Generative AI applications feel familiar to use but unusual to build. This chapter sets expectations for a practical, tool-agnostic journey: instead of diving into math or model internals, it focuses on the core building blocks of real-world GenAI systems, how they fit together, and where their limits lie. You’ll practice with Langflow as a low‑code, visual way to prototype and reason about designs, while keeping concepts portable across frameworks. The aim is to give you an intuition for how large language models behave and a clear mental model for architecting useful applications.
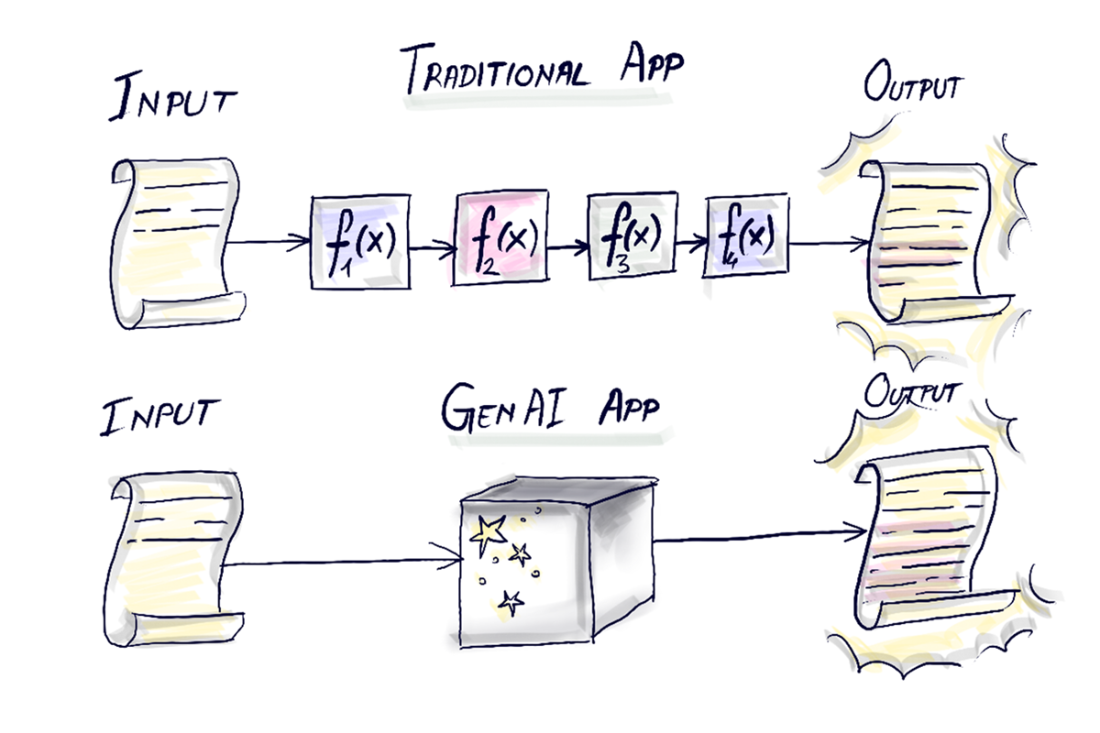
GenAI programming differs from traditional coding because an LLM—a probabilistic “black box” that reads and writes natural language—sits inside your workflow. LLMs are non-deterministic, stateless, and fixed to their pre-training, so production apps wrap them with additional components. To mimic memory, applications capture and resend conversation history; to supply knowledge beyond training data, they attach relevant, up-to-date context (later formalized with Retrieval-Augmented Generation). Beyond context and memory, robust systems trigger external actions via tools/APIs, shape behavior through careful prompt engineering, and coordinate specialized agents. This is how products like ChatGPT and Copilot appear to “remember,” “know,” and “act” despite the model’s raw limitations.
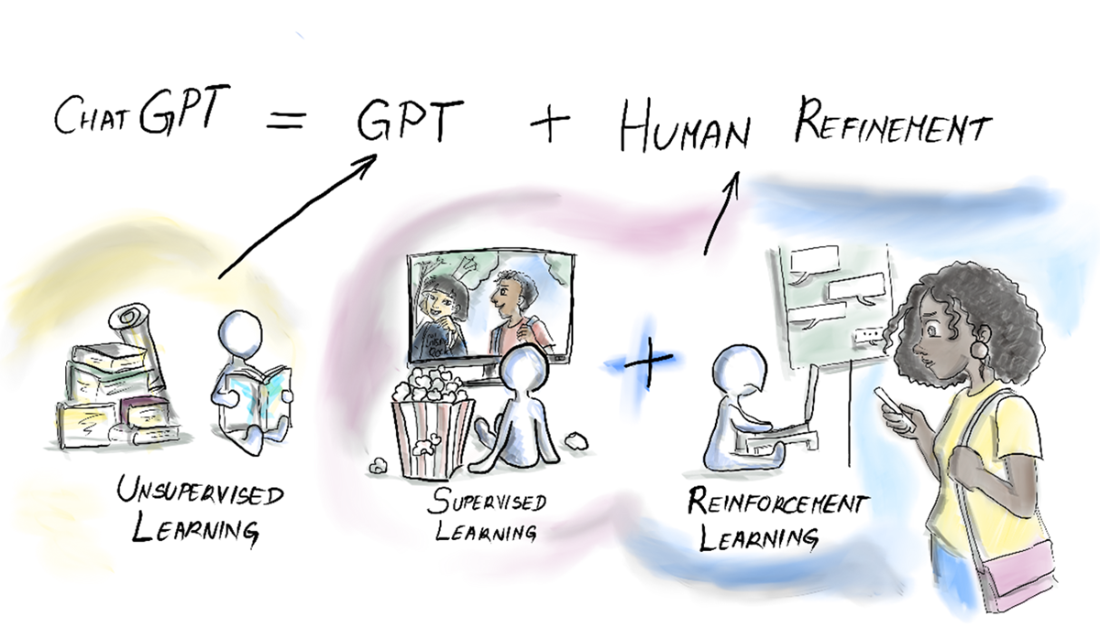
Under the hood, LLMs tokenize text, map tokens to high-dimensional embeddings, use transformer networks and attention to build context, and generate the next token autoregressively. Their capabilities come from large-scale pre-training on vast text corpora, then human-guided refinement (supervised fine-tuning and reinforcement learning from human feedback). Practical constraints—context windows, knowledge cutoffs, and compute demands—remain, but you can extend models with retrieval, fine-tuning, memory, and orchestration patterns; smaller models can also be effective for focused tasks. With these principles, the chapter frames how to “tame the beast” and design reliable, context-rich GenAI applications.
GenAI applications have an LLM (Magic Black Box) somewhere.
The magic box. Gets text as input and generates text as output.
LLM relationships: every chat is a first date.
Taming the GenAI beast.
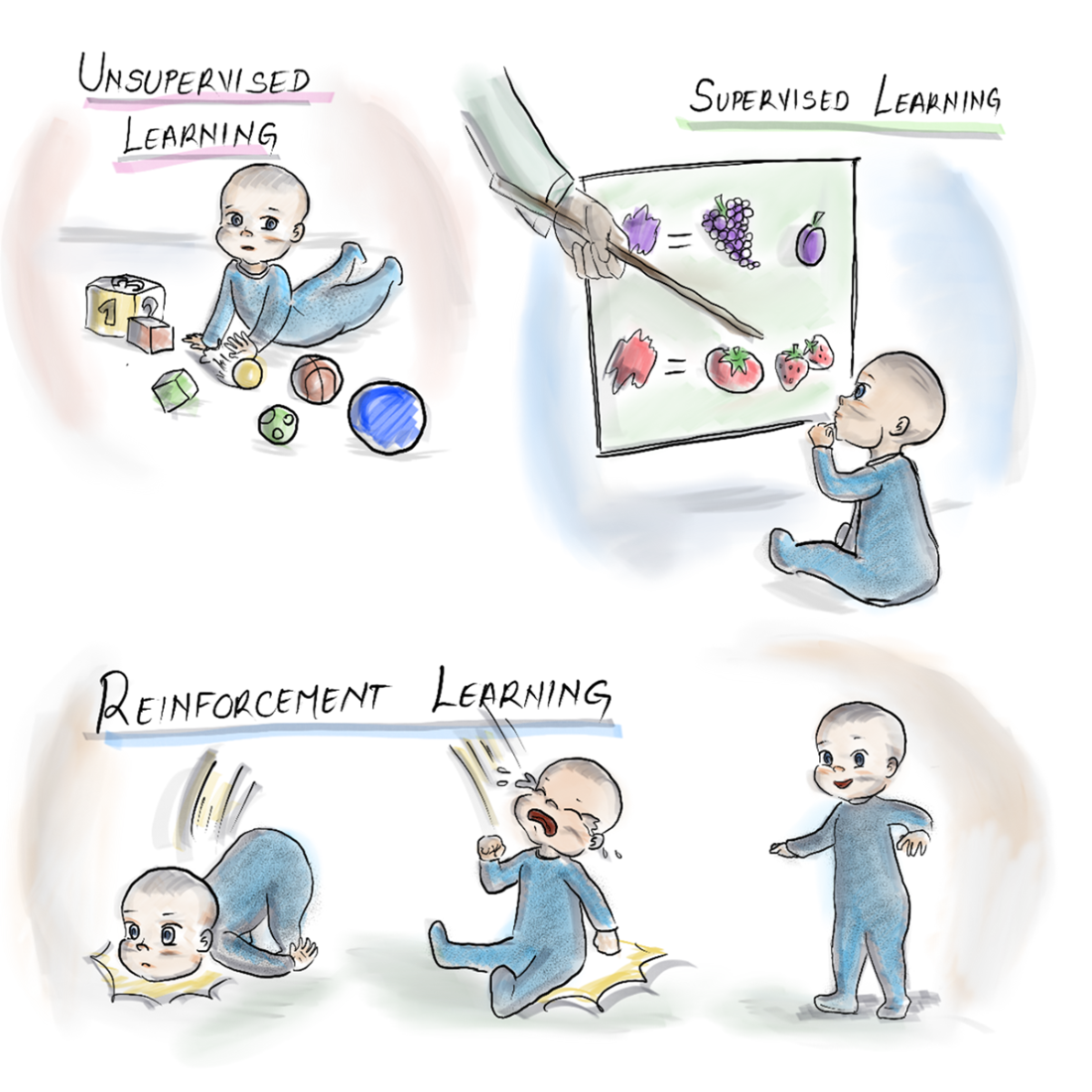
The three types of machine learning: Unsupervised, supervised, and reinforcement.
The learning stages of ChatGPT.
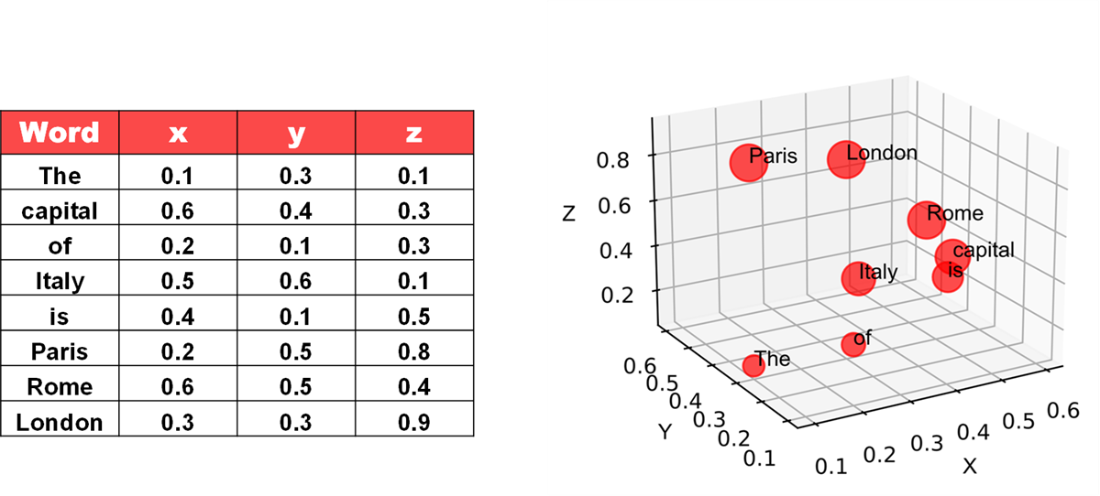
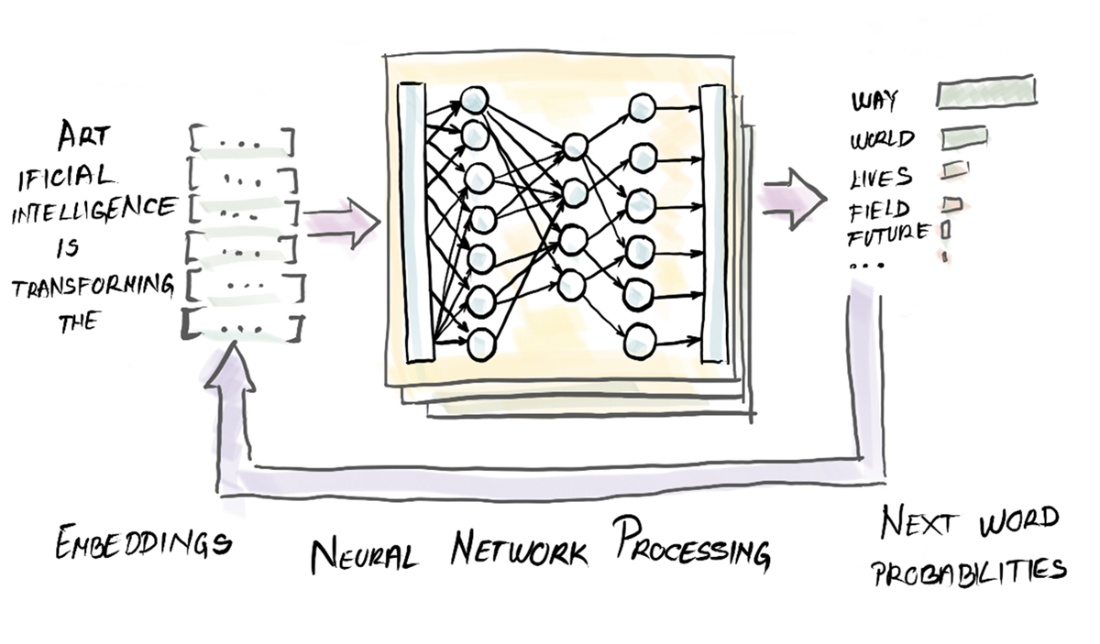
Words are numbers in the eyes of an LLM.
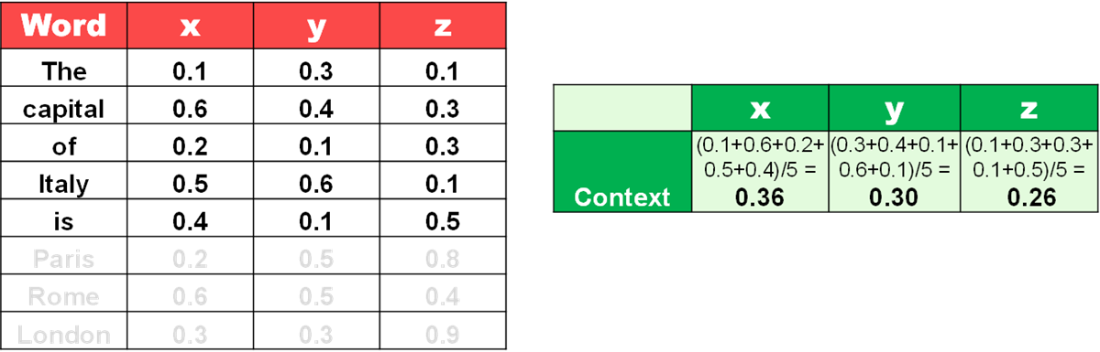
Given a prompt, you can calculate the context.
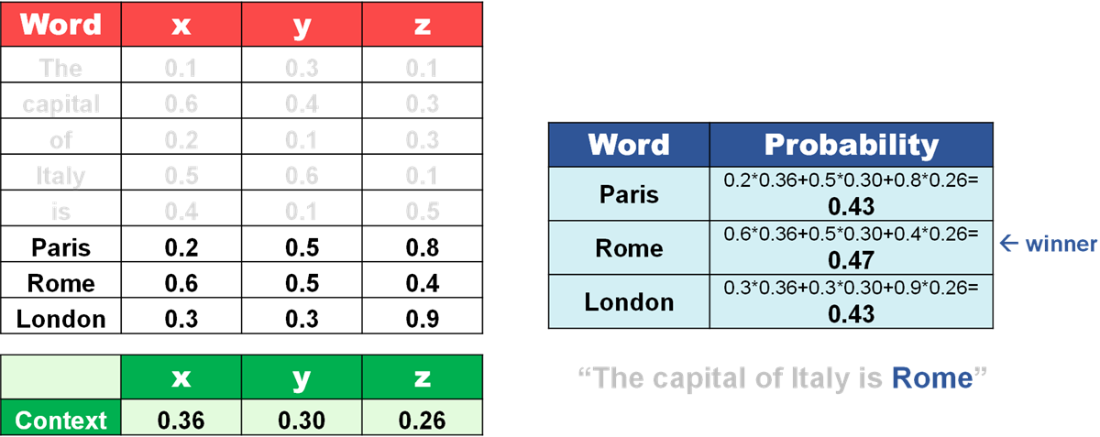
Guess the next best word by combining embeddings with context.
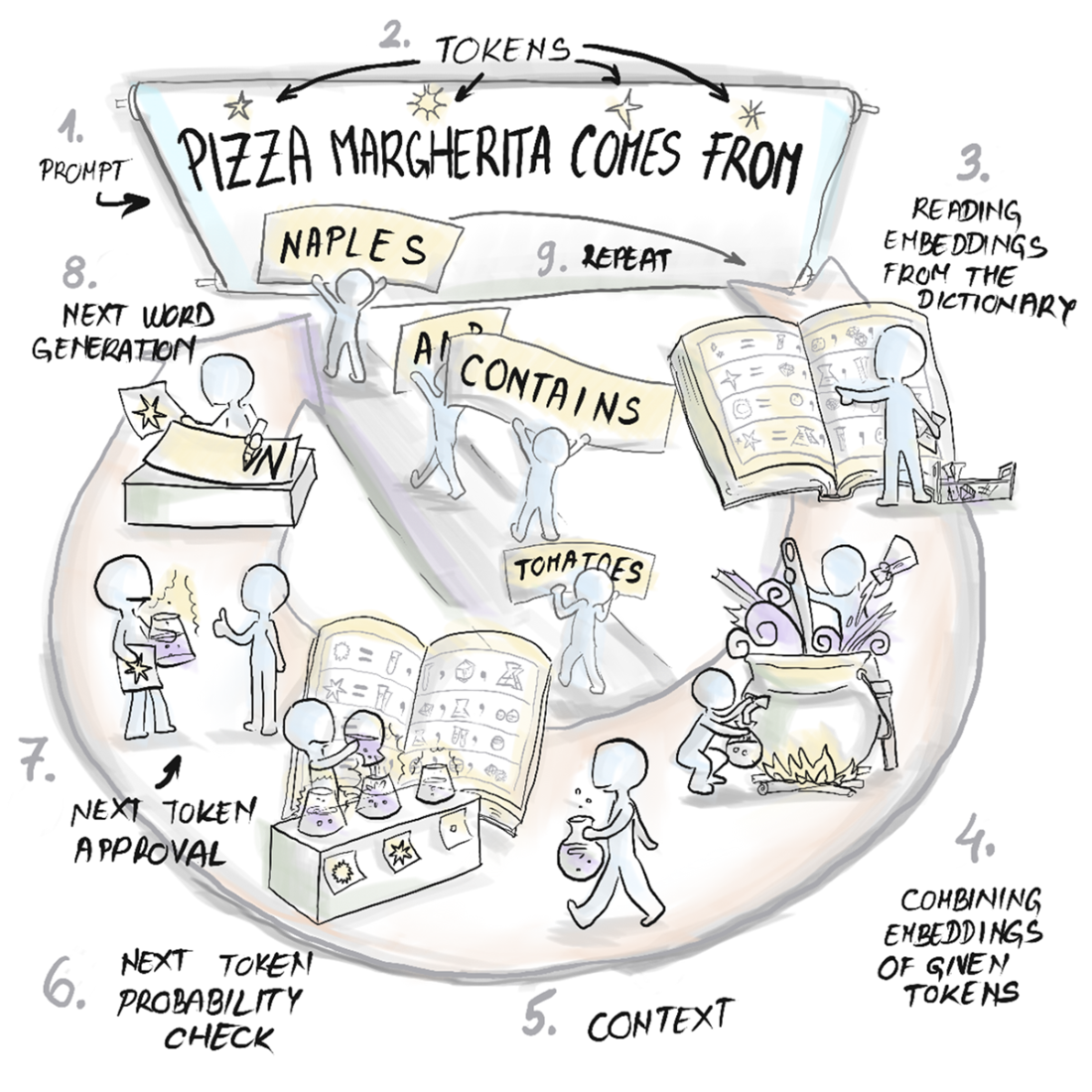
The GPT sentence completion process.
How a GPT architecture generates sentences.
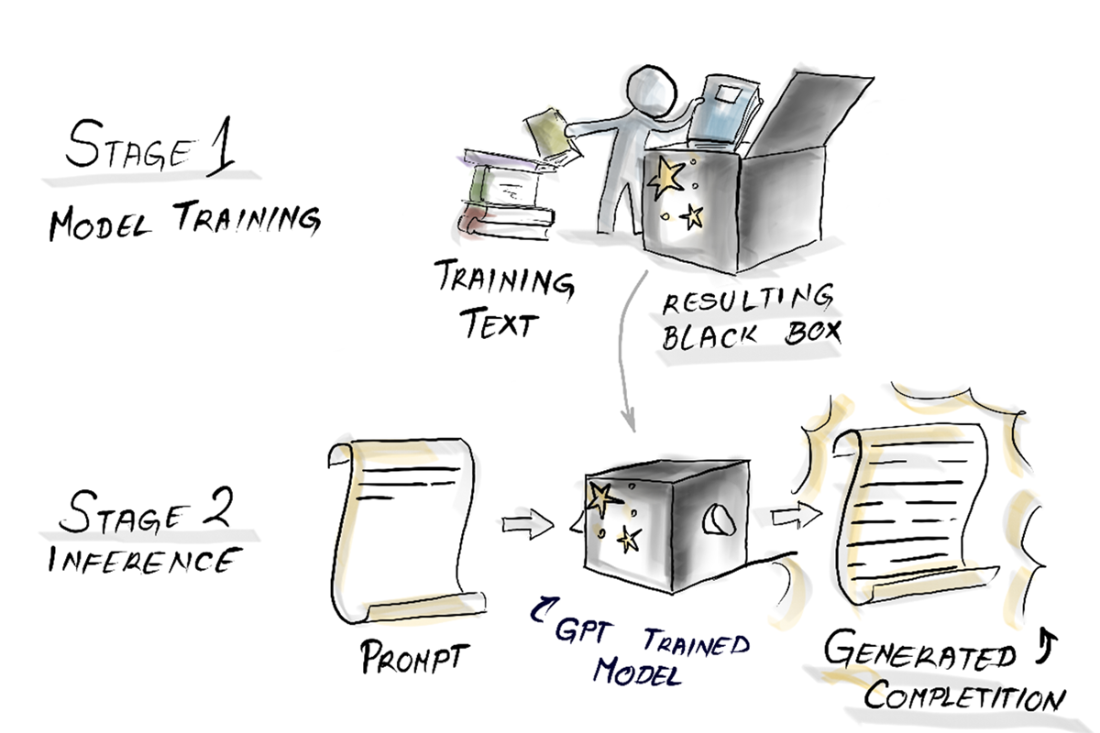
The two stages of GPT-3. First, it gets trained, and then the sentence completion is inferred.
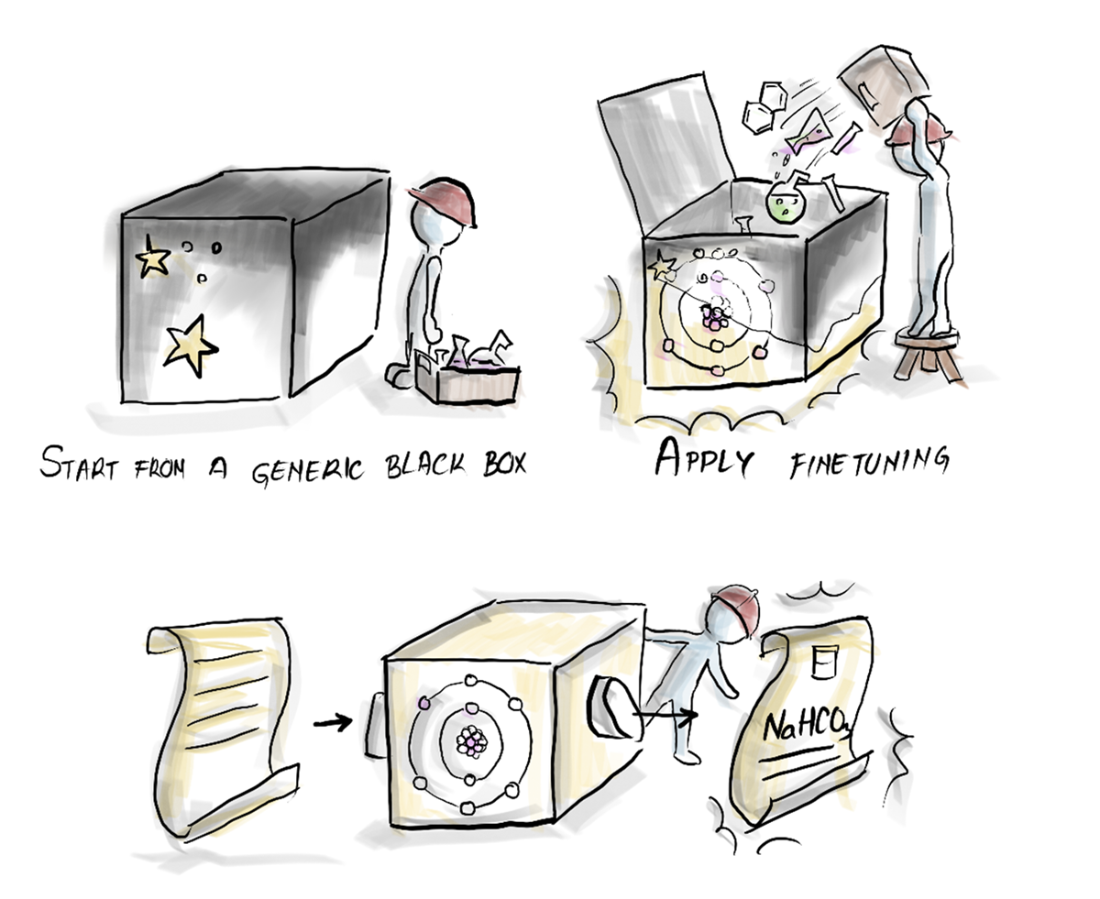
Enhancing a pre-trained model through fine-tuning.
FAQ
How is GenAI programming different from traditional software development?Traditional apps follow explicit, deterministic steps you code in a formal language. GenAI apps route inputs through an LLM that responds in natural language and behaves probabilistically. You design prompts, manage non-determinism, and add components like memory, retrieval, and tools to achieve reliable behavior.Why are LLMs called non-deterministic, stateless, pre-trained, and not explanatory?Non-deterministic: the same prompt can yield different outputs. Stateless: the model forgets previous turns between calls. Pre-trained: its knowledge is fixed at training time. Not explanatory: it’s a black box that can’t tell you “why” it answered a certain way. These traits require app-layer strategies for memory, context, and control.If LLMs are stateless, how can my app remember the conversation?Your app must store past turns and include the relevant history in each new prompt (or a summary of it). Systems like ChatGPT do this by re-sending prior context every time. Practical patterns include sliding windows, summaries, and memory stores sized to fit the model’s context window.How do I give an LLM fresh or private knowledge it didn’t see during training?Attach the needed information to the prompt at inference time. For small corpora, you can include full snippets directly. For larger ones, retrieve only the relevant passages (e.g., with Retrieval-Augmented Generation) or call external tools/APIs, then feed the results to the model.What building blocks beyond the LLM do real GenAI apps use?Common pieces include: conversation state management, retrieval of up-to-date/domain data, tool integrations to take actions (APIs), prompt engineering to control tone and behavior, agentic structures (multiple specialized roles), plus deployment, monitoring, and observability.In simple terms, how does a model like GPT generate text?It tokenizes the input, maps tokens to high‑dimensional embeddings, computes a context via deep transformer layers (with positional information and attention), then produces probabilities over the next token. It selects one token, appends it to the prompt, and repeats—one token at a time.What are tokens, embeddings, and the context window—and why do they matter?Tokens are the text units the model processes. Embeddings are numeric vectors that capture token meaning. The context window is the maximum number of tokens the model can consider at once, limiting how much history and reference material you can include (e.g., GPT‑3 allowed ~2,048 tokens; modern models are much larger).What are transformers and attention, in plain language?Transformers are neural networks built to handle sequences. Attention lets the model “focus” on the most relevant parts of the input and their positions. This helps it relate words to each other (e.g., linking “Italy” to “capital”) and generate coherent, context-aware responses.What’s the difference between pre-training, fine-tuning, and RLHF?Pre-training teaches next-token prediction on massive text to learn general language. Fine-tuning uses supervised examples to specialize the model for tasks or domains. RLHF (Reinforcement Learning from Human Feedback) aligns outputs with human preferences by ranking and optimizing responses.When should I choose a Small Language Model (SLM) over a large one?Pick SLMs when you need lower cost, faster latency, or on-device/private deployment for narrower tasks (e.g., summarization, local assistants). Choose LLMs when you need broad knowledge, stronger reasoning, or more fluent generation—accepting higher compute and cost.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!


 Grokking AI Applications ebook for free
Grokking AI Applications ebook for free