3 Introduction to TensorFlow, PyTorch, JAX, and Keras
This chapter equips you to start doing deep learning in practice by unifying core concepts across the major frameworks—TensorFlow, PyTorch, and JAX—while positioning Keras as a high-level, backend-agnostic API that streamlines model building and training. It clarifies the shared foundations that power modern deep learning—automatic differentiation, hardware-accelerated tensor computation, and distributed execution—and shows how these ideas surface as layers, models, losses, optimizers, metrics, and training loops. The end goal is a practical, framework-spanning understanding that lets you prototype quickly, scale efficiently, and move on to real-world applications.
After a brief history from Theano’s pioneering autodiff to Keras (2015), TensorFlow (2015), PyTorch (2016), and JAX (2018), the chapter frames today’s multiframework reality. TensorFlow emphasizes speed and production tooling, with graph mode and XLA compilation plus a broad ecosystem, at the cost of API sprawl. PyTorch offers intuitive, eager-first workflows and strong model availability, though it’s generally slower and occasionally inconsistent. JAX adopts a stateless, NumPy-consistent approach with explicit PRNG keys and XLA-first compilation, delivering top-tier performance and TPU affinity, while asking more from the developer in debugging and metaprogramming. Keras abstracts these differences by plugging into any of the three as a backend, providing future-proof portability.
Practically, the chapter walks through the essentials in each framework: creating tensors (and Variables/Parameters), expressing math, computing gradients (GradientTape in TensorFlow, backward in PyTorch, grad/value_and_grad in JAX), and speeding execution via compilation (@tf.function, torch.compile, @jax.jit). It culminates in an end-to-end linear classifier implemented three times, then transitions to Keras: defining layers with automatic shape inference, composing models (Sequential or more flexible graphs), and configuring training via compile (loss, optimizer, metrics) and fit, with proper validation, evaluation, and inference using predict. Together, these patterns form a solid foundation for the applied deep learning workflows that follow.
Our synthetic data: two classes of random points in the 2D plane
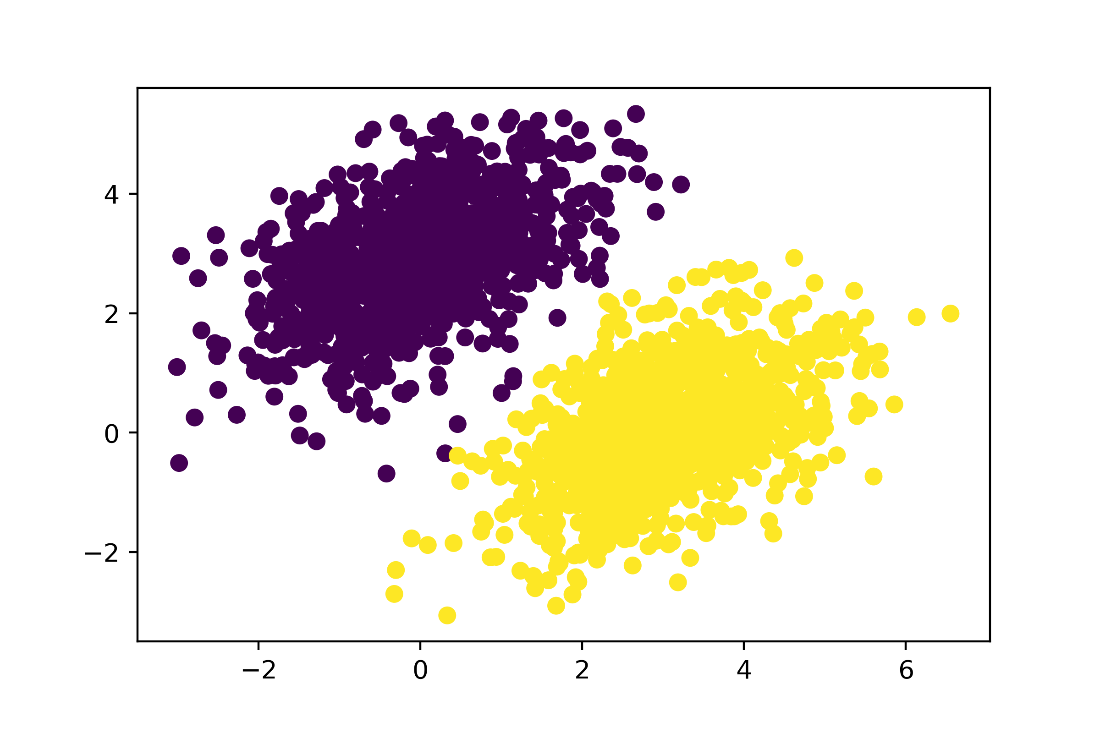
Our model’s predictions on the training inputs: pretty similar to the training targets
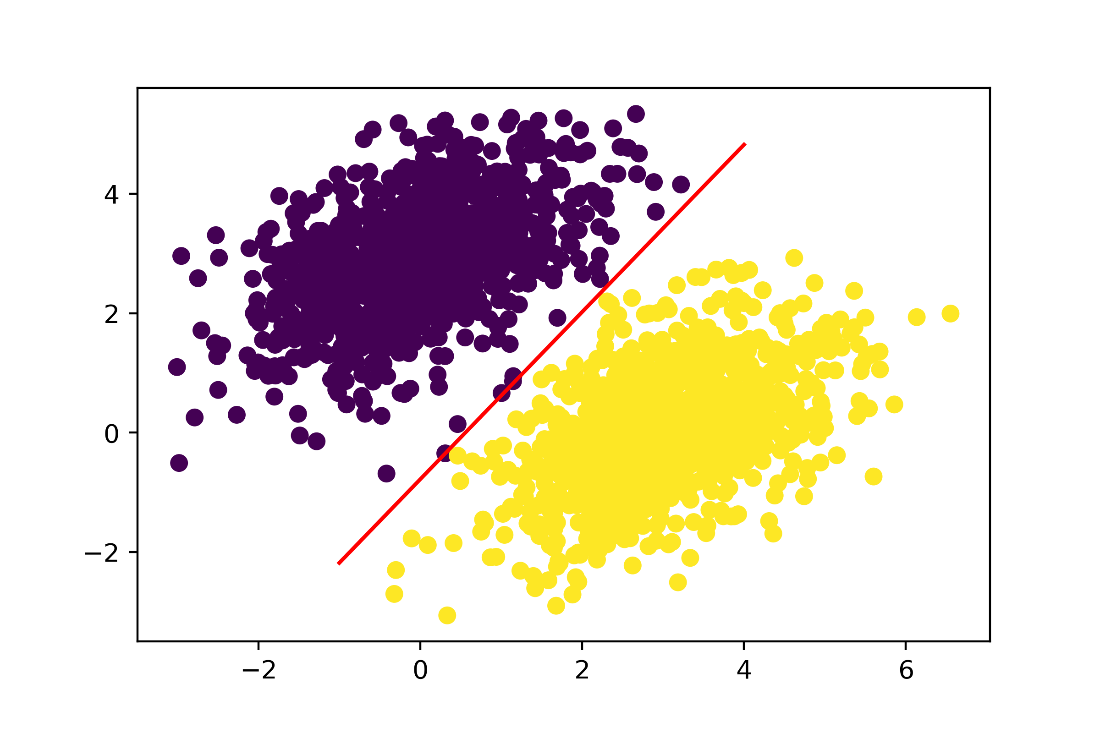
Our model, visualized as a line
Keras and its backends: a backend is a low-level tensor computing platform, Keras is a high-level deep learning API

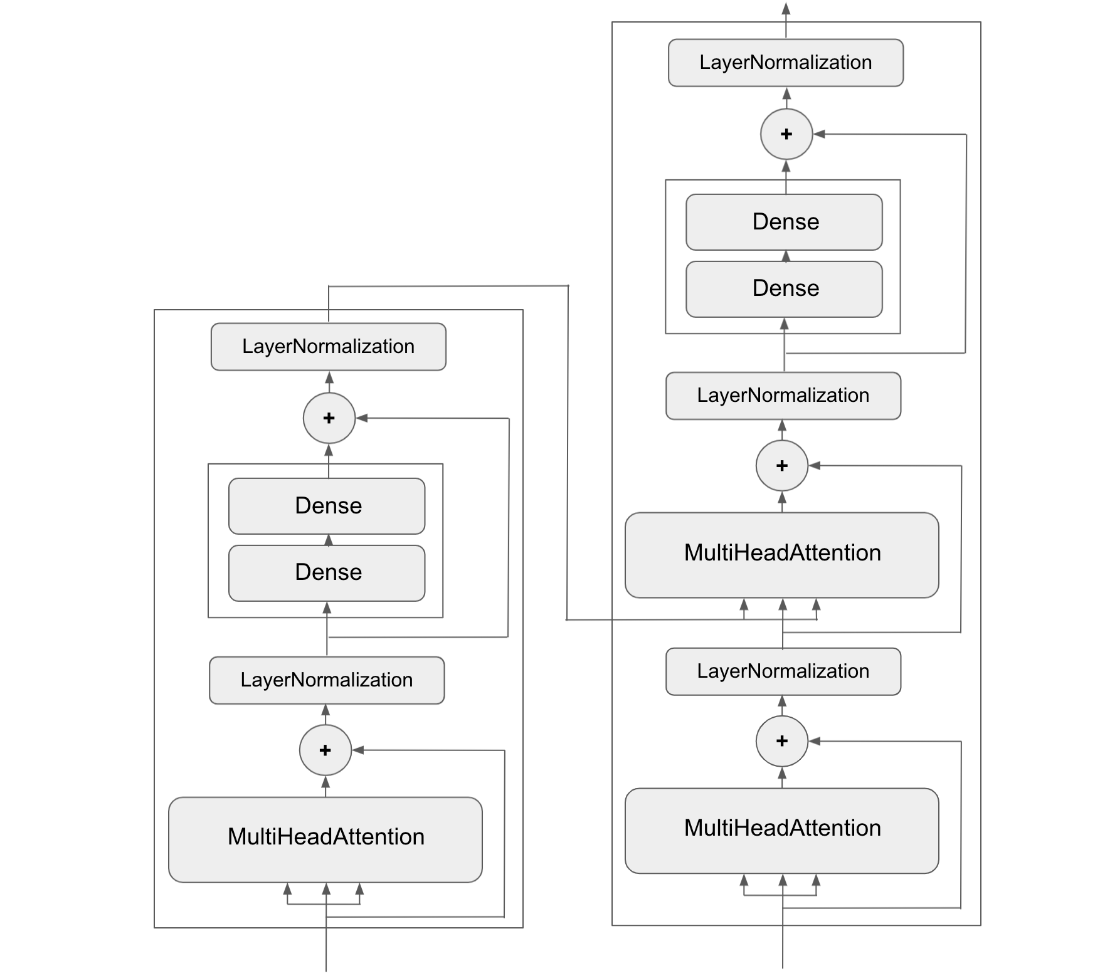
The Transformer architecture. There’s a lot going on here. Throughout the next few chapters, you’ll climb your way up to understanding it (in Chapter 15).
Chapter summary
- TensorFlow, PyTorch, and JAX are three popular low-level frameworks for numerical computation and autodifferentiation. They all have their own way of doing things, their own strengths and weaknesses.
- Keras is a high-level API for building and training neural networks. It can be used with either TensorFlow, PyTorch, or JAX – just pick the backend you like best.
- The central class of Keras is the
Layer. A layer encapsulates some weights and some computation. Layers are assembled into models. - Before you start training a model, you need to pick an optimizer, a loss, and some metrics, which you specify via the
model.compile()method. - To train a model, you can use the
fit()method, which runs mini-batch gradient descent for you. You can also use it to monitor your loss and metrics on “validation data”, a set of inputs that the model doesn’t see during training. - Once your model is trained, use the
model.predict()method to generate predictions on new inputs.
FAQ
How do TensorFlow, PyTorch, JAX, and Keras relate to each other?
Keras is a high-level API for building and training models. It runs on a low-level backend engine: TensorFlow, PyTorch, or JAX. The backends provide tensors, autodiff, device execution, and distribution; Keras provides layers, models, losses, optimizers, metrics, and training loops.What core capabilities do modern deep learning frameworks share?
They all provide: (1) automatic differentiation, (2) tensor computation on CPU/GPU/TPU or other accelerators, and (3) distributed execution across devices and machines.What makes TensorFlow unique, and how do I use its basic APIs?
Tensors are immutable; mutable state lives intf.Variable. Use tf.GradientTape() to compute gradients, and speed up code with @tf.function and optionally jit_compile=True (XLA). TensorFlow is fast, feature-complete (tf.data, ragged/string tensors), and has strong production tooling.How are gradients computed and applied in PyTorch?
Create tensors withrequires_grad=True, run the forward pass, then call loss.backward(). Read gradients from .grad, update parameters (e.g., via an optimizer’s step()), and reset grads with model.zero_grad(). Package state and forward logic in torch.nn.Module; trainable variables are torch.nn.Parameter. torch.compile() can speed up some models.What’s special about JAX and how do I work with it?
JAX is functional and stateless. It uses a NumPy-compatible API (jax.numpy/jnp). Randomness uses PRNG keys (jax.random.key and split). Arrays aren’t updated in place; use x.at[i].set(...). Get gradients with jax.grad or jax.value_and_grad, and compile with @jax.jit.When should I pick TensorFlow vs. PyTorch vs. JAX?
- TensorFlow: strong performance (graph/XLA), very feature-complete, best production/mobile/browser story.- PyTorch: simple eager-first workflow and great Hugging Face model availability; typically slower.
- JAX: usually fastest and clean NumPy API; best on TPUs; debugging can be trickier due to JIT/metaprogramming.
How do I choose and switch the Keras backend?
Default is TensorFlow. Switch by settingKERAS_BACKEND (e.g., os.environ["KERAS_BACKEND"] = "jax") before import keras, or by editing ~/.keras/keras.json ("backend": "tensorflow" | "torch" | "jax"). Use "torch" for PyTorch.How do Keras layers work under the hood?
Subclasskeras.Layer, create weights in build(input_shape), and define the forward pass in call(inputs). Keras infers shapes automatically on first call and manages eager/graph execution details for you.How do I configure and run training with Keras?
Define your model, then callcompile(optimizer, loss, metrics) and fit(x, y, epochs, batch_size). Use evaluate() to get loss/metrics on a dataset and predict() to generate outputs in batches.Why and how should I use validation data?
Validation monitors generalization and overfitting. Keep it separate from training data. Pass it tofit(..., validation_data=(x_val, y_val)) to track validation loss/metrics per epoch, or call evaluate() after training. Deep Learning with Python, Third Edition ebook for free
Deep Learning with Python, Third Edition ebook for free