, tokens are represented using numbers. As a result, there is no understanding of relationships between tokens, such as prefixes and suffixes, or the fact that two tokens share a similar set of letters.
- To support specific domains of knowledge, tokenizers trained automatically may be augmented to provide tokens that are important to their application.
- Tokenizers that do not understand individual letters or digits will have issues with arithmetic operations or simple word games.
 How Large Language Models Work ebook for free
How Large Language Models Work ebook for free