1 The Drug Discovery Process
This chapter introduces drug discovery as a costly, lengthy, and failure-prone search for safe and effective therapeutic compounds. It frames the central challenge as navigating an enormous chemical space of possible drug-like molecules and a large biological space of potential targets. Artificial intelligence, machine learning, and especially deep learning are presented as tools that can help prioritize compounds, predict molecular properties, reduce experimental burden, and identify failures earlier in the pipeline.
The chapter explains key AI applications in modern computational drug discovery, including virtual screening, property prediction, generative chemistry, retrosynthesis, and protein structure prediction. Virtual screening uses computational models to rank compounds for properties such as binding affinity, toxicity, or solubility, while generative models aim to design novel molecules directly from desired functional criteria. The text also introduces foundational machine learning concepts such as training data, test data, generalization, supervised learning, unsupervised learning, classification, regression, clustering, representation learning, and generative modeling, then connects these ideas to molecular representations such as SMILES and cheminformatics tools like RDKit.
The chapter then outlines the drug discovery and development pipeline, from target identification and hit discovery through lead identification, lead optimization, preclinical testing, and clinical trials. It explains how hits are screened for binding to biological targets, how leads are evaluated for properties such as ADMET, potency, selectivity, efficacy, safety, and bioavailability, and how optimized candidates move into animal studies and human trials. Overall, the chapter establishes that AI can support many stages of discovery by improving molecule selection, accelerating optimization, enabling novel design, and helping researchers make better decisions before the most expensive phases of drug development begin.
Drug discovery can be thought of as a difficult search problem that exists at the intersection of the chemical search space of 1063 drug-like compounds and the biological search space of 105 targets.

Using AI to guide early prediction and optimization of drug-like molecules, we can broaden the number of considered candidate molecules, identify failures earlier when they are relatively inexpensive, and accelerate delivery of novel therapeutics to the clinic for patient benefit.

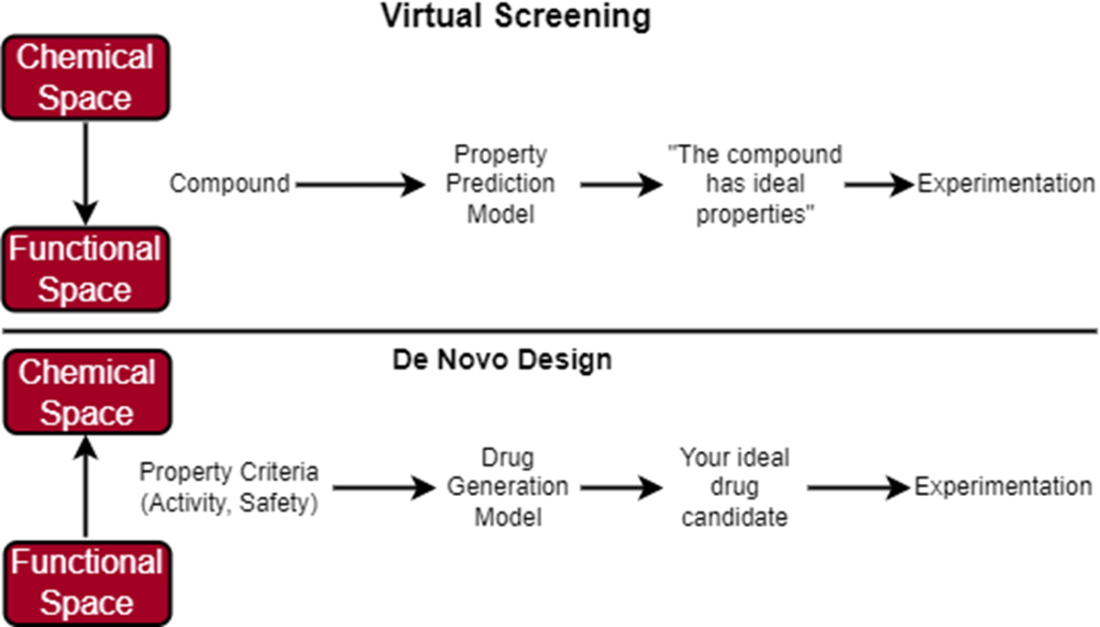
In virtual screening, we start with a large, diverse library of compounds that we can filter using a predictive model that has learned to predict what properties each compound has. Our predictive model has learned how to map the chemical space to the functional space. If the compound is predicted to have optimal properties, we carry it over for further experiments. In de novo design, we start with a defined set of property criteria that we can use along with a generative model to generate the structure of our ideal drug candidate. Our generative model knows how to map the functional space to the chemical space.
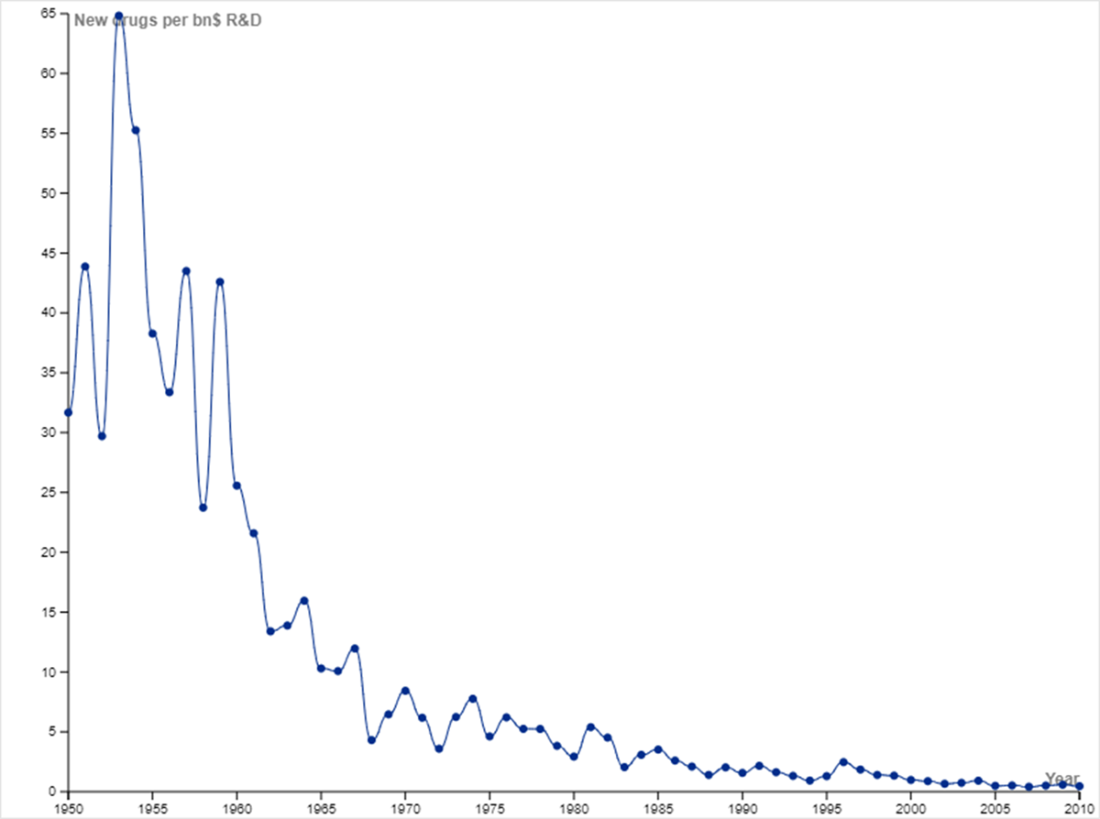
New drugs per billion USD of R&D reflects a downward trajectory. You may have heard of Moore’s Law, which is the observation that the number of transistors on an integrated circuit doubles approximately every two years. Moore’s Law implies that computing power doubles every couple of years while cost decreases. Eroom’s Law (Moore spelled backwards) is the observation that the inflation-adjusted R&D cost of developing new drugs doubles roughly every nine years. Eroom’s Law reflects diminishing returns in developing new drugs, including factors such as lower risk tolerance by regulatory agencies (the “cautious regulator” problem), the “throw money at it” tendency, and need to show more than a modest incremental benefit over current successful drugs (the “better than the Beatles” problem). The plot was constructed with data from Scannell et al., which discusses the trend in greater detail [6].
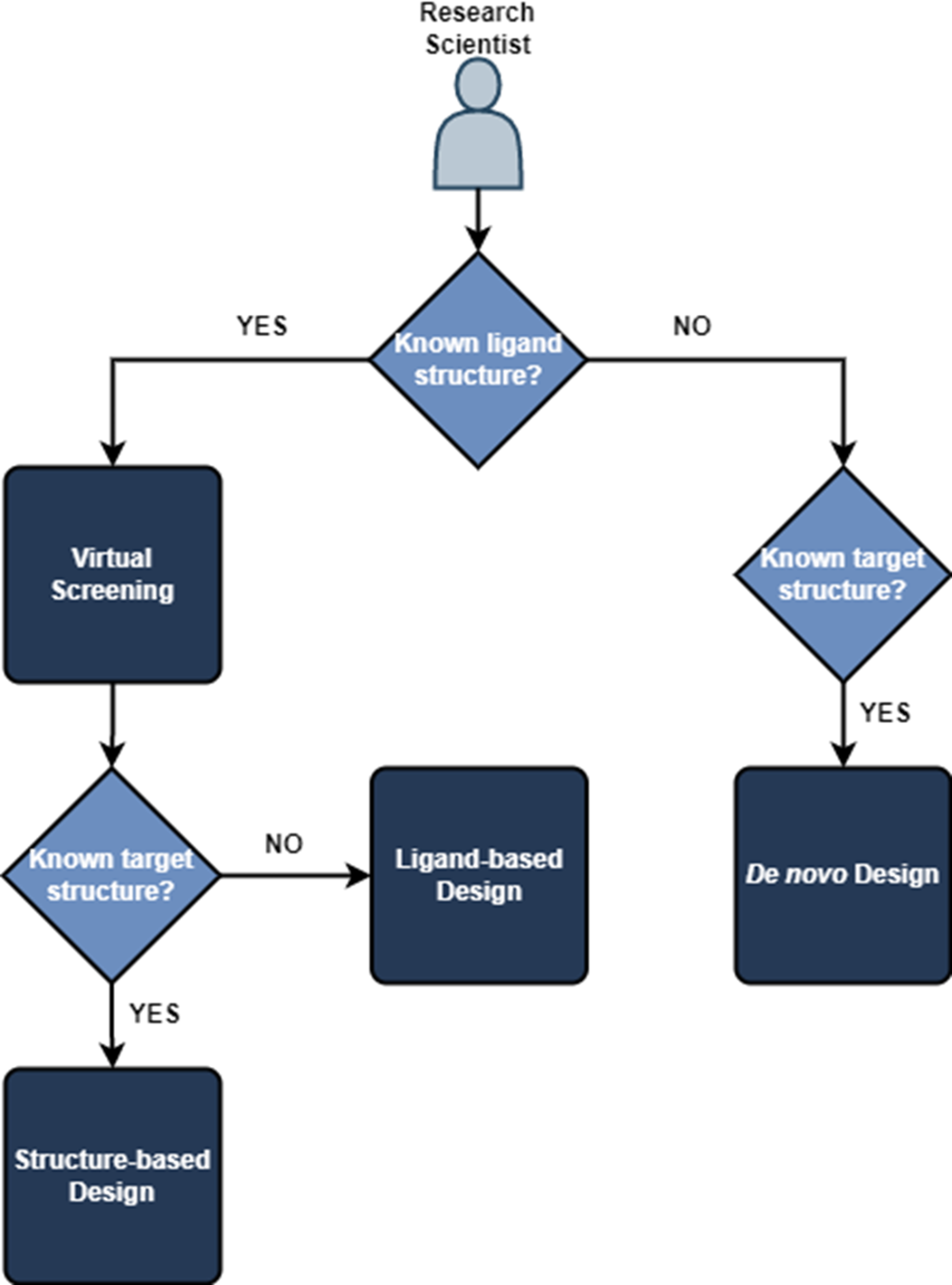
If we know both the structure of our ligand or compound and the target, we can use structured-based design methods. If we only know the ligand structure, we are restricted to ligand-based design methods. Alternatively, if we only know the target structure, we can use de novo design to guide generation of a suitable drug candidate.
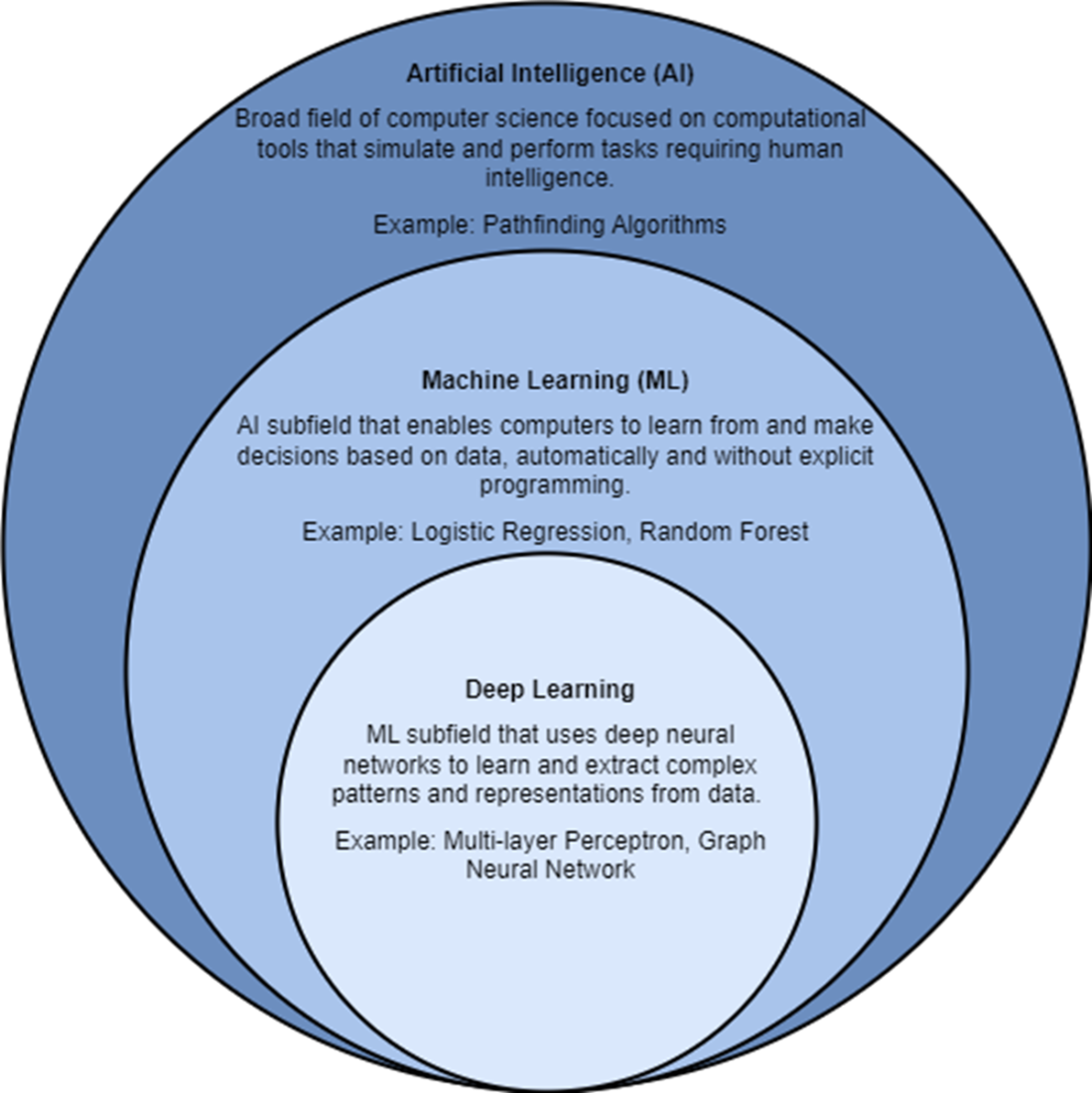
Artificial intelligence, ML, and deep learning are all related to each other.
Example pairs of isomeric SMILES.
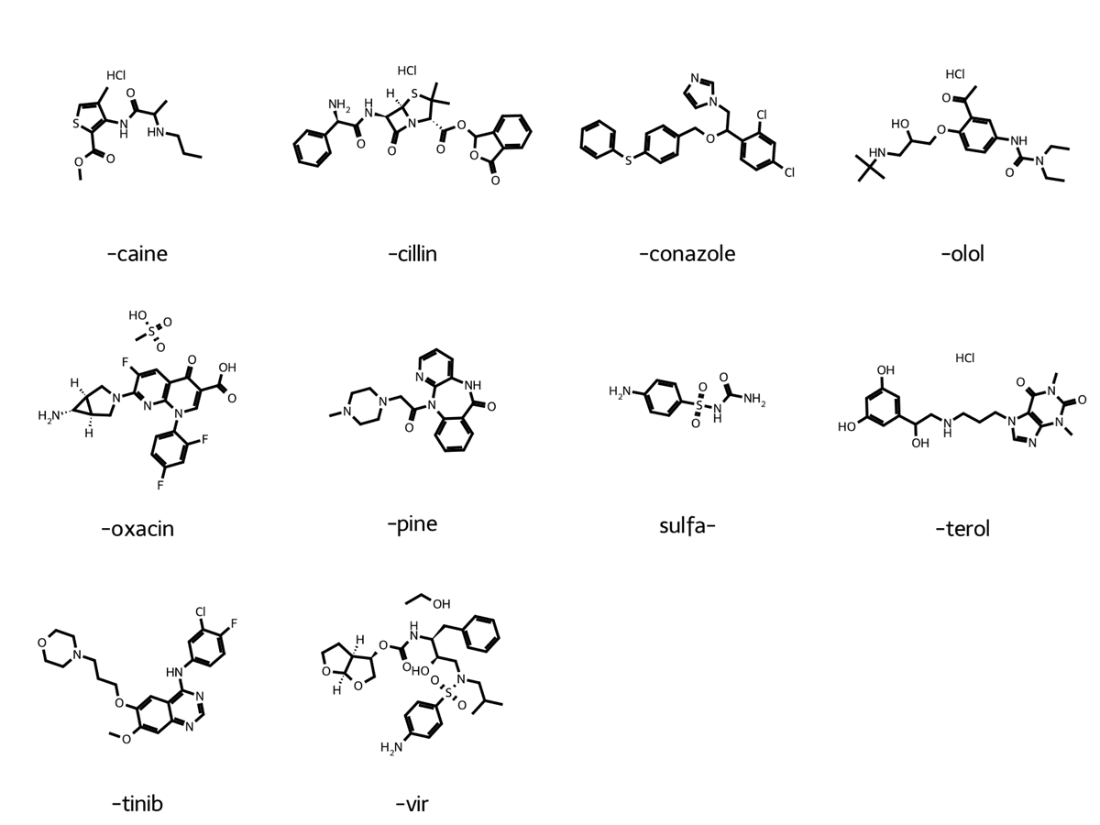
Example drug molecules for each USAN stem classification within our data set.
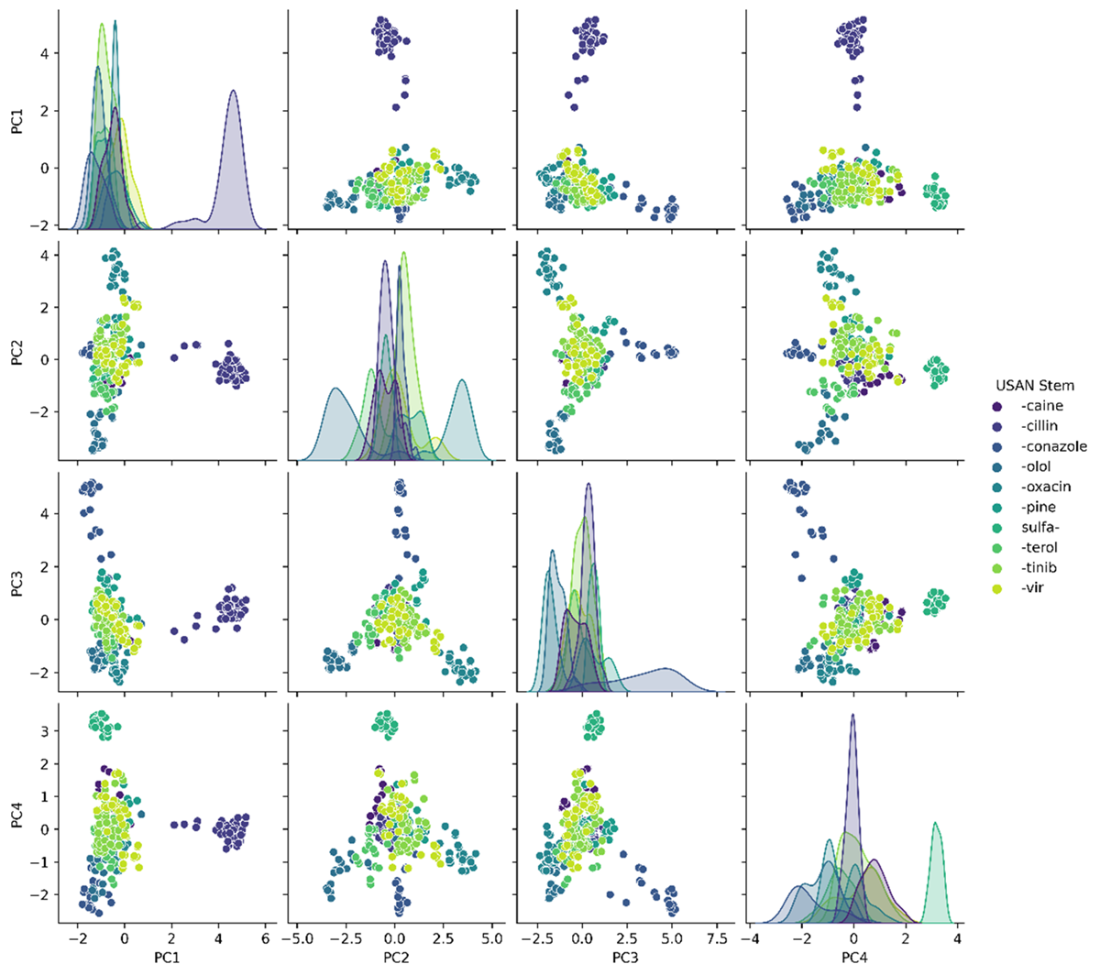
Chemical space exploration in a reduced, 4-dimensional space.
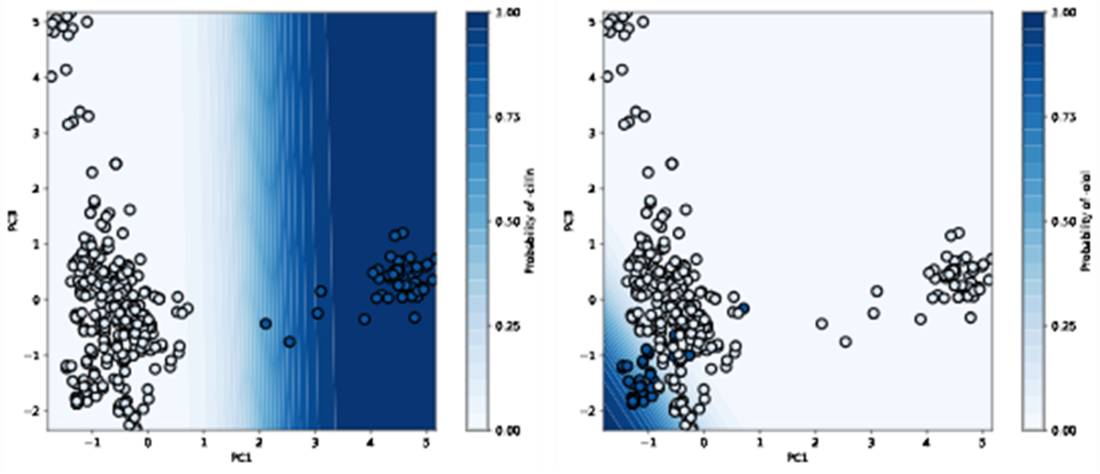
Decision boundary of our logistic regressor for classifying “-cillin” (left) and “-olol” (right) USAN stems. For each plot, colored samples belong to the positive class and uncolored samples belong to the negative class.
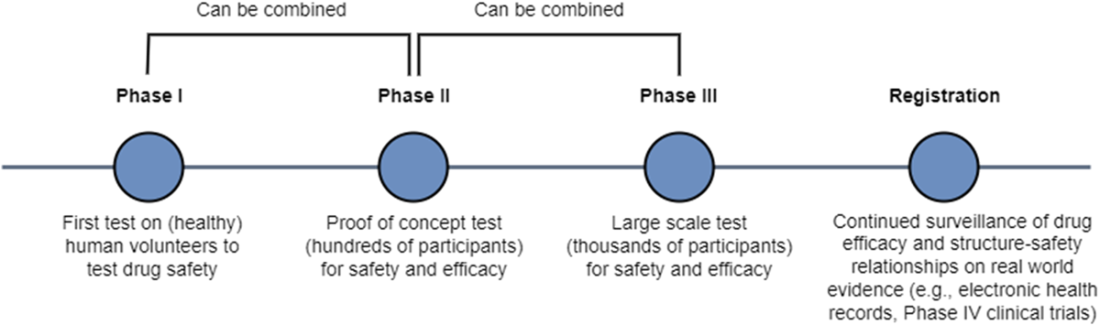
We can breakdown drug design into target identification and validation, hit discovery, hit-to-lead (lead identification), lead optimization, and preclinical development. Once a drug candidate has progressed to the drug development stage, it will need to pass multiple phases of clinical trials testing safety and efficacy prior to submission to and review by the FDA and launch to market.
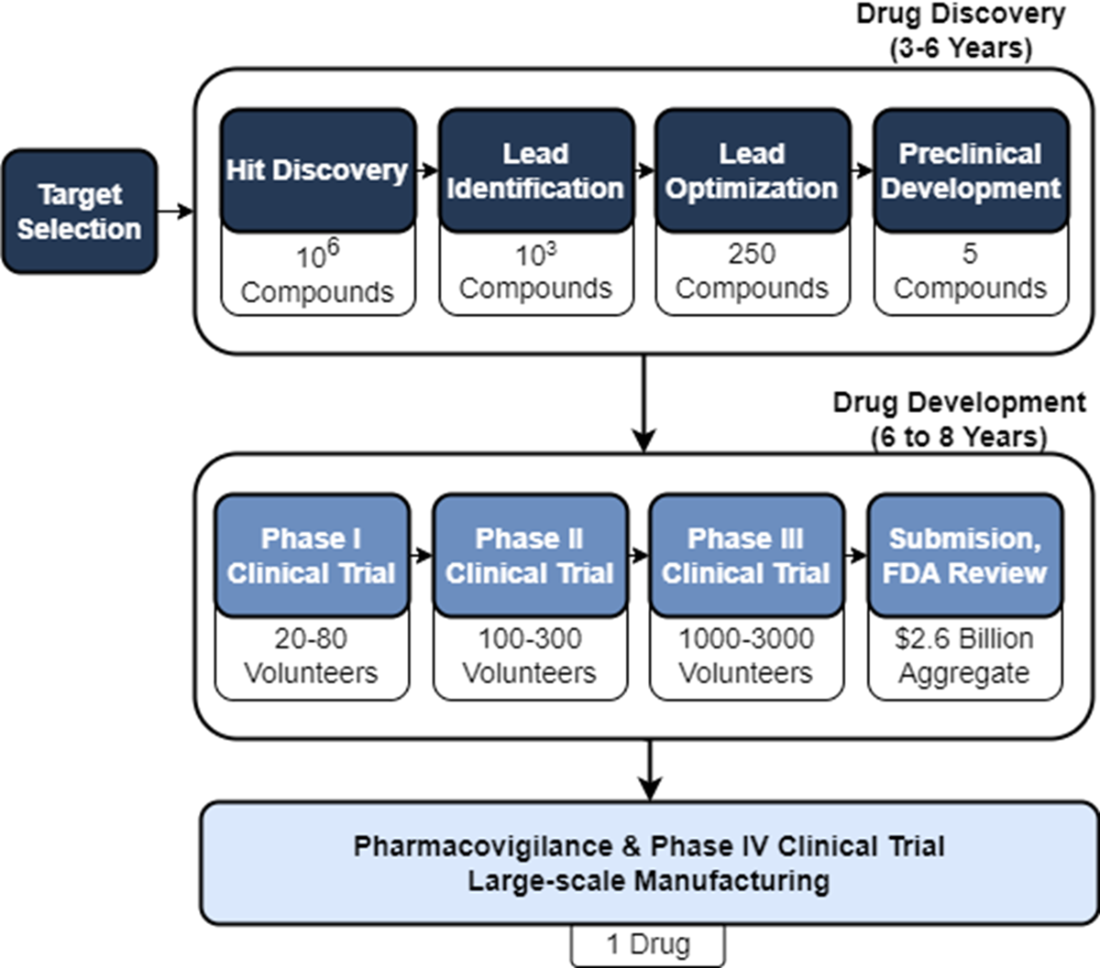
We can break down the ADMET properties into the following broad descriptions. Absorption refers to the process by which a drug enters the bloodstream from its administration site, such as the gastrointestinal tract for oral drugs or the respiratory system for inhalation drugs. Distribution pertains to the movement of a drug within the body once it has entered the bloodstream. Metabolism refers to the biochemical transformation of a drug within the body, primarily carried out by enzymes. Metabolic processes aim to convert drugs into more polar and water-soluble metabolites, facilitating their elimination from the body. Excretion involves the removal of drugs and their metabolites from the body. Toxicity assessment aims to evaluate the potential adverse effects of a drug candidate on various organs, tissues, or systems.
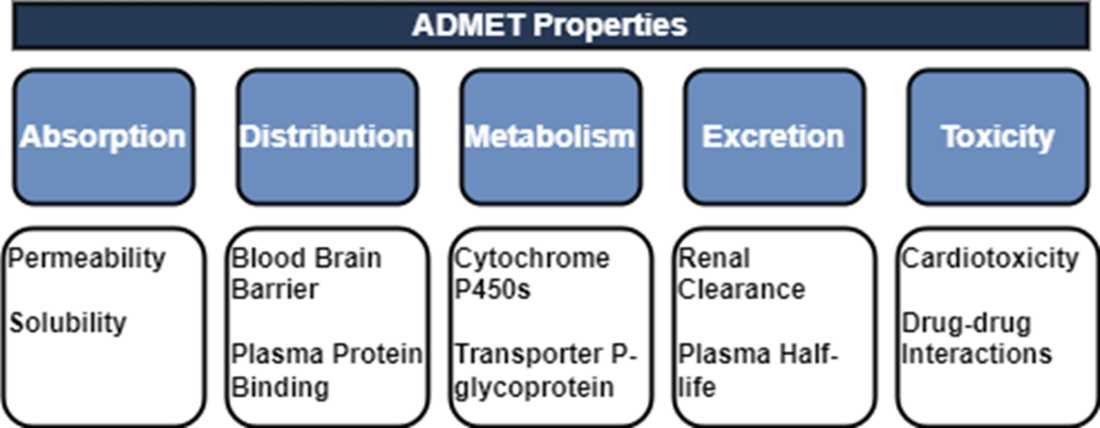
We can segment the early drug discovery pipeline into four main phases: target identification, hit discovery, hit-to-lead or lead identification, and lead optimization. Target identification designates a valid target whose activity is worth modulating to address some disease or disorder. Hit discovery uncovers chemical compounds with activity against the target. Lead identification selects the most promising hits and lead optimization improves their potency, selectivity, and ADMET properties to be suitable for preclinical study.
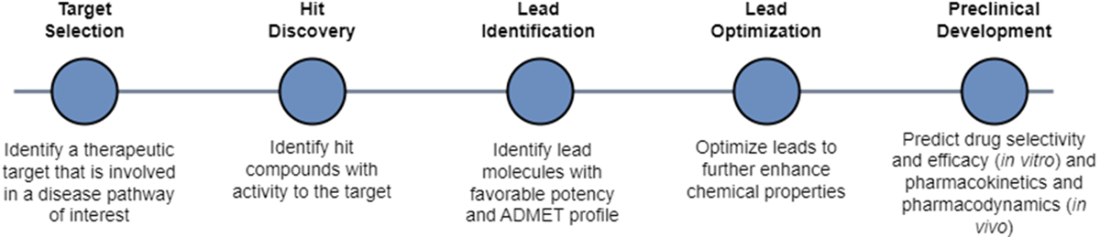
In virtual screening, we conducted our search across a chemical space consisting of an enormous set of molecules. In de novo design, we are still conducting an (informal) search, just not across the chemical space. We are now searching across the functional space of potential molecular properties. If our model “learns” which section of the functional space maps to molecules that have ideal binding affinity and safety, then perhaps it can reverse-engineer novel molecule structures in the chemical space that match our functional criteria.
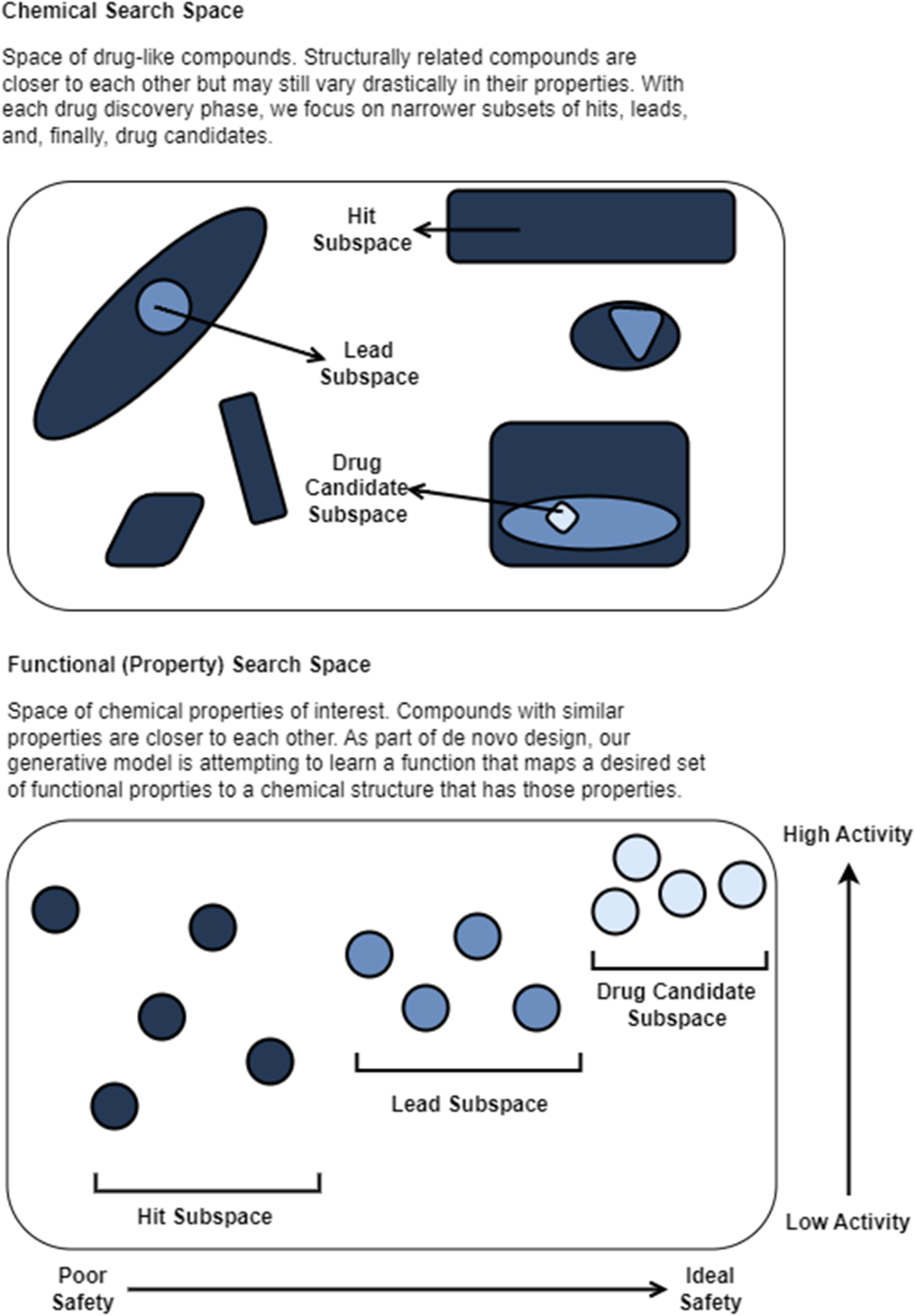
Preclinical trials evaluate drug candidate safety and efficacy on model organisms. Phase I clinical trials evaluate drug candidate safety in its first exposure to humans. Phase II and Phase III clinical trials continue to collect data on safety while measuring drug candidate efficacy on larger groups of patients. The pass rate of our lead compounds decreases drastically as they progress beyond preclinical stages, along with an increase in the associated time to test them.
Summary
- Developing therapeutics entails a long, arduous process. Traditional development from ideation to market is costly (magnitude of billions of dollars), lengthy (10 to 15 years), and risky (attrition of over 90%). Through advances in AI, we can discover cures that have better safety profiles, address medical conditions or diseases with low coverage, and can reach patients quicker.
- Drug discovery can be thought of as a difficult search problem that exists at the intersection of the chemical search space of 1063 medicinal compounds and the biological search space of 105 targets.
- Applications of AI to drug design include molecule property prediction for virtual screening, creation of compound libraries with de novo molecule generation, synthesis pathway prediction, and protein folding simulation.
- ML is a subfield of AI that enables computers to learn from and make decisions based on data, automatically and without explicit programming or rules on how to behave. Example ML algorithms include logistic regression and random forests. Deep learning is a subfield of ML that uses deep neural networks to extract complex patterns and representations from data.
- We can segment the early drug discovery pipeline into four main phases: target identification, hit discovery, hit-to-lead or lead identification, and lead optimization. Target identification designates a valid target whose activity is worth modulating to address some disease or disorder. Hit discovery uncovers chemical compounds with activity against the target. Lead identification selects the most promising hits and lead optimization improves their potency, selectivity, and ADMET properties to be suitable for preclinical study.
- Popular, well-maintained chemical data repositories include ChEMBL, ChEBI, PubChem, Protein Data Bank (PDB), AlphaFoldDB, and ZINC. When using a new data source, learn how it was assembled and how quality is maintained. Garbage data in, garbage model out. See “Appendix B: Chemical Data Repositories” for more information.
FAQ
What is drug discovery, and how is it different from drug development?
Drug discovery is the early process of finding and optimizing a compound that can become a therapeutic drug. It includes target identification, hit discovery, lead identification, lead optimization, and preclinical development. Drug development begins after a promising drug candidate leaves discovery and enters clinical trials, regulatory review, and eventual market launch.
Why is drug discovery described as a “needle in a haystack” problem?
Drug discovery requires searching an enormous chemical space—estimated at around 1063 drug-like molecules—while also considering a biological search space of roughly 105 known human proteins and variants. Because only a tiny fraction of possible compounds are likely to be safe and effective, brute-force experimental testing is impossible. Machine learning helps prioritize candidates and reduce the search burden.
How can machine learning help in drug discovery?
Machine learning can learn patterns from chemical and biological data to predict useful drug-related properties without being explicitly programmed with every rule. In drug discovery, ML can support virtual screening, toxicity prediction, binding affinity prediction, ADMET assessment, generative molecule design, retrosynthesis planning, and protein structure prediction.
What is virtual screening?
Virtual screening is a computational approach for evaluating and prioritizing compounds as potential drug candidates before experimental testing. Traditional virtual screening may use molecular docking or molecular dynamics simulations, while ML-based virtual screening predicts properties such as toxicity, solubility, or binding affinity directly from molecular representations.
What is generative chemistry or de novo drug design?
Generative chemistry uses AI models to create novel chemical entities. In de novo drug design, instead of screening a fixed library of existing molecules, a model is given desired property criteria—such as high solubility, low toxicity, and strong target binding—and generates new molecular structures that may satisfy those criteria.
What are hits, leads, and drug candidates?
A hit is a compound found during screening that shows activity or binding affinity against a target. A lead is a more promising hit that has passed additional testing and shows potential for therapeutic development. A drug candidate is an optimized lead with sufficient potency, selectivity, safety, and ADMET properties to advance into preclinical or clinical evaluation.
What are ADMET properties, and why are they important?
ADMET stands for absorption, distribution, metabolism, excretion, and toxicity. These properties describe how a drug enters the body, moves through it, is chemically transformed, is removed, and whether it causes harmful effects. Poor ADMET properties can cause promising compounds to fail before or during clinical trials.
What is the difference between pharmacokinetics and pharmacodynamics?
Pharmacokinetics, or PK, describes what the body does to the drug, including absorption, distribution, metabolism, and excretion. Pharmacodynamics, or PD, describes what the drug does to the body, including efficacy, potency, mechanism of action, and therapeutic effects.
What are SMILES, and why are they useful in AI drug discovery?
SMILES, short for Simplified Molecular Input Line Entry System, are compact text strings that represent molecular structures using atoms, bonds, and grammar rules. They are useful because they allow molecules to be stored, compared, processed by cheminformatics tools such as RDKit, and converted into numerical features for machine learning models.
What role does RDKit play in machine learning pipelines for drug discovery?
RDKit is an open-source cheminformatics toolkit used to handle, analyze, and visualize chemical structures. It can read molecular formats such as SMILES, create molecule objects, calculate molecular descriptors and fingerprints, perform substructure searches, and integrate with machine learning libraries such as Scikit-Learn for tasks like clustering, dimensionality reduction, and classification.
 Build AI Drug Discovery Pipelines ebook for free
Build AI Drug Discovery Pipelines ebook for free