1 Understanding data-oriented design
This chapter introduces Data-Oriented Design as a way to build Unity games around the flow and transformation of data rather than around networks of interconnected objects. It frames DOD as a practical response to common game-development pressures: maintaining smooth performance, supporting complex gameplay, meeting deadlines, and keeping projects manageable as they grow. The central idea is to identify what data a system needs, organize that data efficiently, and write logic that processes it in clear, predictable steps.
A major focus is performance. Modern CPUs are extremely fast, but they often stall while waiting for data from main memory. DOD improves performance by arranging data so the CPU can reuse cache lines effectively, increasing cache hits and reducing cache misses. Instead of storing all enemy data inside individual objects, the chapter shows how storing positions, directions, velocities, and other values in separate arrays improves data locality. This lets systems process many game elements at once and makes the code naturally friendlier to CPU caches, SIMD-style processing, and parallel work.
The chapter also explains how separating data from logic can reduce complexity and improve extensibility. Rather than designing deep inheritance trees for every new enemy or behavior, DOD encourages developers to ask what new data a feature requires and what transformation should be applied to it. This makes gameplay systems easier to reason about, debug, and extend over time, especially in long-running or content-heavy games. Unity DOTS tools such as Burst, Jobs, ECS, and TransformAccessArray are presented as optional technologies that build on DOD principles, not as requirements for using DOD itself.
Screenshot from our imaginary survival game, with the player in the middle, and enemies moving around.

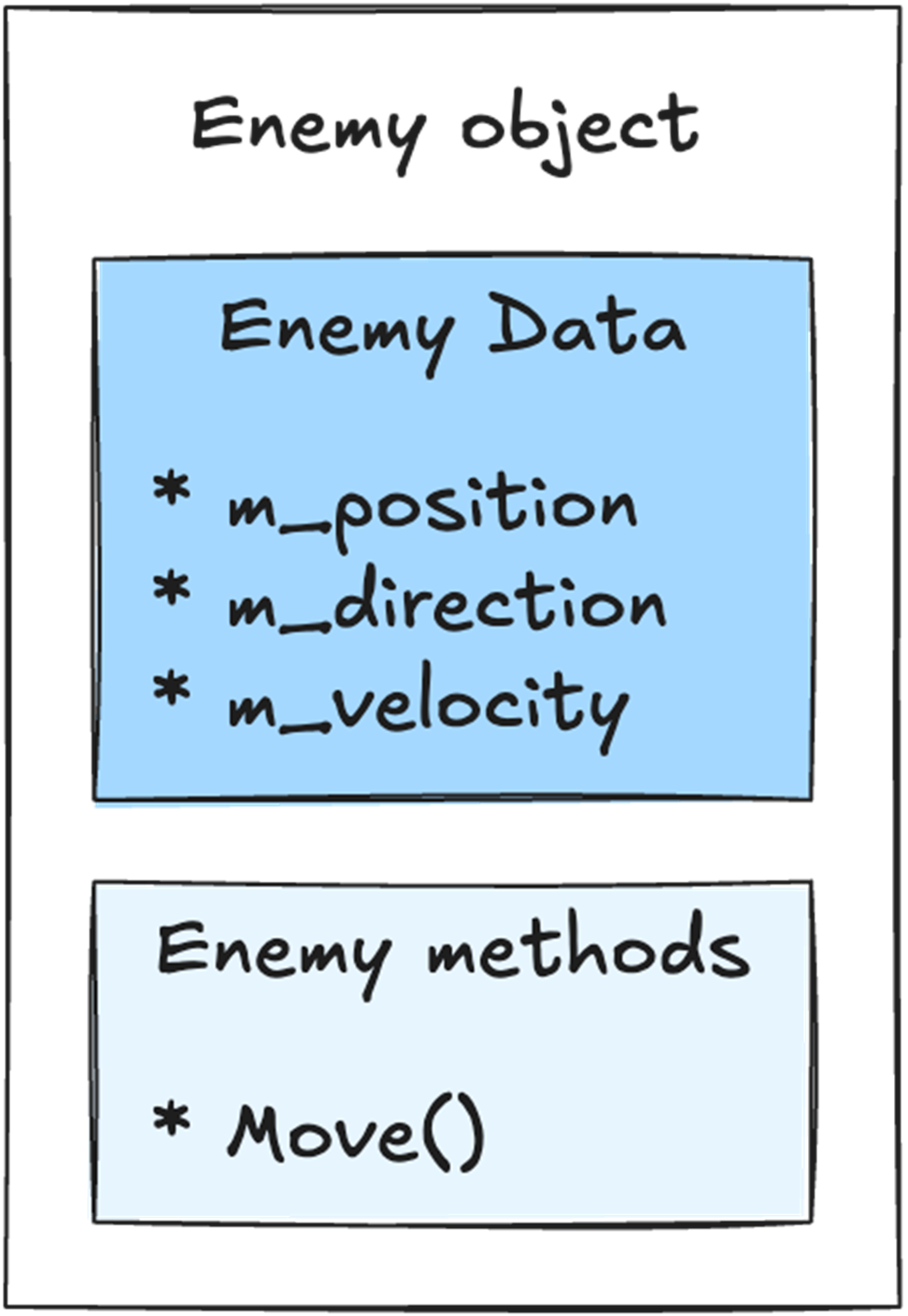
Our Enemy object holds both the data and the logic in a single place. The data is the position, direction, and velocity. The logic is the Move() method that moves this enemy around.
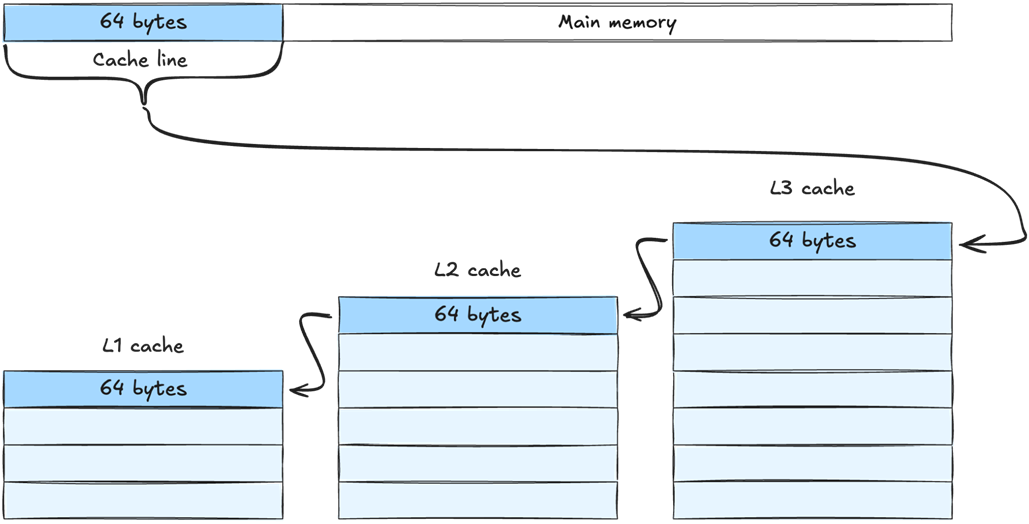
On the motherboard, the memory sits apart from the CPU, regardless if it’s in a console, desktop and mobile device. That physical distance, combined with the size of the memory, makes it relatively slow to retrieve data from memory.

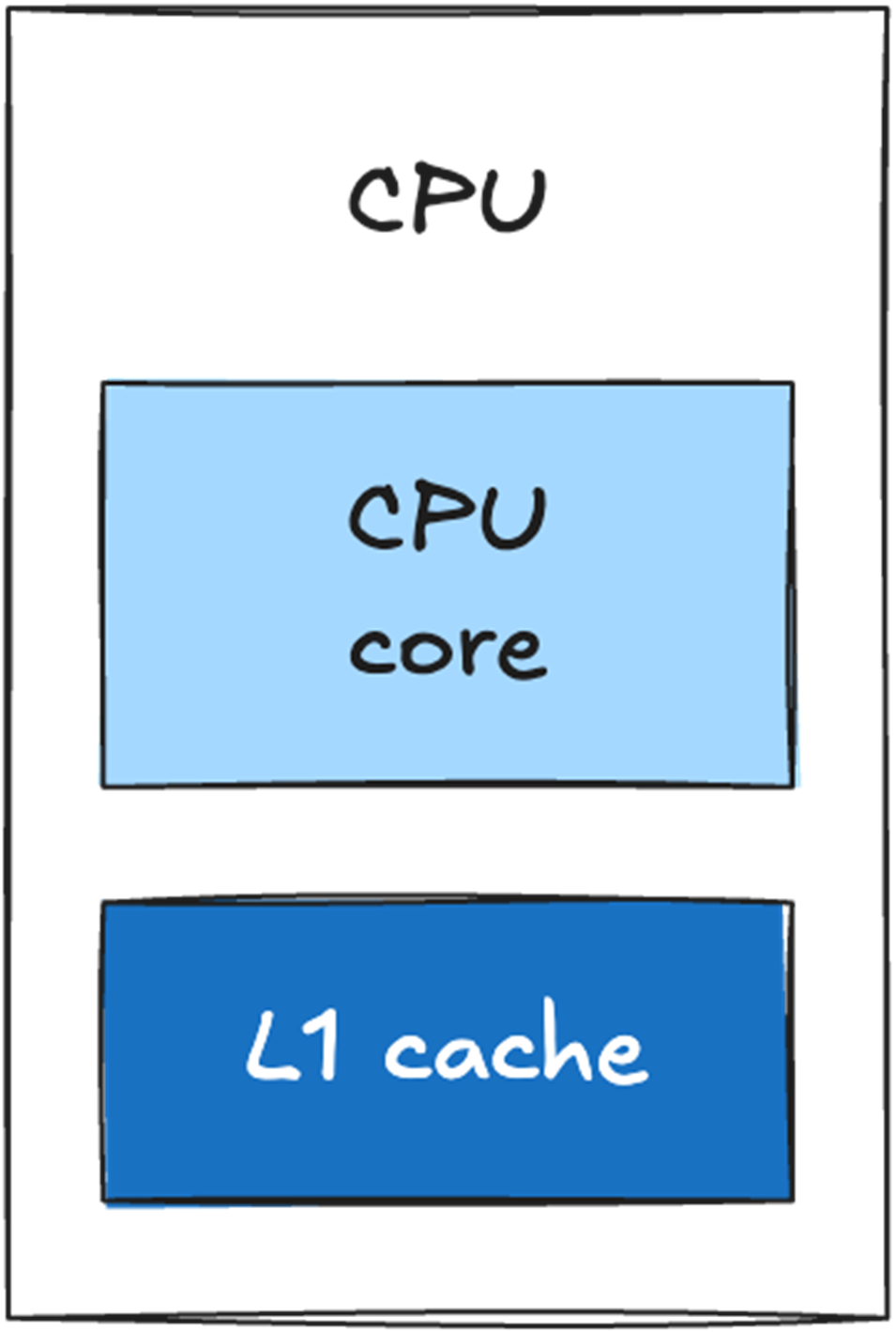
The cache sits directly on the CPU die and is physically small. Retrieving data from the cache is significantly faster than retrieving data from main memory.

A single-core CPU with an L1 cache directly on the CPU die.
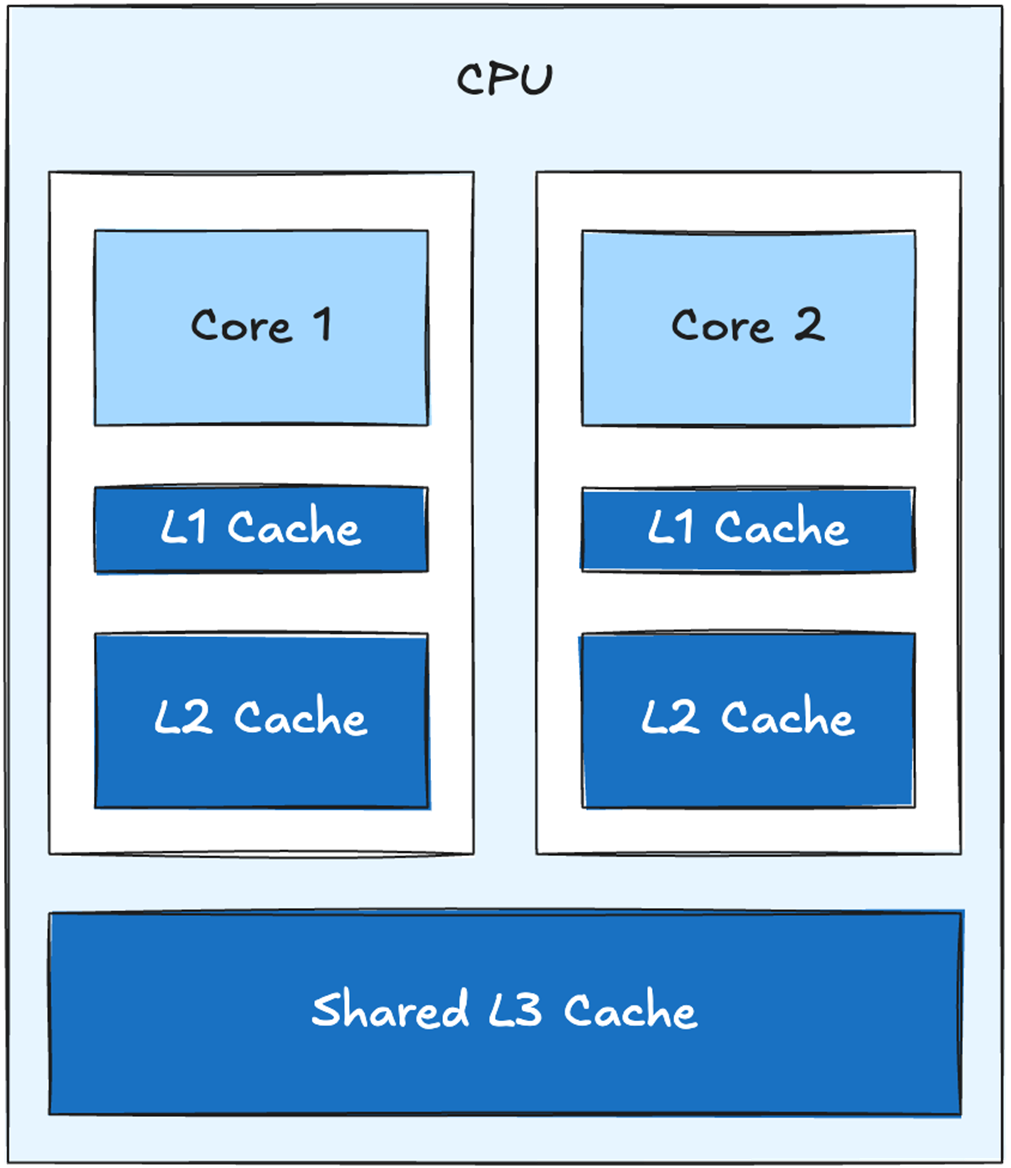
A 2-core CPU with shared L3 cache
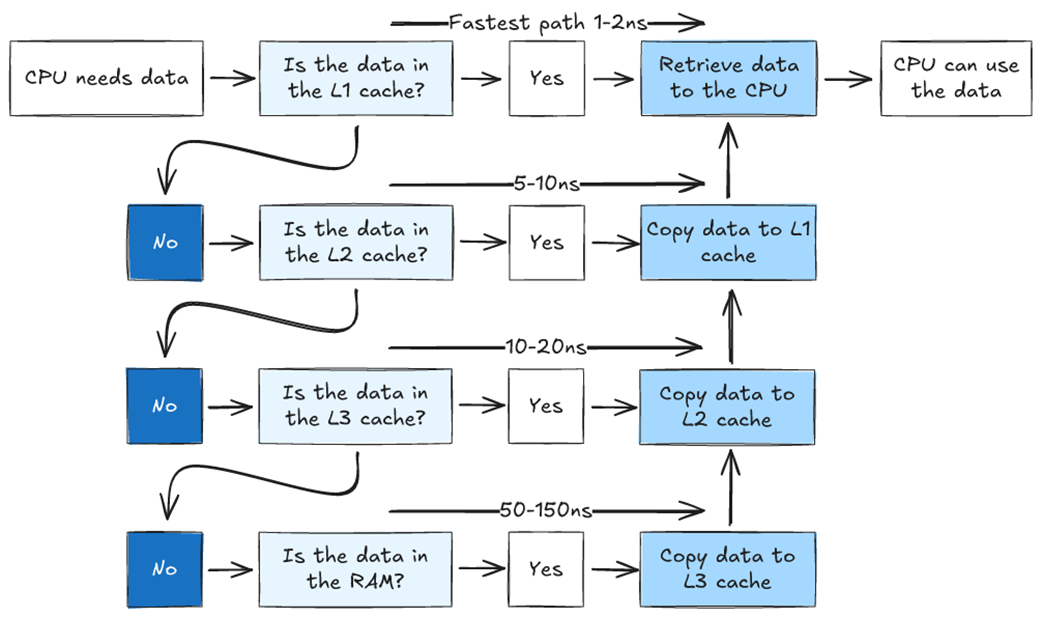
Flowchart showing how the CPU accesses data in a system with three cache levels. If the data is not found in the L1 cache, we look for it in L2. If it is not in L2, we look in L3. If it is not in L3, we need to retrieve it from main memory. The further we have to go to find our data, the longer it takes.
Data is retrieved from main memory in chunks called cache lines. When we ask for data from main memory, the memory manager retrieves the data we need, plus the chunk of data that comes directly after it, and copies the entire chunk to the cache.
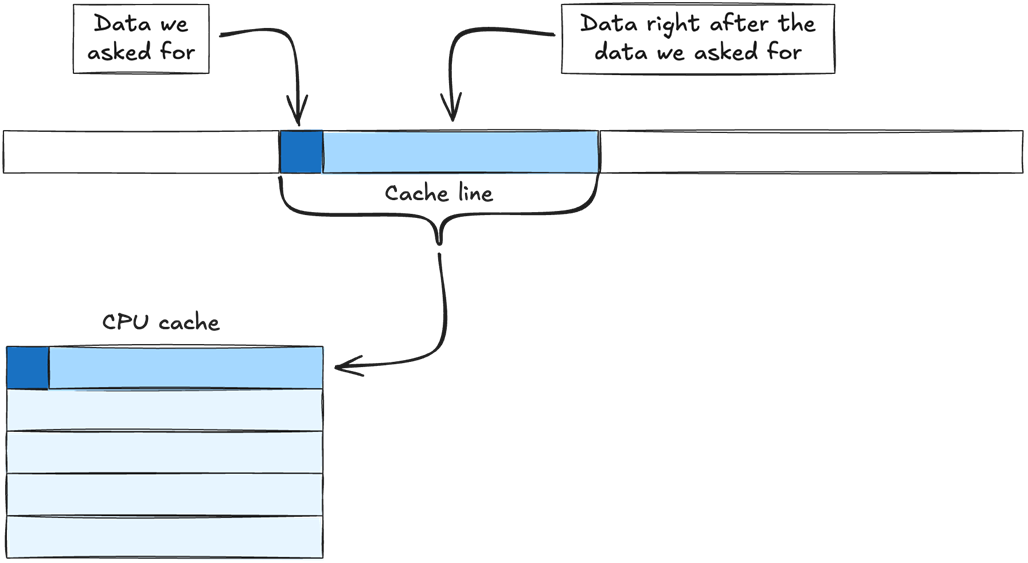
When retrieving a cache line from main memory, it is copied to all levels of the cache. In this example it is first copied to L3, then L2 and finally L1. The cache line is the same size at all levels - meaning the same amount of data is copied to every level. L3 can simply hold more cache lines than L2, and L2 can hold more cache lines than L1.
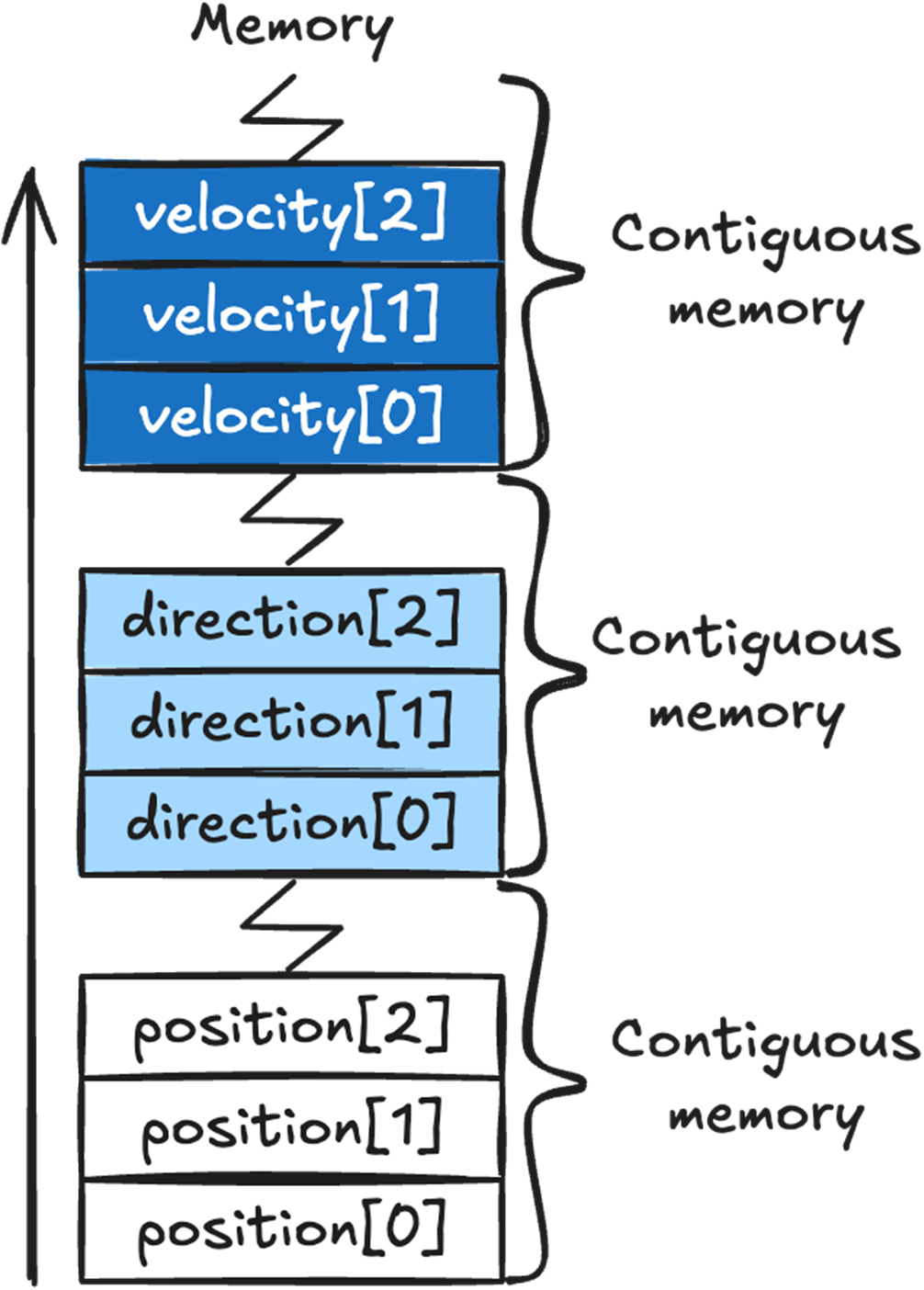
How the member variables of our Enemy object are placed in memory. The position data is placed first, then direction, then velocity. The same order they are defined in the Enemy class. They are packed together in memory without any space between them.

Our cache line will include m_position, m_direction, m_velocity, and whatever data comes right after them. Our cache line is 64 bytes. The variables m_position and m_direction are of type Vector2, which takes 8 bytes. The variable m_velocity is a float, which takes 4 bytes. That means we have 44 bytes leftover, which are automatically filled with whatever data comes after m_velocity.
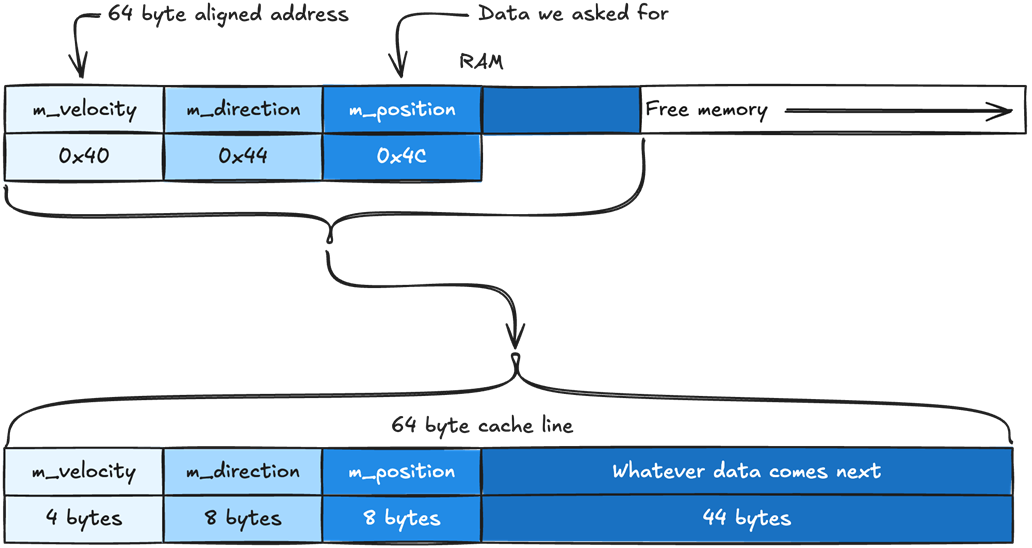
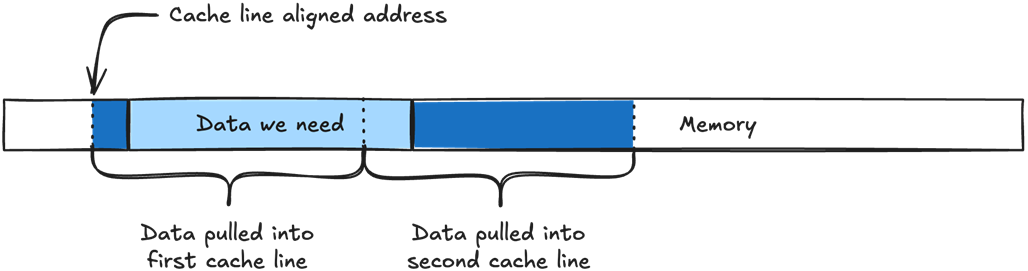
When our CPU asks for m_position, the Memory Management Unit (MMU) will try to fill the cache line from the nearest address that is aligned with the size of our cache line. If our cache lines are 64-byte long, the cache line will be filled with data from the nearest 64-byte aligned address. In this case, m_position sits at 0x4C and the nearest 64-byte aligned address will be 0x40.
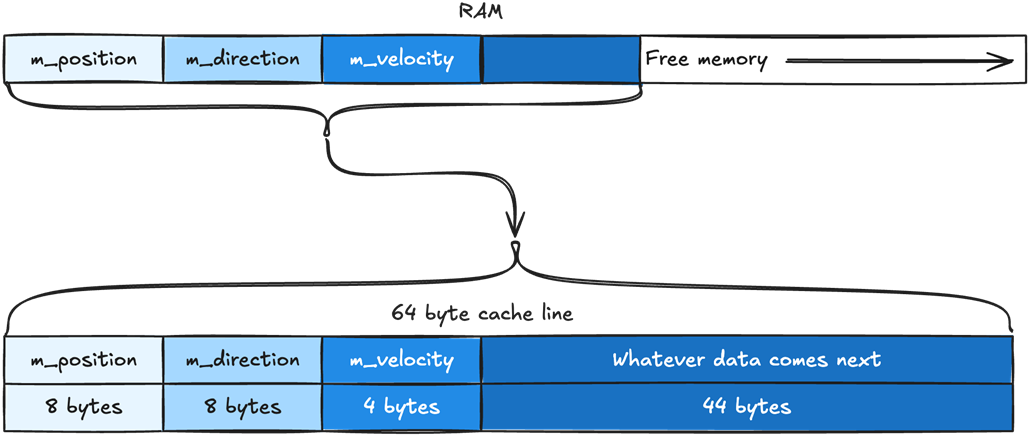
If the data we need does not align with the cache line size, it will need to be split into two cache lines instead of one.
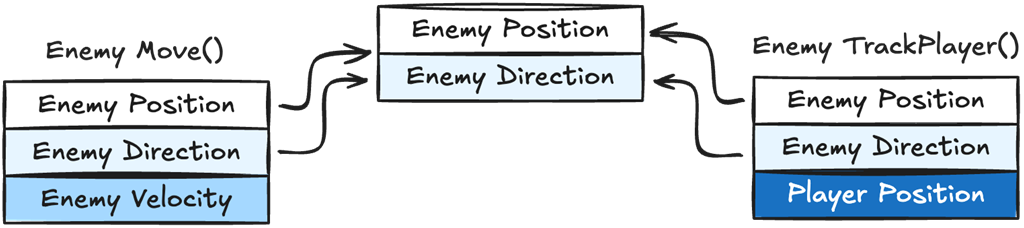
We can see both Move() and TrackPlayer() require the same variables, Enemy Position and Direction, but each one also needs different data as well, Enemy Velocity for Move() and Player Position for TrackPlayer(). When data is shared between different logic functions it makes it impossible to guarantee data locality for every logic function.
Arrays automatically place their data in contiguous memory. All the position array data will be in a single contiguous chunk of memory, as will direction and velocity’s data.
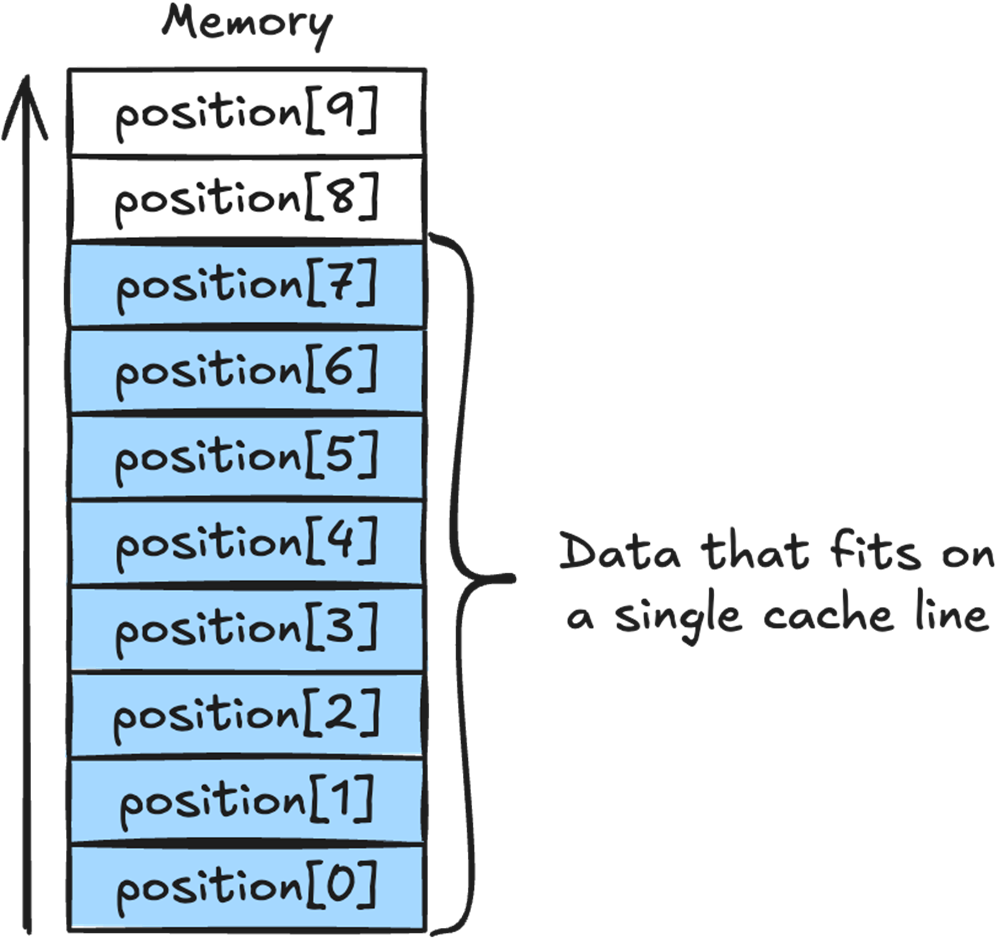
We can see how the position array sits in memory, and how the array elements 0 to 7 all fit in a single 64 byte cache line.
The two existing enemies in our game, the Angry Cactus, which is a static enemy, and the Zombie, which is a moving enemy.

Task to implement a new enemy, the Teleporting Robot.
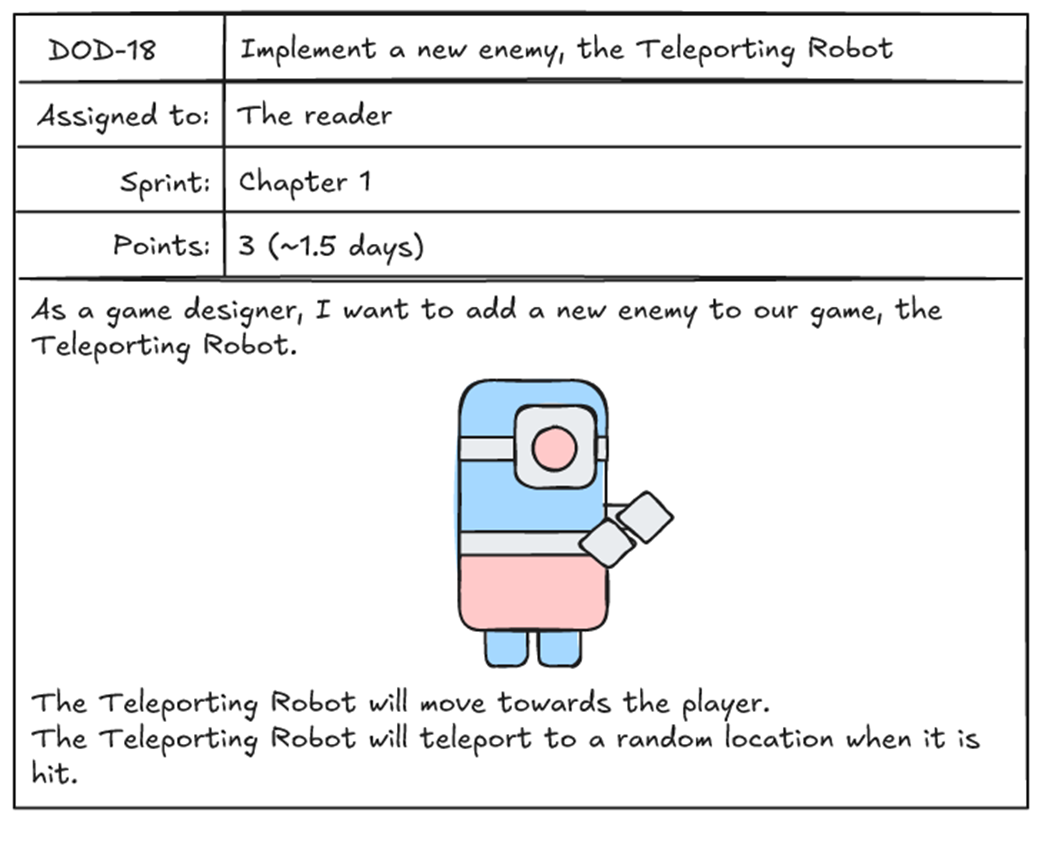
Our game’s enemy inheritance tree, with EnemyTeleportOnHit inheriting from EnemyMove.
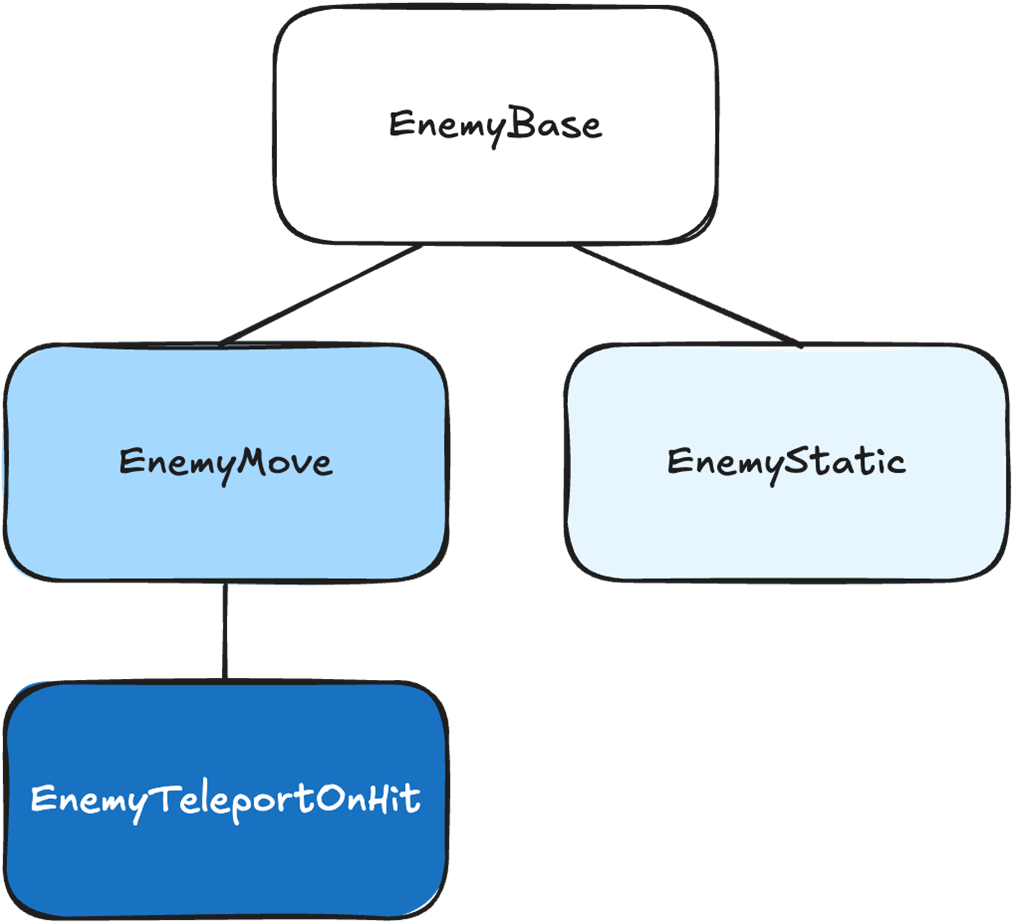
Every function in our game takes in some input data, then transforms it into output data.

The Move() function’s input is the enemy position, direction, and velocity. The transformation is our calculation of the new position. The output is the new position.
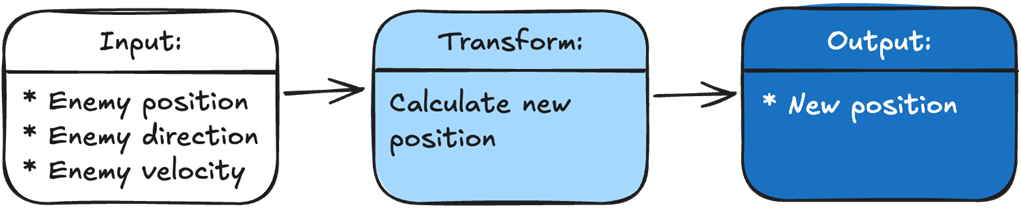
To make our enemy track the player, we just add a function that sets the enemy’s direction toward the player. Our input is the enemy position and the player position. The transformation is calculating a new direction for the enemy. The output is the new direction.
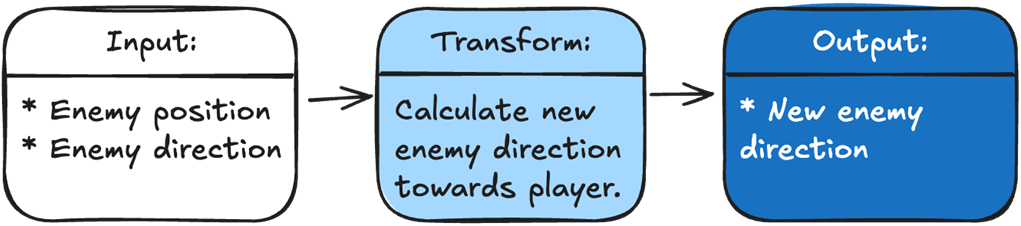
To add our new Robot Zombie, we just add a function that teleports the player to a new location if it is hit. Our input is the damage the enemy received, if any, and whether it should teleport if hit. The transformation is calculating a new position if the enemy is hit. The output is either the new position if the hit succeeds, or the old position if the hit fails.

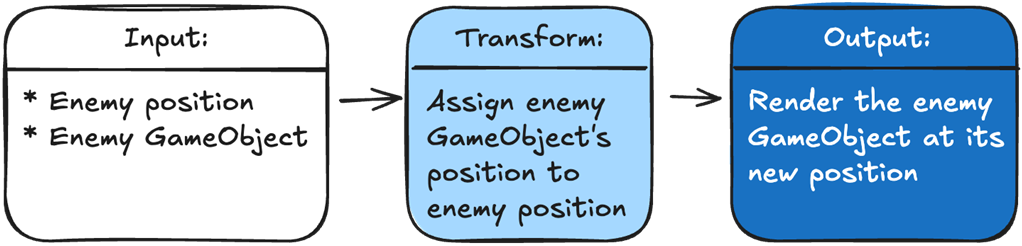
To show an enemy in the correct position, we pass in the enemy’s GameObject and its position. We transform our data by assigning the GameObject’s position to the enemy. The output is Unity rendering our GameObject in the correct position.
Task to implement a new enemy, the Zombie Duck.

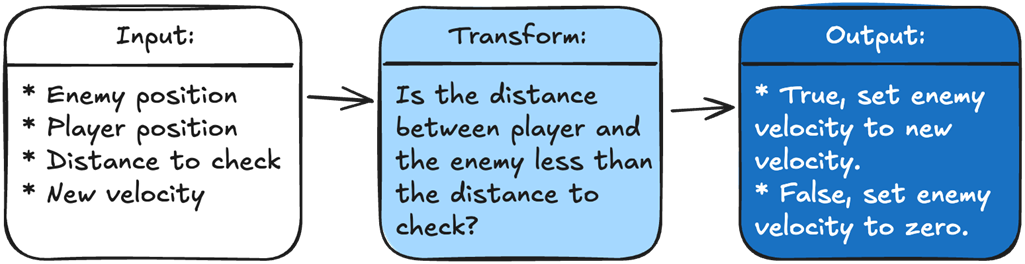
To determine what velocity we should set our enemy, we are going to take in four variables: the enemy position, the player position, the distance we need to check against, and the new enemy velocity. Our logic will calculate the distance between the player and the enemy and check it against the input distance. The output is the new velocity for the enemy based on the logic result.
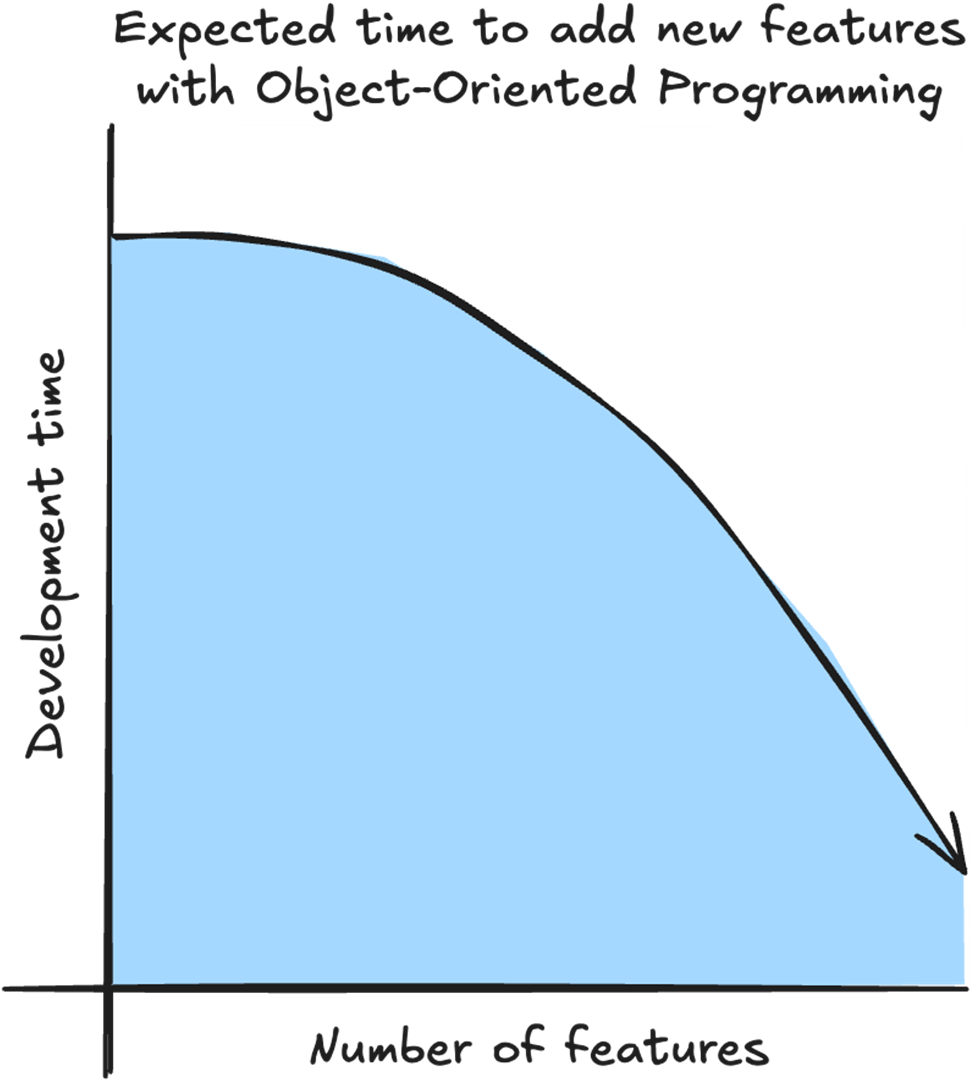
With OOP, in an ideal situation, we start the project by spending time setting up systems and inheritance hierarchies so future features will be quick and easy to implement.
With OOP, what usually happens is that the more features we already have, the longer it takes to add a new feature. For every new feature, we need to take into account the complicated relationship between existing features.
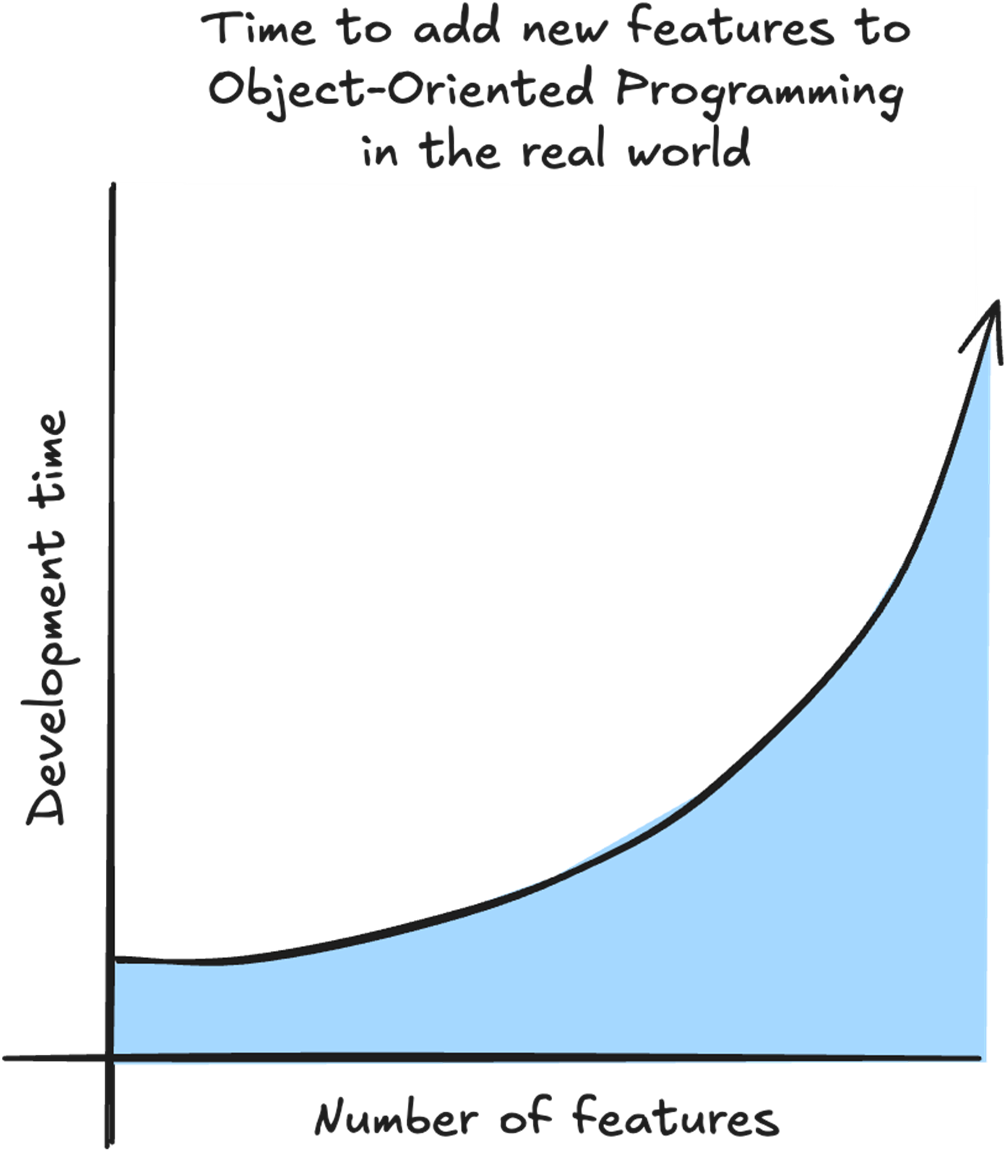
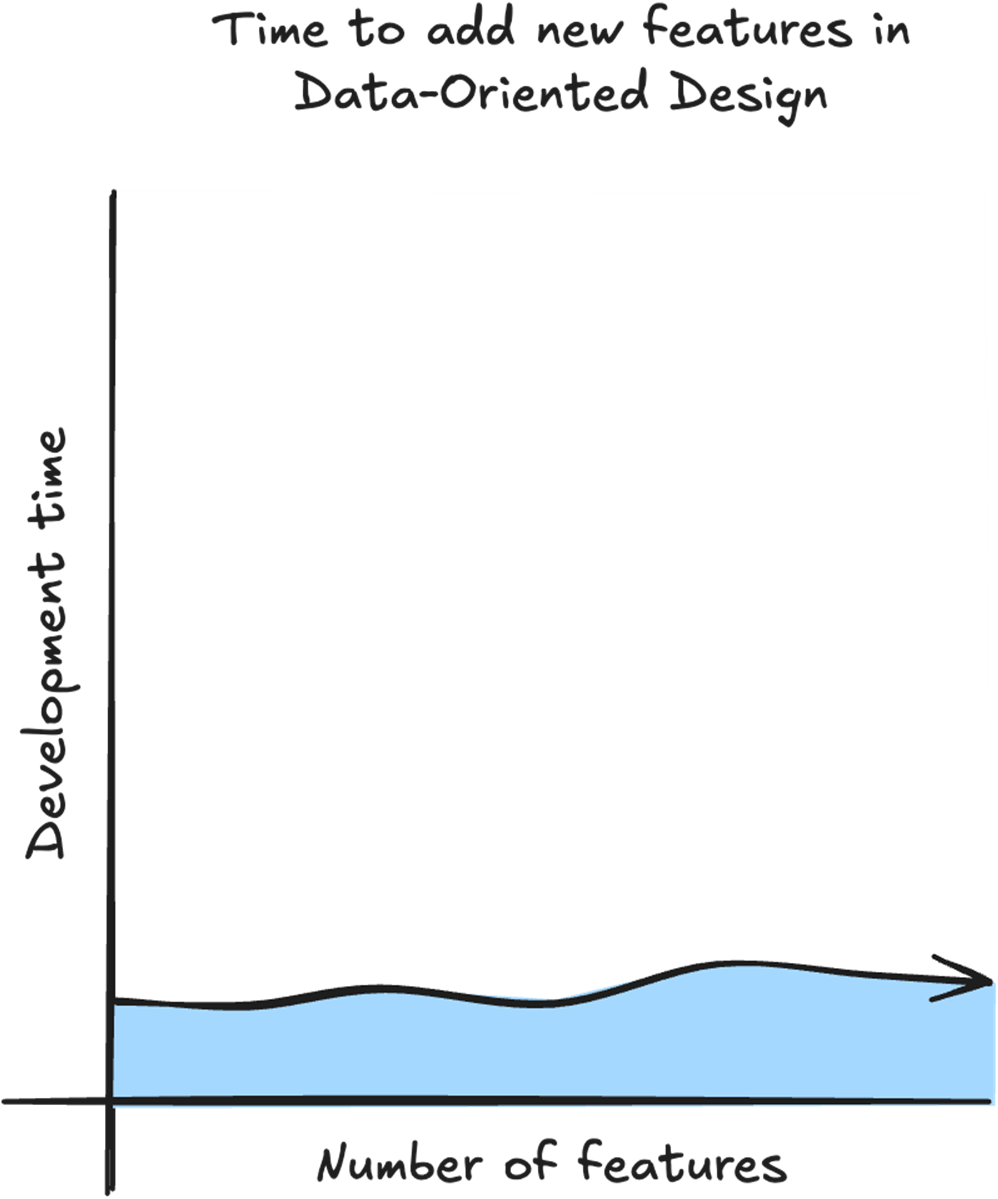
With DOD the time to add a new feature is linear because we don’t need to take into account the existing features. All we need is the data for the feature, and what logic we need to transform the data.
Summary
- With Data-Oriented Design we get a performance boost by structuring our data to take advantage of the CPU cache.
- Your target CPU may have multiple levels of cache, but the first level, called the L1 cache is the fastest.
- The L1 cache is the fastest because it is small and is placed directly on the CPU die.
- Retrieving data from L1 cache is up to 50 times faster than accessing main memory.
- To avoid having to retrieve data from main memory, our CPU uses cache prediction to guess which data we are going to need next and places it in the cache ahead of time.
- Data is pulled from memory into the cache in chunks called cache lines.
- Practicing data locality by keeping our data close together in memory helps the CPU cache prediction retrieve the data we’ll need in the future into the L1 cache.
- Placing our data in arrays makes it easy to practice data locality.
- With Data-Oriented Design we can reduce our code complexity by separating the data and the logic.
- Every function in our game takes input and transforms it into the output needed. The output can be anything from how many coins we have to showing enemies on the screen.
- Instead of thinking about objects and their relationships, we only think about what data our logic needs for input and what data our logic needs to output.
- With Data-Oriented Design, we can also improve our game's extensibility by always solving problems through data. This makes it easy to add new features and modify existing ones.
- Regardless of how complex our game has become, every new feature can be solved using data. This can keep development time more predictable because new features are usually added by identifying the data they need and the logic that transforms it.
- ECS is a design pattern sometimes used to implement DOD. Not all ECS implementations are DOD, and we don’t need ECS to implement DOD.
- Unity DOTS is a collection of tools that can be built on top of a DOD architecture, but DOD does not require DOTS.
FAQ
What is Data-Oriented Design?
Data-Oriented Design, or DOD, is an approach to structuring game code around the flow and transformation of data. Instead of organizing gameplay around relationships between objects, DOD focuses on what data a system needs, how that data is stored, and how logic transforms that data over time.
How is DOD different from traditional object-oriented programming?
In object-oriented programming, data and logic are usually grouped together inside objects, and developers often think in terms of object relationships and inheritance. In DOD, data is separated from logic, and systems are written to process the data they need directly. This often means storing related runtime data in arrays and writing functions that transform many items at once.
Why can DOD improve game performance?
DOD can improve performance because it helps arrange data in memory so the CPU can access it efficiently. Modern CPUs are very fast at executing instructions, but they often spend time waiting for data to arrive from main memory. By grouping needed data together and improving data locality, DOD increases the chance that data is already available in the CPU cache.
What is the CPU cache, and why does it matter?
The CPU cache is a small, very fast memory located close to the CPU core. Accessing data from the L1 cache may take only about 1-2 nanoseconds, while accessing main memory may take 50-150 nanoseconds. Because games often process large amounts of data every frame, keeping frequently used data in cache can greatly reduce the time the CPU spends waiting.
What are cache hits and cache misses?
A cache hit occurs when the data the CPU needs is already available in the CPU cache. A cache miss occurs when the data is not in the cache and must be retrieved from a slower memory location, such as main memory. In DOD, the goal is to maximize L1 cache hits and minimize cache misses.
What is a cache line?
A cache line is the chunk of memory copied into the CPU cache when data is requested. A common cache line size is 64 bytes, though it depends on the CPU. For example, some devices may use 32-byte cache lines, while others may use 128-byte cache lines. When the CPU requests one value, nearby values in memory may be copied into the cache at the same time.
What is data locality?
Data locality means placing data that is used together close together in memory. When related data is stored near each other, it is more likely to fit in the same cache line, allowing the CPU to access it faster. In game code, this often means grouping data used by the same system, such as enemy positions, directions, and velocities.
Why does DOD often use arrays?
Arrays store their elements in contiguous memory, which naturally improves data locality. For example, instead of storing each enemy as an object containing position, direction, velocity, hit points, and other fields, DOD may store all enemy positions in one array, all directions in another array, and all velocities in another. A system can then process those arrays efficiently, often reducing cache misses.
How does separating data and logic reduce code complexity?
Separating data and logic shifts the focus away from deciding which object owns a function and toward identifying what data a function needs. Gameplay code can be treated as input data, a transformation, and output data. This makes systems easier to reason about, debug, and modify because the logic depends on explicit data rather than complicated object relationships.
How do Unity DOTS, Burst, Jobs, and ECS relate to DOD?
DOD is the foundation, while Unity DOTS provides tools that can build on that foundation. Burst can help compile code to use SIMD instructions, Jobs can split work across multiple CPU cores, ECS organizes code into Entities, Components, and Systems, and TransformAccessArray can update GameObject transforms from Jobs. However, DOD does not require ECS; cache-friendly data layout and simple data transformations can be used before selectively adding DOTS features.
 High Performance Unity Game Development ebook for free
High Performance Unity Game Development ebook for free