11 Image segmentation
This chapter broadens the view of deep learning for vision beyond classification to emphasize image segmentation—assigning a label to every pixel in an image. It situates segmentation alongside the two other foundational tasks—classification and object detection—and clarifies the three segmentation flavors: semantic (category per pixel), instance (separating object instances), and panoptic (both category and instance). The chapter highlights real-world uses ranging from background replacement in video calls to robotics, autonomous driving, and medical imaging, framing segmentation as a versatile, practical technique.
The chapter first walks through building a semantic segmentation model from scratch on the Oxford-IIIT Pets dataset, whose masks encode foreground, background, and contours. Data is loaded into arrays and fed to an encoder–decoder convnet: the encoder uses strided convolutions (rather than max pooling) to preserve spatial location while downsampling, and the decoder uses transposed convolutions to upsample back to the original resolution, ending with a per-pixel softmax over classes. Training uses sparse categorical crossentropy and Intersection over Union (IoU) for evaluation, with checkpointing to curb overfitting; the result produces reasonable masks with minor artifacts.
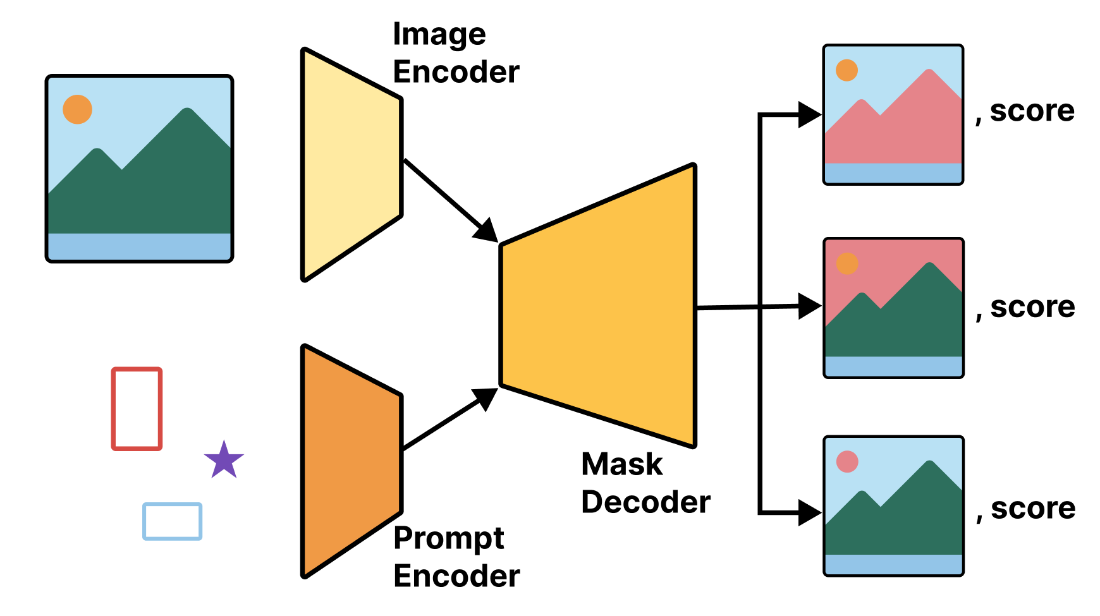
Next, the chapter demonstrates using the pretrained Segment Anything Model (SAM), a large promptable segmenter trained on an extensive dataset of images and masks. SAM accepts points or boxes as prompts and returns multiple candidate masks ranked by quality, enabling flexible, class-agnostic segmentation without fine-tuning. A brief overview covers its components (image encoder, prompt encoder, mask decoder), practical input preparation (resize and pad to a square resolution), and use via a high-level KerasHub preset. Through prompt-based examples, the chapter shows how SAM can rapidly extract objects and accelerate the creation of segmentation datasets for downstream applications.
The three main computer vision tasks: classification, segmentation, detection.
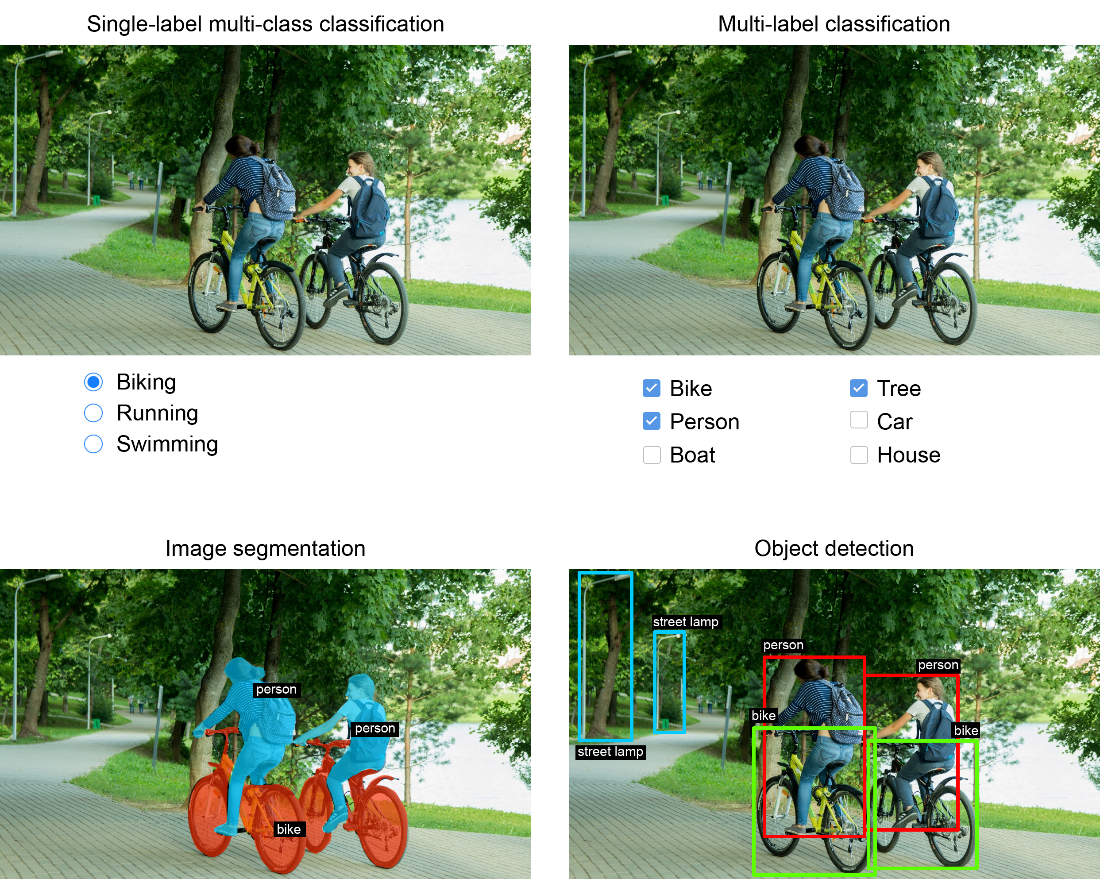
Semantic segmentation vs. instance segmentation vs panoptic segmentation.

An example image

The corresponding target mask

Displaying training & validation loss curves
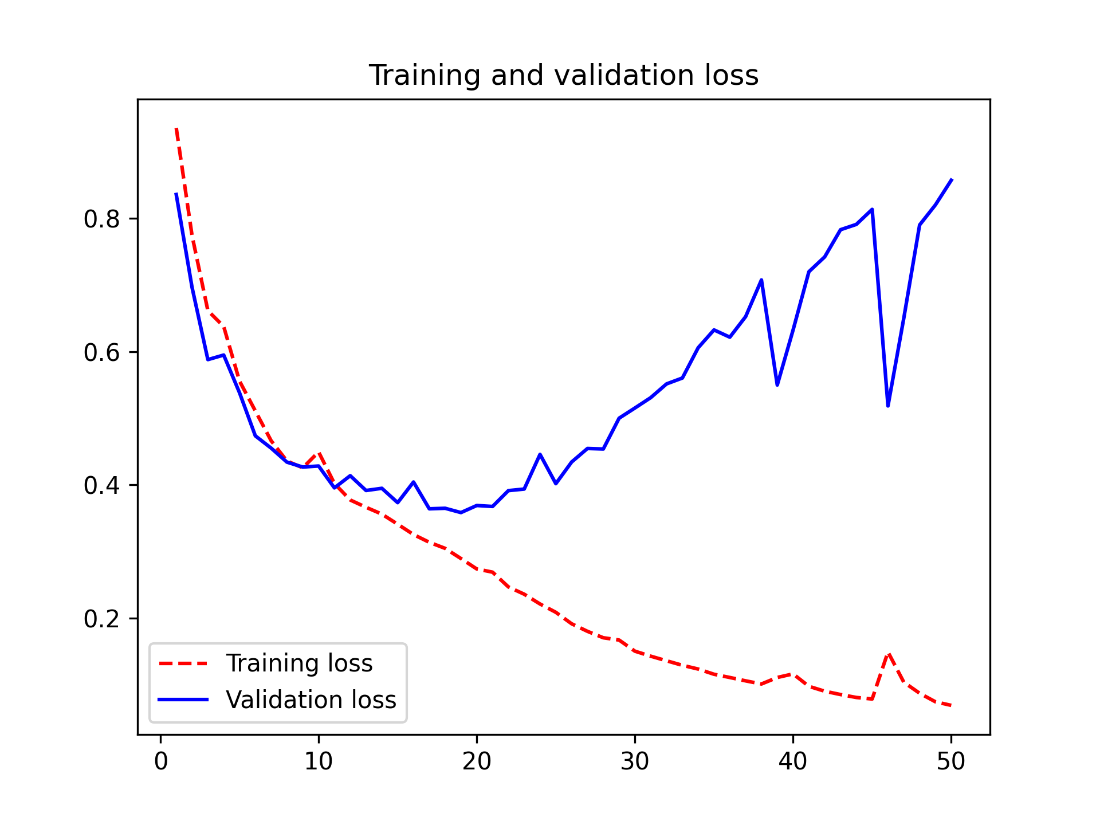
A test image and its predicted segmentation mask

An example image from the SA-1B dataset.

The Segment Anything high-level architecture overview.
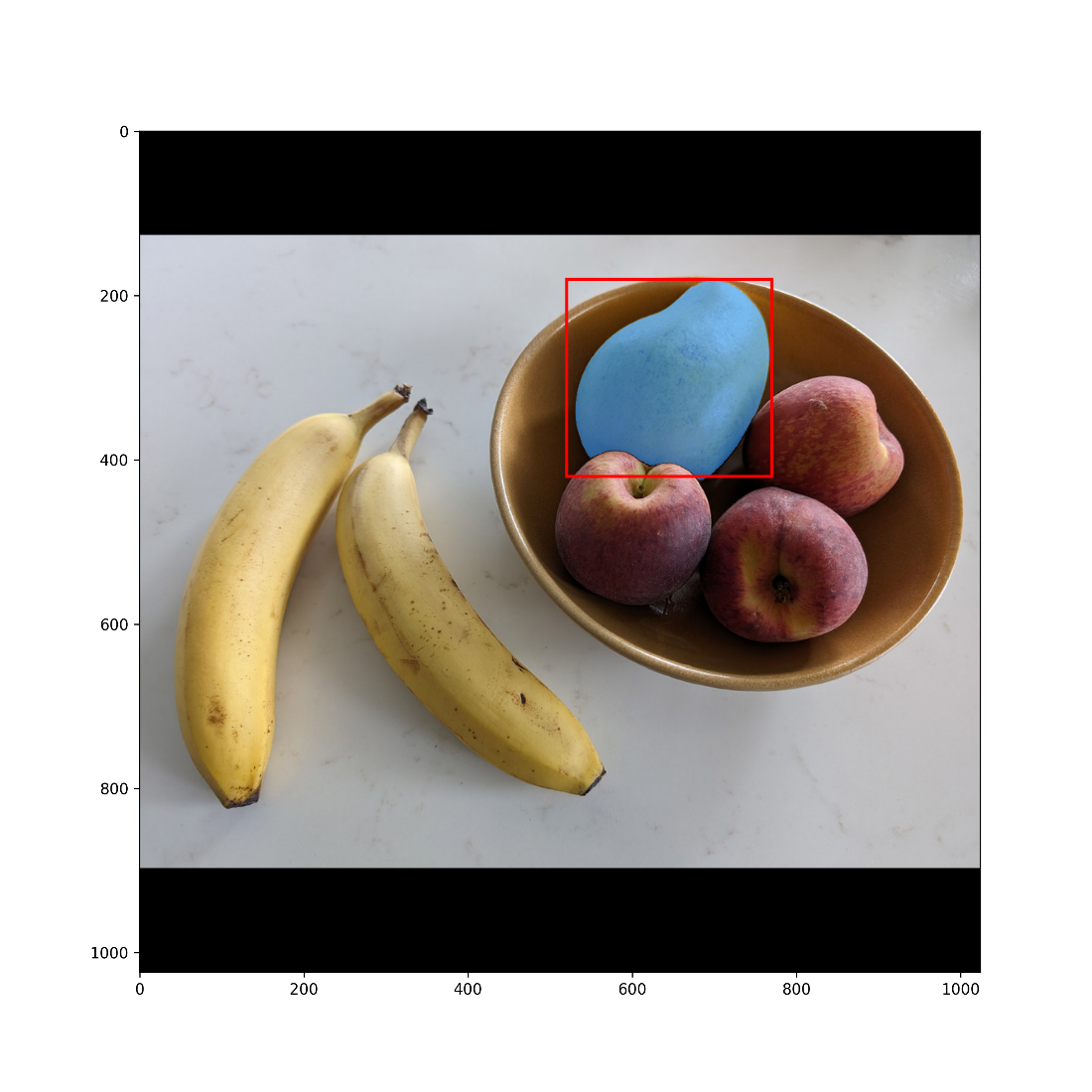
Our test image

A prompt point, landing on a peach

Segmented peach

Segmented banana

Alternative segmentation masks for the banana prompt

Box prompt around the mango

Segmented mango
Chapter summary
- Image segmentation is one of the main categories of computer vision tasks. It consists of computing “segmentation masks” that describe the contents of an image at the pixel level.
- To build your own segmentation model, use a stack of strided
Conv2Dlayers to “compress” the input image into a smaller feature map, followed by a stack of correspondingConv2DTransposelayers to “expand” the feature map into a segmentation mask the same size as the input image. - You can also use a pretrained segmentation model. Segment Anything, included in KerasHub, is a powerful model that supports image prompting, text prompting, point prompting, and box-prompting.
FAQ
What are the main computer vision tasks, and how do they differ?
Image classification assigns one or more labels to an entire image. Image segmentation assigns a class to each pixel, producing a mask that partitions the image into regions. Object detection draws bounding boxes around objects and labels each box.What are semantic, instance, and panoptic segmentation?
- Semantic segmentation: classifies each pixel into a semantic category (e.g., “cat”), without separating individual instances.- Instance segmentation: separates pixels into individual object instances (e.g., “cat 1” vs “cat 2”).
- Panoptic segmentation: combines both, giving each pixel a semantic label and an instance ID.
How are segmentation masks represented in the Oxford-IIIT Pets example?
Masks are single-channel PNGs with the same spatial size as the input image. Pixels take integer values: 1=foreground, 2=background, 3=contour. For training, values are often shifted to start at 0 (by subtracting 1), yielding class indices 0–2 suitable for sparse categorical loss.What is the basic architecture of the scratch-built segmentation model?
An encoder–decoder convnet: the encoder uses Conv2D layers with strides to downsample and extract features; the decoder uses Conv2DTranspose layers to upsample back to the input resolution. The final layer is a per-pixel softmax over num_classes channels. Inputs are rescaled to [0, 1].Why use strided convolutions instead of max pooling for segmentation?
Max pooling discards fine-grained spatial location within pooling windows, which harms per-pixel predictions. Strided convolutions downsample while retaining more spatial information, improving the model’s ability to localize class boundaries.What does Conv2DTranspose do in a segmentation model?
Conv2DTranspose learns to upsample feature maps, effectively reversing earlier downsampling steps. Stacking these layers can bring feature maps back to the original image resolution so the model can output a class probability for every pixel.How do you evaluate segmentation with Intersection over Union (IoU) in Keras?
IoU = intersection area / union area between predicted and ground-truth masks (per class or averaged). In Keras, use keras.metrics.IoU with num_classes, target_class_ids to select the class(es), sparse_y_true=True (integer mask labels) and sparse_y_pred=False (softmax probabilities).How are data prepared for training semantic segmentation in the example?
- Collect matching lists of image paths and mask paths; shuffle both with the same seed.- Resize inputs and masks to a fixed size (e.g., 200×200).
- Load inputs as float32 RGB; load masks as single-channel uint8, then shift labels to start at 0.
- Split into train/validation sets; compile with sparse_categorical_crossentropy and an IoU metric; train with callbacks (e.g., ModelCheckpoint).
What is the Segment Anything Model (SAM) and why is it useful?
SAM is a large pretrained image segmenter from Meta AI, trained on SA-1B (11M images, 1B+ masks). It’s promptable (not limited to fixed classes): you specify a point or a box and it returns masks for the indicated object(s). It works well out-of-the-box and is powerful for rapid dataset annotation.How do you use SAM via KerasHub, and what do its inputs/outputs look like?
- Load with keras_hub.models.ImageSegmenter.from_preset("sam_huge_sa1b").- Resize and pad inputs to 1024×1024 (preserving aspect ratio via pad_to_aspect_ratio).
- Prompt with either points+labels (1=foreground, 0=background) or boxes (top-left, bottom-right).
- The model returns multiple candidate masks (e.g., shape (1, 4, 256, 256)) plus quality scores (iou_pred). You can pick the best-ranked mask and overlay it on the image.
 Deep Learning with Python, Third Edition ebook for free
Deep Learning with Python, Third Edition ebook for free