3 Planning for improvement
Planning for improvement starts with defining what “success” means for your conversational AI, because expectations differ by bot type: Q&A assistants prioritize fast, accurate answers with minimal back-and-forth, process bots focus on guiding users to complete tasks efficiently, and routing agents aim to hand users off to the right destination seamlessly. As user needs, business goals, and external conditions shift, assistants must evolve in step. The chapter illustrates this with MediWorld’s PharmaBot, which moved from a narrow information bot to a process-oriented assistant for vaccine scheduling—highlighting how organizations must align around continuous, data-driven improvement to meet rising expectations and reduce opt-outs and escalations.
Effective improvement requires a cross-functional team—conversational analysts, developers, data analysts, customer support, product, legal/compliance, IT, and governance—aligned on business outcomes and the metrics that prove them, from revenue impact (conversion, AOV, CLV) to cost reduction (containment, FCR, AHT). The chapter urges teams to go beyond simple KPIs like containment by classifying granular conversation outcomes (e.g., automated resolution, intentional transfer, abandonment, escalations, bot-not-wanted) and linking them to design milestones to pinpoint friction. It also covers improving coverage (training data, intent clarity, retrieval/generative patterns), complementing inferred satisfaction with direct signals (thumbs/NPS), and accounting for security and privacy as bots integrate deeper into transactional flows.
The improvement lifecycle is made operational through structured practices: instrument and analyze outcomes, spot trends, and drill down by last step; blend qualitative feedback with quantitative timing to diagnose issues; triage by frequency, expected return, and implementation effort; and prioritize with cost–benefit and impact–effort framing. Teams then outline high-level fixes, define clear acceptance criteria, and deliver in sprints with visible ownership and status. Crucially, they measure again against baselines to verify that changes move target metrics and ROI, iterating as needed. Governance, documentation, and regular stakeholder communication keep the roadmap aligned with policy, ethics, and evolving business needs.
PharmaBot efficiently detected informational intents from user queries.

The team identified areas for improvement using their diverse skills, setting the stage for an effective improvement plan.
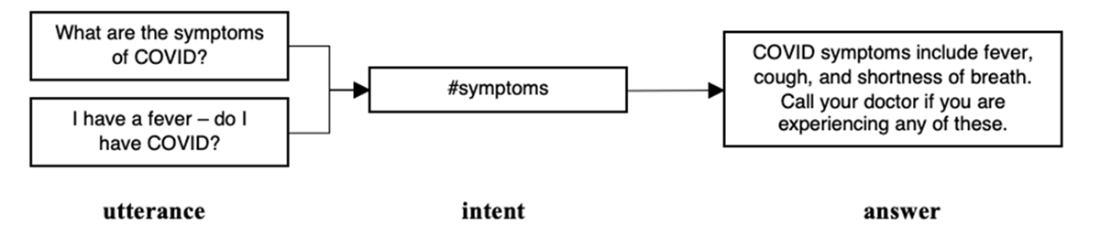
PharmaBot started as a simple Q&A bot. Many question varieties got the same answer.
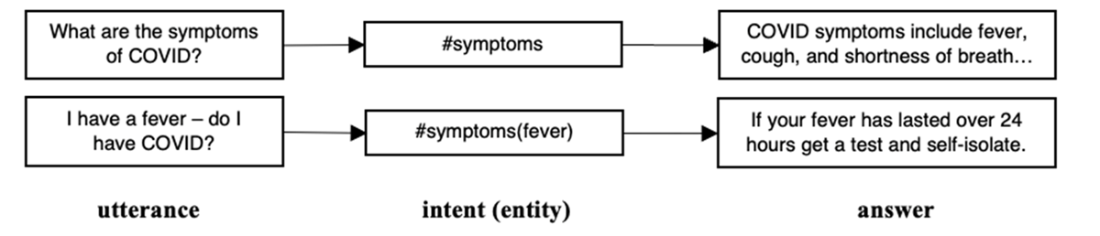
Q&A got more complex by detecting entities in user utterances, leading to more specific answers within a common intent.
Some question types do not have a single static answer but require a full process flow to satisfy.

PharmaBot's basic analytic dashboard shows a usage summary but cannot give insight into what users like (or don’t like) about the bot.
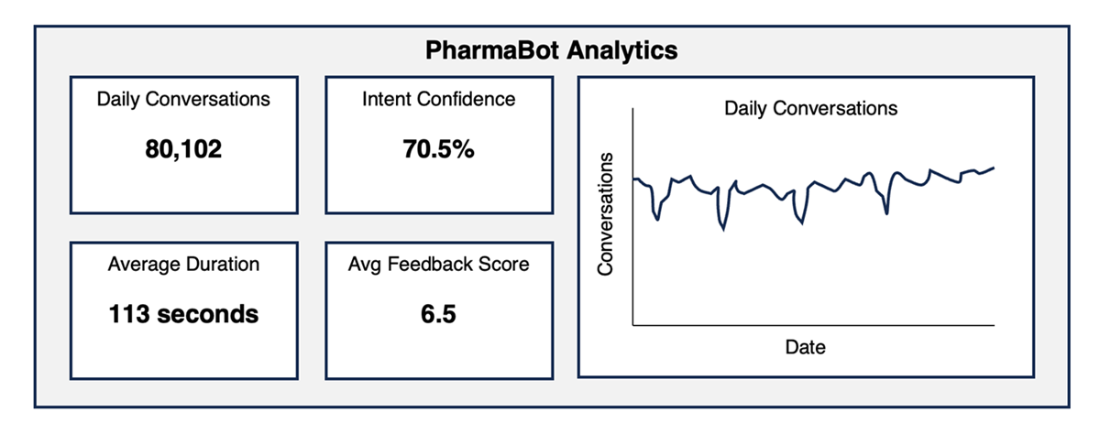
Basic daily dashboard showing a simple business metric: containment. This metric is tracked daily but still does not give deep insights into bot performance.
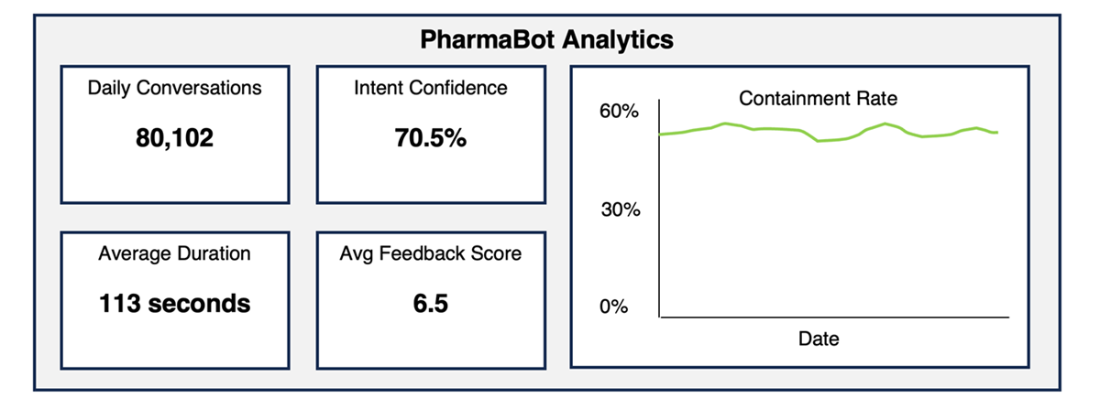
The simplest outcome definition. This does not give insight into how to improve the bot.

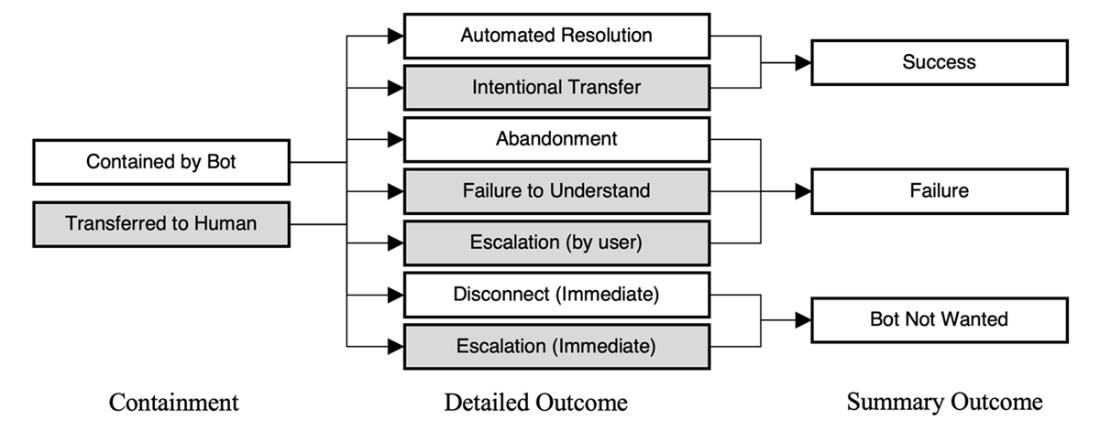
Breaking down why conversations are not contained gives more insight into bot performance and shows you where your bot needs improvement.
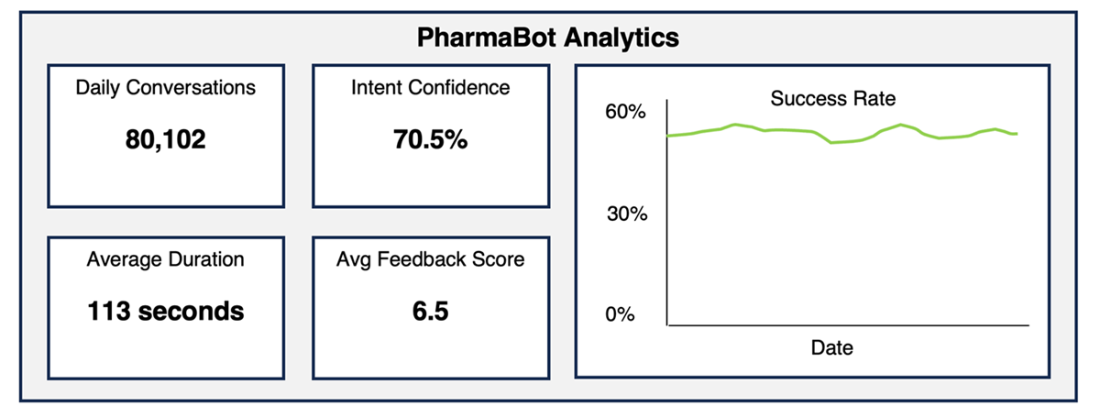
Enhancing the summary dashboard with a success rate. Not all contained calls are successful; not all transferred calls are failures.
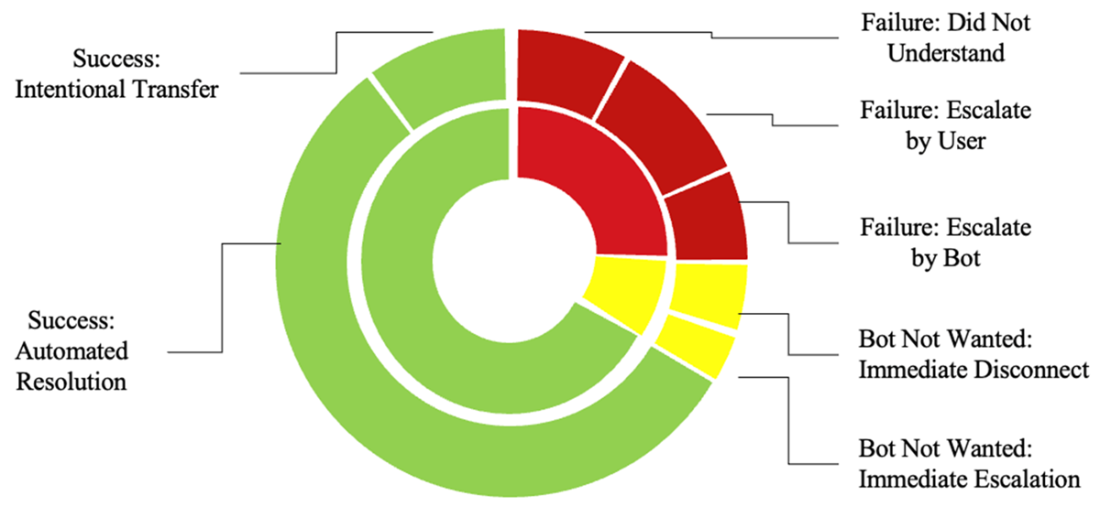
Conversation Outcomes and Outcome Details aggregated over a set time period. This provides much greater insights into bot performance than a binary “contained or not contained” model.
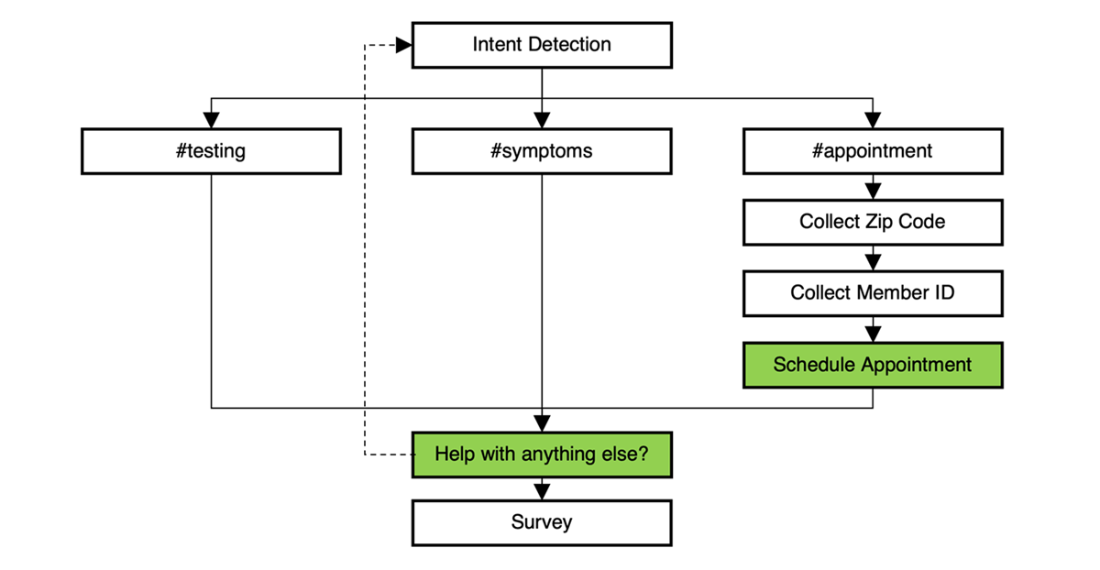
High-level design of PharmaBot with milestones for significant parts of the conversation. “Schedule appointmet” and “Help with anything else?” are both marked as successful paths.
When the outcome model and conversation design are overlaid, insights become apparent. Here we zoom in on the "Escalated by User" outcome, broken down by last step before the escalation.
Dashboard which breaks down an outcome by last step taken, observed over time.
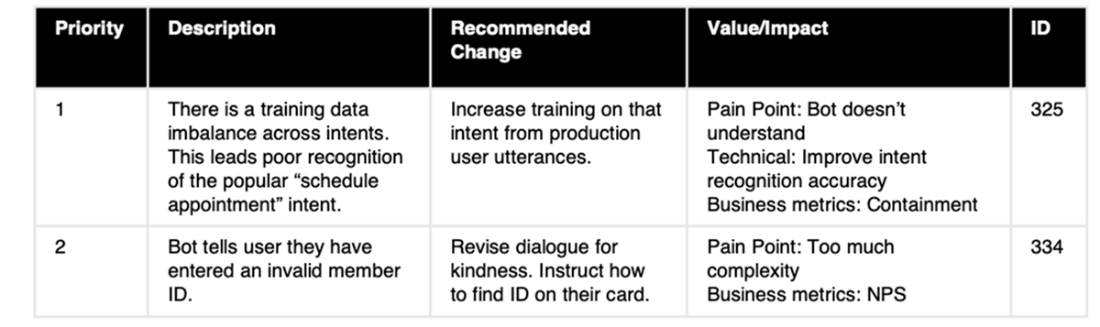
Triage of issues describing insights and recommendations related to each issue, which contributes to its priority.

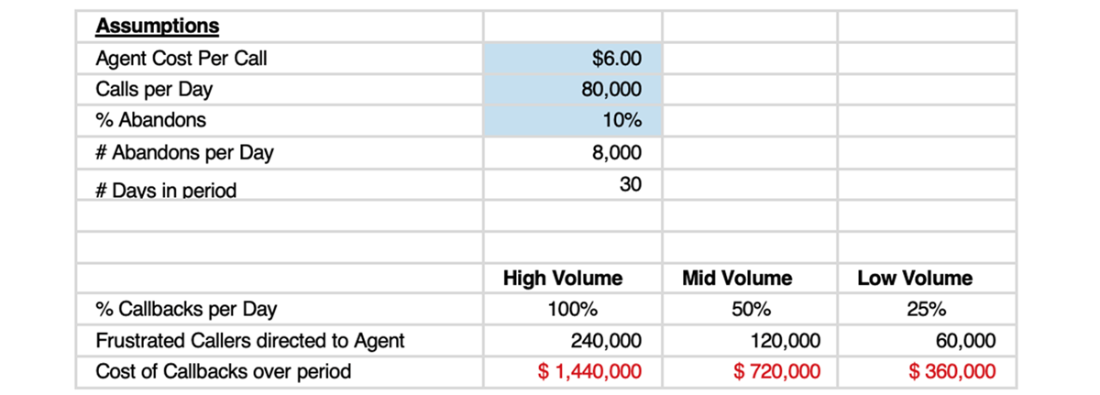
Assessment of the cost of users reaching call center agents after abandoning their chatbot conversations in frustration.
An impact-effort matrix visualizes the relationship between the effort required and potential impact of a proposed change.
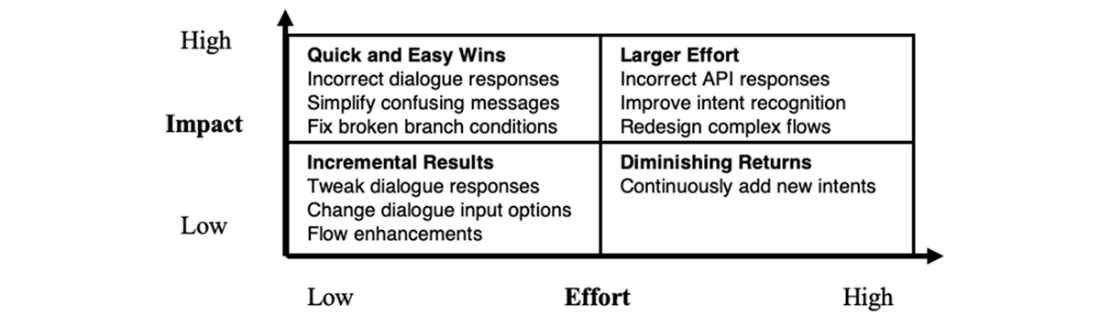
A sample prioritized fix list.
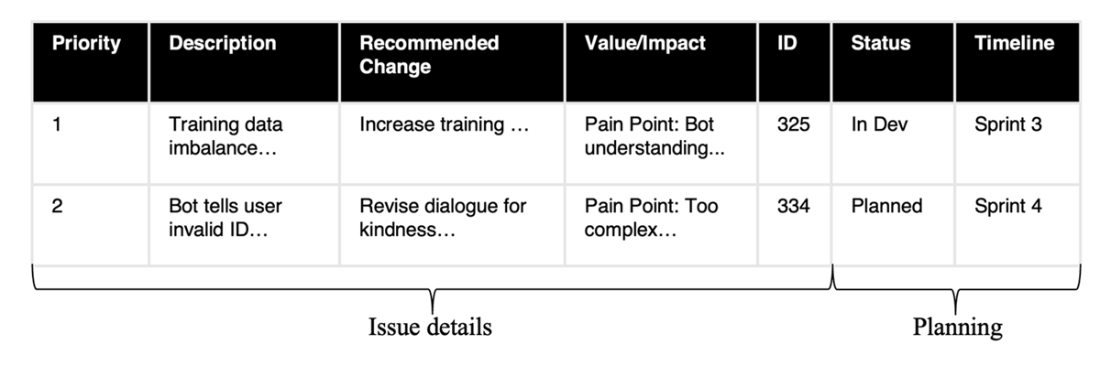
A prioritized table, including development sprints. Further columns, including UAT times and expected deployment dates, may be added.
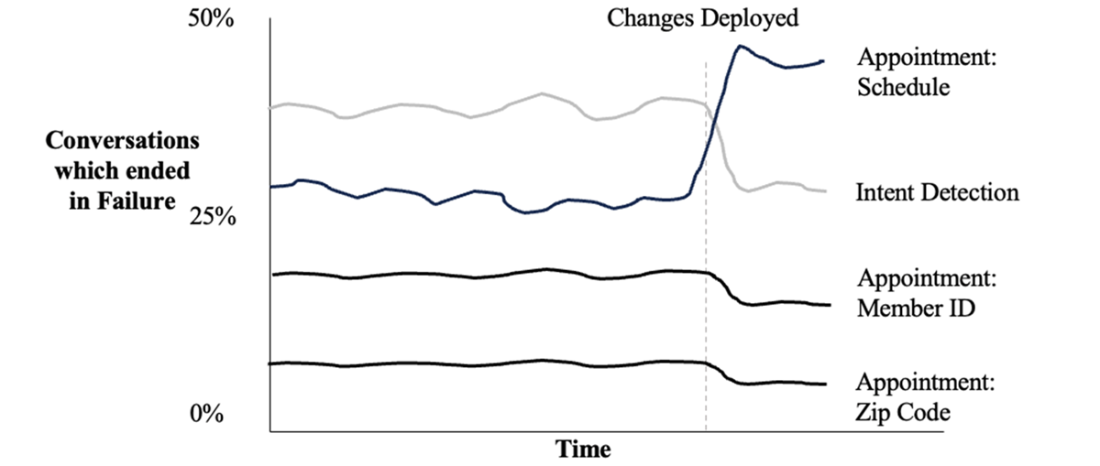
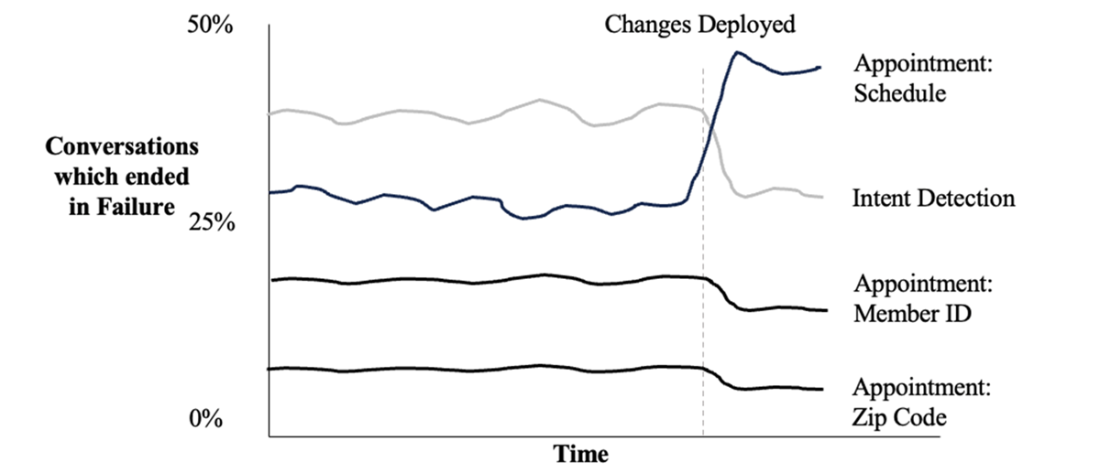
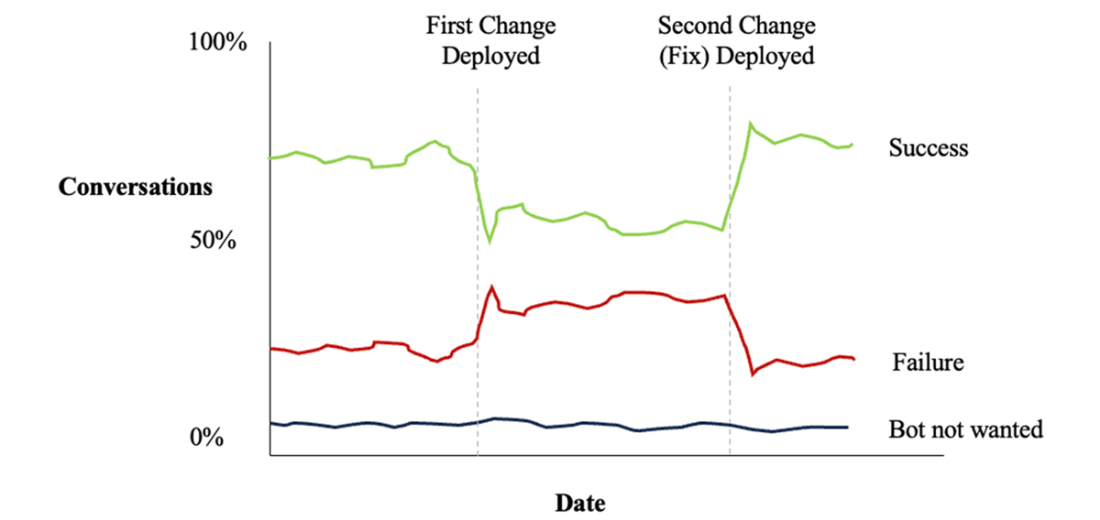
Tracking conversation outcomes against deployment of changes.
Summary
- The continuous improvement cycle for conversational systems is an ongoing, iterative process.
- All improvements should drive toward the pre-defined business goals and user satisfaction.
- Meticulous metric definition, the right choice of monitoring tools, and a commitment to best practices are key.
- Use the “right” metrics relevant to your bot rather than those easiest to measure.
- Detailed conversation outcomes allow targeting a specific set of conversations for improvement.
- Several factors can determine an issue's priority, such as its frequency of occurrence, the expected improvement and complexity of a fix, and the team's capacity.
- Regression testing and analyzing improvements are critical to ensure that indeed improvements have occurred.
FAQ
How do I know when my conversational AI needs improvement?
Watch for signals in your KPIs and user behavior: low containment, high fallback intent usage, frequent agent escalations, immediate opt-outs, declining engagement, or unmet business goals. Start improvements as soon as you see recurring issues and set regular review cycles so changes stay aligned with evolving user needs and organizational objectives.Who should be on the cross-functional improvement team?
- Support/Maintenance: data analyst/engineer, chatbot developer or conversational analyst, QA tester, project manager, and other SMEs (e.g., security).- Business stakeholders: executive leadership, customer service, chatbot product manager, IT, operations, legal and compliance.
- Governance: corporate ethics/compliance focal and a governing executive team. These groups align technical work with business value, policy, and responsible AI standards.
How do we align on what “success” means for the bot?
Revisit the original business goals and match them to bot type: Q&A bots should be fast and accurate; process-oriented bots should complete tasks efficiently (e.g., bookings); routing agents should direct users to the right destination. Translate goals into measurable metrics like accuracy, user satisfaction, coverage, conversion, AOV/CLV, AHT, FCR, and ROI.What’s the difference between containment and true success?
Containment means the bot handled the interaction without a human, but it doesn’t guarantee a good outcome. Define outcomes more precisely:- Success: Automated Resolution; Intentional Transfer (a planned handoff per business rules).
- Failure: Abandoned; Escalated (by user or bot).
- Chatbot Not Wanted: Immediate Disconnect; Immediate Escalation. This clarity shows “good transfers” and avoids counting “bad containments” as wins.
How can we measure effectiveness beyond basic dashboards?
Go beyond counts and confidence scores by building a detailed outcome model and instrumenting milestones in your conversation design. Track outcomes by “last milestone” to see where journeys succeed or fail, break down success/failure reasons, and trend these over time to guide prioritization and stakeholder buy-in.What causes low coverage and how can we improve it?
Low coverage often stems from inadequate or imbalanced training data and overlapping/confused intents. Improve by analyzing real utterances, refining and rebalancing training data, restructuring intents, adding retrieval-augmented generation (RAG) for long-tail questions, and generating synthetic training/testing data where appropriate.How do we find and prioritize issues effectively?
Use both quantitative and qualitative methods:- Quantitative: trend failed and “bot not wanted” outcomes, drill down by last step, time per step, and backend latency; estimate financial impact (e.g., escalations).
- Qualitative: user feedback, call-center insights, transcript reviews.
Triaging considers issue frequency, impact, fix effort, dependencies, and expected return. Use an impact–effort matrix and maintain a prioritized fix list with IDs.
What are good acceptance criteria for a fix?
Write clear, testable statements that define how the bot must behave in specific scenarios, covering current and new behaviors. Validate in development and confirm in production by comparing against baseline metrics. Example: when asked to choose “vaccines or testing,” the bot correctly routes “vaccines,” “testing,” and handles ambiguous “yes” with confirmation.How should we plan delivery of improvements?
Adopt sprint-based delivery (1–4 weeks). Plan by team capacity and velocity, track progress with a board (issue, status, sprint, UAT, deployment date), and keep stakeholders informed. After deployment, re-measure targeted metrics and outcomes to verify the expected impact and inform the next iteration.How can we track customer satisfaction reliably?
Combine indirect and direct measures:- Indirect: infer satisfaction from outcome categories (e.g., automated resolution vs. abandoned/escalated).
- Direct: lightweight CSAT (thumbs up/down or score), brief surveys, NPS, and periodic transcript reviews. Expect lower response rates and bias; use multiple signals for a balanced view.
 Effective Conversational AI ebook for free
Effective Conversational AI ebook for free