5 Improving weak understanding for traditional AI
This chapter presents a practical, iterative approach to strengthening the intent understanding of traditional, classification-based conversational AI. It begins by establishing a clear measurement framework—beyond simple accuracy—using recall, precision, and F1 to diagnose false positives and false negatives at the intent level. With a representative blind test set (or k-fold as an early proxy), teams identify where the model is confused, visualize misclassifications with a confusion matrix, and prioritize fixes by business impact and volume. The guidance emphasizes incremental changes, testing after each update, and aligning training data distribution with real user demand captured in production logs.
Through a stepwise improvement plan, the chapter demonstrates several high-yield tactics. It shows how adding real-user examples can lift recall for underperforming intents (e.g., a login issue intent), how pruning redundant or unrepresentative examples can boost precision (e.g., chitchat about the assistant), and how targeted data augmentation can raise an intent’s F1 when both recall and precision matter. When heavy overlap creates persistent confusion, merging related intents and using entity detection to route to the correct downstream answer can simplify the space and improve accuracy. Iterating across versions in this manner moves a working solution from ~76% to ~92% overall blind-test accuracy, while cautioning against overfitting small datasets and reminding teams to keep performance grounded in fresh, representative logs.
Beyond fixes to existing scope, the chapter outlines how to expand coverage by clustering unmatched utterances into new intents (e.g., canceling licenses/registrations or addressing a data breach) and deciding when to stop adding intents with a long-tail analysis that separates high-value topics from low-frequency outliers. It closes by showing how to enrich traditional intent-driven responses with a light layer of generative text: an LLM can prepend a brief, empathetic, situation-aware greeting and summary before delivering a consistent, static answer. This hybrid pattern improves user experience without sacrificing compliance or answer stability, and pairs well with a continuous, data-driven improvement loop anchored in blind testing and careful prioritization.
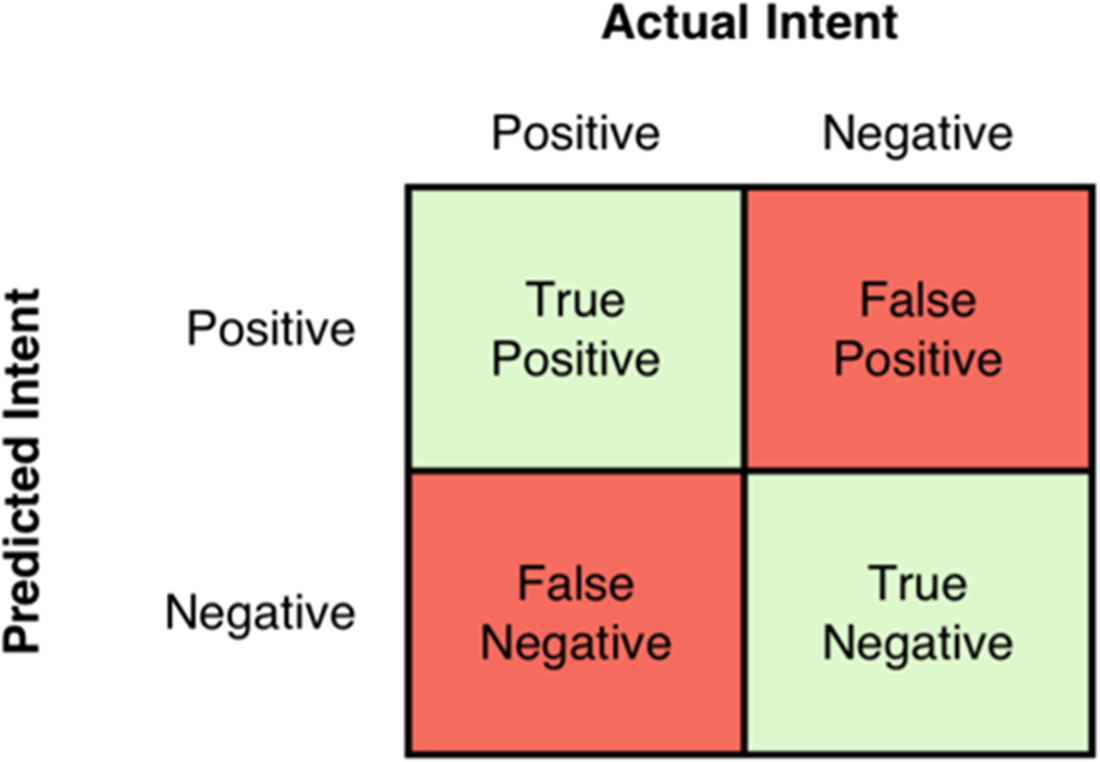
In a 2x2 confusion matrix, the possible outcomes are derived by comparing the predicted intent to the actual intent.
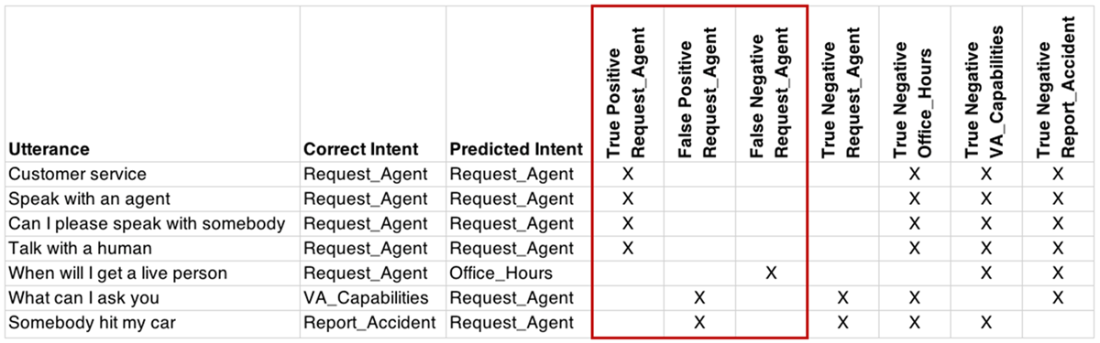
The highlighted columns are used for calculating precision and recall for #Request_Agent.
A solid diagonal line shows that each predicted intent (represented by a single letter) matched to the actual intent.
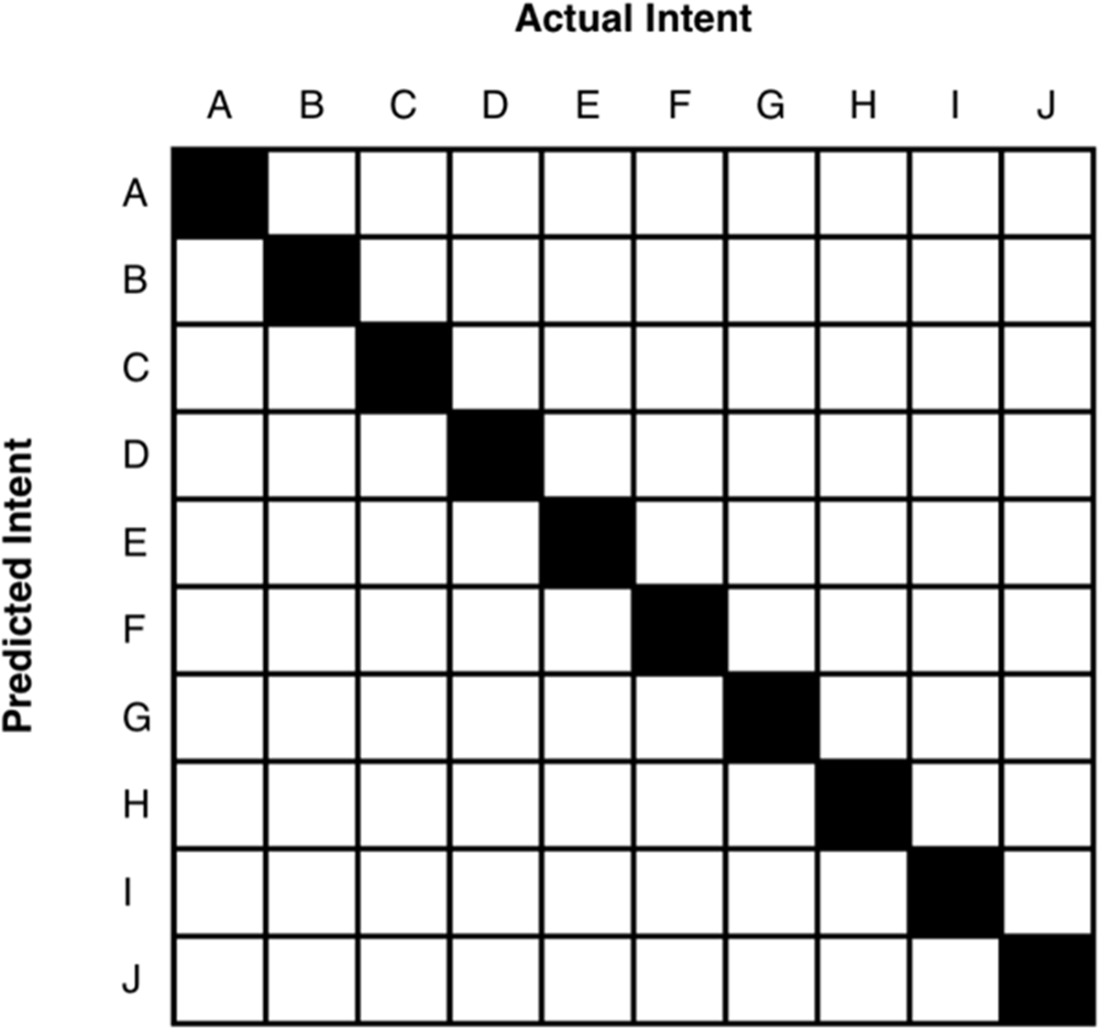
This model had nine correct predictions, but wrongly predicted intent G when the actual intent was E.

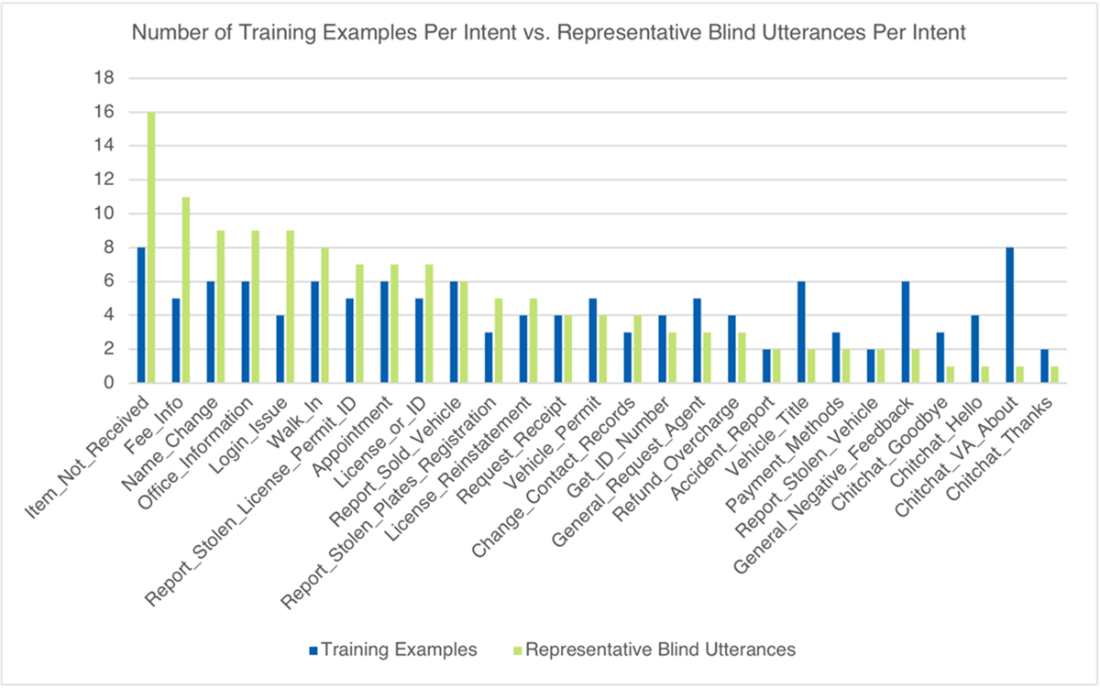
A comparison of training examples to the utterances in our representative blind test set shows that there is some disparity in volume for many of the most popular intents (the representative blind utterances) on the left. We also see disparity across several of the least popular intents (those on the right).
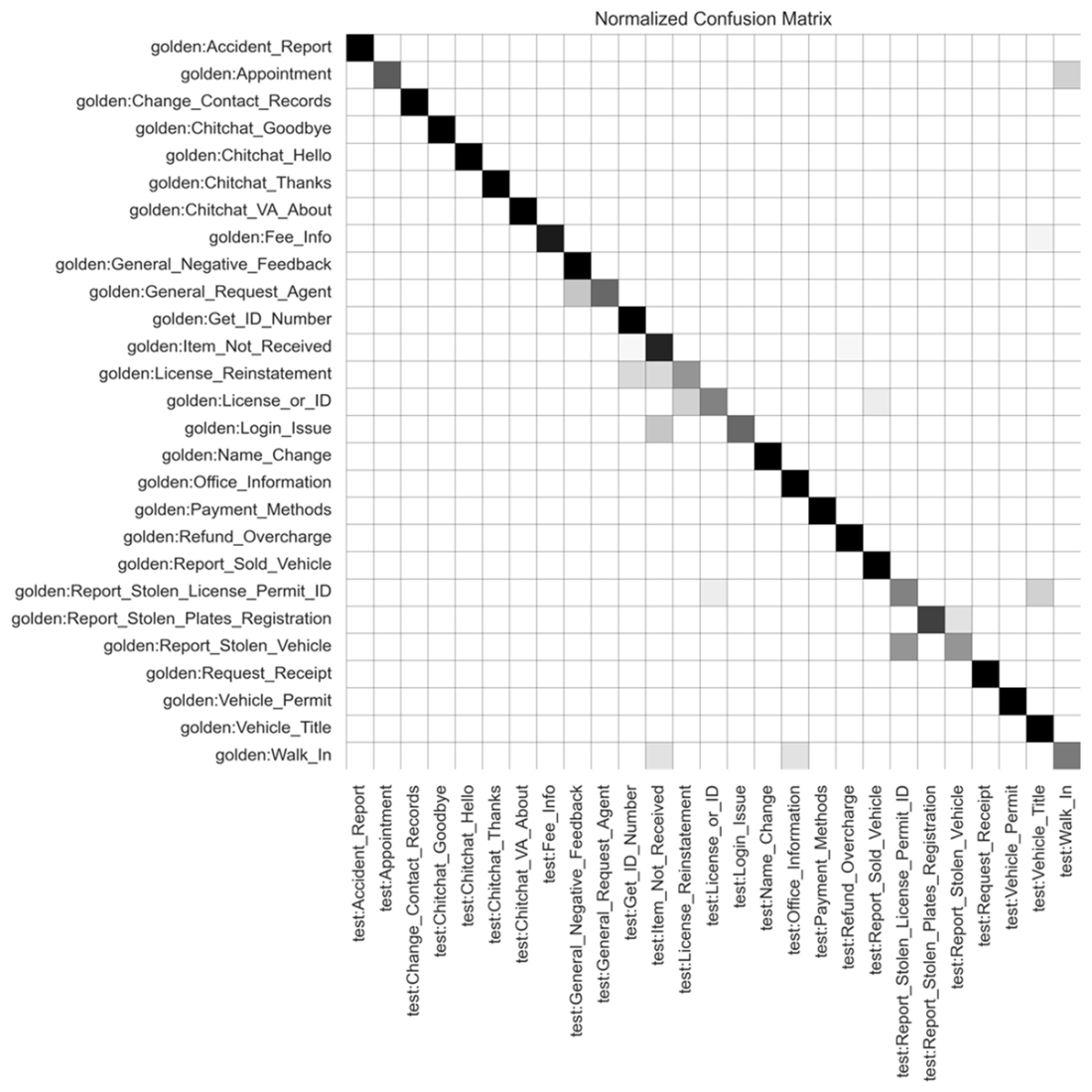
Confusion matrix after V4 update. The density in shading represents the volume of questions predicted for a given intent. If a classifier test had a perfect accuracy score, you would see a solid black diagonal line running from the upper left corner to the lower right corner. The shaded squares that stray away from this diagonal line marks the areas of confusion within your model.
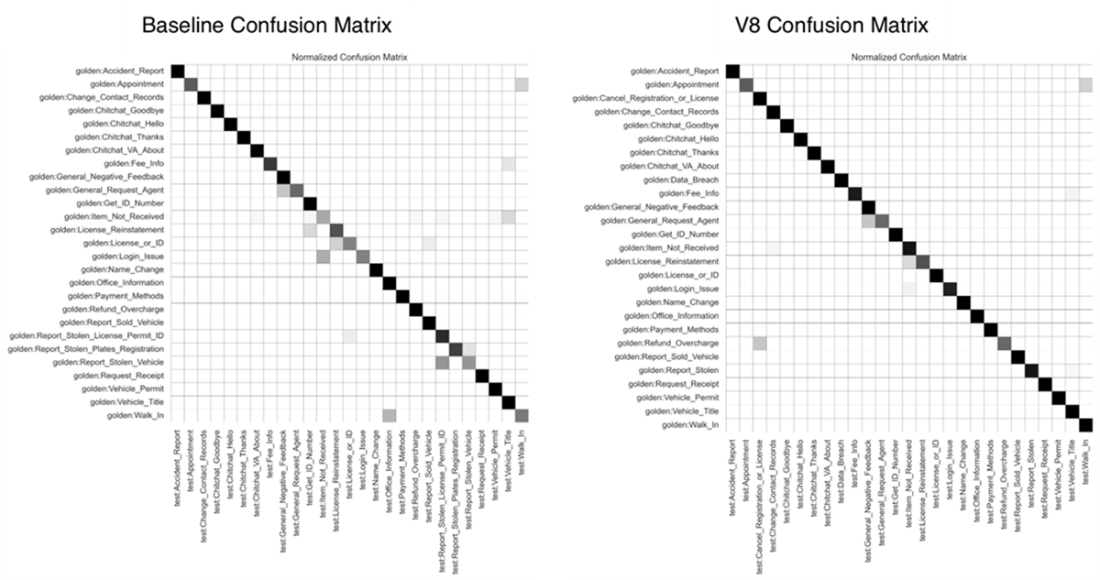
Comparison of baseline (V1) confusion matrix to V8 update.
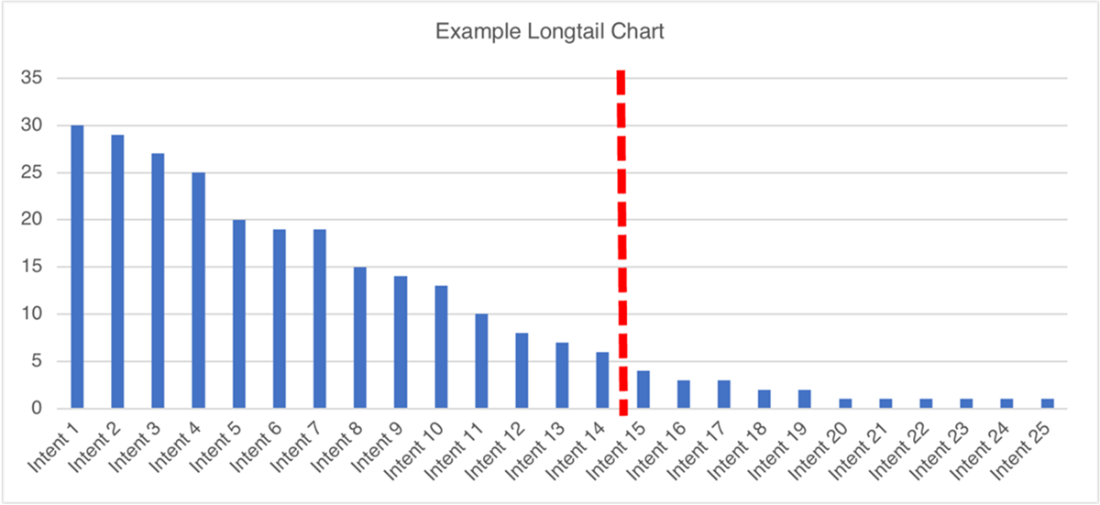
Example of a longtail chart. The terms we use to describe the volume distribution of our available training data are “short head” and “long tail.” These terms describe the visual representation of rendering our data on a bar chart. The heavier-volume intents are on the left (the short head), and as the volume decreases for each intent, the data has the appearance of a long tail falling off to the right.
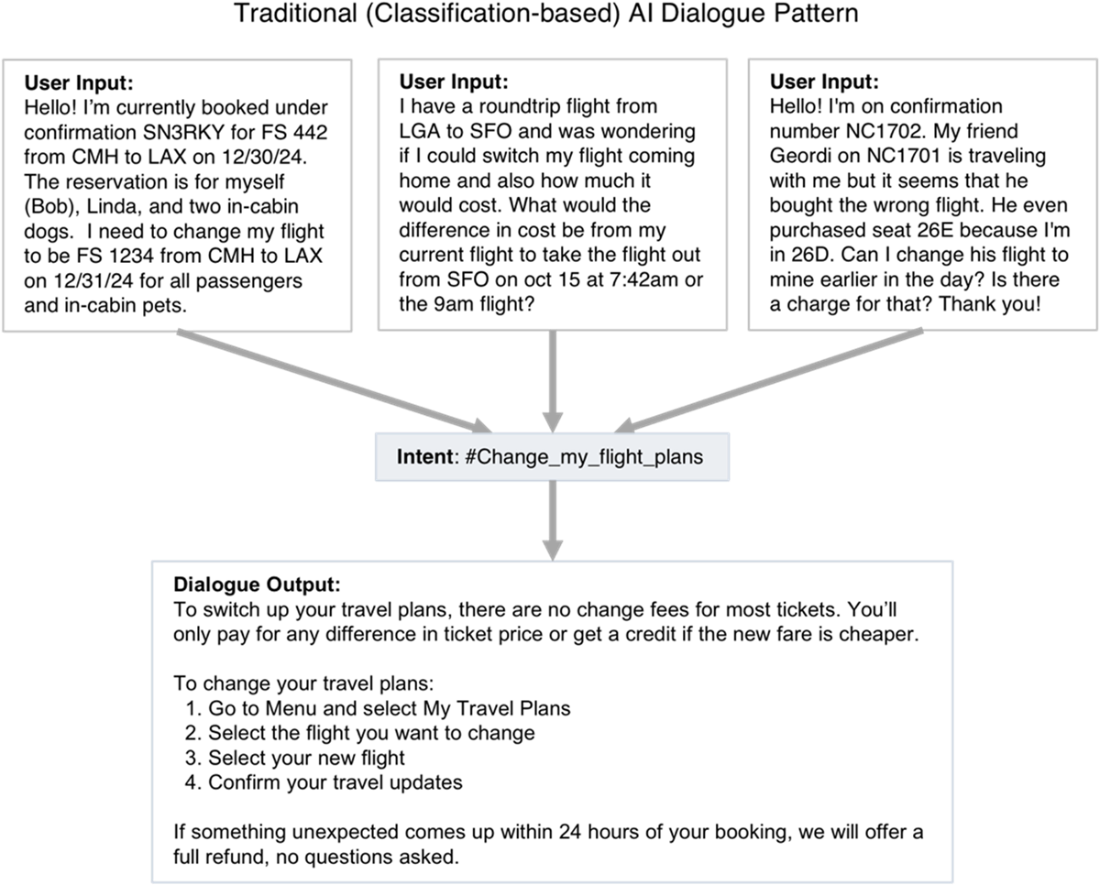
In a traditional (classification-based) dialogue pattern, an intent is identified, and the dialogue is configured to give a static or minimally-personalized answer.
An output response identifies the correct intent using traditional AI, then prepends generated text to a static output response configured for the intent. The generated greeting and summary convey to the user that the bot understands their goal and the particular details of the user’s situation.
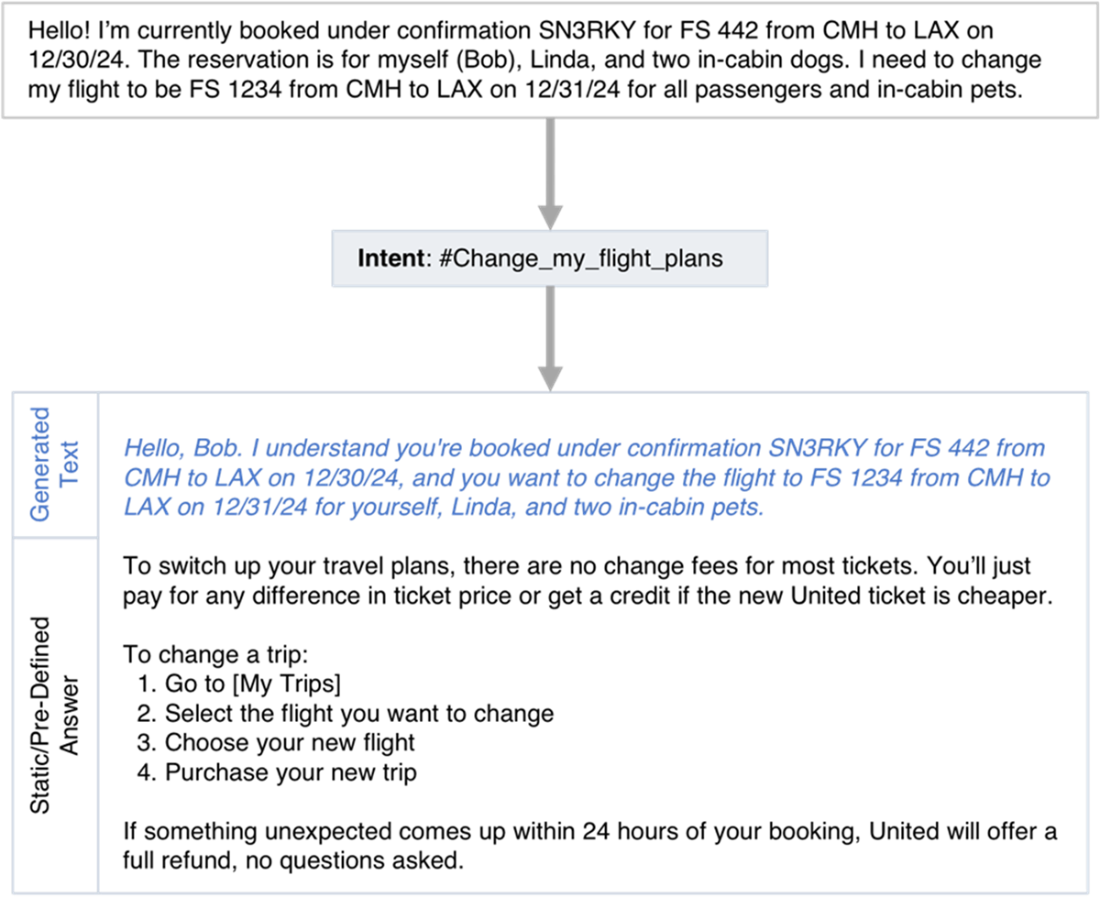
LLMs can be called within traditional dialogue patterns to greet a user and summarize their problem before delivering a pre-defined or static answer.

Summary
- A classifier’s performance can be measured in terms of accuracy, recall, precision, and F1-score. These measurements reflect the types of errors a classifier may be committing.
- The performance metrics produced by your testing will inform your next steps towards classifier performance improvement. Higher volume intents with low performance are a good place to start.
- Iterative test/train cycles will show you the effects of your changes.
- A chatbot can use additional strategies, such as disambiguation, clarifying questions, and entity detection to overcome confusion or route answers for merged intents
- A chatbot with a strong classifier can deliver more business value by delivering the right answers on the first try and deflecting work that would otherwise be handled by a human agent. You should plan to monitor and re-train your solution throughout the life of the bot.
- Generative AI can supplement a traditional AI solution by infusing static chatbot responses with personalization and empathy, which enhances the perception of understanding.
 Effective Conversational AI ebook for free
Effective Conversational AI ebook for free