6 Training reasoning models with reinforcement learning
This chapter explains how reinforcement learning can improve an LLM’s reasoning ability as a training-time scaling method. It contrasts this with inference-time scaling, noting that both approaches can be combined: a model can first be trained to reason better and then use more compute during generation for further gains. The central idea is that pre-training teaches a model broad knowledge through next-token prediction, while reinforcement learning shapes how the model uses that knowledge by optimizing whole outputs, such as whether an answer is correct.
The chapter compares reinforcement learning with human feedback and reinforcement learning with verifiable rewards. Human-feedback methods rely on human preference rankings to train a separate reward model, which then scores new model outputs during training. Verifiable-reward methods simplify this pipeline by replacing the learned reward model with deterministic checks, such as verifying whether a math answer matches the ground truth in the required format. This makes training cheaper, more reproducible, and easier to scale, although it is mainly applicable to domains where correctness can be automatically checked, such as math and code.
The main implementation focus is training a small reasoning model with verifiable rewards using group relative policy optimization. The process begins by loading a pretrained model and a non-overlapping MATH training subset, then generating multiple sampled answers for each prompt. Each answer receives a binary correctness reward, these rewards are converted into group-relative advantages, and the model computes sequence-level log-probabilities for the generated responses. The GRPO loss reinforces responses that performed better than other rollouts for the same prompt and discourages worse ones, after which a standard PyTorch training loop updates the model, logs metrics, saves checkpoints, and evaluates progress. Even a short training run can unlock strong reasoning behavior, though the chapter notes that the simplified GRPO version can become unstable over longer runs and that later improvements add regularization and stability techniques.
A mental model of the topics covered in this book. This chapter focuses on techniques that improve reasoning with additional training (stage 4). Specifically, this chapter covers reinforcement learning.
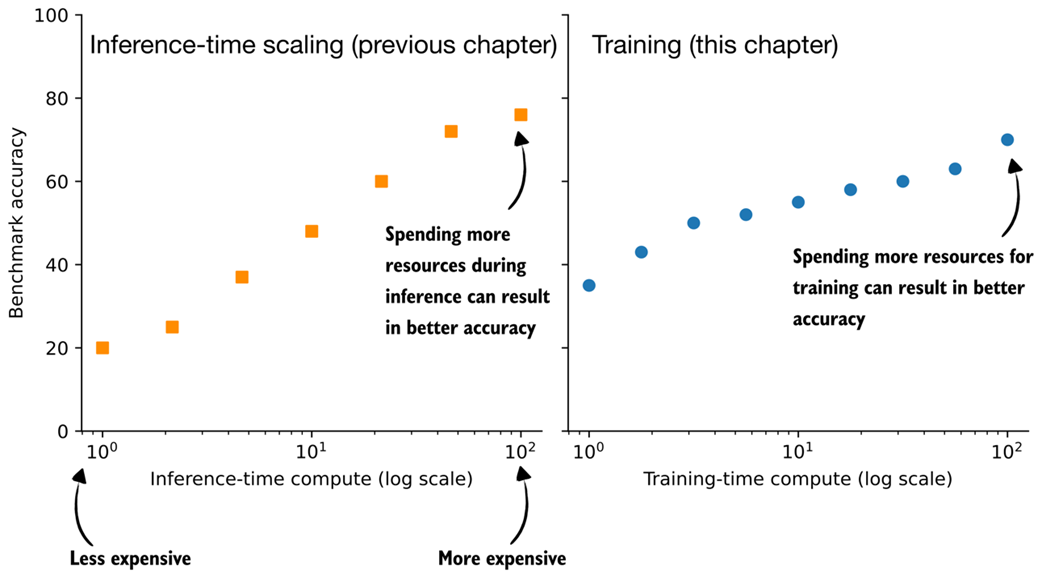
Conceptual comparison of inference-time scaling and training-time scaling. Increasing compute at inference improves accuracy by spending more resources per answer generation, while increasing compute during training improves accuracy by investing more resources upfront.
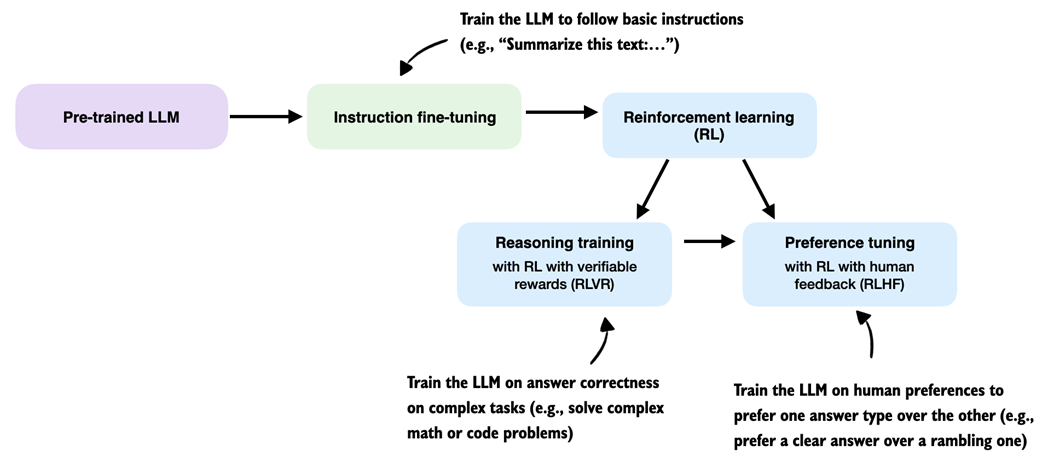
Common training stages for LLMs. The ordering of the reasoning training and preference tuning stages can vary, and some pipelines interleave reasoning and preference tuning rather than strictly sequencing them.
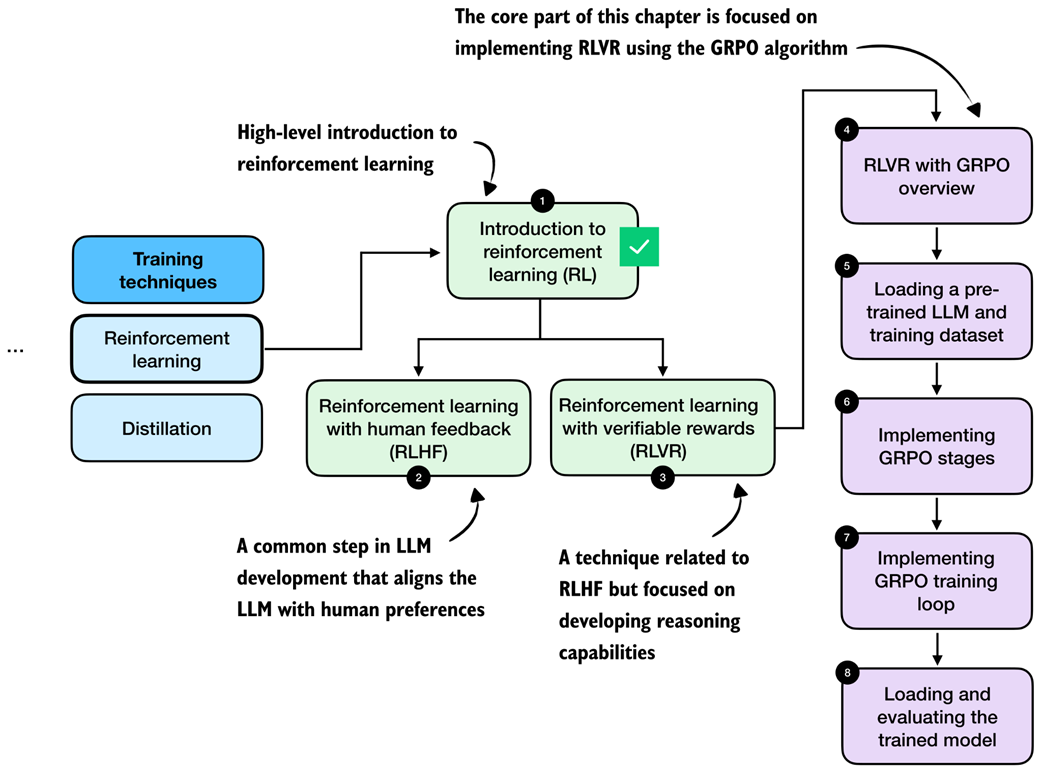
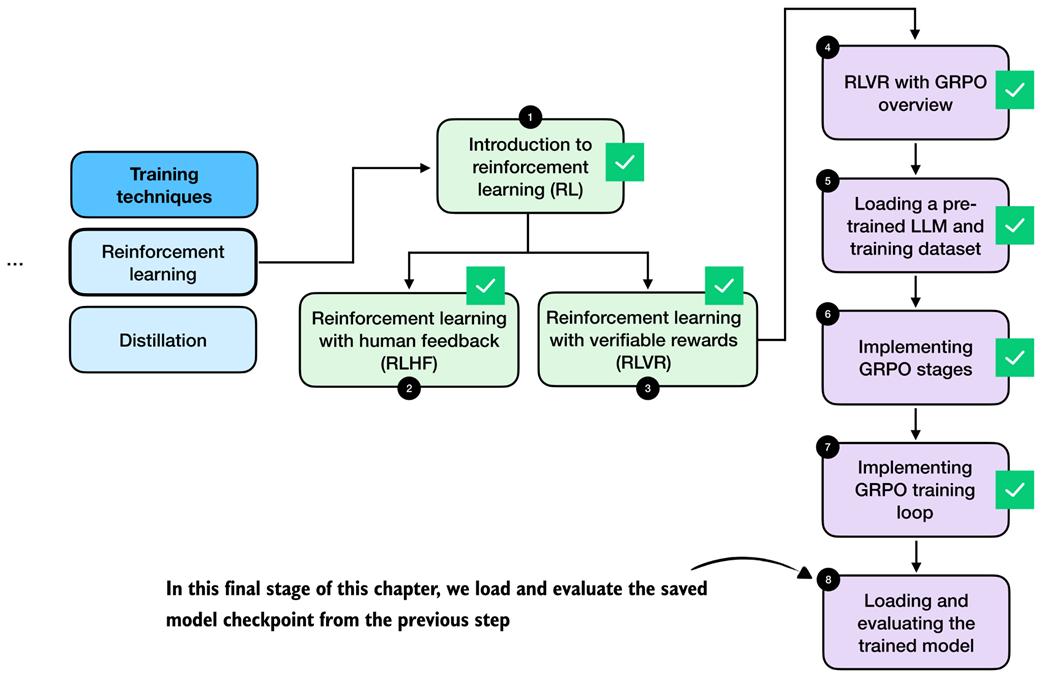
Roadmap of this chapter. After a brief introduction to reinforcement learning (RL) for LLMs in this section, we discuss the difference between two RL stages, RLHF and RLVR, in the next section. Then, we focus on implementing RLVR using the GRPO algorithm in the remainder of this chapter.
Two-stage overview of reinforcement learning with human feedback (RLHF). First, a reward model is trained on human-ranked responses to assign a preference score to each. Second, the LLM is updated using these reward scores within an RL objective to encourage preferred responses and discourage less desirable ones.
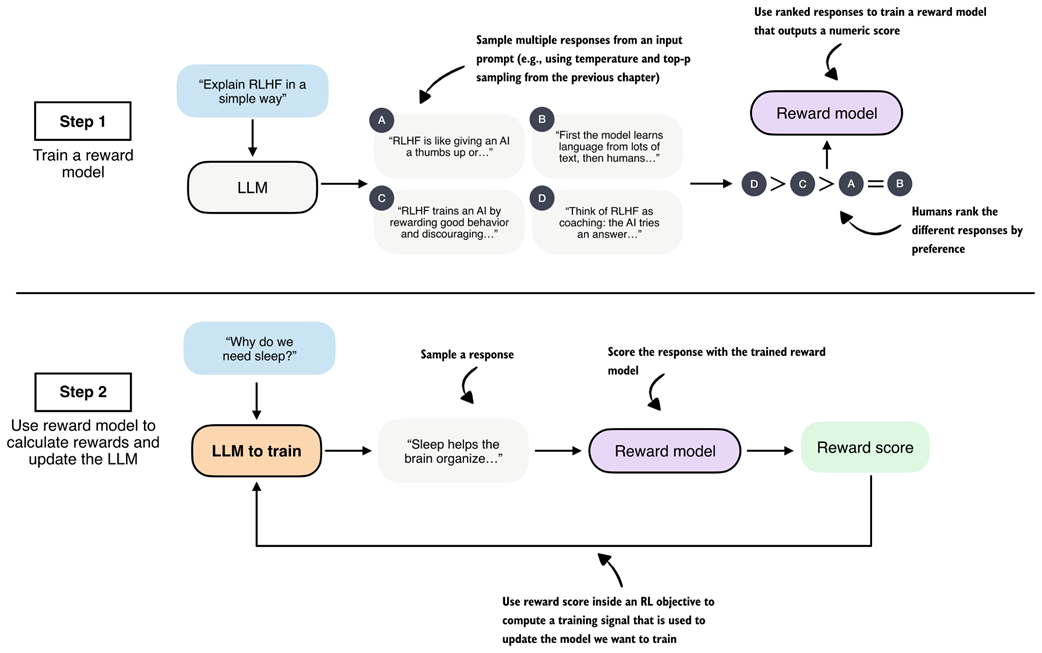
Overview of reinforcement learning with verifiable rewards (RLVR). The LLM generates a response that is evaluated by a deterministic verifier, for example the math verifier from chapter 3, which assigns a correctness label used as a reward signal within an RL objective to update the model.
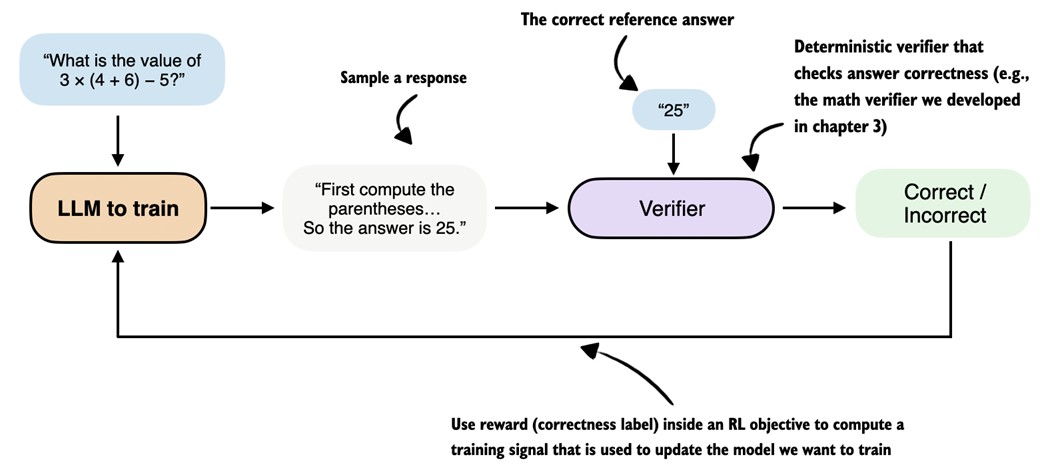
After introducing the two main reinforcement learning approaches for LLMs, RLHF and RLVR, the remaining sections focus on implementing RLVR using the GRPO algorithm, from dataset loading to implementing the full training loop.
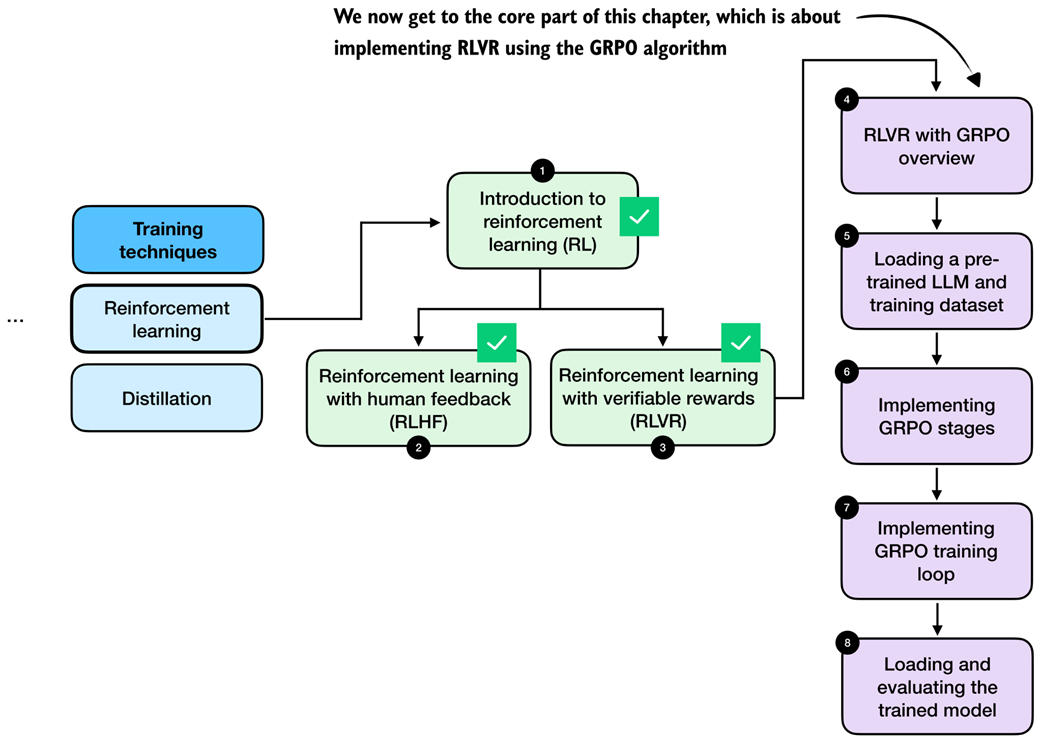
High-level overview of the GRPO algorithm for RLVR using a chef analogy. Multiple rollouts are generated and scored, relative advantages are computed, and a policy gradient objective with a KL-based regularization (loss) term is used to update the model parameters.
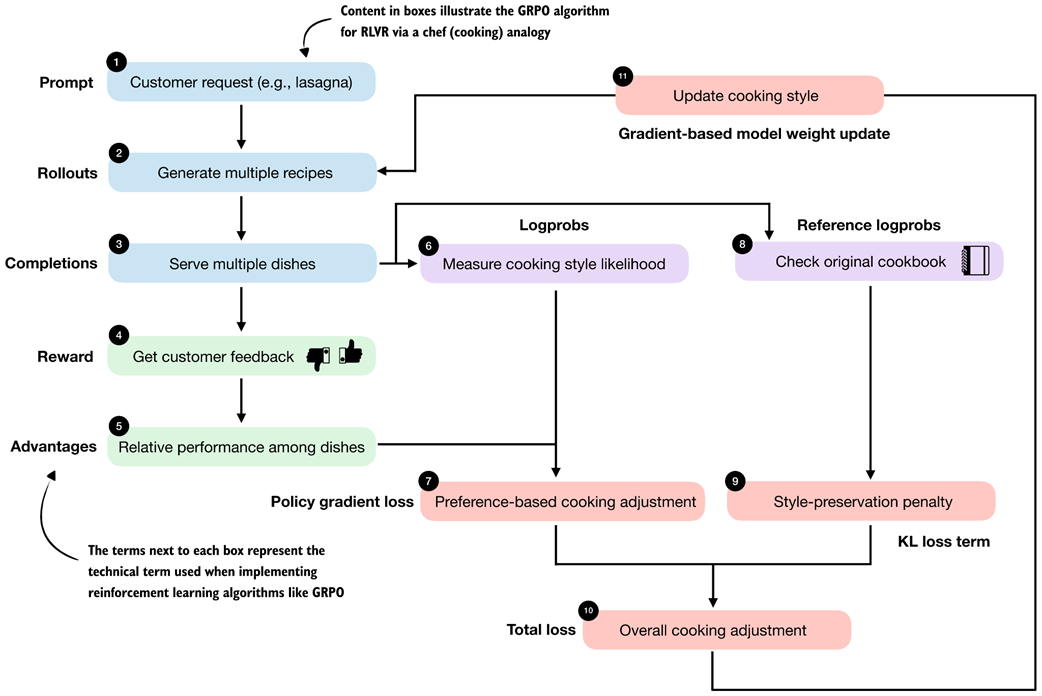
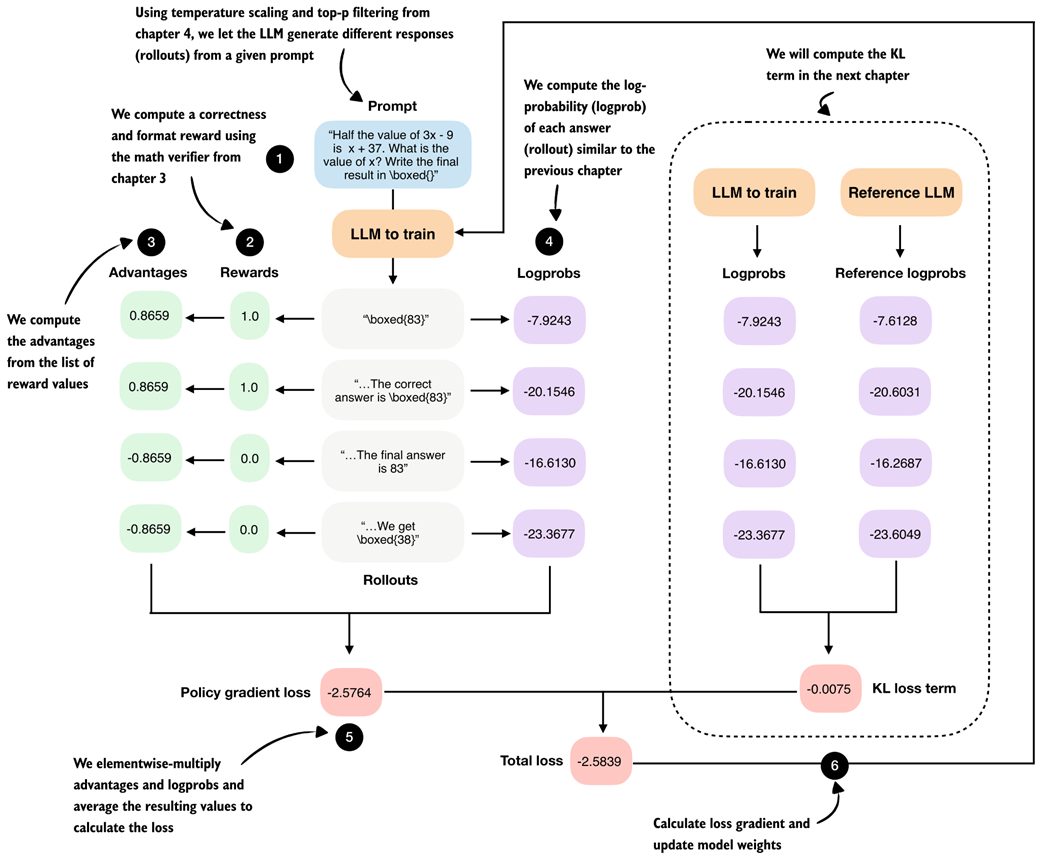
Step-by-step GRPO update for RLVR. (1) A prompt is sampled and multiple rollouts are generated. (2) Each rollout is scored using a verifiable reward. (3) Group-relative advantages are computed from these rewards. (4) The log-probability of each rollout under the current model is calculated. (5) Advantages and log-probabilities are combined to form the policy gradient loss. (6) A KL regularization term against a reference model is added, and the resulting total loss is used to update the model parameters.
In stage 5, we load the pre-trained model (this section) and dataset (next section) that we will use for the model training.
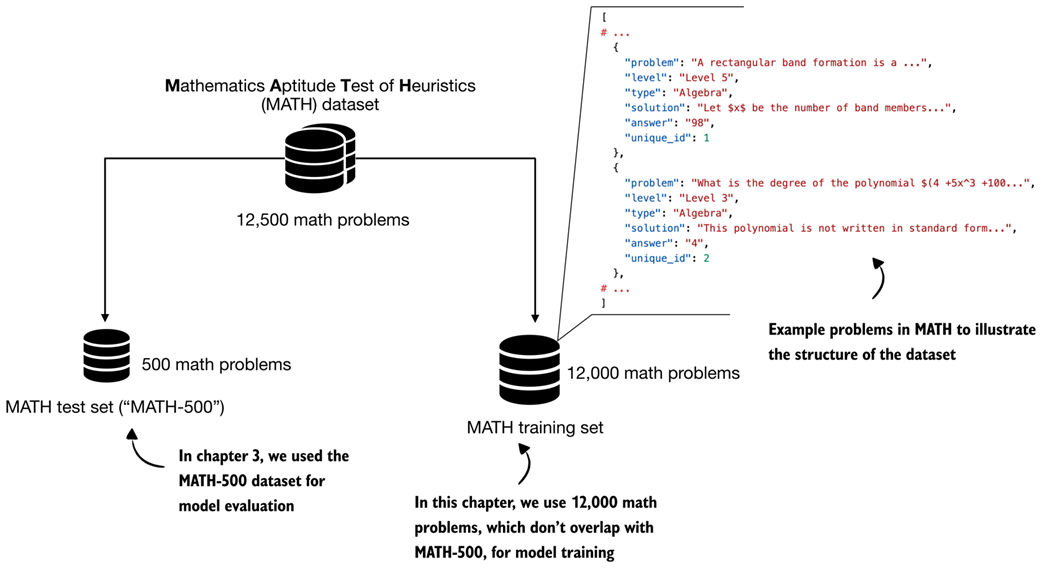
Structure and split of the MATH dataset. The full dataset contains about 12,500 problems that are divided into a 500-problem test set (MATH-500), which we used for model evaluation in chapter 3. A non-overlapping set of 12,000 problems is used for training in this chapter.
After outlining the RLVR method and GRPO algorithm, the following sections implement the individual GRPO stages that we need to train the LLM via verifiable rewards on the MATH dataset.
Step-by-step GRPO update for RLVR (without KL loss term). We begin by prompting the LLM to generate the different rollouts.
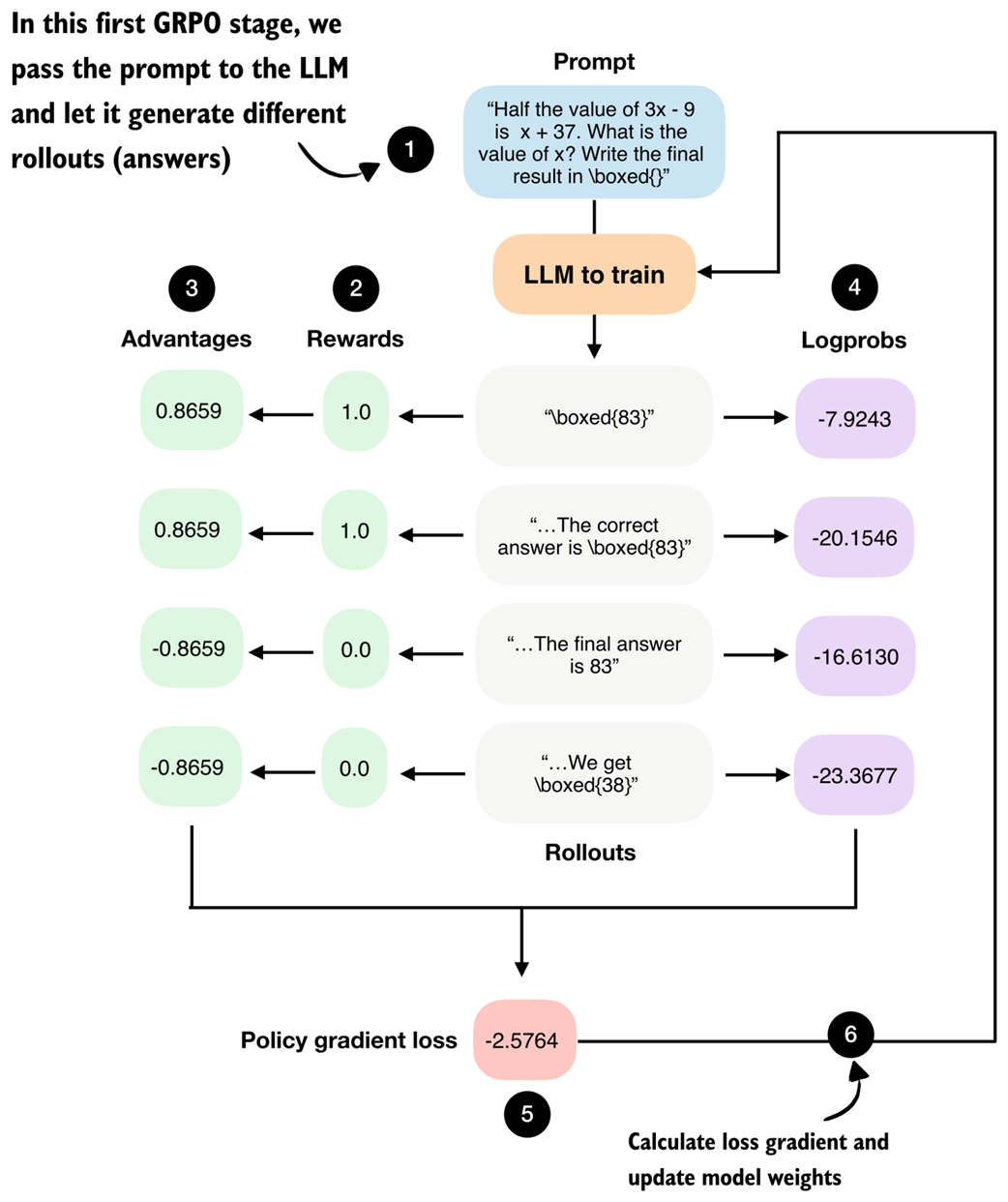
The second stage in the GRPO pipeline computes the rewards for each rollout the LLM generated in the previous section.
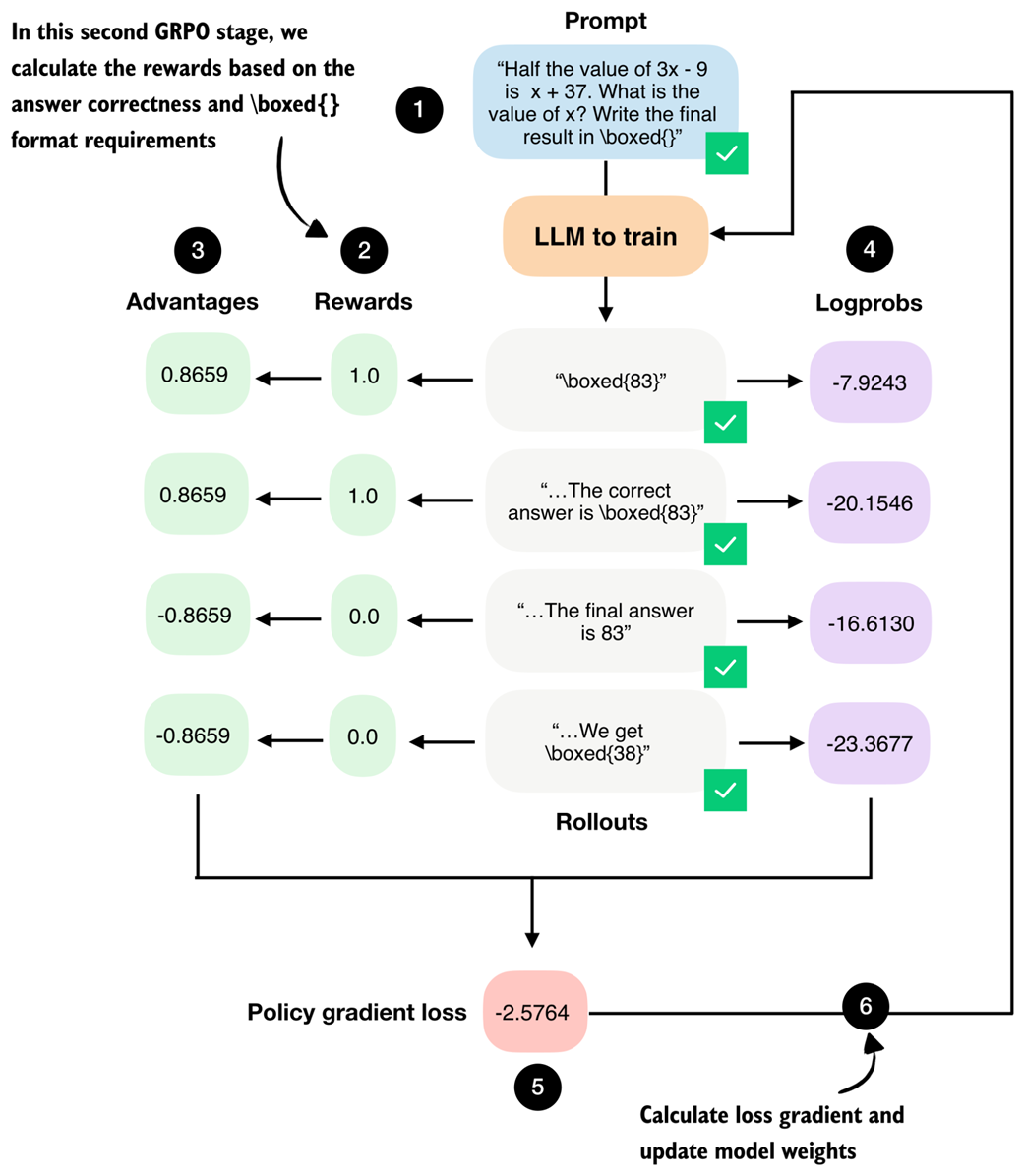
The third GRPO stage computes the advantage values from the answer (rollout) correctness rewards.
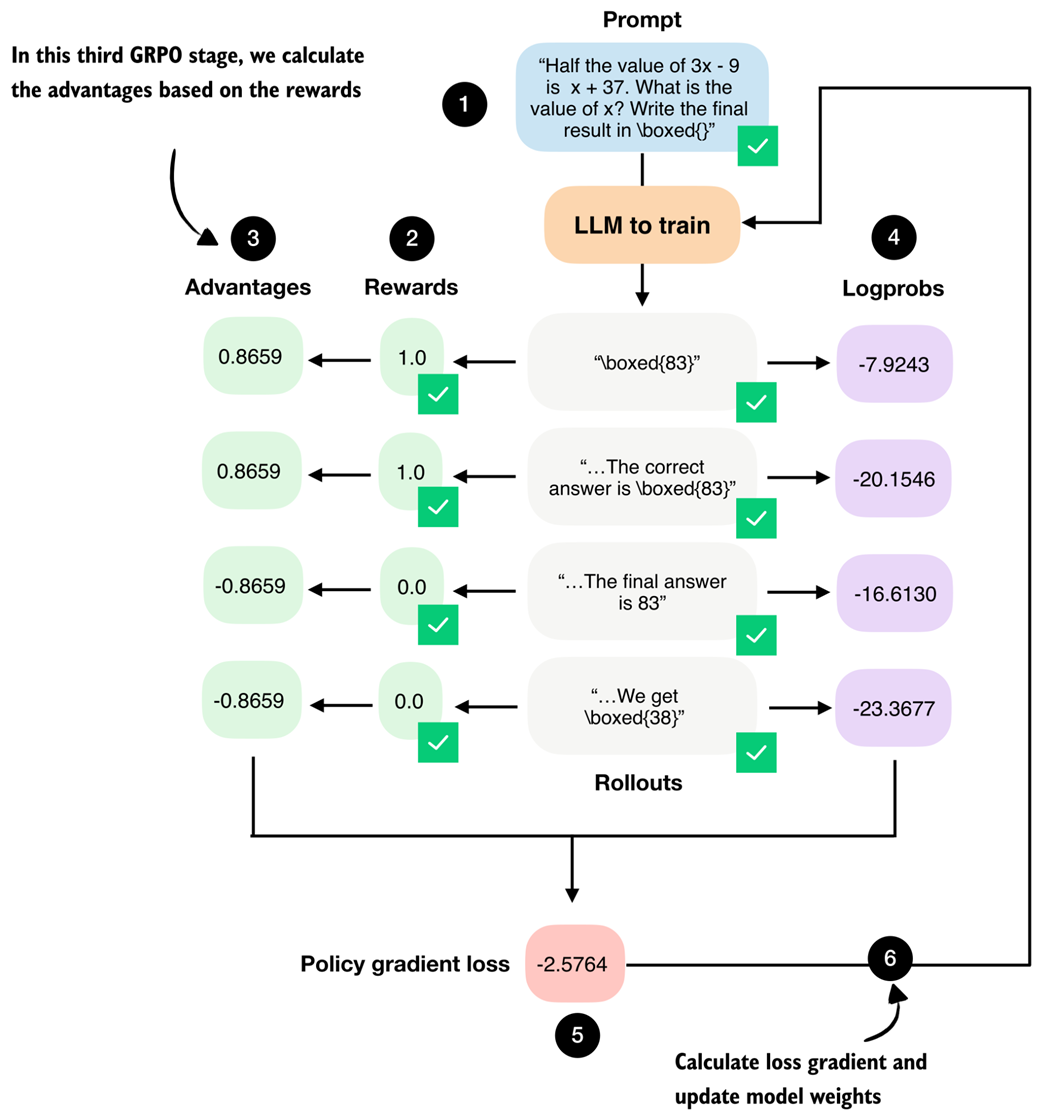
The fourth stage in the GRPO pipeline computes log-probabilities for each rollout, which is related to the logprob scorer we developed in the previous chapter.
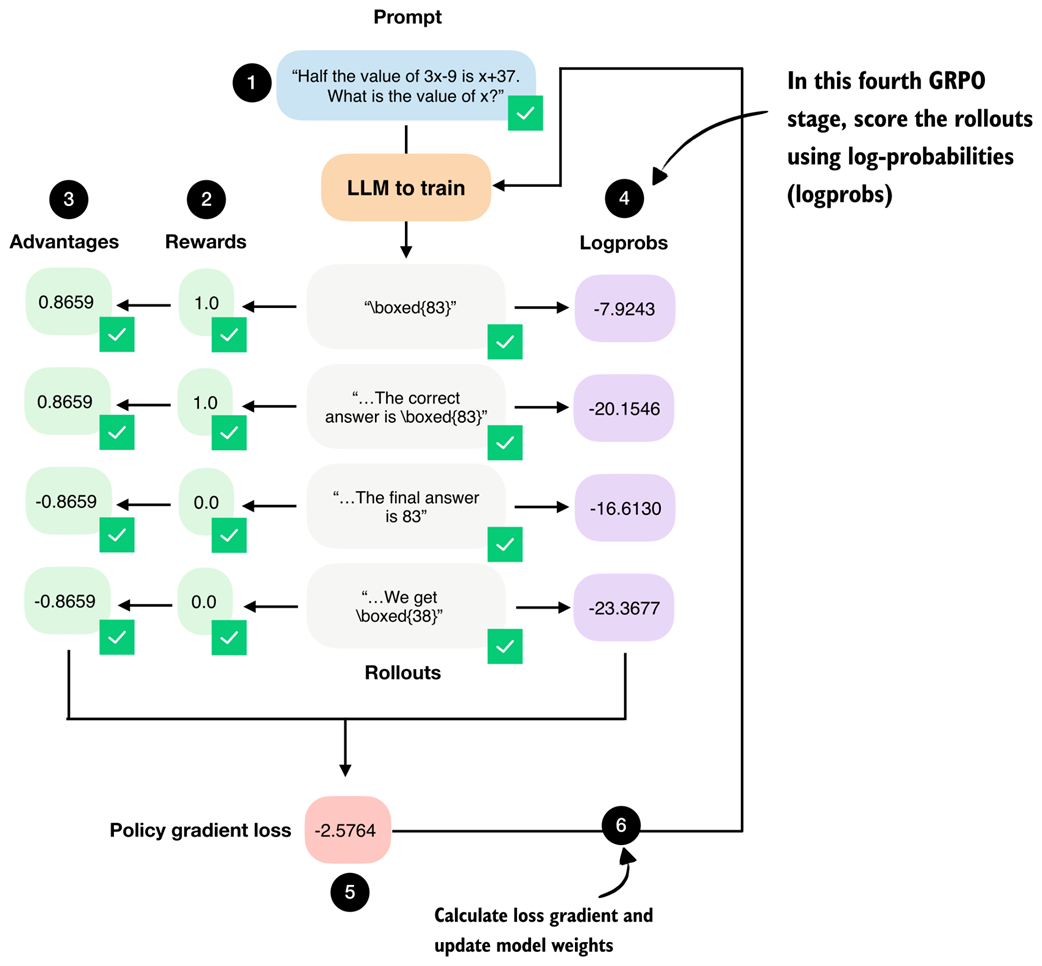
The fifth stage in the GRPO pipeline computes the policy gradient loss that we use to update the model. Stage number 6, the model weight update, will be implemented as part of the training loop later.
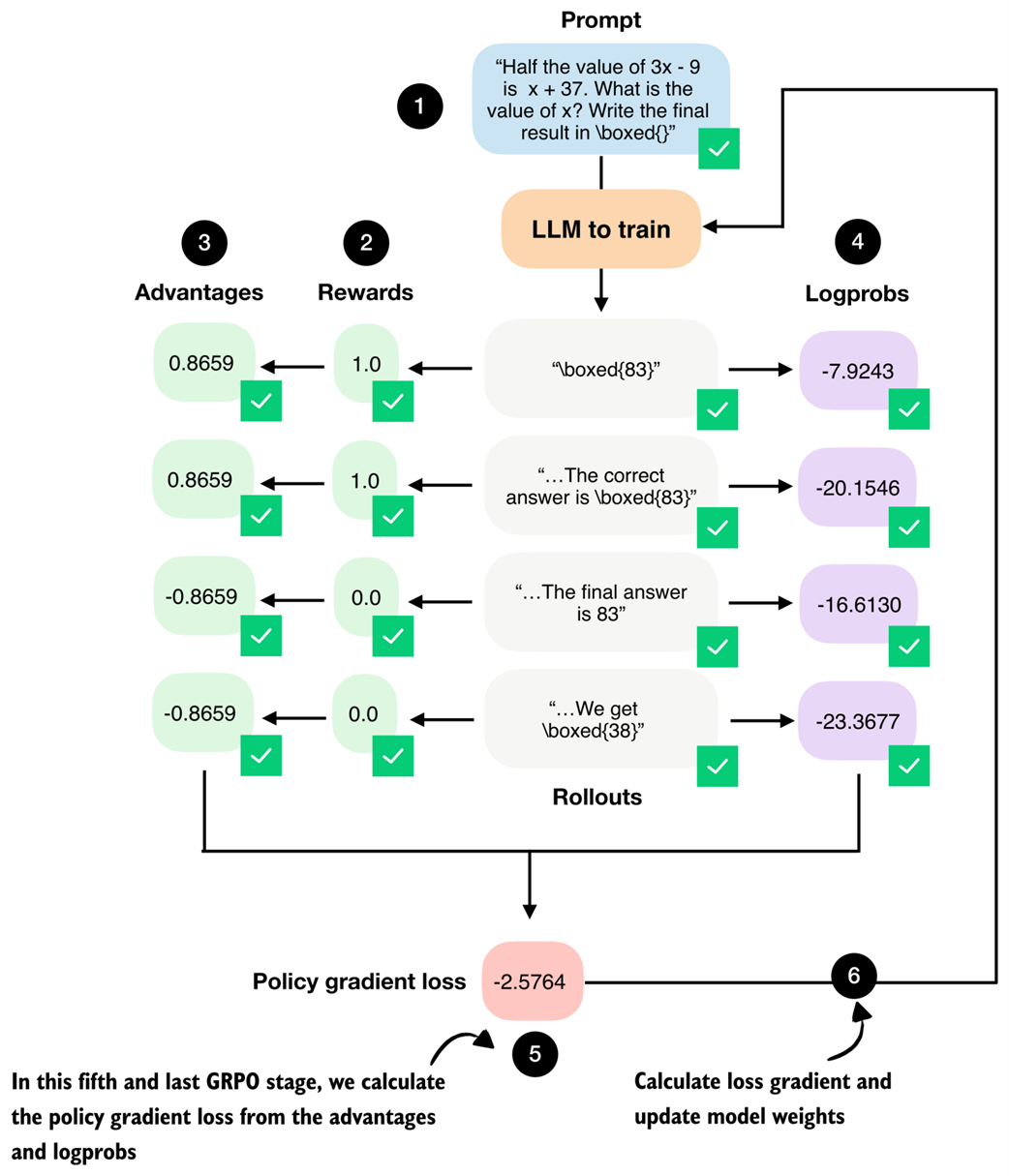
The complete GRPO workflow where (1) multiple rollouts are generated for a prompt, (2) assigned correctness rewards, (3) converted into group-relative advantages, and (4) combined with log probabilities to (5) compute the policy gradient loss. The loss gradients (6) will be computed and used to update the model in the next section.
After implementing the individual GRPO stages, we now implement the surrounding training loop to update the model weights.
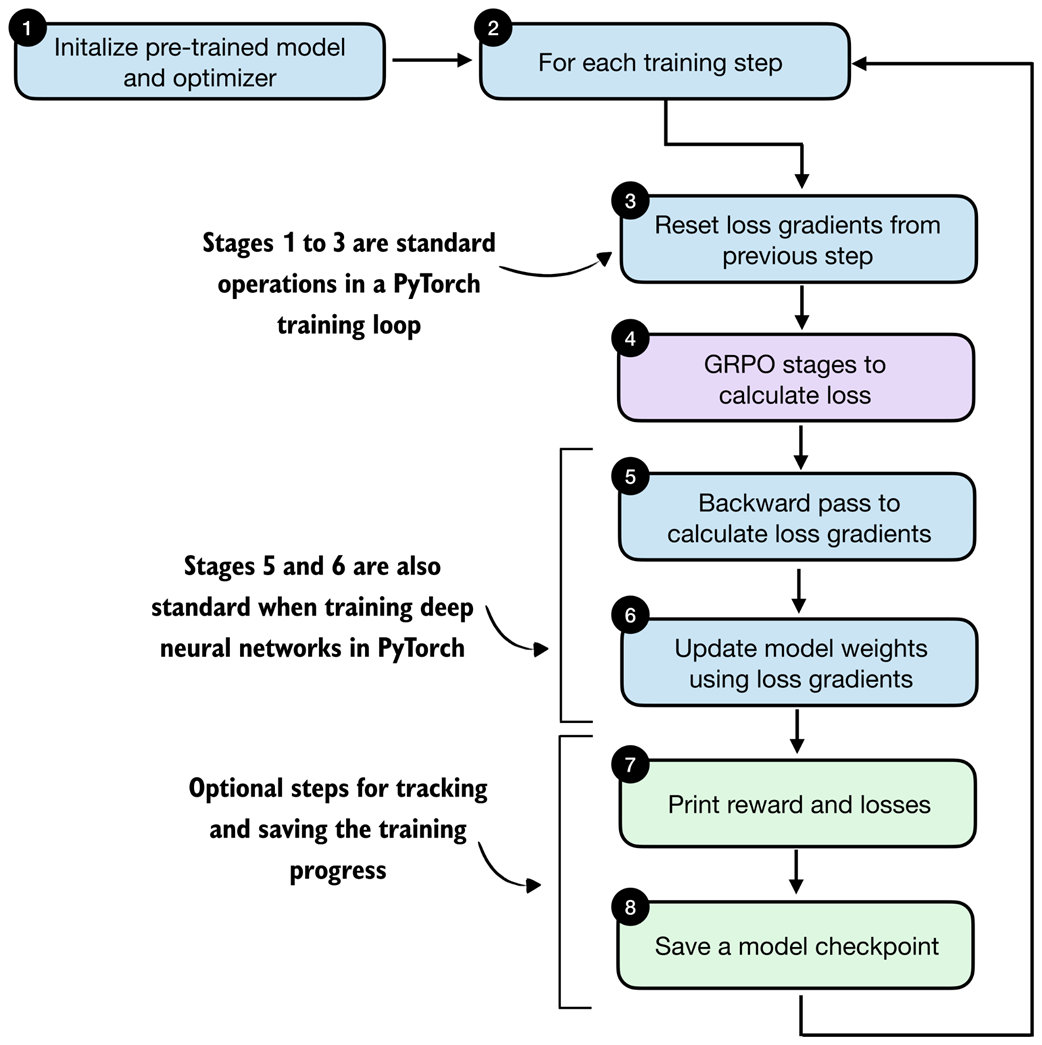
Outline of the training loop. The overall structure follows a standard deep learning training loop. The key difference lies in how the loss is computed: instead of a standard supervised objective, the loss is obtained via the GRPO stages (stage 4).
The final step of this chapter discusses how we can load the saved model checkpoints and evaluate them.
Summary
- Reinforcement learning (RL) can be used to train LLMs on human preference labels and verifiable rewards.
- RL is typically applied as post-training on top of a pre-trained base model, and it can be inserted at different stages of an LLM pipeline, including reasoning training and preference tuning.
- RL with human feedback (RLHF) optimizes for human preferences via a two-stage setup: train a reward model from ranked responses, then use reward scores to update the LLM.
- RL with verifiable rewards (RLVR) simplifies RLHF by replacing learned reward models with deterministic, automatically computed verifiers (for example, math answer checking)
- We focussed on RLVR for math reasoning.
- We used GRPO as the policy optimization algorithm that turns verifier rewards into parameter updates; because GRPO directly optimizes the model using sequence-level rewards without requiring a separate value model, it is particularly convenient.
- GRPO is a more resource-friendly alternative to other RL algorithms for LLMs because it avoids training a separate value model and instead derives learning signals from comparisons within a group of sampled rollouts.
- A "rollout" refers to a full model answer (completion) for a prompt; rewards, advantages, and log-probabilities are computed from the rollout in later steps.
- Rewards are computed from a verifier that only grants a reward if the final answer is both correct and extractable in a required format like "\boxed{}".
- Raw rewards are transformed into advantages by normalizing each rollout reward relative to the group mean and standard deviation.
- GRPO also relies on sequence-level log-probabilities, which are computed by summing token log-probabilities over the generated answer tokens.
- Sequence log-probabilities, together with the advantages, form the core policy-gradient objective in GRPO.
- The full GRPO loss computation is combined into a single function that performs rollout sampling, reward computation, advantage calculation, log-prob computation, and policy-gradient loss calculation.
- The surrounding training loop is a standard deep learning loop, with the key difference being that the loss comes from GRPO rather than conventional classification losses.
- Training is resource-intensive because each step requires generating multiple, potentially long rollouts, but even short GRPO runs can increase MATH-500 accuracy from 15% to 47%.
FAQ
What is the difference between inference-time scaling and training-time scaling for reasoning models?
Inference-time scaling improves accuracy by spending more computation each time the model generates an answer, for example by sampling or searching more during generation. Training-time scaling improves accuracy by investing additional computation during training so the model becomes better before inference. Chapter 6 focuses on training-time scaling through reinforcement learning, although inference-time and training-time scaling can also be combined.
How does reinforcement learning fit into the LLM training pipeline?
For LLMs, reinforcement learning is usually applied as a post-training stage on top of a pretrained model, often after instruction fine-tuning. Two common RL stages are reasoning training and preference tuning. Reasoning-focused RL can also be applied directly to a pretrained base model, as demonstrated by DeepSeek-R1-Zero, which makes it easier to attribute improvements specifically to reasoning training.
What is reinforcement learning with human feedback (RLHF)?
RLHF is a training approach that uses human preference labels to shape model behavior. Human annotators rank multiple model responses to the same prompt, and those rankings are used to train a reward model. The reward model then scores new outputs, and the LLM is fine-tuned with reinforcement learning to produce responses that receive higher preference scores.
What is reinforcement learning with verifiable rewards (RLVR)?
RLVR replaces the learned reward model used in RLHF with deterministic verifiers. For example, in math tasks, a verifier checks whether the model’s final answer matches the ground truth and assigns a reward such as 1 for correct and 0 for incorrect. This removes the need for human annotation or a separate reward model, but it requires domains where reliable verification is possible, such as math or code.
Why is RLVR simpler than RLHF?
RLHF typically requires two stages: training a reward model from human preferences, then using that reward model to train the target LLM. RLVR collapses this into a single loop: the model generates responses, a deterministic verifier assigns rewards, and those rewards are used directly to update the model. This makes RLVR cheaper, more reproducible, and easier to scale when reliable verification signals are available.
What is GRPO, and why is it used in this chapter?
GRPO stands for group relative policy optimization. It is a policy optimization algorithm used to update the LLM’s weights from RLVR rewards. Unlike PPO, GRPO does not require a separate value model. Instead, it samples multiple responses for the same prompt and compares their rewards relative to each other, which makes it more resource-friendly for reasoning-model training.
What does “group relative” mean in GRPO?
The “group relative” part means that the model generates multiple rollouts, or complete responses, for the same prompt. Each rollout receives a reward, and those rewards are converted into advantages by comparing each reward to the group mean and standard deviation. This tells the model which responses were better or worse than the other responses generated for the same prompt.
How are rewards computed for math problems in the chapter’s RLVR setup?
Rewards are computed with a math verifier. The verifier extracts the model’s final answer and compares it with the ground-truth answer. In the chapter’s implementation, an answer receives 1.0 only if it is correct and uses the required \boxed{} format. Otherwise, it receives 0.0. This encourages the model to produce both correct and properly formatted answers.
Why does GRPO convert rewards into advantages?
Rewards indicate how well individual rollouts performed, while advantages indicate how each rollout performed relative to the other rollouts for the same prompt. Positive advantages increase the likelihood of the actions that produced a rollout, negative advantages decrease their likelihood, and near-zero advantages contribute little to the update. If all rollouts receive the same reward, the advantages become zero and GRPO produces little or no learning signal.
How does the GRPO training loop update the model?
The training loop generates multiple rollouts for a prompt, scores them with verifiable rewards, converts rewards into group-relative advantages, computes sequence-level log-probabilities for the rollouts, and combines advantages with log-probabilities into a policy gradient loss. PyTorch then performs a backward pass, optionally clips gradients for stability, and updates the model weights with an optimizer such as AdamW. The chapter’s simplified implementation omits the KL regularization term, which is added in the next chapter.
 Build a Reasoning Model (From Scratch) ebook for free
Build a Reasoning Model (From Scratch) ebook for free