1 Evaluations and alignments for AI
Evaluation and alignment are presented as the core feedback loop for building production-ready AI systems. Evaluation asks what a model or system actually does—measuring accuracy, reliability, behavior on edge cases, hallucinations, and user-facing quality—while alignment asks what the system should do, shaping behavior toward human goals, constraints, policies, and values. Unlike traditional software testing, AI evaluation must handle free-form, probabilistic outputs where many answers can be valid and quality may depend on context, tone, helpfulness, or factual grounding.
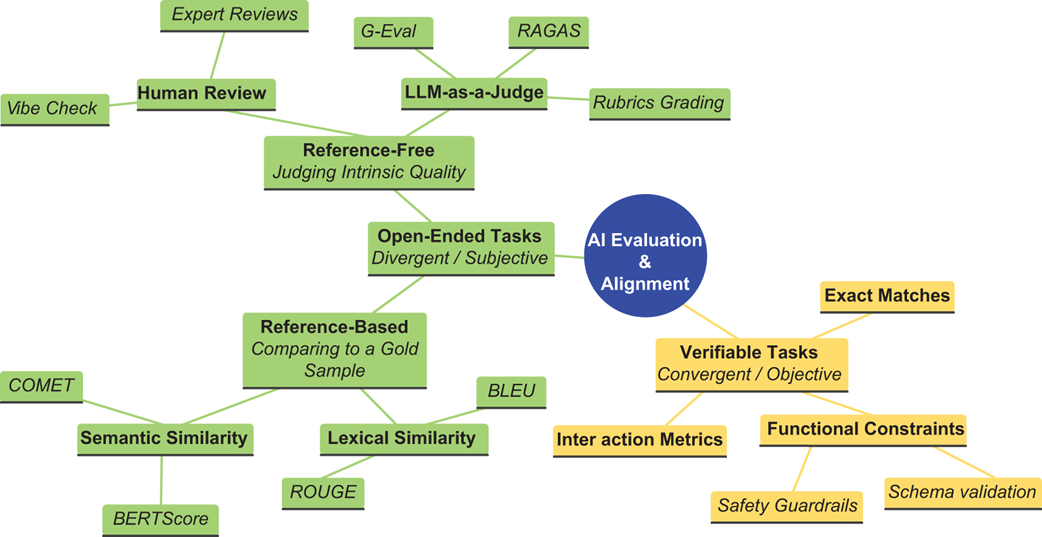
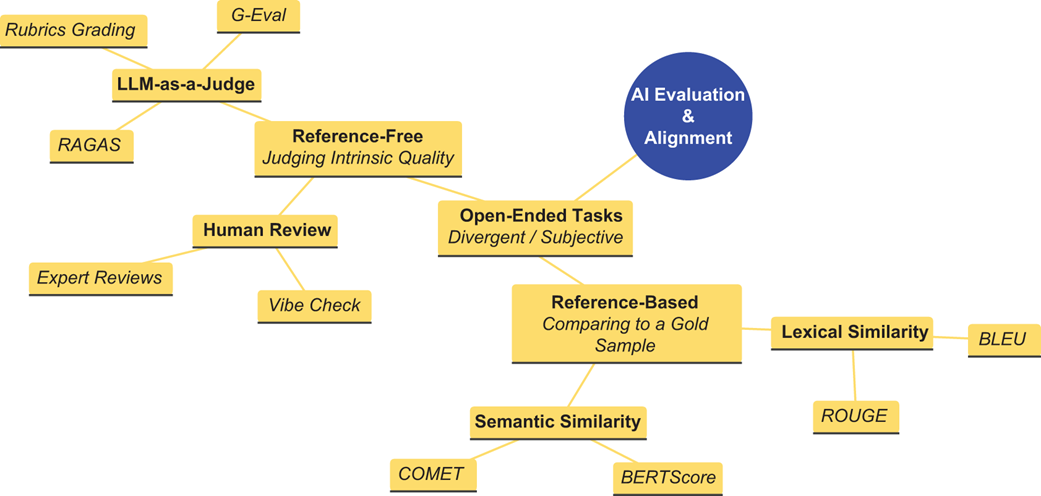
The chapter organizes AI evaluation around the distinction between verifiable and open-ended tasks. Verifiable tasks, such as math answers, unit-tested code, or classification, can be checked objectively, but still face challenges such as answer extraction, verifier reliability, limited test coverage, correct answers with flawed reasoning, and multiple valid implementations. Open-ended tasks, such as summarization, translation, dialogue, customer support, and creative writing, require reference-based methods, reference-free metrics, human judgment, LLM-as-a-Judge systems, and composite strategies. The chapter also treats hallucination as a critical evaluation problem: generated claims must be extracted, checked against evidence, and measured through concepts such as faithfulness, while recognizing that ambiguity, context, half-truths, and unsupported inference chains make hallucination detection difficult.
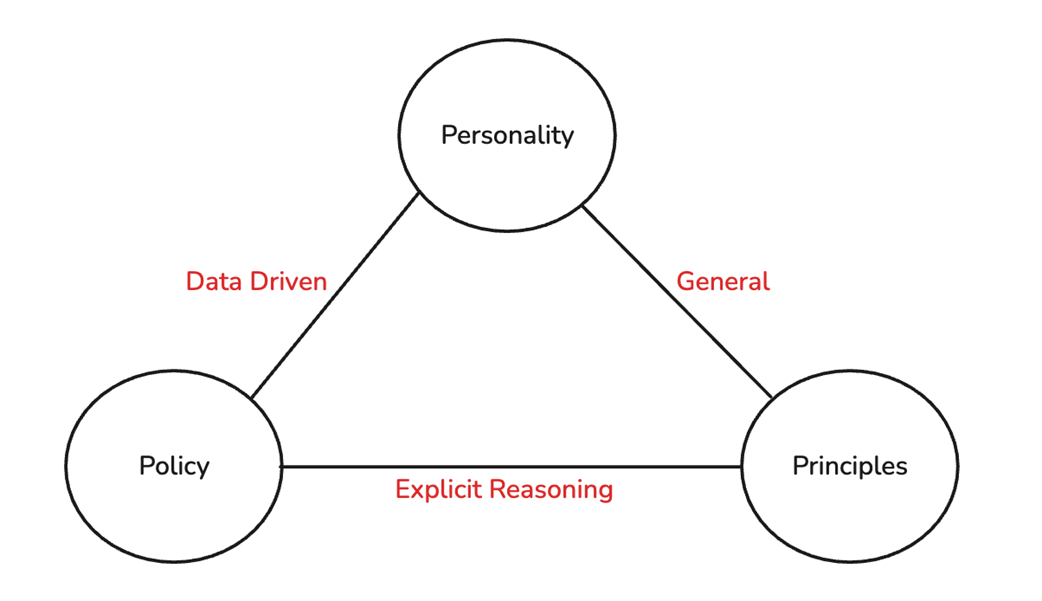
Alignment is framed through three interacting pillars: principled alignment, policy-based alignment, and personality alignment. Principled alignment encodes broad values such as helpfulness, harmlessness, fairness, cultural sensitivity, and uncertainty awareness; policy alignment enforces concrete rules, instruction hierarchies, compliance requirements, and resistance to manipulation; and personality alignment shapes tone, style, brand voice, and character consistency. The chapter concludes by emphasizing an iterative AI engineering cycle: define success metrics, evaluate the system, analyze failures, align behavior through prompts, retrieval, fine-tuning, policies, or training objectives, and repeat. Because evaluation signals often become reward signals, flawed metrics can produce flawed alignment, so practitioners must work backward from desired outcomes and design robust evaluations before optimizing systems.
A taxonomy of AI evaluation methods, distinguishing between verifiable tasks and open-ended tasks.
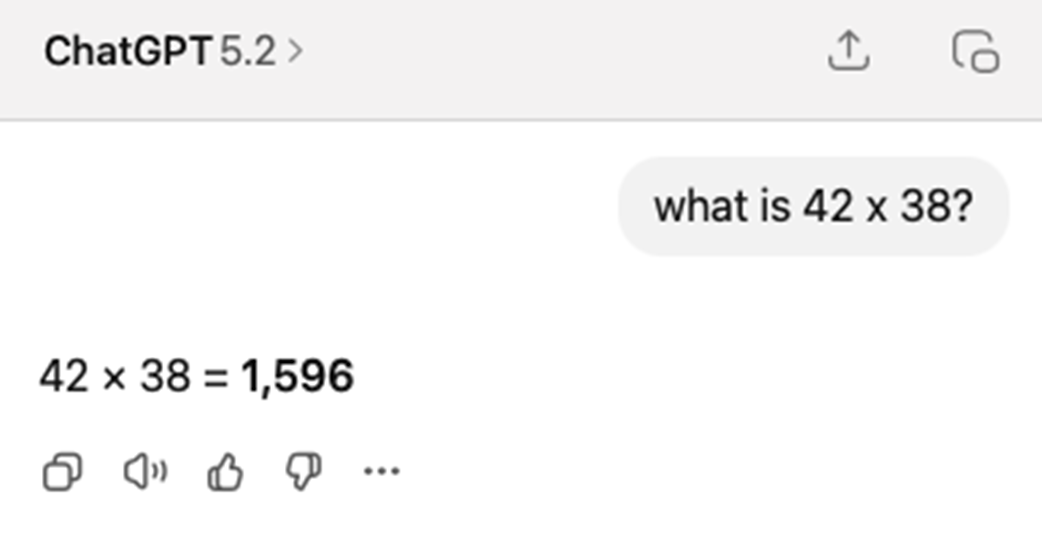
AI’s answer is correct but requires parsing. The model produces a chain-of-thought (COT) response where the final answer must be extracted from the surrounding text.
Open-ended evaluation tasks require navigating a landscape of subjective quality judgements and are broadly classified into Reference-based and reference-free evaluations.
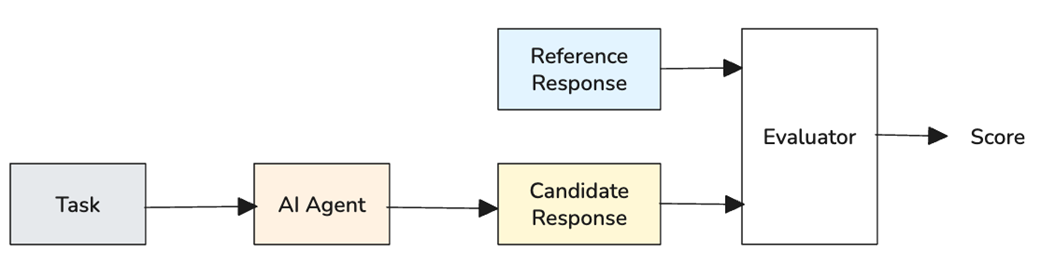
Reference-based evaluation workflow. Human experts create reference answers from a test set. The AI system generates candidate responses from the same inputs. The evaluator then compares each candidate's response with the corresponding reference response, producing scores.
Reference-free evaluation workflow. Quality signals are defined for the task. The AI generates outputs for test inputs. Metrics assess each output’s intrinsic properties without reference answers. Scores reveal quality patterns and failure modes.
Example task evaluation instructions provided to Amazon Mechanical Turk data labeler.

Training progression showing how models learn format before knowledge. Source: “Characterizing Learning Curves During Language Model Pre-Training: Learning, Forgetting, and Stability” by Chang et al, 2023.

Example of hallucinated authorship in an AI response.
Three pillars of alignment and how they relate to each other.
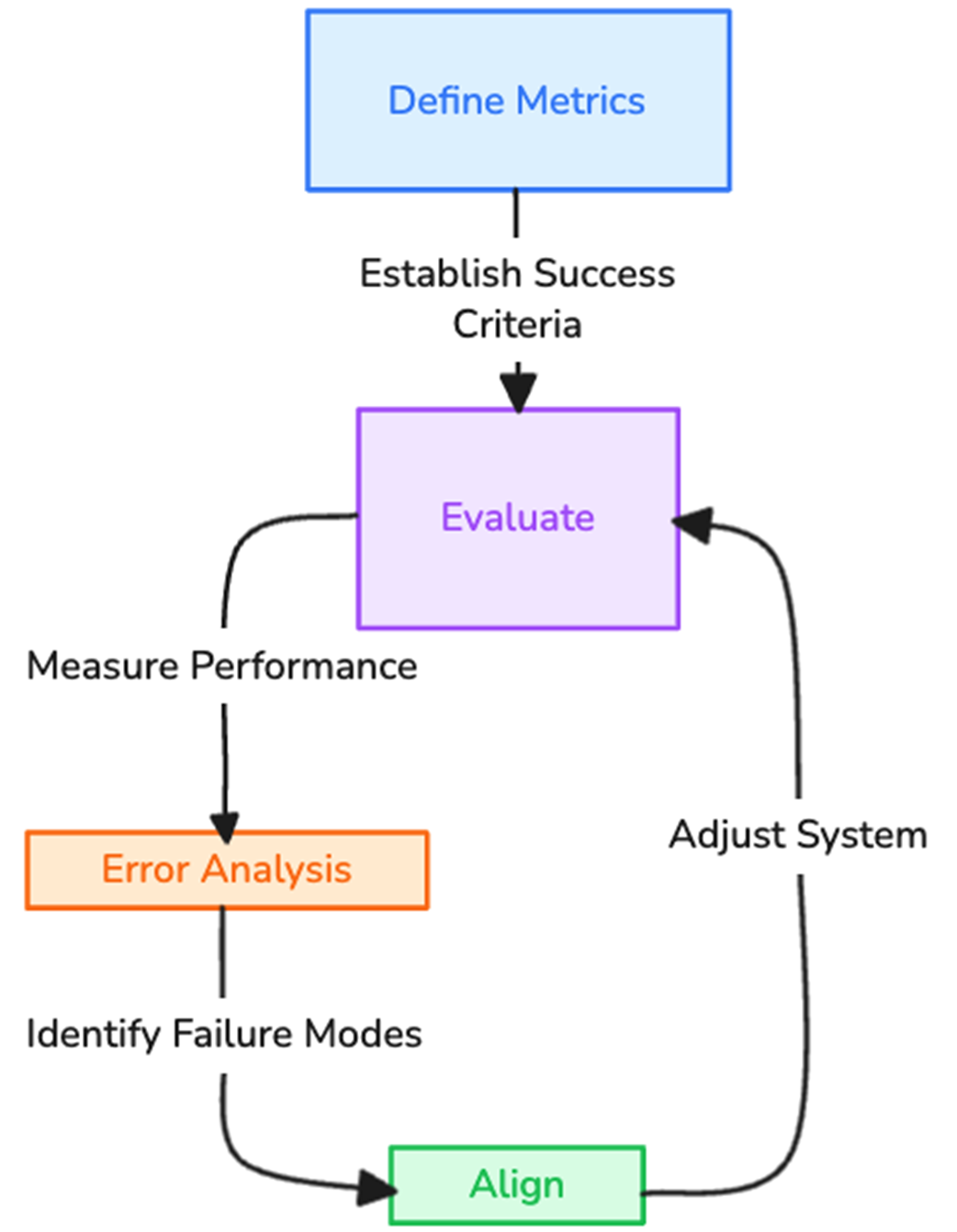
The iterative cycle of AI engineering. Define establishes what success looks like, Evaluate measures the current system against the designed evaluation metrics, Error analysis identifies failure modes, and then Align optimizes the system using different methods. The cycle then repeats.
Summary
- Evaluation measures whether a model, agent, or AI system performs the intended task accurately, reliably, and across edge cases. Alignment ensures the model’s behavior matches human goals, intentions, and values. Together, they ensure AI systems follow user intent and complete tasks safely.
- AI systems span a spectrum from verifiable to open-ended tasks.
- Verifiable tasks have objectively checkable outputs—coding and math are common examples.
- Open-ended tasks lack objective verification; examples include translation, report generation, and creative writing.
- There are two broad approaches to evaluating open-ended tasks, both aiming to approximate human judgment as closely as possible.
- Reference-based evaluations compare model outputs to expert-produced gold standards.
- Reference-free evaluations rely on intrinsic properties of generated content, sometimes guided by expert criteria.
- Evaluations may use heuristic, statistical, semantic, or LLM-as-a-Judge methods to align with human evaluators, even though humans often disagree.
- Hallucinations occur because AI systems learn structure and form before learning factual grounding—they master how to sound correct before knowing what is correct. Hallucination can be measured using faithfulness metrics.
- The three pillars of alignment are principled, policy-based, and personality-based.
- Principled alignment aligns AI with foundational human values.
- Policy-based alignment aligns AI behavior with specific rules, norms, or institutional policies.
- Personality-based alignment shapes consistent traits and communication styles in AI behavior.
- Evaluation and alignment are interdependent. Evaluation metrics become optimization targets, creating feedback loops that can lead to emergent or unintended behaviors.
- Working backward from desired outcomes distinguishes AI engineering from research and other forms of engineering — we define metrics first, then build systems to optimize them.
- There is no one-size-fits-all solution. Every evaluation and alignment technique involves trade-offs that must be carefully balanced for specific use cases.
FAQ
What is the difference between evaluation and alignment in AI systems?
Evaluation measures what an AI model or system actually does: its accuracy, reliability, behavior on edge cases, and performance against task criteria. Alignment focuses on what the system should do: following instructions, respecting constraints, behaving consistently with human goals, and avoiding harmful or undesirable behavior.
Together, evaluation and alignment form a feedback loop: evaluation identifies gaps between actual and desired behavior, and alignment applies interventions to close those gaps.
Why are AI evaluations harder than traditional software tests?
Traditional software tests often check deterministic behavior: for example, whether a sorting algorithm returns a correctly sorted list. Classical machine learning evaluation can often compare predictions against labeled data.
LLMs are harder to evaluate because they generate free-form language. The same prompt may have many valid responses, and quality may depend on subjective properties such as helpfulness, coherence, tone, factuality, and user context. This requires methods beyond unit tests, accuracy scores, confusion matrices, and loss curves.
What is the difference between verifiable and open-ended tasks?
Verifiable tasks have objective, checkable answers. Examples include arithmetic problems, code that must pass unit tests, and classification into predefined categories. These are convergent tasks because correct answers converge on the same result or an equivalent result.
Open-ended tasks allow many valid outputs. Examples include summarization, creative writing, dialogue, explanation, and marketing copy. These are divergent tasks because quality depends on context, preferences, and judgment rather than a single correct answer.
What are the main challenges of evaluating verifiable tasks?
Even verifiable tasks have practical difficulties. One challenge is answer extraction: a model may provide the correct answer inside a long chain-of-thought explanation, making it hard to parse reliably.
Other challenges include verifier reliability, coverage gaps in test suites, correct answers produced by flawed reasoning, and multiple valid solutions that differ in readability, efficiency, or maintainability. For example, code may pass all tests but still be poorly written or fail on untested edge cases.
What are reference-based evaluations?
Reference-based evaluations compare an AI system’s output against human-created or human-verified answers, often called a golden dataset. If the candidate response is similar to the reference response, the model receives a higher score.
Common reference-based metrics include ROUGE for summarization, BLEU for translation, and BERTScore for semantic similarity. These methods are useful because they are automatic and repeatable, but they can penalize valid responses that express the same idea in a different or better way.
What are reference-free evaluations?
Reference-free evaluations judge an output without comparing it to a gold-standard answer. Instead of asking whether the response matches an expected answer, they ask whether the response has desirable qualities such as relevance, politeness, coherence, factual grounding, completeness, or appropriate tone.
Reference-free evaluation methods include intrinsic quality metrics, human evaluations, and LLM-as-a-Judge systems. These methods are especially important for real-world tasks where no single correct response exists, such as customer support conversations or open-ended explanations.
What is LLM-as-a-Judge?
LLM-as-a-Judge is an evaluation method where a capable language model is used to assess the outputs of another model or system. The judging model receives evaluation instructions similar to those given to a human evaluator and produces scores, rankings, or explanations.
This approach can scale human-like evaluation quickly and cheaply, but it raises concerns about bias, self-evaluation, cost, and verifier reliability. It also creates the question: who evaluates the evaluator?
What is hallucination, and how can it be measured?
Hallucination occurs when an AI model generates information that is not backed by facts or evidence. It is especially dangerous because hallucinated outputs can sound fluent, confident, and plausible.
One way to measure hallucination is through faithfulness. A response is broken into claims, each claim is checked against evidence, and the ratio of supported claims to total claims is computed. Higher faithfulness means fewer unsupported claims; lower faithfulness means more hallucination.
What are the three pillars of AI alignment?
The chapter describes three pillars of alignment: principled alignment, policy-based alignment, and personality alignment.
Principled alignment embeds values and ethical principles, such as being helpful, harmless, fair, and honest. Policy-based alignment ensures the model follows specific rules, procedures, instruction hierarchies, and compliance requirements. Personality alignment shapes how the model communicates, including tone, style, brand voice, and character consistency.
What is the iterative mental model for evaluation and alignment?
The iterative mental model treats evaluation and alignment as a continuous cycle rather than separate phases. First, define what “good” looks like through evaluation criteria. Then measure the system against those criteria. Next, analyze errors to identify gaps between current and desired behavior. Finally, apply alignment techniques to improve the system and repeat the process.
This cycle applies across model selection, prompt engineering, RAG development, fine-tuning, and production monitoring. In AI engineering, the “fix” is often not a code change but an adjustment to prompts, retrieval, tools, orchestration logic, or model weights.
 Evaluation and Alignment, The Seminal Papers ebook for free
Evaluation and Alignment, The Seminal Papers ebook for free