2 Tuning for a Specific Domain
This chapter provides a practical roadmap for adapting open-source foundation models to a specific domain. It begins by framing the core options for specialization—full fine-tuning, parameter-efficient techniques, and retrieval augmented generation—and emphasizes the importance of disciplined data preparation regardless of approach. The material is hands-on, showing how to structure datasets, tokenize consistently, manage sequence lengths, and set up training and evaluation pipelines, while also introducing retrieval workflows that pair external knowledge with pretrained models.
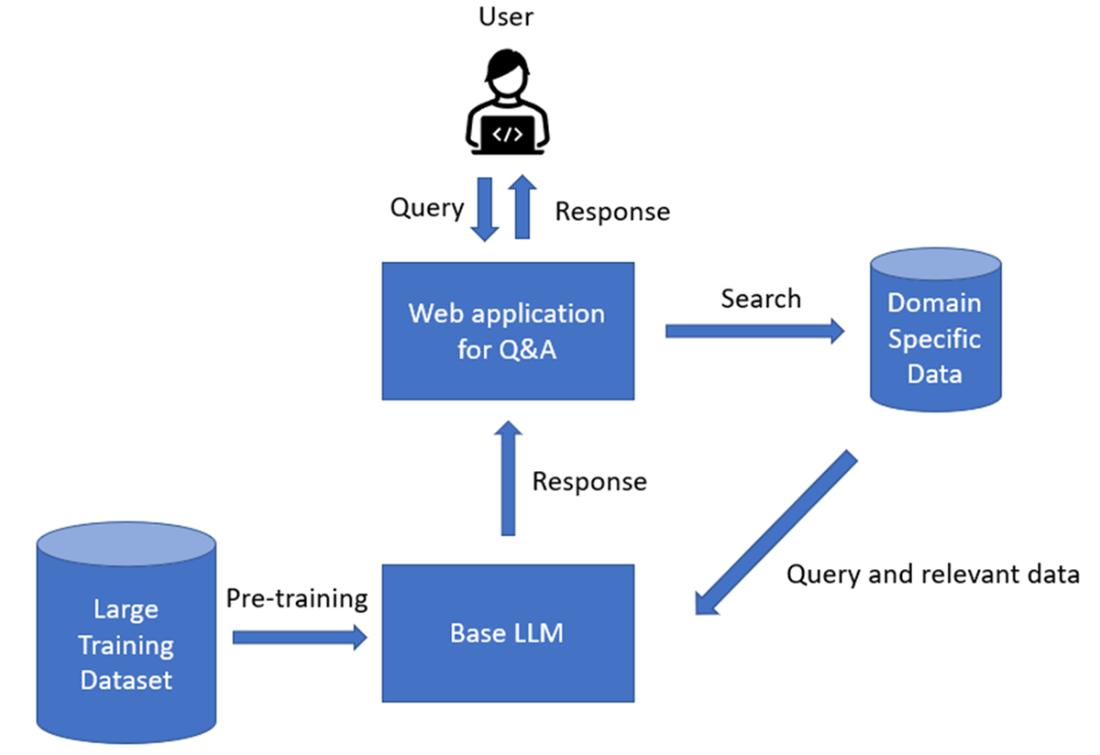
Concrete data-preparation examples span both encoder-only and decoder-only models. For a BERT-based classifier, the chapter walks through labeling, tokenization with special tokens, consistent padding and truncation, label encoding, train/validation splits, dataset classes, and data loaders, culminating in loading a sequence-classification head. For GPT-style completion, it mirrors the same flow—pairing context and target, tokenizing, padding to a uniform length, and batching—before loading a causal language model. When fine-tuning is not ideal, the chapter shows how to prepare for RAG by embedding a knowledge base, indexing it in a vector store, and retrieving semantically similar content efficiently (illustrated end to end with sentence embeddings and nearest-neighbor search), highlighting scalability to production workloads.
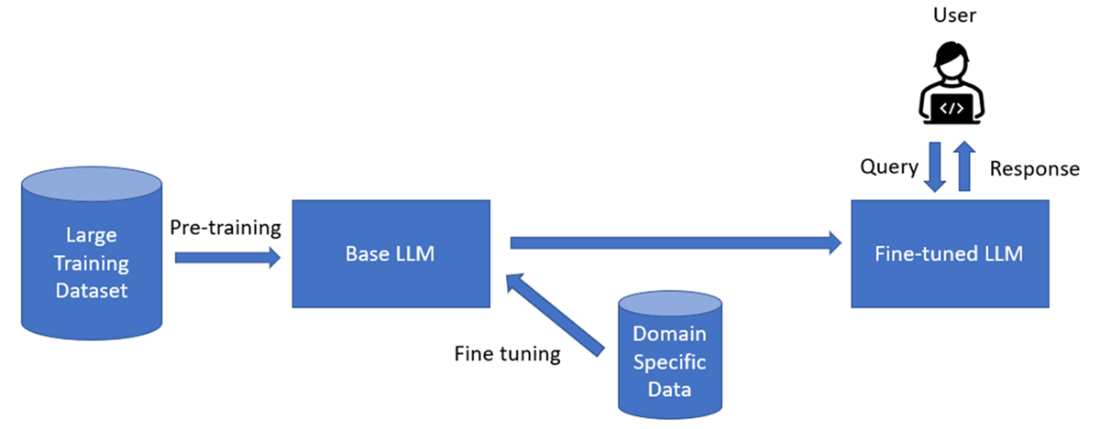
The fine-tuning section demonstrates full task adaptation with a DistilBERT question-answering example: selecting a dataset with question, context, and answer spans; preprocessing to map character offsets to token positions; configuring tokenization and batching; and training with standard trainer utilities before running inference. The chapter then introduces parameter-efficient fine-tuning via LoRA using a small FLAN-T5 model quantized for efficiency, configuring low-rank adapters, training only a tiny fraction of parameters, and loading adapters for inference. It closes with guidance on choosing between RAG and fine-tuning: RAG excels for up-to-date, source-grounded answers with lower training cost but added infrastructure considerations, while fine-tuning (and PEFT) delivers superior task performance and domain nuance for complex patterns at higher engineering cost. The key takeaway is to match the strategy to the use case—there is no one-size-fits-all solution.
The typical RAG workflow.
The typical fine tuning workflow.
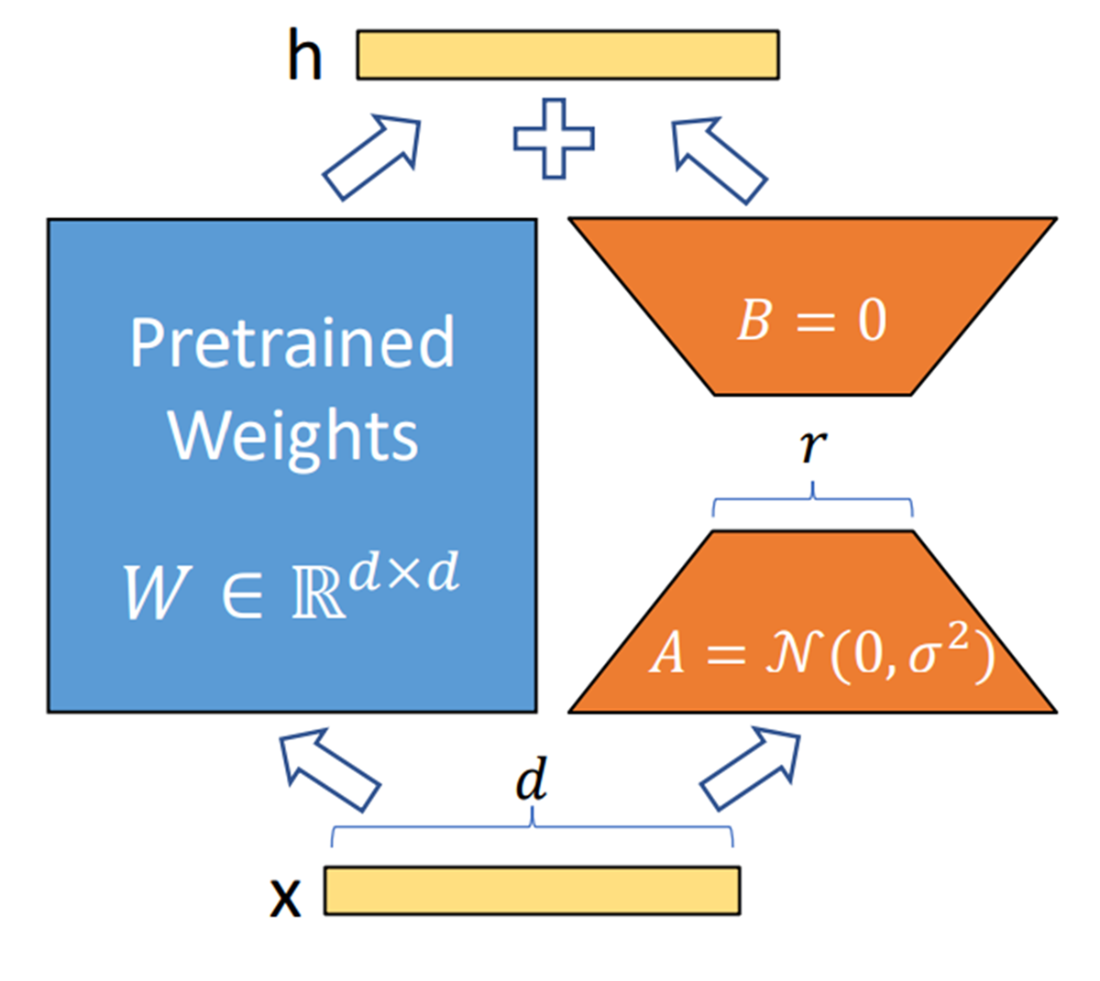
The LoRA fine tuning process
Summary
- BERT models require tokenization with special tokens CLS and SEP to mark sequence boundaries for classification tasks.
- GPT models use context-target pairs where the model learns to generate the target text given the context input.
- Tokenizers convert text into numerical representations that models can process during training and inference.
- FAISS creates vector indexes for efficient similarity search across large datasets of text embeddings.
- RAG combines information retrieval with text generation to provide models with external knowledge sources.
- RAG retrieves relevant information from vector databases before generating responses to improve accuracy.
- Fine tuning adjusts all parameters of a pre-trained model using task-specific labeled datasets.
- LoRA fine tunes only a small subset of model parameters while keeping the original weights frozen.
- PEFT techniques like LoRA reduce computational costs compared to full fine tuning while maintaining performance.
- RAG works better for up-to-date information and reduces hallucinations through source traceability.
- Fine tuning produces better results for complex domain-specific tasks requiring specialized knowledge.
- Vector databases store embeddings and enable fast similarity search for RAG implementations.
FAQ
How do I prepare data for fine-tuning BERT on a classification task?
- Gather a labeled dataset as (text, label) pairs.
- Load the model-specific tokenizer (bert-base-uncased).
- Insert special tokens ([CLS] at start, [SEP] as separator) as required by BERT and tokenize with padding/truncation and a max_length.
- Produce tensors for input_ids and attention_mask; encode labels (e.g., with a label encoder).
- Split into train/validation (e.g., scikit-learn train_test_split).
- Build a CustomDataset returning input_ids, attention_mask, labels; wrap with DataLoader.
- Load BertForSequenceClassification with num_labels set to your label set size, then train.
Why are special tokens, padding, and truncation important in data preparation?
- Special tokens help the model understand sequence structure: [CLS] marks the start, [SEP] separates/ends segments (especially needed by encoder-only models like BERT).
- Padding ensures all sequences have the same length in a batch, enabling efficient tensor operations.
- Truncation keeps inputs within the model’s maximum context window, controlling memory/latency.
- Tokenization choices directly affect vocabulary handling, OOV behavior, and computational cost.
How do I split data and create PyTorch DataLoaders for fine-tuning?
- Use train_test_split to create training and validation sets for inputs, masks, and labels.
- Implement a torch.utils.data.Dataset that returns a dict with input_ids, attention_mask, and labels.
- Wrap datasets with DataLoader; set batch_size and shuffle (True for training, False for validation).
- Feed these loaders into your training loop or a Hugging Face Trainer.
What changes when preparing data for GPT-2 text completion versus BERT classification?
- Task format: GPT-2 learns to predict a target completion given a context; pair each (context, target).
- Concatenation: Join context and target with clear separators/special tokens consistent with the tokenizer.
- Tokenization: Use GPT2Tokenizer; encode the combined sequence and pad to a uniform length.
- Dataset items: Typically only input_ids (causal language modeling infers labels by shifting).
- Model: Load GPT2LMHeadModel rather than a sequence classification head.
What is Retrieval Augmented Generation (RAG) and what are its phases?
- RAG augments an LLM’s prompt with retrieved, relevant external context to improve accuracy and freshness.
- Two phases:
1) Retrieval: Fetch relevant chunks/embeddings from private/public sources (often via a vector DB).
2) Generation: Provide the retrieved context to the LLM to generate answers, often with source attribution.
How do I build a simple similarity search pipeline with FAISS?
- Prepare a small corpus with labels (e.g., texts about superheroes).
- Encode texts into embeddings using sentence-transformers (e.g., paraphrase-mpnet-base-v2).
- Create an IndexFlatL2 in FAISS; L2-normalize and add vectors to the index.
- Encode the query text, normalize it, then call index.search with k neighbors.
- Join results (distances and indices) with the original data to inspect nearest matches.
- FAISS scales to million-to-billion vector collections and supports GPU via CUDA.
How does full fine-tuning differ from PEFT, and what does LoRA change?
- Full fine-tuning updates all model weights on a task-specific dataset; it’s accurate but compute/data heavy.
- PEFT updates a small subset of parameters, retaining most base weights frozen; it’s faster and cheaper.
- LoRA (Low-Rank Adaptation) injects low-rank adapters (e.g., into attention q/v layers), keeping base weights frozen and training only adapter params—often under 1% of total—while preserving quality.
What are the key steps to fine-tune DistilBERT for question answering?
- Load a QA dataset containing question, context, and answer spans.
- Tokenize questions and contexts with truncation (only_second for long contexts) and return offset mappings.
- Map character-level answer spans to token start/end positions using offsets; handle cases where the answer falls outside the truncated window.
- Remove unused columns and create tokenized train/test datasets.
- Load AutoModelForQuestionAnswering, set up a DefaultDataCollator, and define TrainingArguments.
- Instantiate Trainer and call train().
- For inference, compute start/end argmax over logits and decode the span.
What LoRA configuration and training flow does the chapter demonstrate?
- Model: FLAN-T5-small loaded in 8-bit for efficiency.
- Data: samsum (dialogue → summary). Preprocess with max lengths, tokenize inputs with “summarize: ” prefix, mask label padding with -100.
- LoRA config: r (rank), lora_alpha, lora_dropout, target_modules (e.g., “q”, “v”), task_type set to seq2seq.
- Prepare model for k-bit training; wrap with get_peft_model to add adapters.
- Use DataCollatorForSeq2Seq and Seq2SeqTrainer with modest epochs (e.g., 3).
- Save only adapter weights; at inference, load base model and attach PEFT adapters.
How should I choose between RAG and fine-tuning (including PEFT) for a domain-specific task?
- Prefer RAG when:
- You need up-to-date, traceable answers with source attribution.
- You have limited labeling budget and want to avoid training costs.
- The base model already performs reasonably; extra context can close the gap.
- Prefer fine-tuning/PEFT when:
- The task requires learning domain-specific patterns/jargon or complex reasoning.
- You need higher accuracy on in-domain generation beyond what context can provide.
- Consider costs: RAG requires vector DB and pipelines; FT needs compute and ML ops. Hallucinations: FT/PEFT mitigates domain-specific ones; RAG helps with general knowledge grounding. No one-size-fits-all—evaluate per use case.
 Domain-Specific Small Language Models ebook for free
Domain-Specific Small Language Models ebook for free