7 Generating Python Code
This chapter introduces practical ways to build and run domain-specific small language models for Python code generation. It contrasts closed, commercial assistants with open-source options and shows why specialized, compact models can rival much larger generalist systems on coding tasks. Benchmarks such as SWE-bench highlight that even strong models still require expert oversight, and the text argues that programmers remain central: coding assistants amplify skilled engineers rather than replace them. Specialization trims irrelevant knowledge, reduces cost and risk, and makes on-device deployment feasible.
A hands-on workflow starts with Salesforce’s CodeGen (350M mono) as a baseline, demonstrating prompts from function headers to natural language and comments. The chapter then optimizes inference by exporting to ONNX with Optimum and applying dynamic quantization, yielding sizable latency reductions, higher throughput, and more consistent runtimes; when a model isn’t supported, it shows a mid-level path using the Transformers ONNX exporter and ONNX Runtime quantization. For quality, it adopts a robust evaluation pipeline inspired by ReCode on HumanEval: tokenize and generate, validate syntax via Python’s AST, execute provided unit tests for correctness, and aggregate pass rates—while emphasizing safe execution practices.
Next, the chapter explores stronger and still-efficient models: CodeGen 2.5 (7B) with infill and FlashAttention for faster sampling, and BigCode’s StarCoder2 (3B) with Grouped Query Attention and long context windows. It demonstrates lightweight deployment through BitsAndBytes (8/4-bit) and GGUF formats, and shows how to run a 4-bit StarCoder2 locally on a MacBook Air (M1) using llama.cpp/llama-cpp-python, achieving usable, sub–half-second CPU-only latencies. It also covers serving via an OpenAI-compatible endpoint for IDE integration and converting HF checkpoints to GGUF when needed. The overarching message: with careful optimization, quantization, and disciplined evaluation, capable Python coding assistants can run efficiently on commodity hardware.
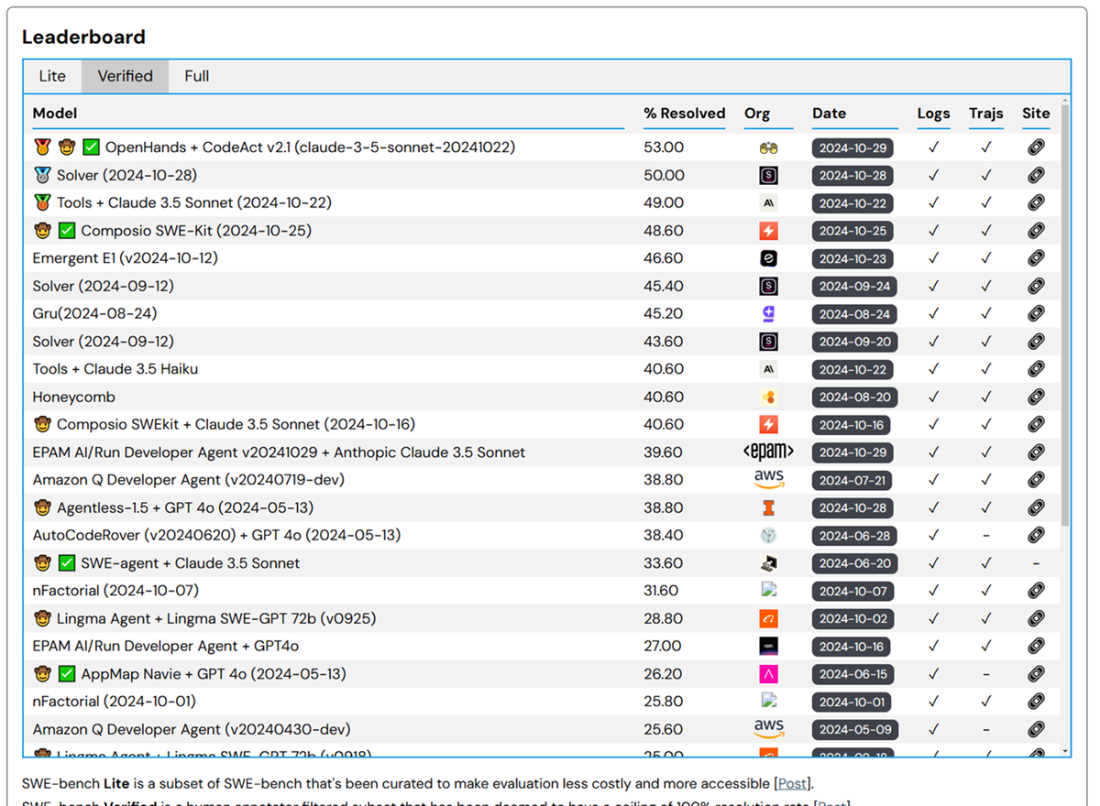
The SWE-bench leaderboard.
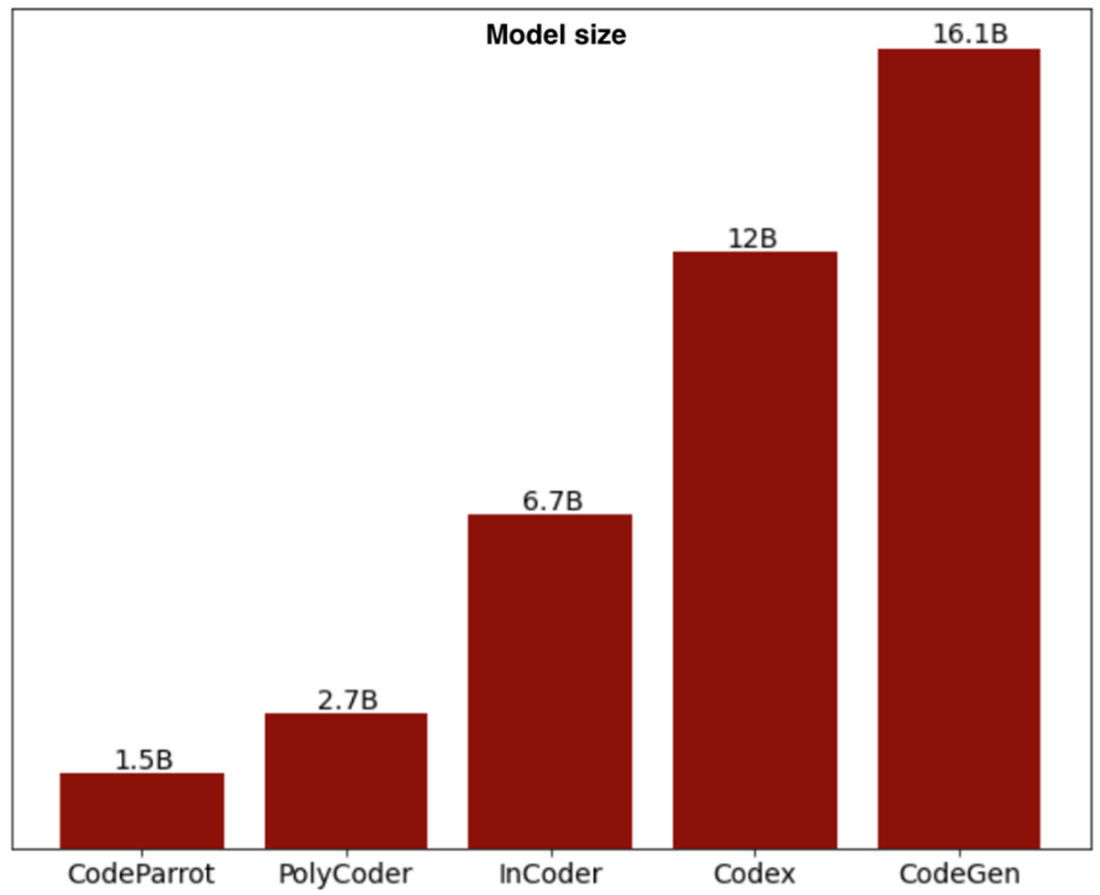
Comparison of the most popular code assistant LLMs’ size when CodeGen was released.
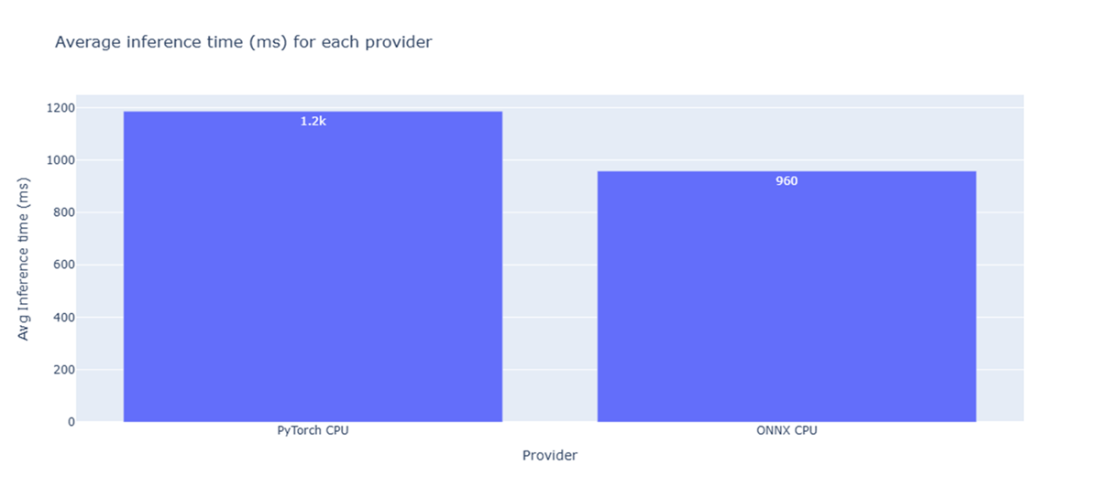
Average inference time on CPU for the vanilla CodeGen model and its ONNX converted version.
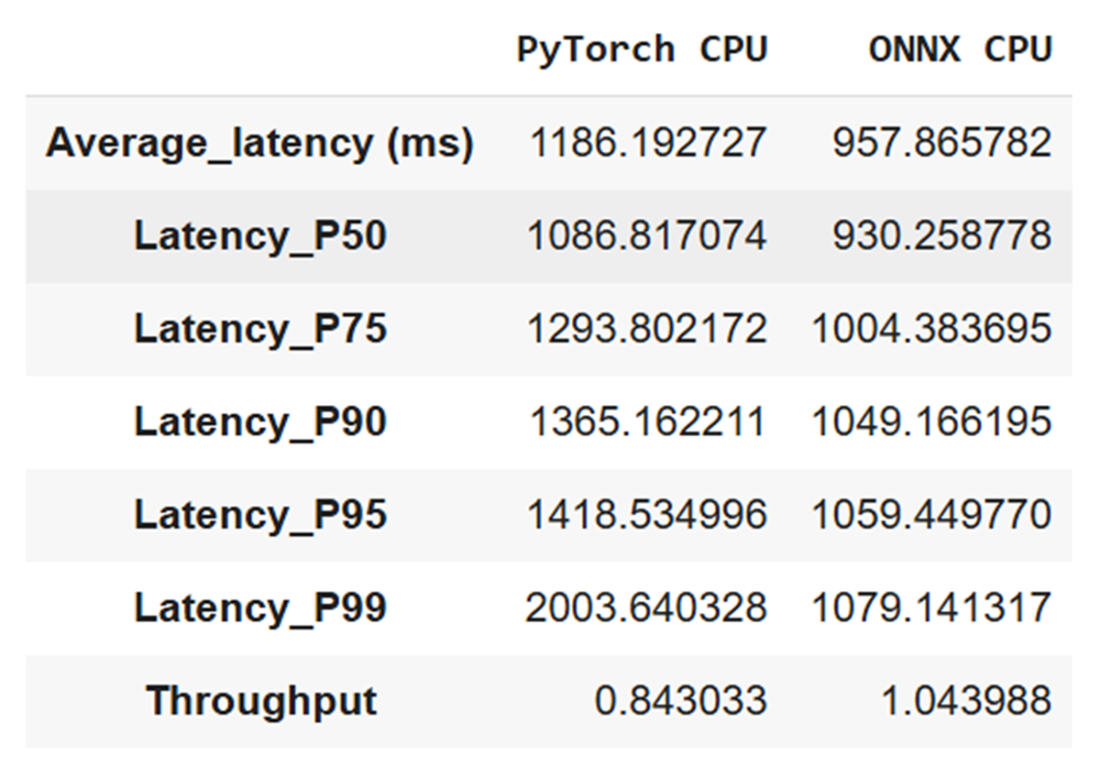
Comparison about latency and throughput metrics related to the CodeGen 350M mono vanilla model and its ONNX converted version benchmarks
Comparison between duration times for 100 inference runs with the CodeGen 350M mono vanilla model and its ONNX converted version
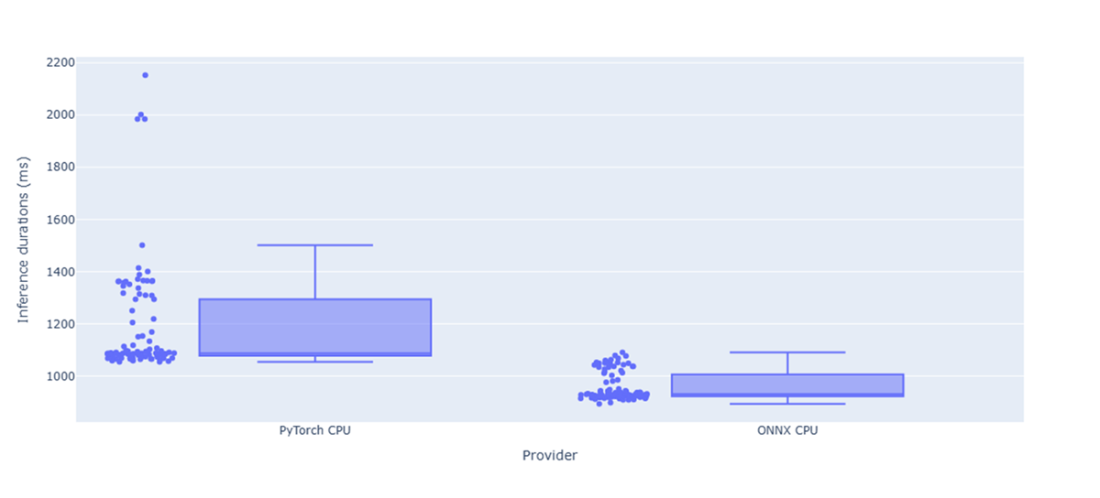
Average inference time on CPU for the ONNX CodeGen model and its quantized version.
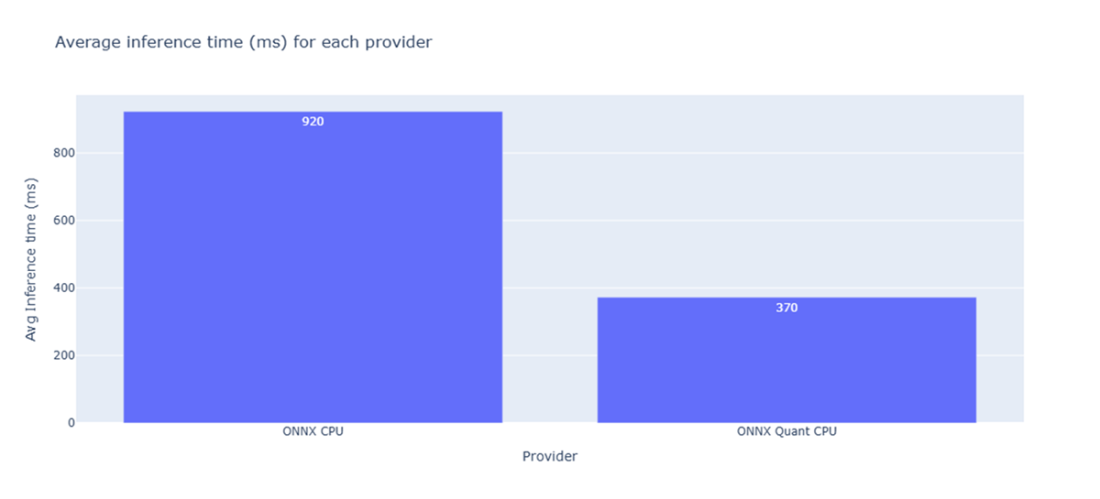
Comparison about latency and throughput metrics related to the CodeGen 350M mono ONNX model and its quantized version benchmarks.
Summary
- Specialized open source language models for code generation require smaller parameter counts than generalist models while achieving comparable performance.
- CodeGen models support multiple programming languages or Python-only code generation through the mono family.
- ONNX conversion of code generation models can reduce average inference time by approximately 19% compared to vanilla PyTorch implementations.
- 8-bit quantization of ONNX models can provide additional 60% reduction in inference time while maintaining code quality.
- Models not supported by Optimum require mid-level conversion using the transformers.onnx package with manual configuration.
- Abstract Syntax Tree parsing validates generated Python code for syntactic correctness before execution.
- HumanEval dataset provides 164 Python programming problems for evaluating code generation model performance.
- Code generation models support various prompt formats including function signatures, natural language comments, and multiline docstrings.
- StarCoder2 uses Grouped Query Attention to achieve faster inference times with reduced computational overhead.
- llama-cpp-python provides Python bindings for running GGUF models locally without GPU requirements.
- Code infilling requires specific token formatting with mask and separator tokens for proper context understanding.
- 4-bit quantization reduces model size by approximately 75% while maintaining acceptable code generation quality.
- Local deployment of code generation models enables offline coding assistance without external API dependencies.
- Metal Performance Shaders backend enables optimized inference on Apple Silicon processors.
- Code generation evaluation requires both syntactic validation and functional correctness testing against unit tests.
- ReCode evaluation framework provides robustness metrics for code generation under different prompt perturbations.
FAQ
What kinds of models does the chapter focus on, and why is Python the target language?
The chapter focuses on open-source, domain-specific language models specialized for coding assistance and code generation. It targets Python because most readers are familiar with it, which makes evaluating model output easier and more meaningful.Will coding LLMs replace software engineers?
No. Benchmarks like SWE-bench show that even leading models still need expert supervision. Many software engineering tasks—requirements understanding, design, coordination across files and systems, and iterative polishing—are human-centric and go beyond token prediction. LLMs can make good engineers more productive but do not replace core engineering expertise.What is CodeGen, and which versions and sizes are available?
CodeGen is Salesforce’s Transformer-based code generation family with two training families: “mono” (Python-only) and “multi” (several languages). First-generation model sizes include 350M, 2.7B, 6.1B, and 16.1B parameters. Later releases include CodeGen 2.0 and CodeGen 2.5 (7B, mono and multi). CodeGen can complete functions from headers, respond to natural-language prompts (larger models), generate unit tests, and more.How do I speed up CodeGen inference using ONNX and Optimum?
- Export to ONNX with Optimum’s ORTModelForCausalLM and run on CPU or other providers.- Apply dynamic quantization with Optimum’s ORTQuantizer.
- Observed benefits in the chapter’s CPU setup: average latency dropped from ~1186 ms (PyTorch) to ~958 ms (ONNX), and further improved with 8-bit quantization (about 60% average latency reduction vs. ONNX fp32). Model size also shrank from ~1.33 GB to ~346 MB after 8-bit quantization.
What if my model architecture isn’t supported by Optimum?
Use a mid-level route: export to ONNX with the Transformers ONNX CLI (feature “causal-lm”), then quantize with onnxruntime’s quantize_dynamic (e.g., QInt8). This path was useful before Optimum added support for some architectures (like early CodeGen generations).How can I evaluate the quality of generated Python code?
- Use HumanEval (164 Python tasks with prompts and tests).- Generate code with a consistent config (e.g., max length, caching).
- Validate syntax by parsing to an AST (ast.parse); discard invalid code.
- Run the provided unit tests to check correctness (with caution: executing arbitrary code has risks).
- The chapter draws on Amazon Science’s ReCode approach to assess robustness under prompt perturbations.
What’s new in CodeGen 2.5 compared to earlier releases?
CodeGen 2.5 (7B) supports robust code infilling (looks at both left and right context) and is optimized for fast sampling via Flash Attention, improving efficiency for training and inference. Mono and multi variants use a permissive Apache 2.0 license; the “instruct” variant is research-only, not for commercial use.Why consider StarCoder2-3B, and what are its strengths?
StarCoder2-3B is a compact, high-performing coding SLM trained on The Stack v2 and curated text, with Grouped Query Attention for faster inference, a 16k-token context window (with a 4k sliding window), and strong multi-language support including Python. It can be used via Transformers and quantized with bitsandbytes to 8-bit or 4-bit to reduce memory and improve speed.How can I run a Python code LLM on a laptop with limited resources?
- Use a GGUF-quantized model (e.g., StarCoder2-3B Q4_K_M) and llama.cpp via the llama-cpp-python bindings.- Download the GGUF from Hugging Face, load it with a small CPU thread count, and generate locally (even offline after the first download).
- On a MacBook Air M1 (8 GB), the chapter reports ~432 ms average latency and ~2.31 TPS using 4 threads and CPU-only.
 Domain-Specific Small Language Models ebook for free
Domain-Specific Small Language Models ebook for free