This chapter broadens the focus from code-generation SLMs to chemistry and drug discovery, showing how Transformer models adapted to sequential chemical representations can generate meaningful biological and materials structures. It motivates domain-specific small language models as practical alternatives to large closed systems in settings where specialized data, task tuning, and unusual data formats limit general LLMs. Across three case studies—de novo protein design, therapeutic antibody generation, and crystal structure synthesis—the chapter blends modeling guidance with hands-on inference workflows, validation strategies tailored to each domain, and lightweight performance optimizations suitable for accessible hardware.
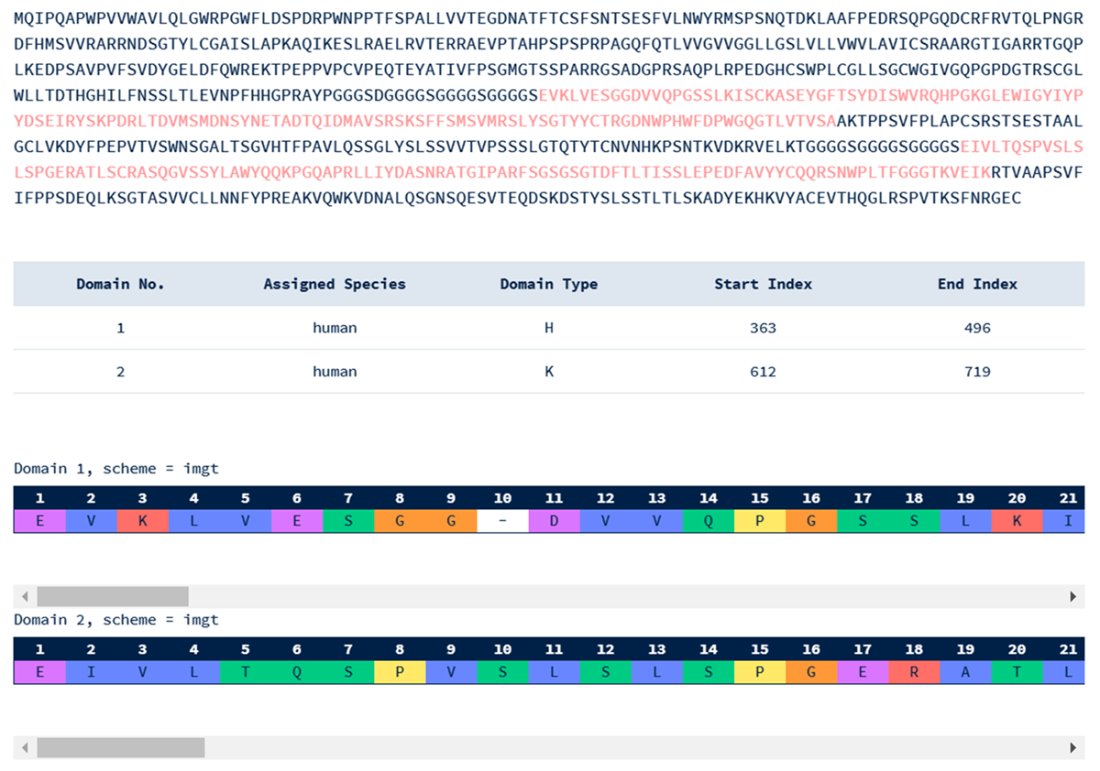
For proteins, ProtGPT2 is a 738M-parameter, decoder-only GPT-2 variant trained self-supervised on UniRef50 to predict next “oligomer” tokens, producing de novo sequences that preserve natural propensities, secondary structure, and globularity. Inference is straightforward via a standard pipeline and is fast enough on commodity CPUs; sequence quality can be triaged with perplexity. The Antibody Generator (AntibodyGPT) fine-tunes ProGen2 models (small/medium/large) on 5,000 antibody–antigen crystal structures to propose therapeutic antibody sequences. Inference typically needs a GPU for reasonable latency; enabling expandable CUDA allocator segments and applying 8-bit quantization via BitsAndBytes substantially reduce memory and time (e.g., shrinking a small model from ~617 MB to ~157 MB and cutting average latency by about 40%). Biological plausibility is assessed with ANARCI for numbering and receptor classification, with expert review advised.
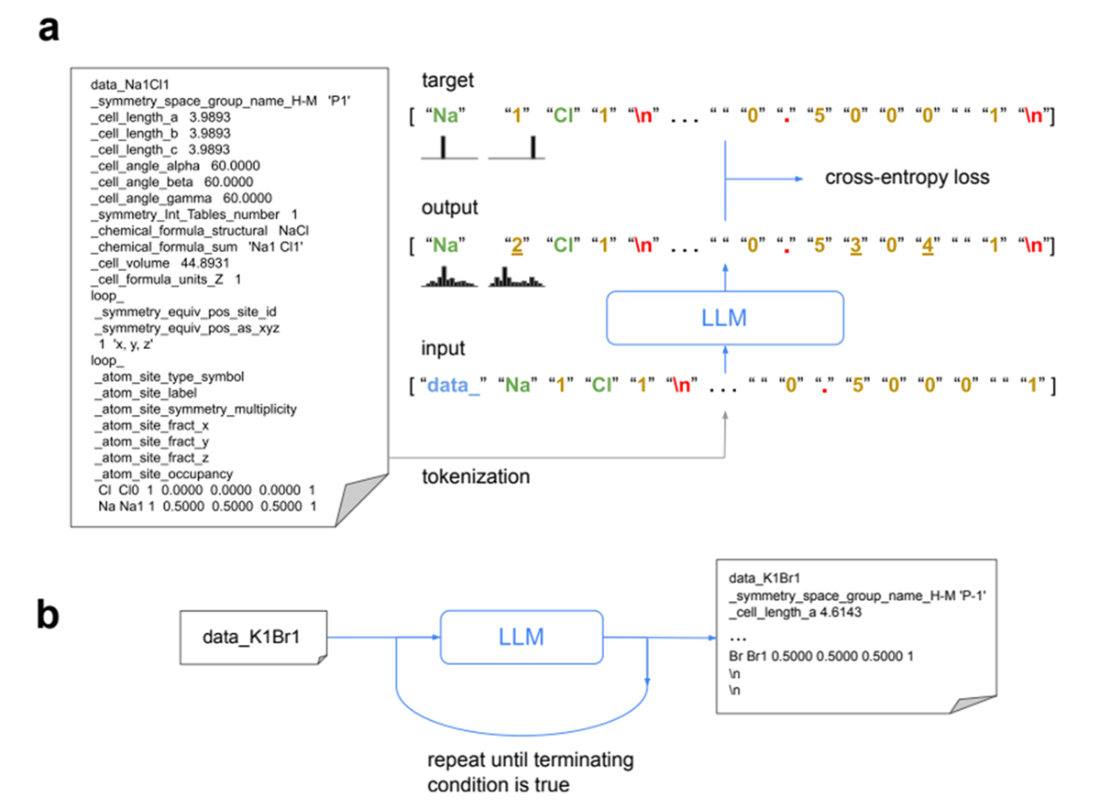
For materials, CrystaLLM treats crystallographic information files (CIF) as token sequences and performs GPT-style next-token prediction to generate valid inorganic crystal structures conditioned on prompts such as a target composition (for example, data_Na2Cl2). A small 25M-parameter model runs efficiently on CPU: the workflow creates a prompt, samples raw CIF content, post-processes it, and validates outputs for space-group and atomic consistency and reasonable bond lengths; an MCTS-based decoding option enhances structural sampling. The chapter also outlines how to wrap pretrained checkpoints for use with common tooling by adding a config, converting weights, and packaging for distribution. Overall, it demonstrates that compact, task-tuned SLMs—combined with domain-aware validation and modest inference optimizations—can deliver practical pipelines for protein and crystal structure generation.
The different options available for the ProGen2 and the Antibody Generator model families.
The output of the online ANARCI tool for one of the antibody sequences generated in our example.
The CrystaLLM training (a) and generation with MCTS decoding (b) processes.
Summary
Chemistry language models adapt NLP techniques to represent molecular structures as text sequences for drug discovery tasks.
ProtGPT2 generates protein sequences using a decoder-only GPT-2 architecture trained on 87162 protein sequences from UniRef50 database.
Protein generation requires prompting with endoftext tokens and produces amino acid sequences that follow natural protein patterns.
Perplexity scoring evaluates generated protein sequences with lower scores indicating better quality outputs.
AntibodyGPT fine-tunes ProGen2 models on 5000 experimentally resolved crystal structures for therapeutic antibody generation.
ProGenForCausalLM class enables loading and inference with ProGen2-based models from custom repositories.
CUDA memory allocation settings can improve inference latency by enabling expandable segments for better memory management.
8-bit quantization reduces AntibodyGPT model size from 617MB to 156MB with 40% improvement in average latency.
ANARCI tool validates generated antibody sequences for conformity to known antibody structural patterns.
CrystaLLM generates crystal structures from textual representations of crystallographic information files.
CIF file generation involves tokenizing crystallographic data and using autoregressive prediction for structure completion.
Monte Carlo Tree Search algorithm improves structural sampling quality for crystal structure generation.
Chemical structure validation requires domain-specific tools rather than standard text generation metrics.
Domain-specific models achieve effective results with smaller parameter counts than generalist language models.
Specialized chemistry models require subject matter expert validation for biological relevance and functional viability.
FAQ
What does Chapter 8 focus on?It demonstrates how small, domain-specific language models can generate biological and chemical structures and how to run them efficiently. Concretely, it covers generating protein sequences, creating crystal structures from CIF-like text, and practical inference optimizations tailored to chemistry and drug discovery workflows.How are Transformers adapted to chemistry tasks?Chemistry problems are reframed as sequence modeling. Molecules, reactions, and lab procedures are expressed as text (e.g., SMILES), enabling models to learn from open datasets. A notable example is the Molecular Transformer, which treats reaction prediction as machine translation of SMILES, achieving top-1 accuracy above 90% on common benchmarks without handcrafted rules.Why prefer small open-source models for drug discovery?Large closed models often underperform on specialized, proprietary chemistry tasks and are costly or infeasible to fine-tune. Small open-source models offer full control, can be trained or adapted on domain-specific data, and are released with permissive licenses and datasets, enabling production-grade performance at reasonable cost.What is ProtGPT2 and how is it trained?ProtGPT2 is a 738M-parameter, decoder-only GPT-2 model trained to predict the next token (amino acid/oligomer) on 87,162 raw protein sequences from UniRef50 (UR50_2021_04) without annotations. It learns natural protein features (amino acid propensities, secondary structure content, globularity) and explores novel regions of protein space for de novo design.How do I generate protein sequences with ProtGPT2 and how fast is it?You can load it from the Hugging Face Hub using a text-generation pipeline and sample multiple sequences with parameters like top_k, temperature, and repetition_penalty. On a Colab free tier CPU, generating a batch of 10 sequences typically completes in under 2 minutes, and you can seed generation with any starting amino acid, fragment, or protein prompt.How is the quality of ProtGPT2 outputs assessed?A simple, widely used proxy is perplexity: lower perplexity indicates the model finds a sequence more likely under its learned distribution. While helpful, perplexity should be complemented with domain checks when possible (e.g., downstream structure predictions or expert review) depending on the use case.What is AntibodyGPT (Antibody Generator) and what models exist?AntibodyGPT fine-tunes Salesforce’s ProGen2 (decoder-only) on 5,000 experimentally resolved antibody–antigen crystal structures to generate therapeutic antibody sequences. Three variants—small (151M), medium (765M), and large (2.7B)—are available on the Hugging Face Hub.How do I run AntibodyGPT efficiently?Use the custom ProGenForCausalLM AutoClass and tokenizer from the referenced GitHub repo to load checkpoints, then condition generation on a target antigen sequence. A GPU is recommended; on CPU, generation can take hours. Enabling PyTorch’s CUDA caching allocator expandable_segments and quantizing to 8-bit with BitsAndBytes can reduce average latency by roughly 40% versus the baseline.How do I validate generated antibody sequences?Use ANARCI (web tool or Python API) for antibody numbering and receptor classification. It checks conformity to known sequence patterns and structural frameworks, helping ensure outputs are biologically plausible and potentially functional; expert review remains essential.What is CrystaLLM and how do I generate and validate CIFs?CrystaLLM is a GPT-2–style, decoder-only model trained on textual CIF representations to generate physically plausible inorganic crystal structures. Workflow: clone the repo, download small (25M) or large (200M) weights, create a prompt (e.g., “data_Na2Cl2\n”), sample sequences to produce raw CIFs, post-process them, and validate with the provided script (checks include space-group and bond-length reasonableness). The small model runs on CPU; generating two CIFs with 3,000 max tokens typically takes under a minute. An optional MCTS-based decoding script improves structural sampling. You can also convert checkpoints to the Transformers format and push to the Hugging Face Hub.
pro $24.99 per month
access to all Manning books, MEAPs, liveVideos, liveProjects, and audiobooks!
 Domain-Specific Small Language Models ebook for free
Domain-Specific Small Language Models ebook for free