1 Why your AI projects need a platform
AI projects often begin as impressive prototypes, but they quickly become complex production systems once real users, traffic, costs, compliance needs, and reliability expectations appear. The chapter uses Sam’s customer-support chatbot to show how a simple model API integration can fail under production pressure: response times become unpredictable, scaling breaks, costs spiral, safety risks emerge, answers lack grounding in company knowledge, and teams have no systematic way to improve performance. The central message is that AI applications need platform thinking from the start because the model call is only a small part of the overall system.
The chapter explains that modern GenAI infrastructure is much larger than the visible model interaction. While traditional machine learning systems already required substantial supporting infrastructure, GenAI applications add even more needs: knowledge ingestion, vector search, session memory, tool use, safety checks, compliance, observability, experimentation, model routing, cost controls, and deployment automation. Without shared platform services, organizations fall into AI sprawl, where every team rebuilds its own version of session management, monitoring, token tracking, security, and evaluation. Even well-engineered local solutions become organizational technical debt when they are fragmented and inconsistent.
The proposed solution is a layered, service-oriented AI platform that provides reusable capabilities for production AI applications. Data and Session Services support context-aware intelligence; a Workflow Service coordinates multi-step processes; a Tool Service manages external integrations; a Guardrails Service enforces safety and compliance; Observability and Evaluation Services provide monitoring and systematic improvement; a Model Service abstracts providers; and an Infrastructure Layer with an API Gateway handles scaling, configuration, and operational concerns. By centralizing these foundations, teams can focus on business logic and user experience while inheriting reliable, secure, scalable infrastructure for building AI systems that work beyond the demo stage.
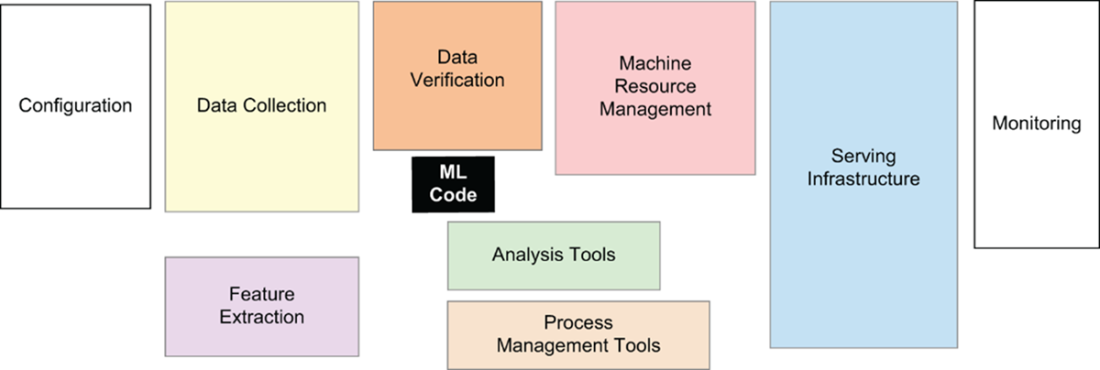
The Hidden Infrastructure Iceberg in Traditional ML Systems. While the actual machine learning code (dark center box) represents only 5-10% of system complexity, the surrounding infrastructure components—data collection, feature extraction, monitoring, and serving infrastructure—constitute 90-95% of the engineering effort. This foundational insight from the 2015 NeurIPS paper reveals why ML systems are so complex to put into production.
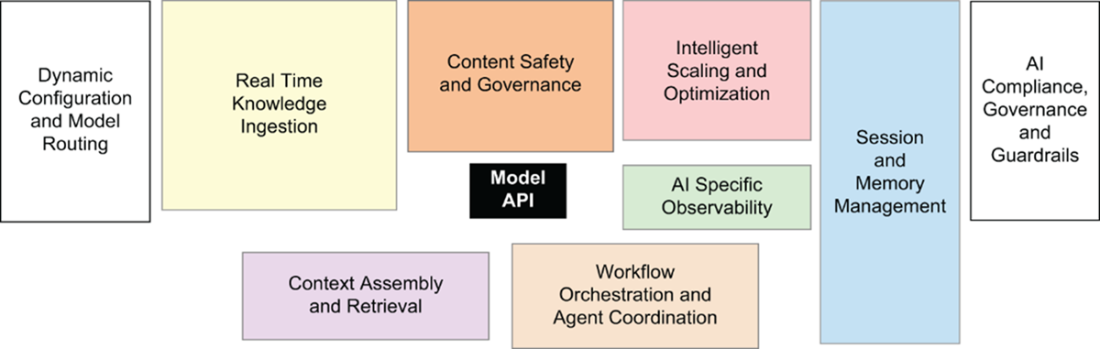
The GenAI Infrastructure Explosion. The model API call now represents just 2% of total system complexity—even less than in traditional ML. Modern GenAI applications require vastly expanded infrastructure: knowledge management systems, safety and compliance layers, session management for conversations, tool integration platforms, advanced observability, and multi-provider model orchestration. This architectural shift explains why simple prototypes become complex production systems.
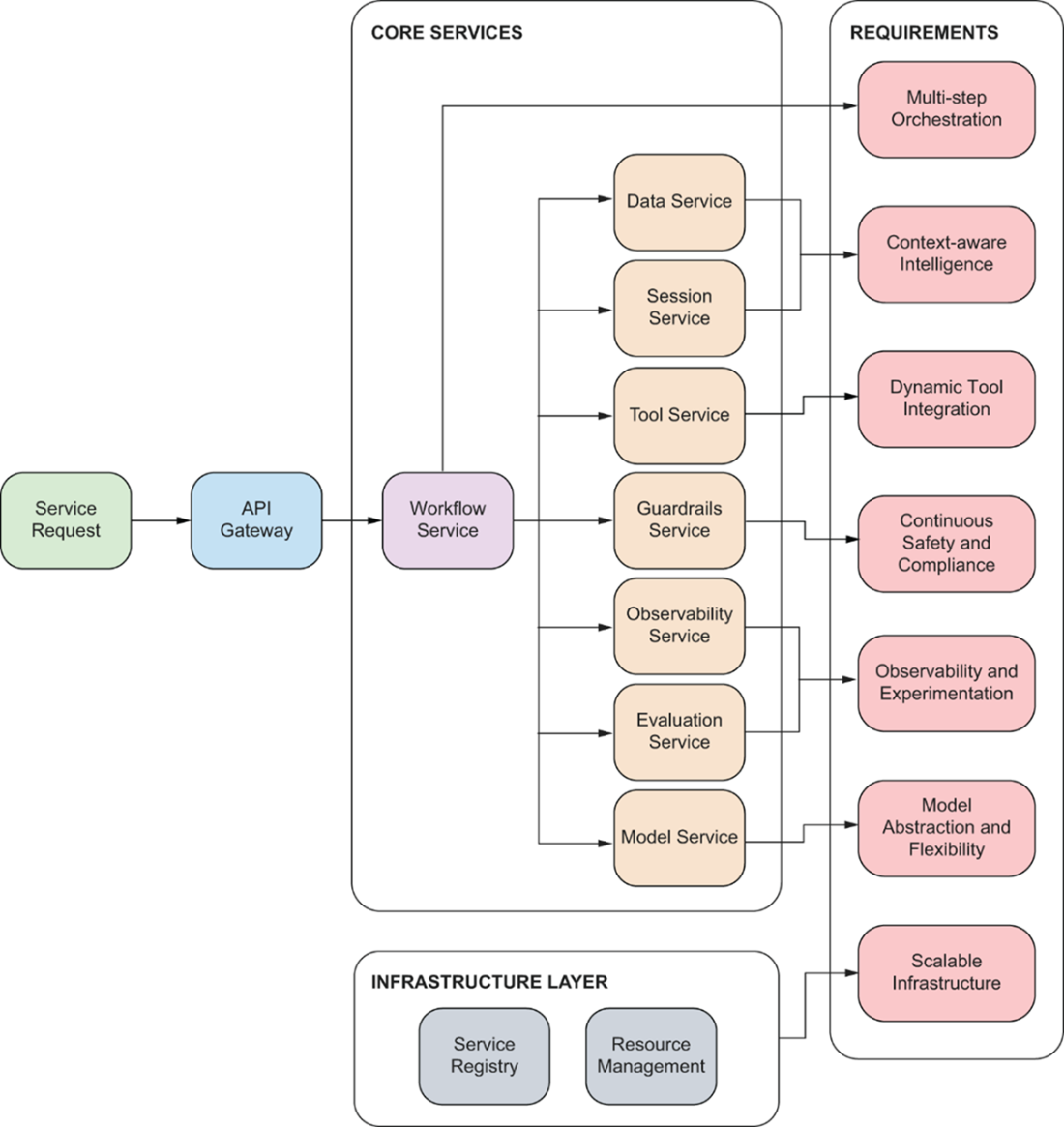
AI Platform Architecture: Our platform design directly addresses the core requirements through specialized services: the Data Service and Session Service provide context-aware intelligence; the Workflow Service enables multi-step orchestration; the Tool Service handles dynamic integrations; the Guardrails Service ensures safety and compliance; the Observability and Evaluation Services provide monitoring and experimentation; the Model Service abstracts provider differences; and the Infrastructure Layer with API Gateway provides scalable foundations. Each service operates independently while sharing common patterns, eliminating the need for teams to rebuild foundational components.
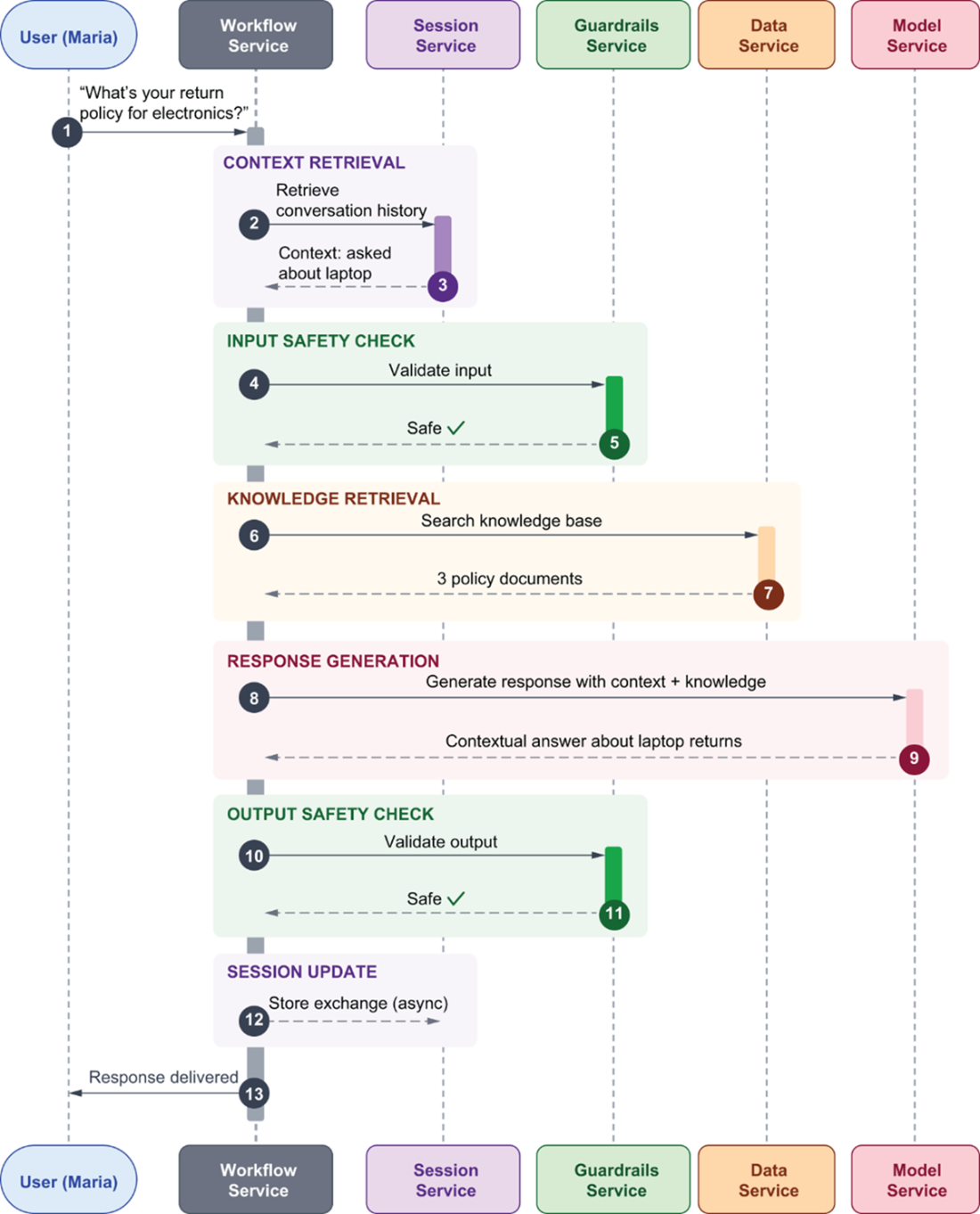
The conversational request flow shows how Maria's simple question flows through multiple platform services before returning a response. The Workflow Service orchestrates the entire interaction, coordinating calls to the Session Service to retrieve conversation history, the Guardrails Service to validate both input and output for safety, the Data Service to search organizational knowledge, and the Model Service to generate contextually appropriate responses. The Observability Service tracks costs and performance throughout this coordinated sequence, demonstrating how platform services transform simple interactions into production-ready AI applications.
Summary
- AI prototypes consistently fail in production because they lack the infrastructure that real-world usage demands.
- The model API call represents only 2% of total system complexity in modern GenAI applications.
- The remaining 98% consists of knowledge management systems, session management, safety and compliance layers, tool integration platforms, observability systems, model management, and infrastructure layers.
- AI sprawl emerges when teams build disconnected AI solutions independently, each implementing their own versions of session management, cost tracking, safety controls, and observability. This duplication makes each new AI feature exponentially harder to build as teams navigate a maze of incompatible one-off implementations.
- Context-aware intelligence requires two complementary capabilities that AI applications must provide. The Data Service handles document ingestion, vector embedding generation, and semantic search. The Session Service manages conversational state by tracking user interactions, preferences, and conversation history across multiple exchanges.
- Multi-step orchestration through the Workflow Service coordinates complex AI processes involving sequential and parallel operations where each step depends on previous ones and any step can fail.
- Model abstraction through the Model Service provides a unified interface that works seamlessly with any AI provider—GPT-4, Claude, local Llama models, or future providers—without requiring application code changes. The service handles provider-specific API differences, response formatting variations, error handling strategies, intelligent routing based on task requirements, automatic fallback, and cost optimization.
- Dynamic tool integration via the Tool Service provides registration and discovery mechanisms for external APIs and services, handling authentication patterns, rate limiting, error recovery, and result caching automatically.
- Safety and compliance enforcement through the Guardrails Service ensures every input and output passes through configurable safety filters automatically rather than relying solely on model behavior that users can manipulate, preventing scenarios where AI assistants provide unauthorized advice or expose sensitive data regardless of prompt engineering attempts.
- The Observability Service handles operational monitoring by tracking costs per request, measuring performance across services, implementing distributed tracing that follows requests through multiple components, and collecting system metrics that identify bottlenecks before they impact users.
- The Evaluation Service focuses on AI-specific assessment through systematic experiments, A/B testing infrastructure, prompt versioning, and quality measurement that enables data-driven optimization rather than guesswork.
- Scalable infrastructure foundations provided by the Infrastructure Layer and API Gateway handle configuration management for secrets and environment settings, service discovery so components can find each other, resource allocation that scales individual services based on load, and deployment automation that enables reliable updates without downtime.
- Service-oriented architecture enables independent scaling where high-demand features don't impact other applications, clear boundaries where teams can work on different services without coordination, and shared infrastructure patterns that prevent duplication.
- Each service operates independently with well-defined API contracts, allowing the Model Service to scale separately from the Session Service, the Data Service to use different storage technology than the Workflow Service, and teams to deploy updates to individual services without affecting the entire platform.
 Designing AI Systems ebook for free
Designing AI Systems ebook for free