1 A tale of two models: transformers and diffusions
Generative AI models learn from large datasets to create new content, with text-to-image systems standing out for translating natural language into vivid, high-fidelity visuals. These models are multimodal: they take text as input and produce images, bridging language and vision in ways that power applications across design, marketing, education, healthcare, and entertainment. By contrasting unimodal and multimodal approaches, the chapter shows how advances in natural language processing and computer vision converge to make prompt-driven image creation practical and impactful in real-world workflows.
The chapter centers on two complementary families of techniques. Transformer-based generators treat images like sequences: a VQGAN encoder converts images into discrete codebook tokens, a language model (such as BART) turns text into tokens, and training aligns the two so that, at inference, text tokens can be decoded by VQGAN into images—an idea popularized by DALL·E-style systems. Diffusion models take the opposite route: they learn to reverse a noise-adding process, progressively denoising random noise into an image conditioned on a prompt. To make this efficient, latent diffusion performs denoising in a compact latent space and then upscales via a VAE decoder, often guided by a CLIP model to better match text semantics; Stable Diffusion is a leading open implementation of this pipeline.
Beyond mechanics, the chapter maps a hands-on path to building these systems from scratch—covering transformers and vision transformers, basic and guided diffusion, CLIP for text–image alignment, latent diffusion, and VQGAN—so readers can implement min-DALL·E-like and Stable Diffusion–style generators. It also underscores current limitations and risks: models can misinterpret negations (“pink elephant”–type failures), raise concerns about originality and copyright, and struggle with geometric consistency due to limited 3D understanding. Social and environmental considerations include high compute and energy costs, potential misuse (e.g., deepfakes and misinformation), and representational biases, motivating ongoing work on efficiency, safeguards, and fairness.
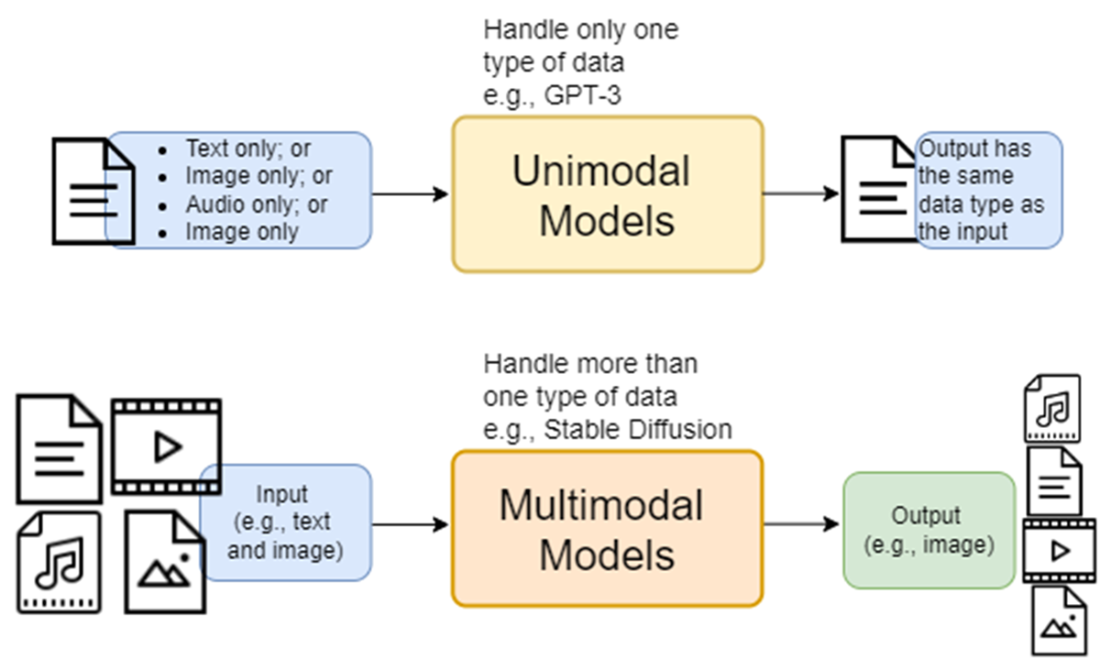
Comparison of unimodal and multimodal models. Unimodal models handle only one type of data as both the input and output. For example, GPT-3 is a unimodal model since it processes text as input and generates text as output. On the other hand, multimodal models operate with more than one type of data. A prominent example is text-to-image generation models (say, Stable Diffusion), where the input is text and an image (when editing existing images), and the output is an image.
Examples of generating captions for images. Above each image, we first display the original caption from the training dataset, created by humans. We then feed the image into a trained image-to-text model to generate a caption, which is displayed above the image as well. While the generated captions differ from those created by humans, they accurately describe what’s going on in these images.

How the min-DALL-E model generates an image based on the prompt "panda with top hat reading a book." The model divides an image into 256 patches, organized in a 16x16 grid. When generating an image based on a text prompt, the model first predicts the top left patch. In the next iteration, the model predicts the patch next to it, based on the first patch and the prompt. The process is repeated until we have all the needed patches in the image. In this figure, the top left subplot shows the output when 32 image patches are generated. The second subplot in the top row shows the output when 64 patches are generated. The rest of the images show the outputs when 96, 128, ..., and 256 patches are generated.

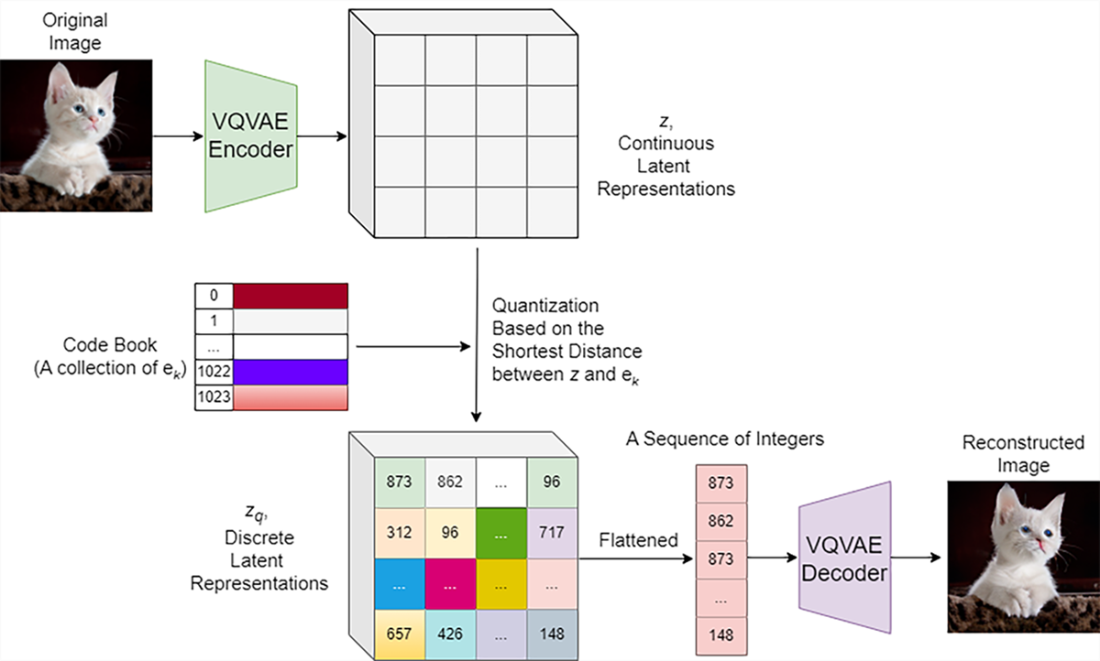
A diagram of VQGAN. The encoder in VQGAN compresses an image into a lower-dimensional latent space. The latent vector for each image is divided into different patches. The continuous latent vector for each patch is then compared to the discrete vectors in the codebook. The quantized latent vector uses discrete vectors in the codebook to approximate the continuous latent vector for each image patch. The quantized latent vectors are then passed through the decoder in VQGAN to reconstruct the image.
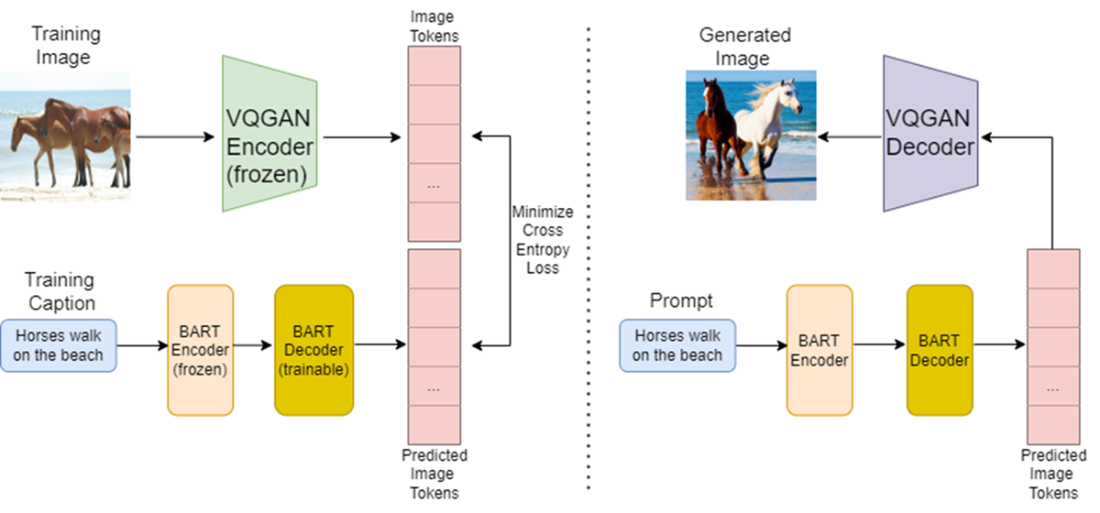
The left side of this figure depicts how a transformer-based text-to-image model is trained, while the right side illustrates the process of generating an image from a text prompt using the trained model. To train the model, images are encoded into image tokens using a VQGAN encoder. Corresponding captions are processed through a BART encoder and then a BART decoder to generate text tokens. The objective is to train the BART decoder to predict text tokens that match the image tokens produced by the VQGAN encoder. That is, the text tokens are used as the predicted image tokens. To generate an image using the trained model, the text prompt is fed into the BART encoder and then the BART decoder to produce the predicted text tokens, which are passed through the VQGAN decoder to generate the final output, as shown at the top center of the figure.
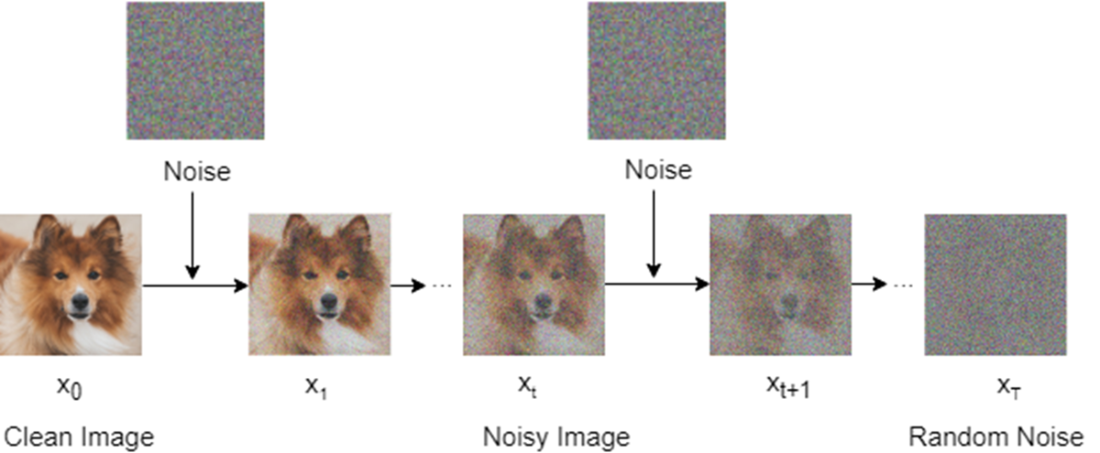
A diagram of the forward diffusion process. We start with a clean image from the training set, 𝑥0, and add noise 𝜖0 to it to form a noisy image 𝑥1, which is a weighted sum of 𝑥0 and 𝜖0. We repeat this process for 1000 time steps until the image 𝑥1000 becomes random noise.
How a trained latent diffusion model (LDM) generates an image based on a text prompt. The text prompt ("a banana riding a motorcycle, wearing sunglasses and a straw hat," for example, as shown at the top left corner) is first encoded into a text embedding. To generate an image in the lower-dimensional space (latent space), we start with an image of pure noise (bottom left). We use the trained U-Net to iteratively denoise the image, conditional on the text embedding so the generated image matches the text embedding, with the guidance of a trained contrast language-image pre-training (CLIP) model. The generated latent image (bottom right) is presented to a trained VAE to convert it to a high-resolution image, which is the final output (top right).
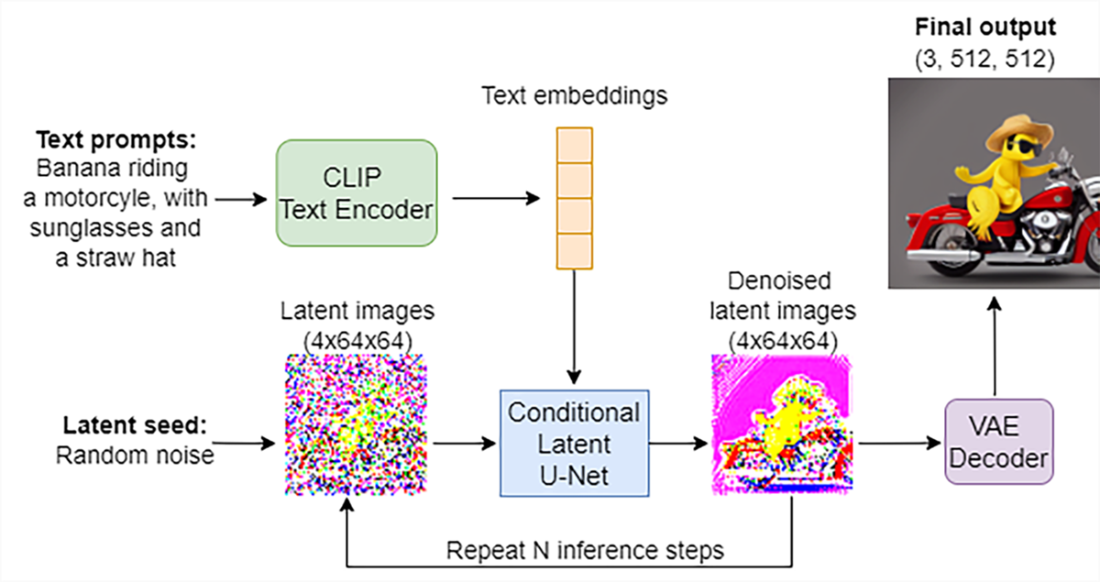
Intermediate decoded outputs from a trained latent diffusion model at time steps 800, 600, ..., 200, and 0. The text prompt is " a banana riding a motorcycle, wearing sunglasses and a straw hat."

The StableDiffusionPipeline package in the diffusers library allows you to use Stable Diffusion as an off-the-shelf tool to generate great images in just a few lines of code. This figure shows the generated image based on the prompt "an astronaut in a spacesuit riding a unicorn."

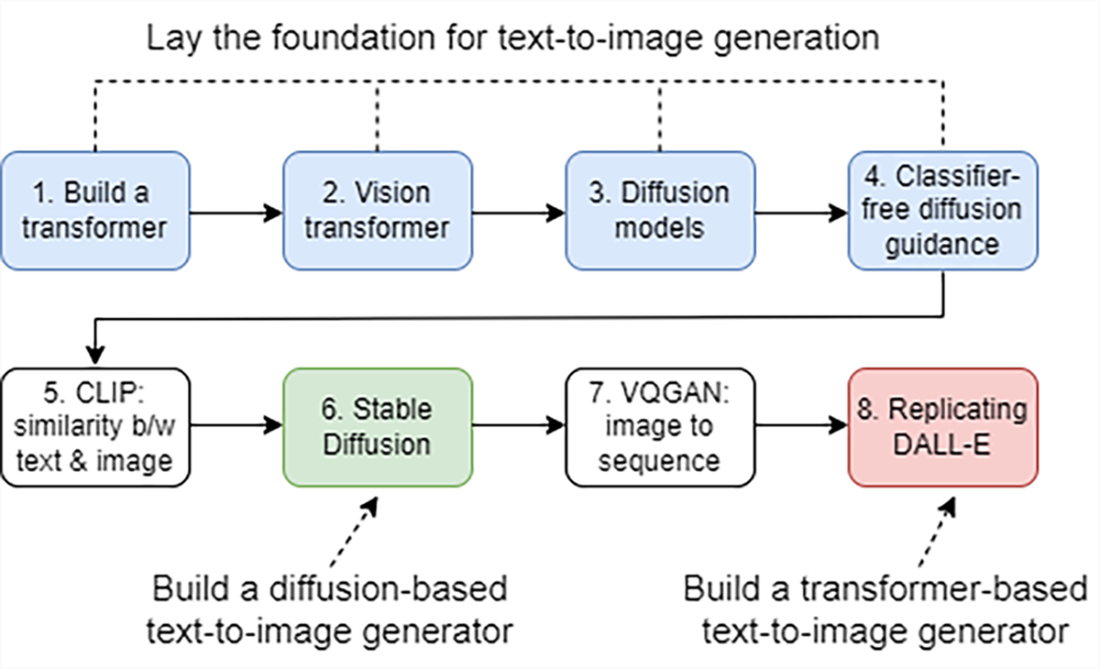
The eight steps to building a text-to-image generator from scratch. Steps 1-4 establish the foundation: you’ll learn to build a transformer, understand how a vision transformer (ViT) processes images, implement a basic diffusion model, and use classifier-free guidance to control image generation. In steps 5-8, you’ll train your own CLIP model to connect images and text, create a diffusion-based generator (such as Stable Diffusion), master the VQGAN architecture for discrete image encoding, and build a transformer-based generator inspired by DALL-E. Each step brings you closer to understanding and creating a text-to-image generator.
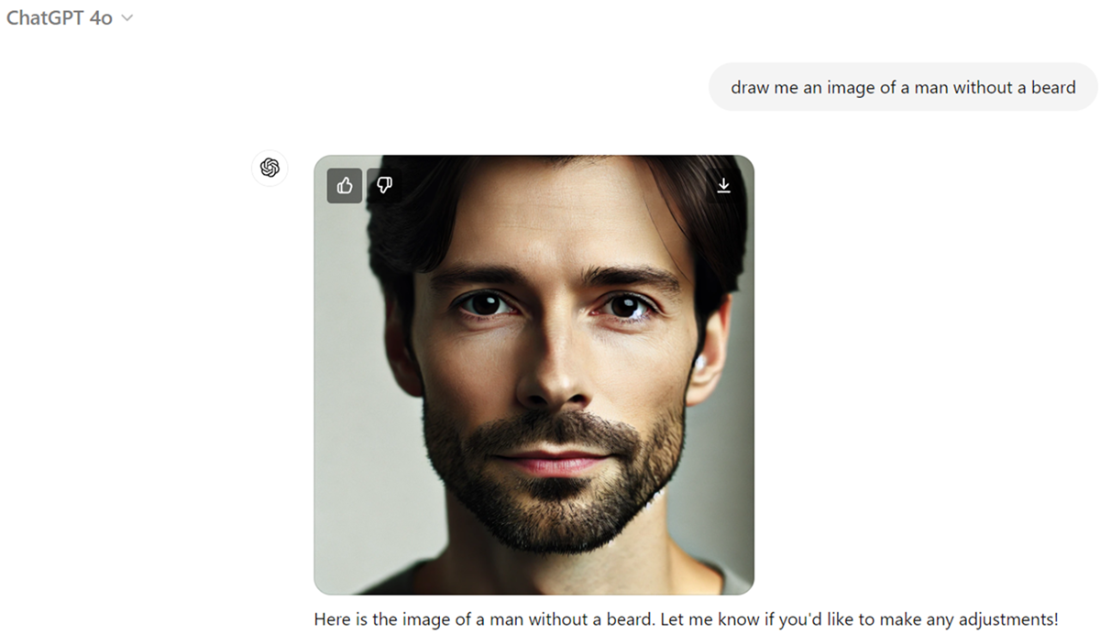
An image generated by ChatGPT 4o using the prompt "draw me an image of a man without a beard."
Summary
- Text-to-image models are a type of multimodal generative model designed to transform a text description into a corresponding image.
- Unimodal models operate within a single type of data modality, such as text-only or image-only models. In contrast, multimodal models connect different data modalities, enabling interactions across text, images, audio, and video.
- Transformer-based text-to-image generation models treat images as sequences by dividing them into patches, each patch acting as an element in the sequence. Image generation is then a sequence prediction problem, where the model predicts patches from top-left to bottom-right based on a text prompt.
- In diffusion-based text-to-image generation models, we start with an image of pure noise. The model iteratively denoises it based on the text prompt, reducing noise with each step until a clear image matching the prompt is produced.
- Instead of conducting forward and reverse diffusion processes on high-resolution images, latent diffusion models (LDMs) conduct diffusion processes in a lower-dimensional latent space, making the process faster and more efficient. After training, a variational autoencoder (VAE) converts the low-resolution latent space images into high-resolution final outputs.
- Despite significant advancements, text-to-image generative models face challenges like the Pink Elephant problem, copyright disputes, geometry inconsistencies, and social, ethical, and environmental concerns.
FAQ
What are text-to-image generation models, and why are they considered multimodal?
Text-to-image models are generative AI systems that take text as input and produce images as output. They are multimodal because they connect two different data types—language (text) and vision (images)—unlike unimodal models that operate within a single modality (for example, text-in/text-out).
How do transformer-based text-to-image models generate images from text?
They reframe image generation as a sequence prediction task:
- Images are encoded into discrete “image tokens” using a model like VQGAN, which turns image patches into indices from a learned codebook.
- Text is turned into “text tokens” using a language transformer (e.g., BART).
- Training aligns the BART decoder’s output with the VQGAN image-token sequence (minimizing cross-entropy), so the model learns to predict image tokens from text.
- At inference, the prompt → BART produces tokens → VQGAN decoder reconstructs the image from those tokens.
What are diffusion models, and how do forward and reverse diffusion work?
Diffusion models learn to denoise. In forward diffusion, small amounts of Gaussian noise are added to a clean image over many steps until it becomes pure noise. A denoising network (often a U-Net) is trained to reverse this process: starting from noise, it removes noise step-by-step to produce a coherent image. Conditioning on text steers the denoising toward images that match the prompt.
What is a latent diffusion model (LDM), and why is it more efficient?
LDMs run diffusion in a low-dimensional latent space instead of pixel space:
- A VAE encoder compresses images into a compact latent representation (e.g., 4×64×64 instead of 3×512×512), cutting computation dramatically.
- The U-Net denoises in this latent space, often guided by a text embedding and a CLIP-based similarity signal.
- A VAE decoder then upsamples the denoised latent to a high-resolution image.
What is Stable Diffusion, and how can I use it quickly?
Stable Diffusion is a popular open-source LDM trained on large-scale image–text pairs. It incorporates training optimizations and broad dataset coverage. You can generate images with just a few lines using the Hugging Face diffusers StableDiffusionPipeline, or explore its internals to customize guidance, sampling steps, and prompts.
What are practical applications of text-to-image models?
- Creative content: art, illustrations, marketing visuals, rapid prototyping.
- Product and game design: concept art, characters, environments, fashion sketches.
- Education and communication: visualizing historical, scientific, or medical concepts.
- ML workflows: data augmentation via synthetic images.
- Related skills you’ll build: image captioning, text–image similarity (CLIP), and image selection/retrieval by prompt.
What is the “pink elephant” problem in text-to-image generation?
It’s a failure with negation (e.g., “a man without a beard” producing a bearded man). Causes include limited handling of negative constraints in training data/objectives, prompt parsing issues, and bias toward frequent co-occurrences. Emerging techniques in prompt conditioning and model training aim to reduce this.
Why do models struggle with geometric consistency?
They’re trained on diverse 2D images and typically don’t learn explicit 3D structure, depth, lighting, or physics. Positional encodings help with spatial order but don’t enforce strict geometric rules. This can yield inconsistent object parts, perspective errors, or impossible configurations. Stronger 3D priors, multi-view data, or physics-informed constraints can help.
Do text-to-image models “steal” from artists or create new works?
Two viewpoints:
- Critique: Models may reproduce elements of copyrighted works in training sets (especially overrepresented images), blurring the line between inspiration and copying.
- Defense: Models learn statistical patterns rather than memorizing; diffusion from noise and recombination of concepts produce novel outputs influenced by, but not duplicative of, training data.
The legal and ethical landscape is still evolving.
What are key social, environmental, and ethical concerns?
- Energy and compute: Training/inference can be resource-intensive; techniques like pruning, quantization, and transfer learning help but don’t eliminate the footprint.
- Misuse: Risk of deepfakes and misinformation calls for guardrails, moderation, and policy collaboration.
- Bias: Models may amplify stereotypes; auditing, dataset curation, and careful mitigation are needed—without overcorrection that distorts facts.
 Build a Text-to-Image Generator (from Scratch) ebook for free
Build a Text-to-Image Generator (from Scratch) ebook for free