1 The World of Large Language Models
Language underpins human connection, and the chapter traces how computers learned to work with it—from early natural language processing to today’s deep-learning-driven large language models (LLMs). Fueled by neural networks, abundant data, and powerful compute, LLMs progressed beyond narrow voice assistants to systems that predict and generate coherent text, sustain dialogue, and reason over context. The discussion treats LLMs as practical building blocks in a larger machine-learning ecosystem, and previews the expanding horizon of multimodal models that jointly understand text, images, and audio for more natural, human-like interactions.
On the application front, LLMs power conversational agents, text and code generation, retrieval and classification, recommendation, editing, and agent-based task automation. A highlighted pattern is Retrieval-Augmented Generation (RAG), which couples targeted retrieval from curated sources with generation to ground answers in fresher, domain-specific context. Realizing these capabilities depends on training at scale with vast, diverse corpora to learn linguistic patterns and semantics, followed by fine-tuning for specific domains. The chapter explains the compute demands (GPUs/TPUs), the roles of training versus fine-tuning, and the practical orchestration required to design, resource, and deploy effective LLM applications.
The chapter also surveys core challenges—bias and ethics, limited interpretability, and hallucinations—emphasizing the need for safeguards, validation, and responsible use. Finally, it maps the startup landscape catalyzed by LLMs: quick-to-build wrappers, infrastructure providers (e.g., vector databases and LLM frameworks), and capital-intensive “GPU-rich” model labs competing at the frontier. With this context, the book positions itself as a hands-on guide to building robust, context-aware LLM applications, setting up deeper dives into architectures like Transformers in subsequent chapters.
An output for a given prompt using ChatGPT
Rose Goldberg’s famous self-operation napkin constructing an LLM application demands a thoughtful orchestration of resources, from computational power to application definition, echoing the complexity of Rube Goldberg's contraptions.

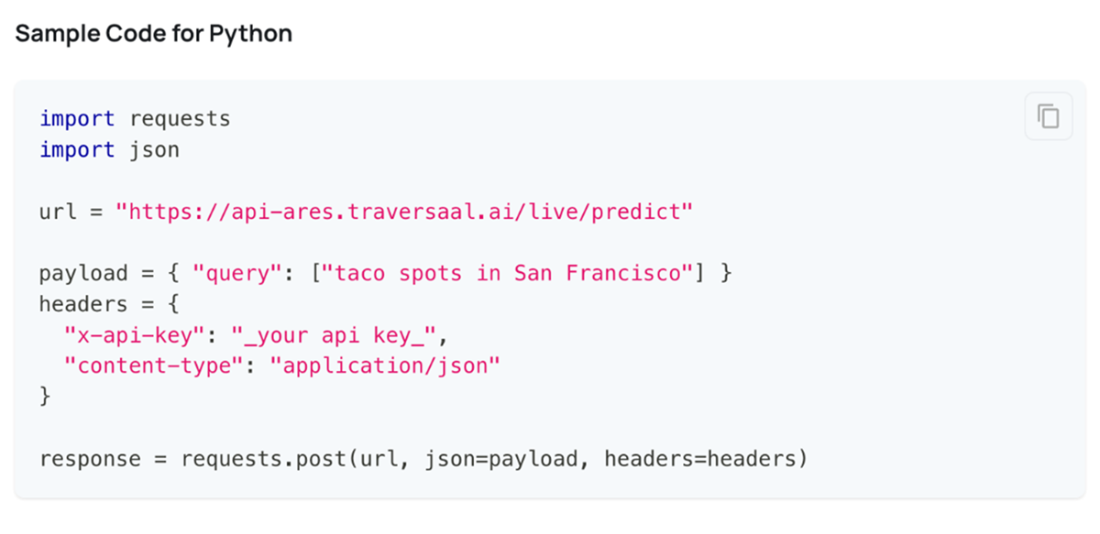
A Python code snippet demonstrating how to use the Ares API to retrieve information about taco spots in San Francisco using the internet. Instead of just showing URLs, the API returns actual answers with web URLs as source
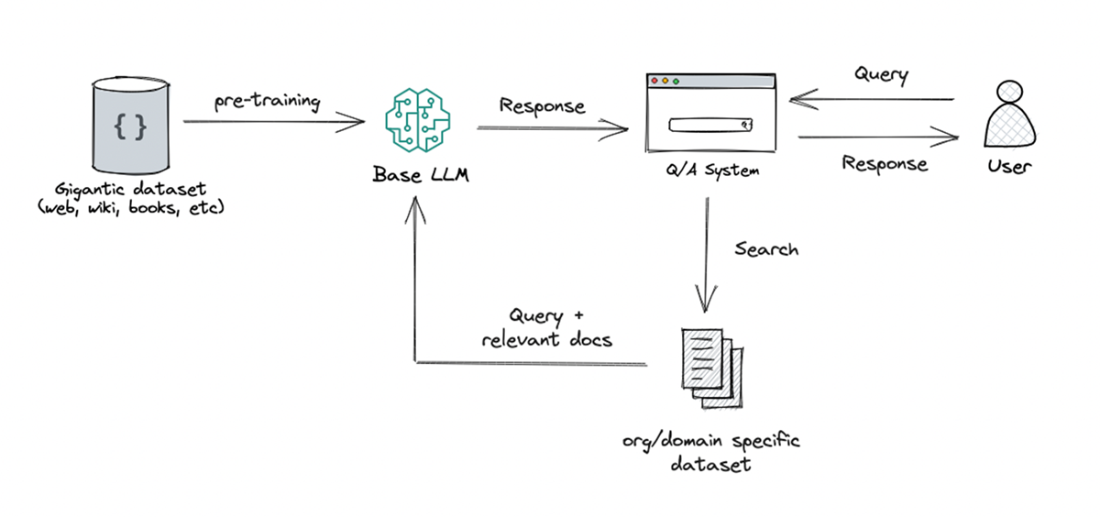
Retrieval Augmentation Generation is used to enhance the capabilities of LLMs, especially in generating relevant and contextually appropriate responses. The approach involves incorporating an initial retrieval step before generating a response to leverage information from a knowledge base.
Summary
- Large language models (LLMs) are the latest breakthrough in natural language processing after statistical models and deep learning. LLMs stand on the shoulders of this prior research but take language understanding to new heights through scale.
- Pretrained on massive text corpora, LLMs like GPT-3 capture broad knowledge about language in their model parameters. This allows them to achieve state-of-the-art performance on language tasks.
- Applications powered by LLMs include text generation, classification, translation, and semantic search to name a few.
- LLMs utilize multi-billion parameter Transformer architectures. Training such gigantic models requires massive computational resources only recently made possible through advances in AI hardware.
- Bias and safety are key challenges with large models. Extensive testing is required to prevent unintended model behavior across diverse demographics.
- Numerous startups are offering LLM model APIs, democratizing access and allowing innovation in the realm of Generative AI.
 Build an Advanced RAG Application (From Scratch) ebook for free
Build an Advanced RAG Application (From Scratch) ebook for free