2 Types of machine learning
Machine learning teaches computers to make decisions from experience by learning patterns in data. This chapter introduces the main ways models learn, organized by the kind of data and feedback available. It clarifies the building blocks—data points, features, and labels—and distinguishes labeled data (with a target to predict) from unlabeled data (without explicit targets). With that foundation, it presents the three major families of machine learning: supervised learning for predicting known labels, unsupervised learning for discovering structure without labels, and reinforcement learning for training an agent to act through rewards and penalties.
Supervised learning operates on labeled datasets to predict outcomes for new examples. It splits into regression, which predicts numerical values (such as house prices or recovery times), and classification, which predicts categorical states (such as spam vs. not spam, sick vs. healthy, or dog vs. cat). The chapter highlights common applications across text, images, recommendations, and forecasting, and notes that labels can be numerical or categorical, guiding the choice between regression and classification. It also previews widely used algorithms—linear models, decision trees, neural networks, support vector machines, and ensemble methods—while emphasizing that the book focuses primarily on supervised approaches.
Unsupervised learning extracts insight from unlabeled data by uncovering structure and simplifying representation. Clustering groups similar items (useful for market segmentation, organizing emails, or image partitioning), while dimensionality reduction condenses many features into a smaller set that preserves most information. Techniques like matrix factorization and singular value decomposition can reduce both rows and columns, enabling recommendations and data compression. The chapter also surveys generative learning, which creates new, realistic samples akin to the training data (for example with GANs or VAEs), and introduces reinforcement learning, where an agent learns to achieve goals through reward-driven exploration—powering advances in game-playing, robotics, and self-driving systems.

Labeled data is data that comes with a tag, or label. That label can be a type or a number. Unlabeled data is data that comes with no tag. The dataset on the left is labeled, and the label is the type of pet (dog/cat). The dataset in the middle is also labeled, and the label is the weight of the pet (in pounds). The dataset on the right is unlabeled.

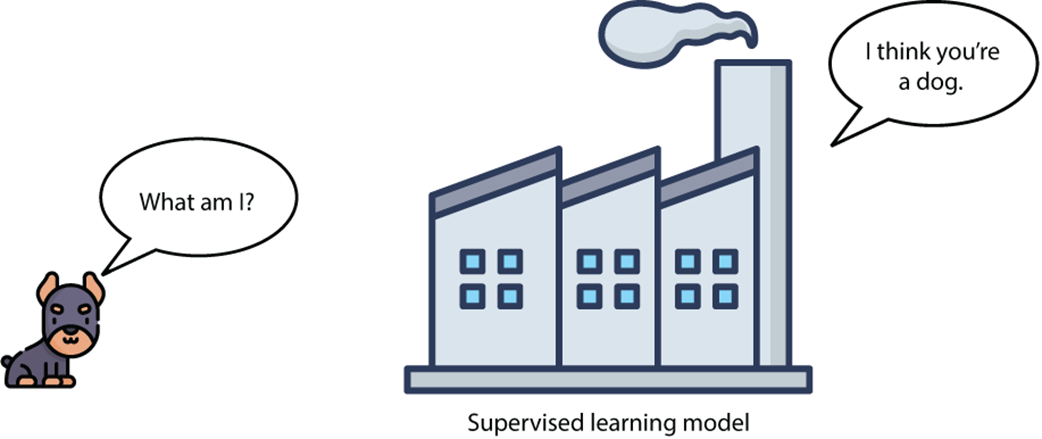
A supervised learning model predicts the label of a new data point. In this case, the data point corresponds to a dog, and the supervised learning algorithm is trained to predict that this data point does, indeed, correspond to a dog.
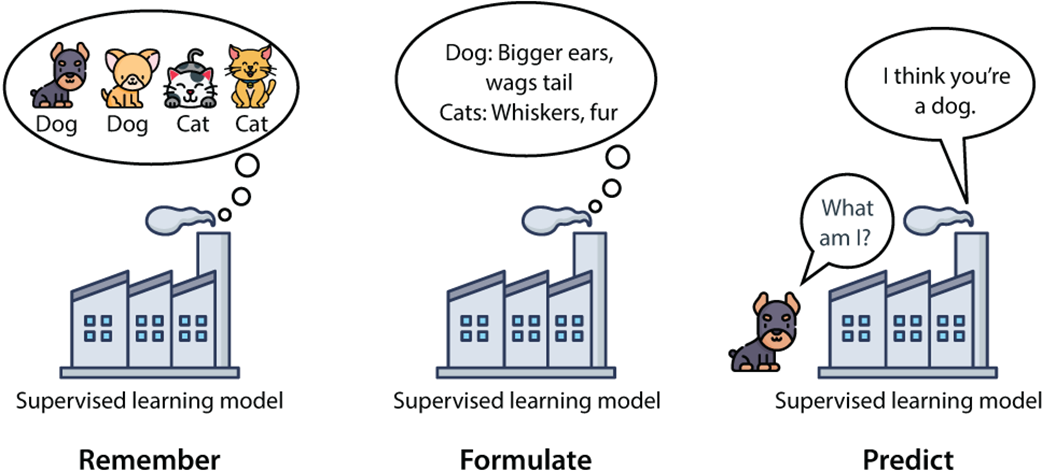
A supervised learning model follows the remember-formulate-predict framework from chapter 1. First, it remembers the dataset. Then, it formulates rules for what would constitute a dog and a cat. Finally, it predicts whether a new data point is a dog or a cat.
An unsupervised learning algorithm can still extract information from data. For example, it can group similar elements together.

A plot of the email dataset. The horizontal axis corresponds to the size of the email and the vertical axis to the number of recipients. We can see three well-defined clusters in this dataset.
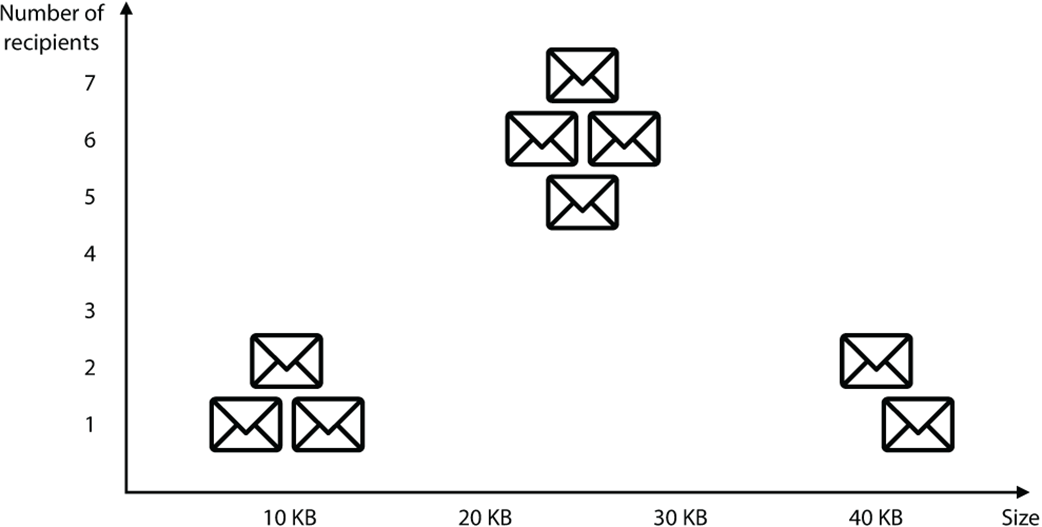
We can cluster the emails into three categories based on size and number of recipients.

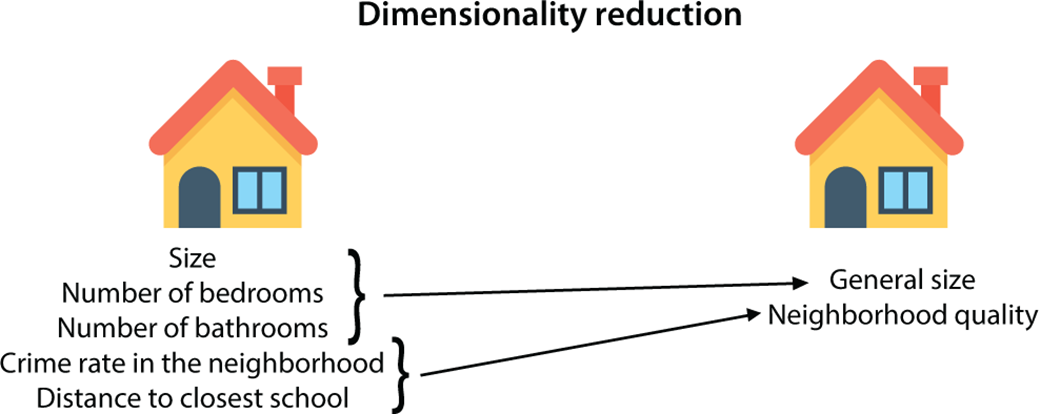
Dimensionality reduction algorithms help us simplify our data. On the left, we have a housing dataset with many features. We can use dimensionality reduction to reduce the number of features in the dataset without losing much information and obtain the dataset on the right.
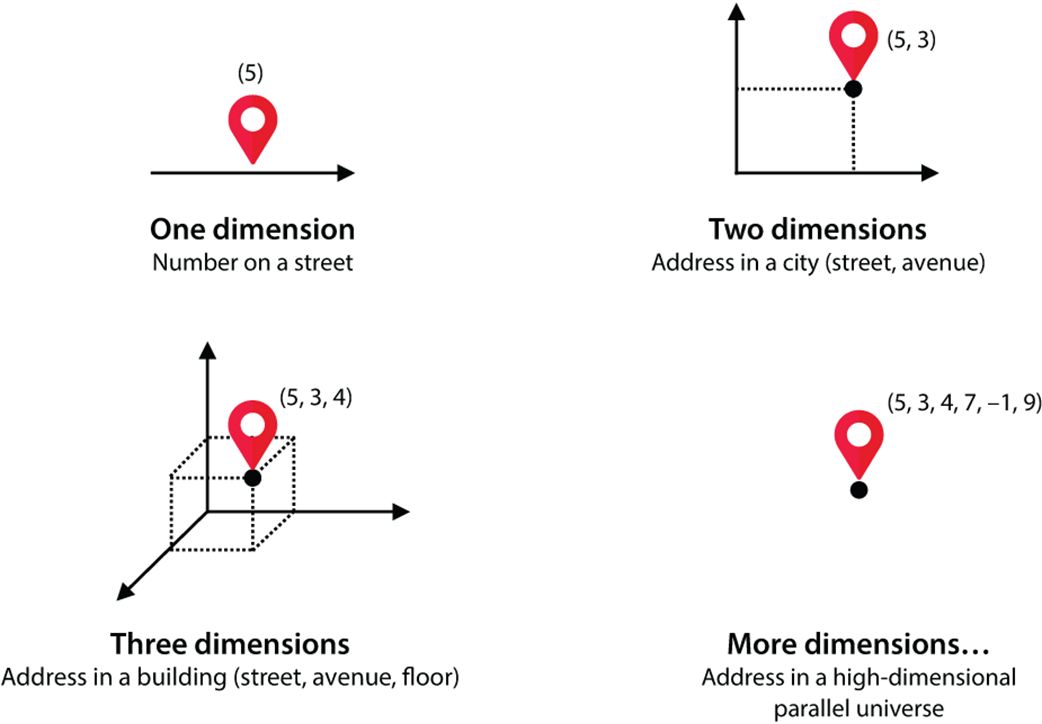
How to imagine higher dimensional spaces: One dimension is like a street, in which each house only has one number. Two dimensions is like a flat city, in which each address has two numbers, a street and an avenue. Three dimensions is like a city with buildings, in which each address has three numbers: a street, an avenue, and a floor. Four dimensions is like an imaginary place in which each address has four numbers. We can imagine higher dimensions as another imaginary city in which addresses have as many coordinates as we need.
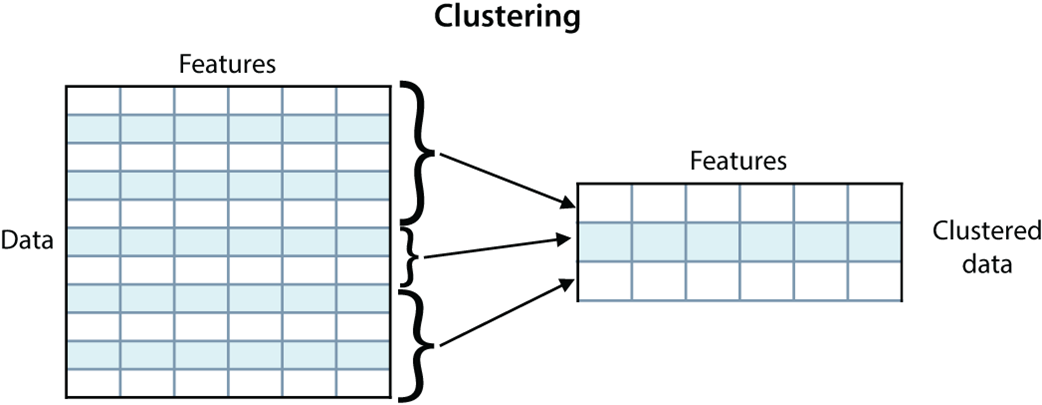
Clustering can be used to simplify our data by reducing the number of rows in our dataset by grouping several rows into one.
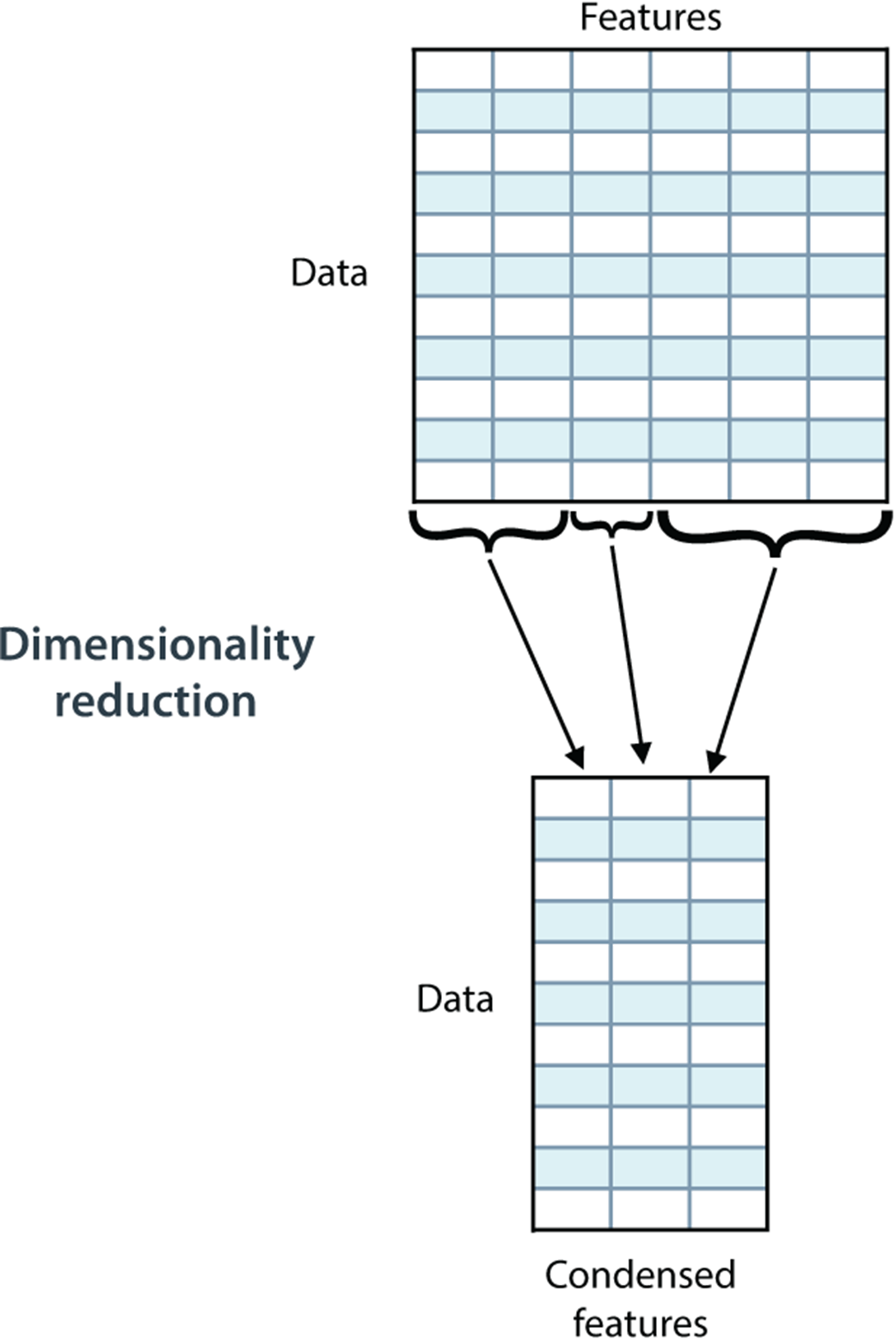
Dimensionality reduction can be used to simplify our data by reducing the number of columns in our dataset.
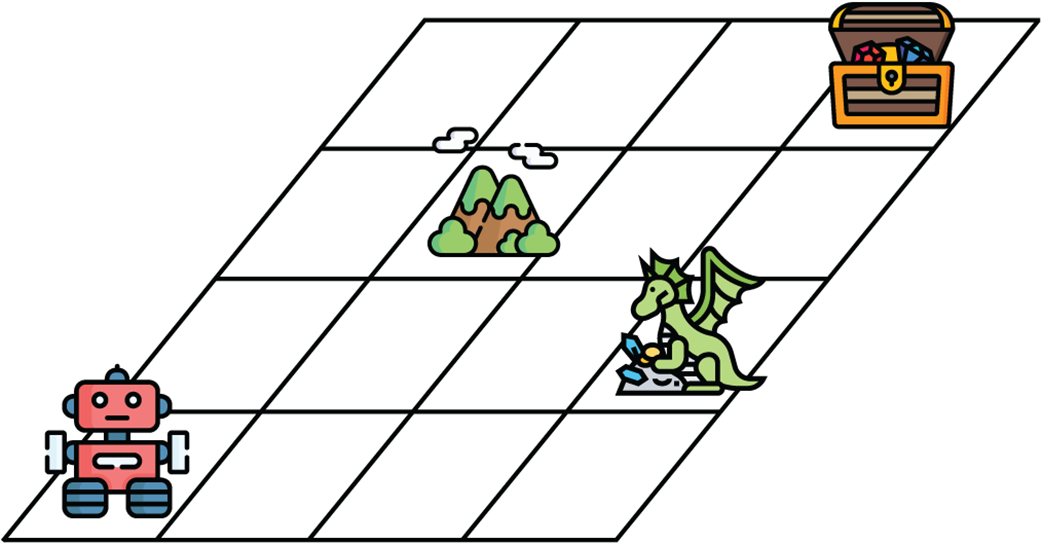
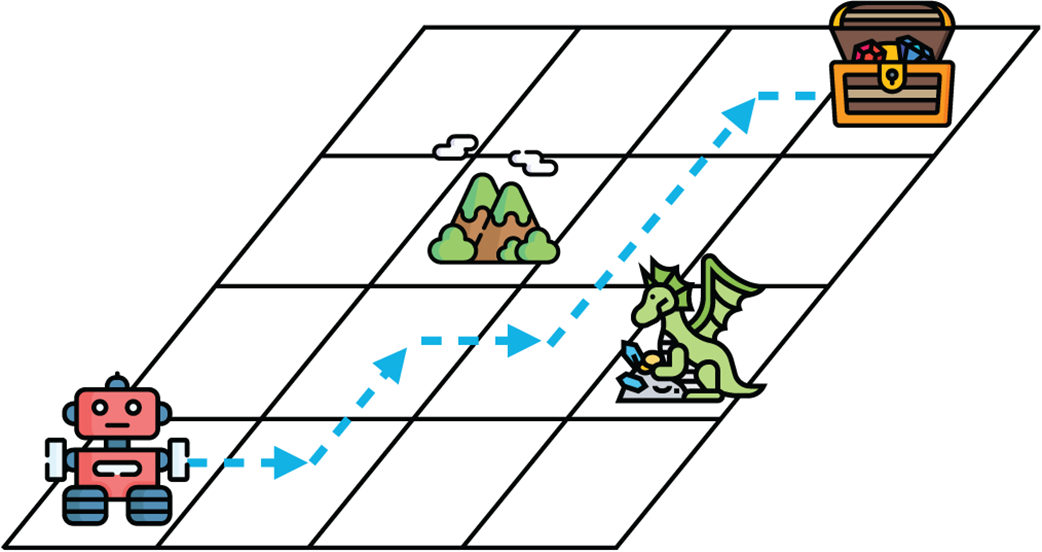
A grid world in which our agent is a robot. The goal of the robot is to find the treasure chest, while avoiding the dragon. The mountain represents a place through which the robot can’t pass.
Here is a path that the robot could take to find the treasure chest.
 Grokking Machine Learning, Second Edition ebook for free
Grokking Machine Learning, Second Edition ebook for free