15 Language models and the Transformer
This chapter moves from basic text preprocessing to models that generate and transform language. It begins with the language modeling paradigm—predicting the next token given prior tokens—and shows how an autoregressive loop turns next-token predictions into open-ended text. Building on this, it frames machine translation as sequence-to-sequence learning with an encoder-decoder design and a decoding loop that feeds previously generated tokens back into the model. Along the way, it highlights the limitations of RNN-based approaches for long-range dependencies and fixed-size state bottlenecks, motivating a shift toward attention-based architectures.
The core of the chapter is the Transformer, which replaces recurrence with attention. It introduces dot-product attention with the query–key–value formulation, softmax weighting, scaling, and multi-head parallelism to capture diverse relationships. Self-attention enables tokens to contextualize one another; residual connections, layer normalization, and two-layer feed-forward blocks provide depth and nonlinearity. A practical caveat is that attention is order-agnostic, so positional embeddings are added to token embeddings to encode sequence order. Implemented as stacked encoder and decoder blocks—with causal masking in the decoder and cross-attention to the encoder—the Transformer achieves better translation quality than a GRU baseline while training faster on accelerators due to parallelism.
The chapter then demonstrates the modern workflow of leveraging large pretrained Transformers (e.g., BERT/RoBERTa) trained with masked language modeling and subword tokenization, and fine-tuning them for downstream tasks such as IMDb sentiment classification, achieving higher accuracy with minimal task-specific training. It closes by explaining why Transformers work so well: attention iteratively shapes semantically continuous and interpolative embedding spaces, echoing word2vec’s principles but at far greater scale and expressivity—storing not just facts but “vector programs” that can be recombined at inference time. This power comes with trade-offs (data hunger, potential hallucinations), and the field continues to evolve with improvements to attention, normalization, and positional encoding, as well as alternatives for very long sequences.
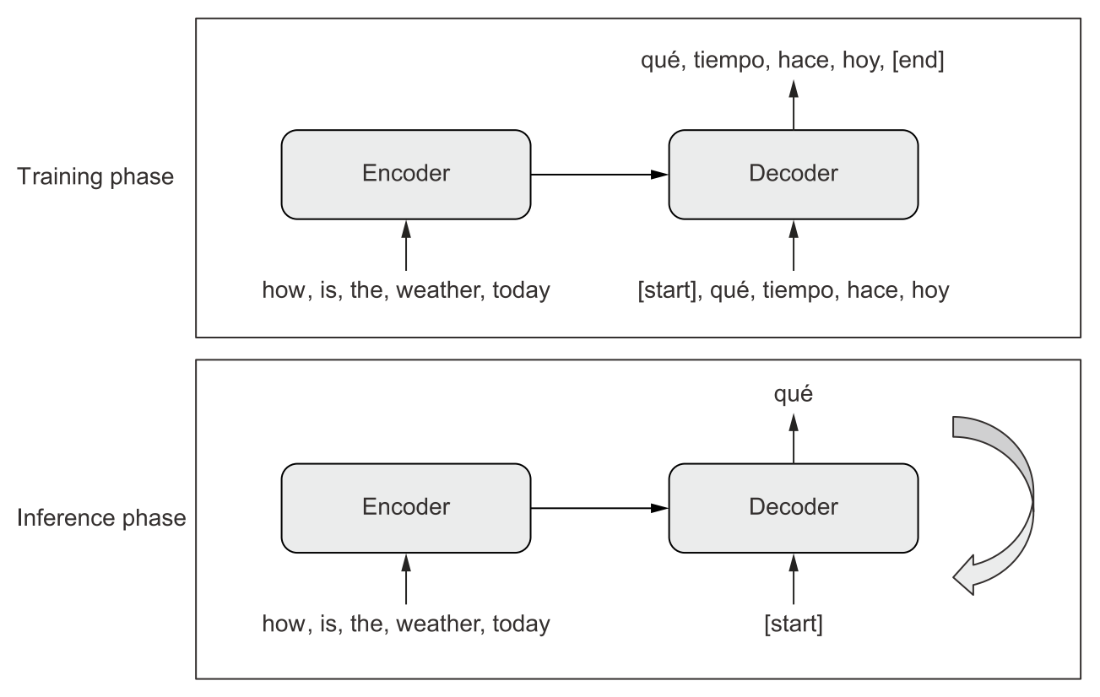
Sequence-to-sequence learning: the source sequence is processed by the encoder and is then sent to the decoder. The decoder looks at the target sequence so far and predicts the target sequence offset by one step in the future. During inference, we generate one target token at a time and feed it back into the decoder.
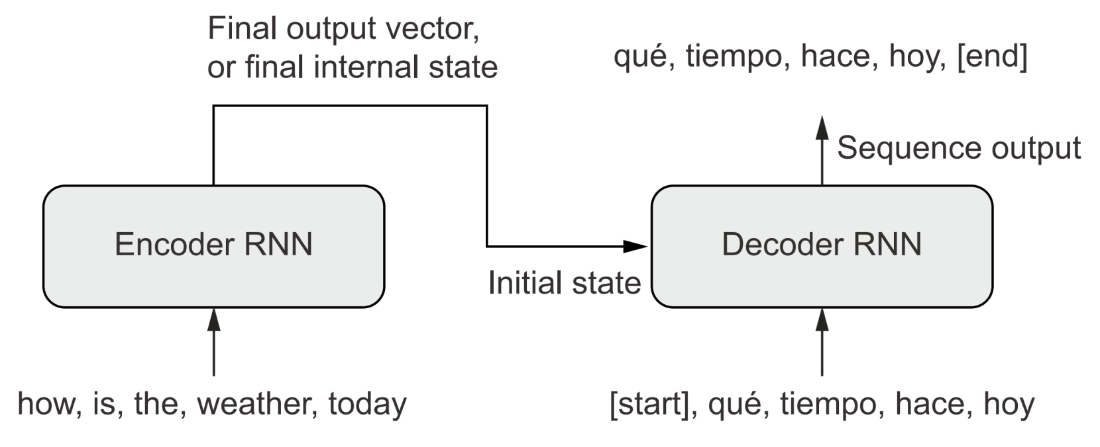
A sequence-tosequence RNN: an RNN encoder is used to produce a vector that encodes the entire source sequence, which is used as the initial state for an RNN decoder.
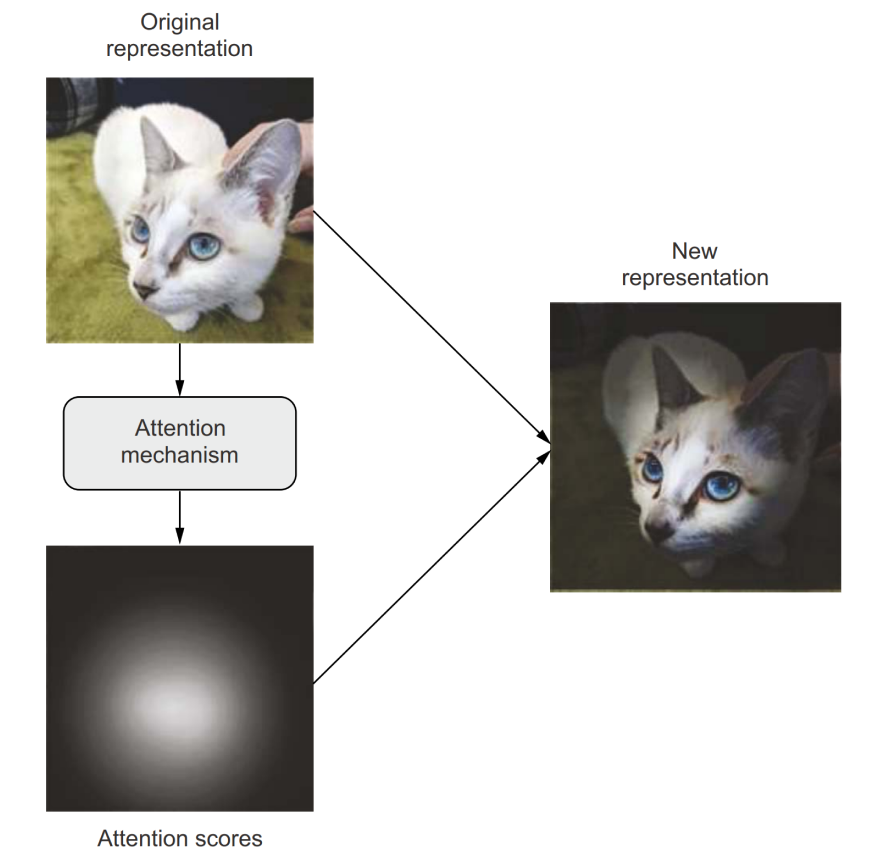
The general concept of “attention” in deep learning: input features get assigned “attention scores,” which can be used to inform the next representation of the input.
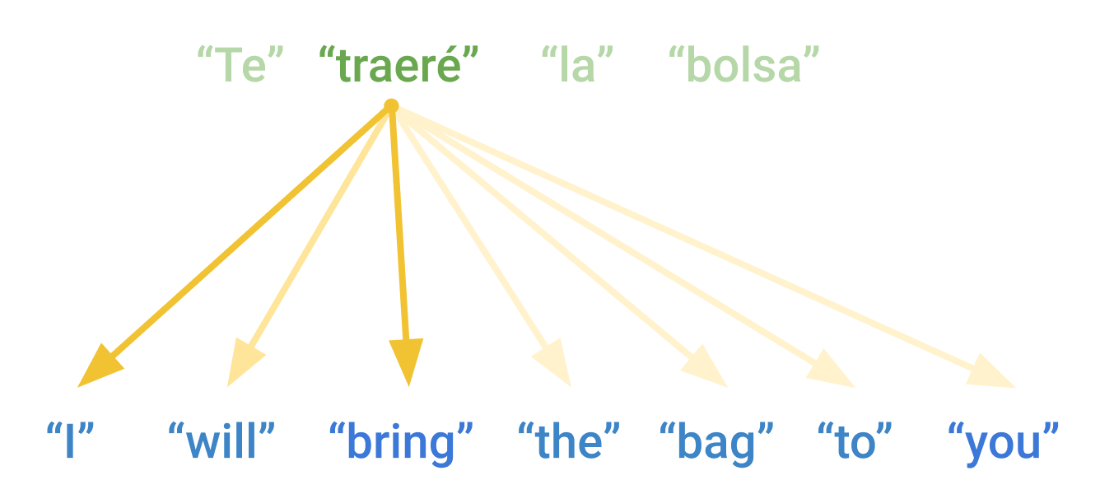
Attention assigns a relevance score to each vector in a source for each vector in a target sequence.
When both target and source are sequences, attention scores are a 2d matrix. Each row shows the attention scores for the word we are trying to predict, in green.

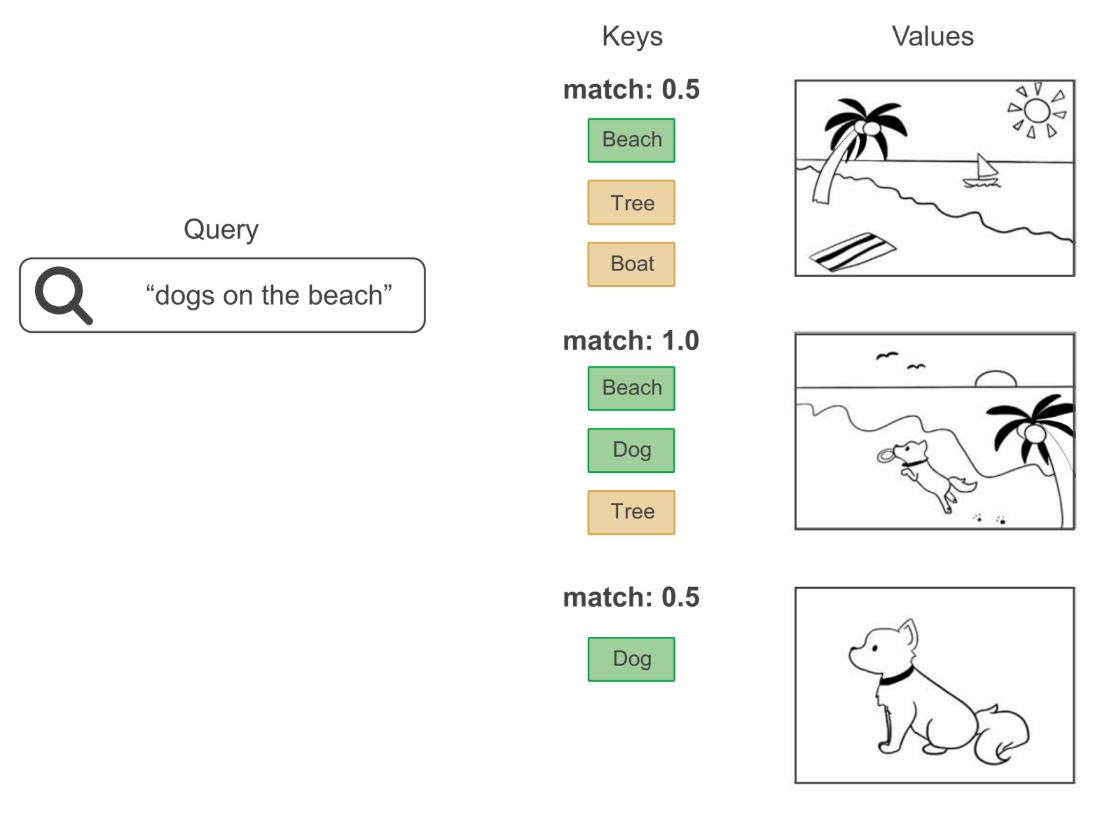
Retrieving images from a database: the query is compared to a set of keys, and the match scores are used to rank values (images).
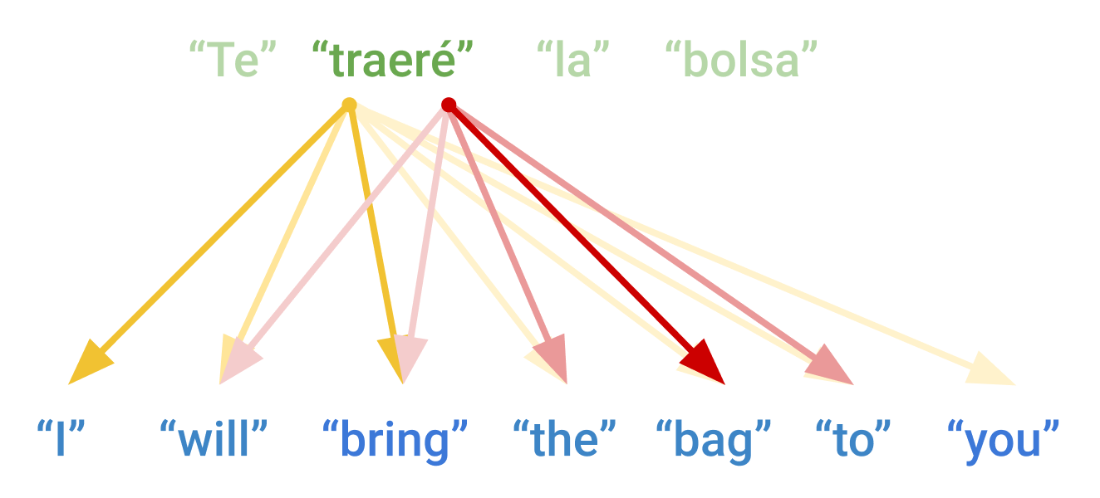
Multi-headed attention allows each target word to attend to different parts of the source sequence in separate partitions of the eventual output vector.
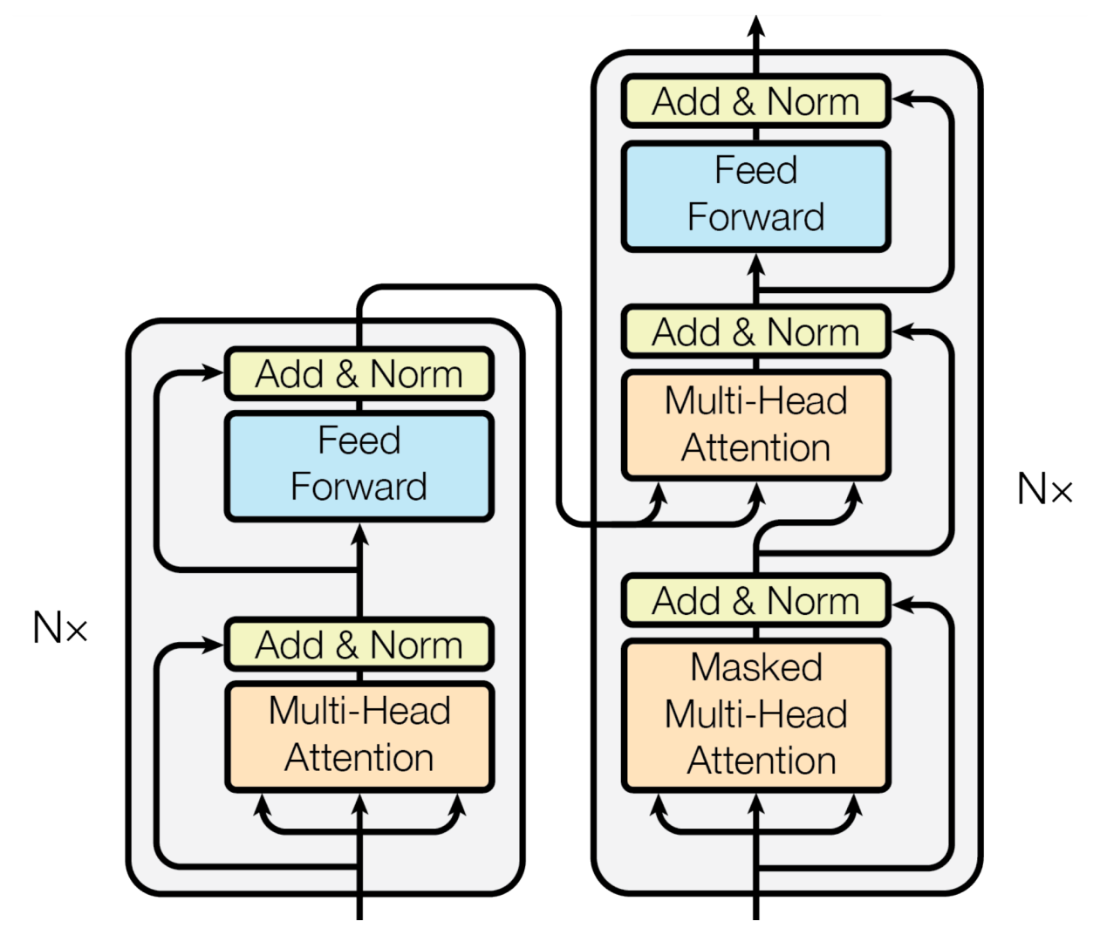
A visual representation of the computations for both TransformerEncoder and TransformerDecoder blocks.
Chapter summary
- A language model is a model that learns a specific probability distribution –
p(token|past tokens).- Language models have broad applications, but the most important is that you can generate text by calling them in a loop – where the output token at one time step becomes the input token in the next.
- A masked language model learns a related probability distribution
p(tokens|surrounding tokens), and can be helpful for classifying text and individual tokens. - A sequence-to-sequence language model learns to predict the next token given both past tokens in a target sequence and an entirely separate, fixed, source sequence. Sequence-to-sequence models are useful for problems like translation and question answering.
- A sequence-to-sequence model usually has two separate components. An encoder computes a representation of the source sequence, and a decoder takes this representation as input and predicts the next token in a target sequence based on past tokens.
- Attention is a mechanism that allows a model to pull information from anywhere in a sequence selectively based on the context of the token currently being processed.
- Attention avoids the problems RNNs have with long-range dependencies in text.
- Attention works by taking the dot-product of two vectors to compute an attention score. Vectors near each other in an embedding space will be summed together in the attention mechanism.
- The Transformer is a sequence modeling architecture that uses attention as the only mechanism to pass information across a sequence.
- The Transformer works by stacking blocks of alternating attention and two-layer feed-forward networks.
- The Transformer can scale to many parameters and lots of training data while still improving accuracy in the language modeling problem.
- Unlike RNNs, the Transformer involves no sequence-length loops at training time, making the model much easier to train in parallel across many machines.
- A Transformer encoder uses bidirectional attention to build a rich representation of a sequence.
- A Transformer decoder uses causal attention to predict the next word in a language model setup.
 Deep Learning with Python, Third Edition ebook for free
Deep Learning with Python, Third Edition ebook for free