4 Improving reasoning with inference-time scaling
This chapter shows how to boost a model’s reasoning at inference time—without retraining—by spending more compute when generating answers. It introduces two practical techniques: prompting the model to write out its reasoning (chain-of-thought) and sampling multiple responses to select a consensus answer (self-consistency). The author extends a flexible text-generation wrapper so different decoding strategies can be swapped in, then demonstrates that even a simple base model that initially answers a math problem incorrectly can be steered toward the correct result by eliciting step-by-step reasoning. The core trade-off is emphasized throughout: higher accuracy usually comes from generating more tokens and/or more samples, increasing latency and cost, and not every task or model benefits uniformly (overthinking and model-specific behavior can appear).
The chapter builds the sampling tools needed for diverse but coherent candidates. It first reviews next-token selection (logits → probabilities → token) and adds temperature scaling to control diversity: lower temperature sharpens the distribution (more deterministic), higher temperature flattens it (more exploratory). To keep exploration sensible, it implements top-p (nucleus) sampling, which filters out low-probability tokens by keeping only the smallest set whose cumulative probability mass reaches a threshold p, then renormalizes before sampling. These mechanisms are integrated into the streaming generation function, along with guidance on practical settings (e.g., moderate temperatures and typical top-p cutoffs) to balance variety with relevance.
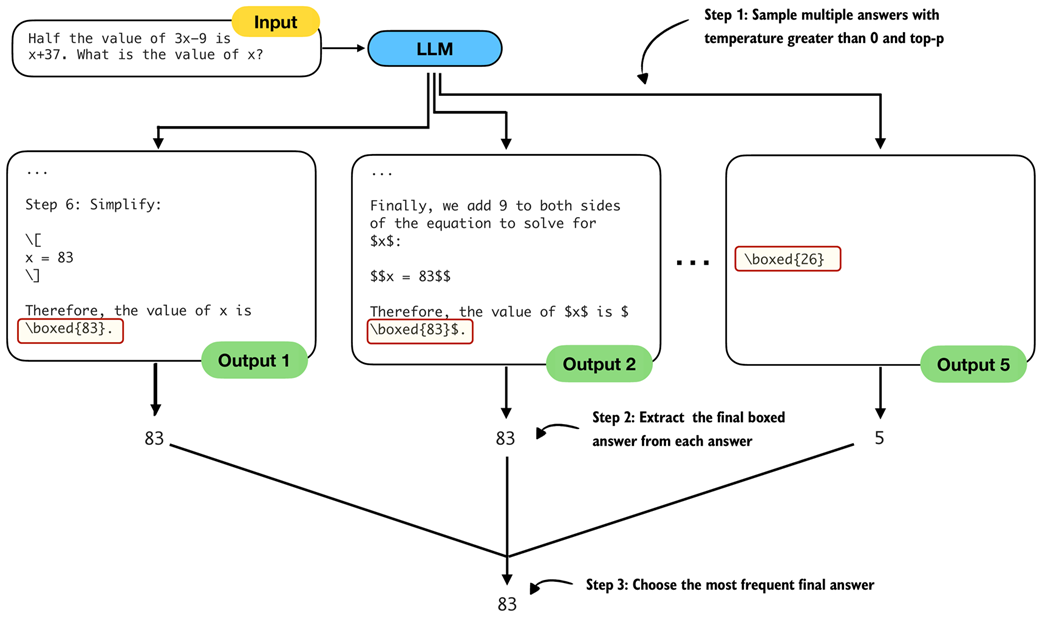
With these pieces in place, the chapter implements self-consistency: generate several answers with temperature and top-p, extract the final boxed result from each, then take a majority vote. On MATH-500, chain-of-thought alone can lift the base model dramatically (from around 15% to about 41% accuracy), whereas temperature+top-p by itself yields modest gains; adding self-consistency raises the base model further into the low 30% range, and combining chain-of-thought with self-consistency can surpass 50%—at a substantial runtime cost that scales with the number and length of samples. A reasoning-tuned model also benefits (roughly 48% to 55% with voting). The chapter closes by noting that voting works best when short, extractable answers are available, and previews the next chapter’s more general inference-time method: iterative self-refinement.
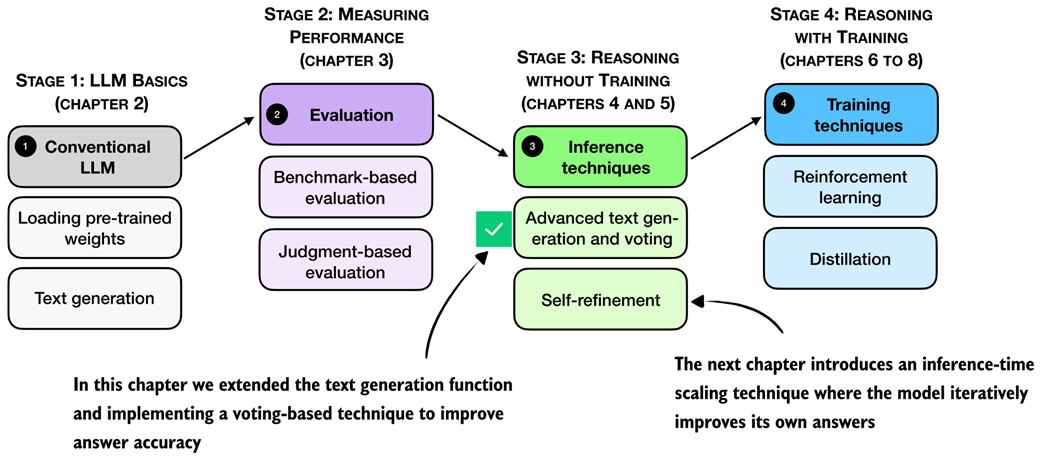
A mental model of the topics covered in this book. This chapter focuses on techniques that improve reasoning without additional training (stage 3). In particular, it extends the text-generation function and implements a voting-based method to improve answer accuracy. The next chapter then introduces an inference-time scaling approach where the model iteratively refines its own answers.
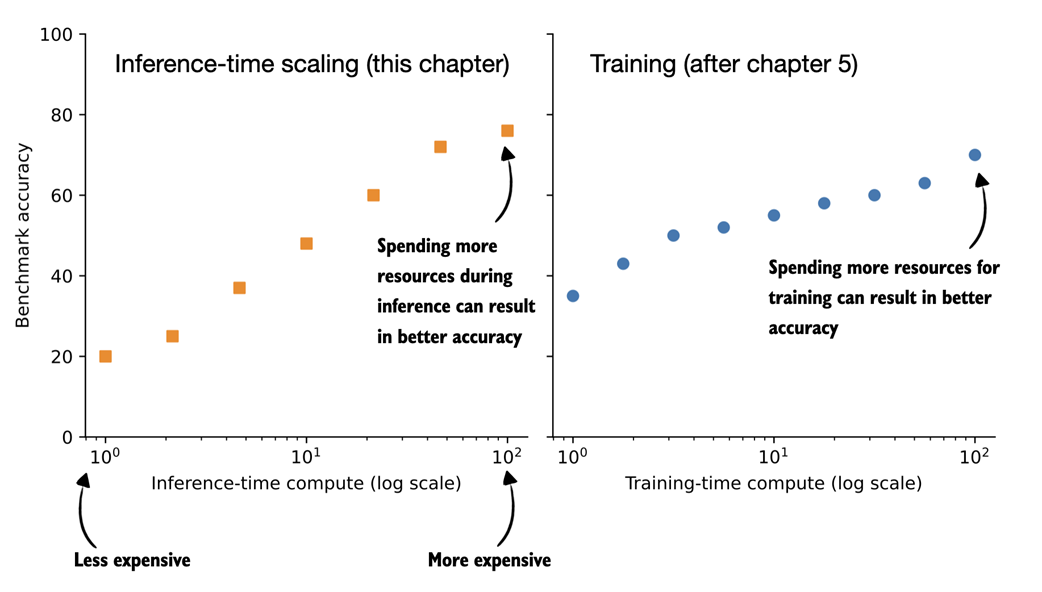
Comparing inference-time scaling (this chapter) and training-time scaling (after chapter 5). Both improve accuracy by using more compute, but inference-time scaling does this on the fly, without changing the model's weight parameters. The plots are inspired by OpenAI's article introducing their first reasoning model (https://openai.com/index/learning-to-reason-with-llms/).
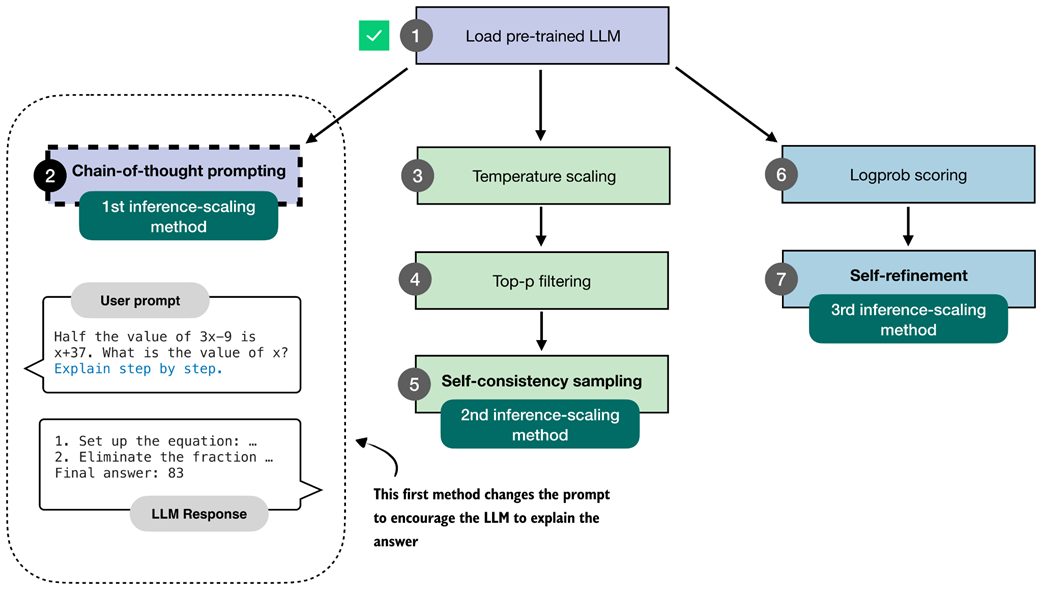
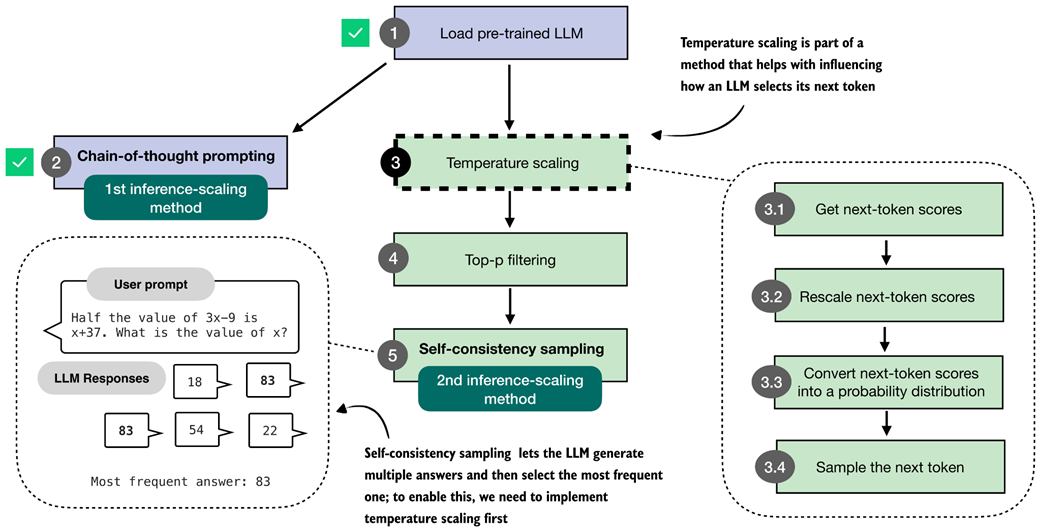
Overview of three inference-time methods to improve reasoning covered in this book. The first modifies the prompt to encourage step-by-step reasoning, and the second samples multiple answers and selects the most frequent one. Both are discussed in this chapter. The third method, in which the model iteratively refines its own response, is introduced in the next chapter.
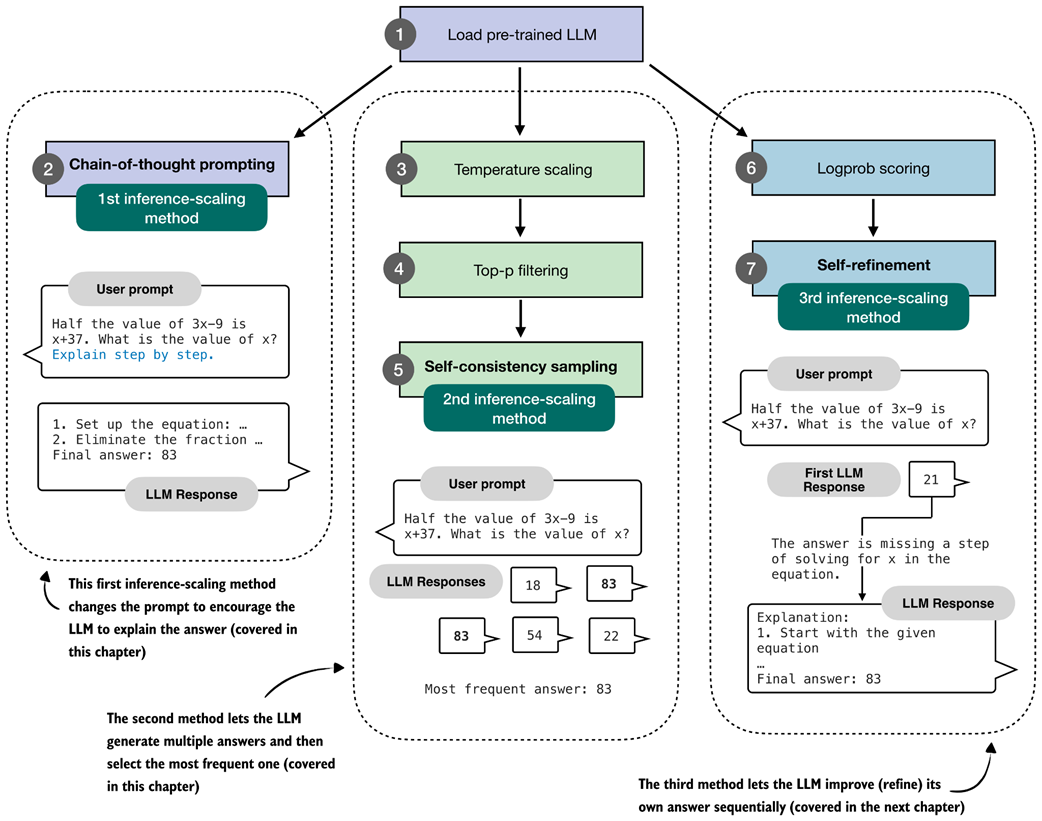
The first inference-time method, chain-of-thought prompting, modifies the prompt to encourage the model to explain its reasoning step by step before producing a final answer.
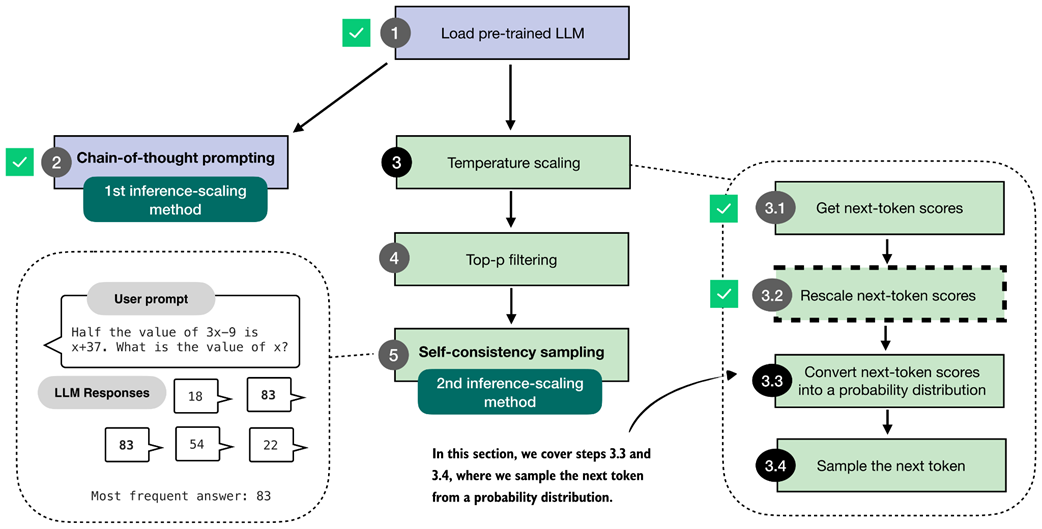
The second inference-time method, self-consistency sampling, generates multiple answers and selects the most frequent one. This method relies on temperature scaling, covered in this section, which influences how the model samples its next token.
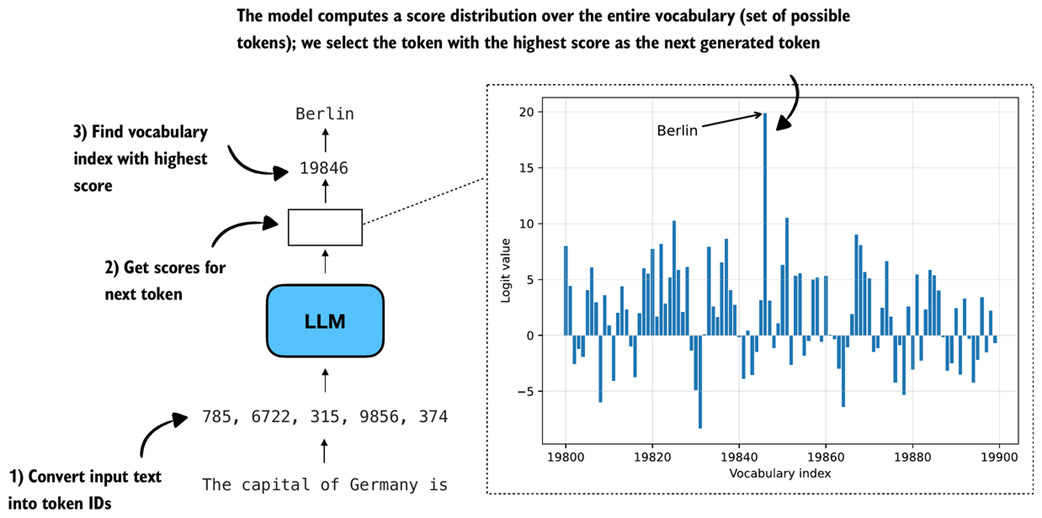
How an LLM generates the next token. As in the other process diagrams in this book, the flow runs from bottom to top. The model converts the input into token IDs, computes scores for all possible next tokens, and selects the one with the highest score as the next output.
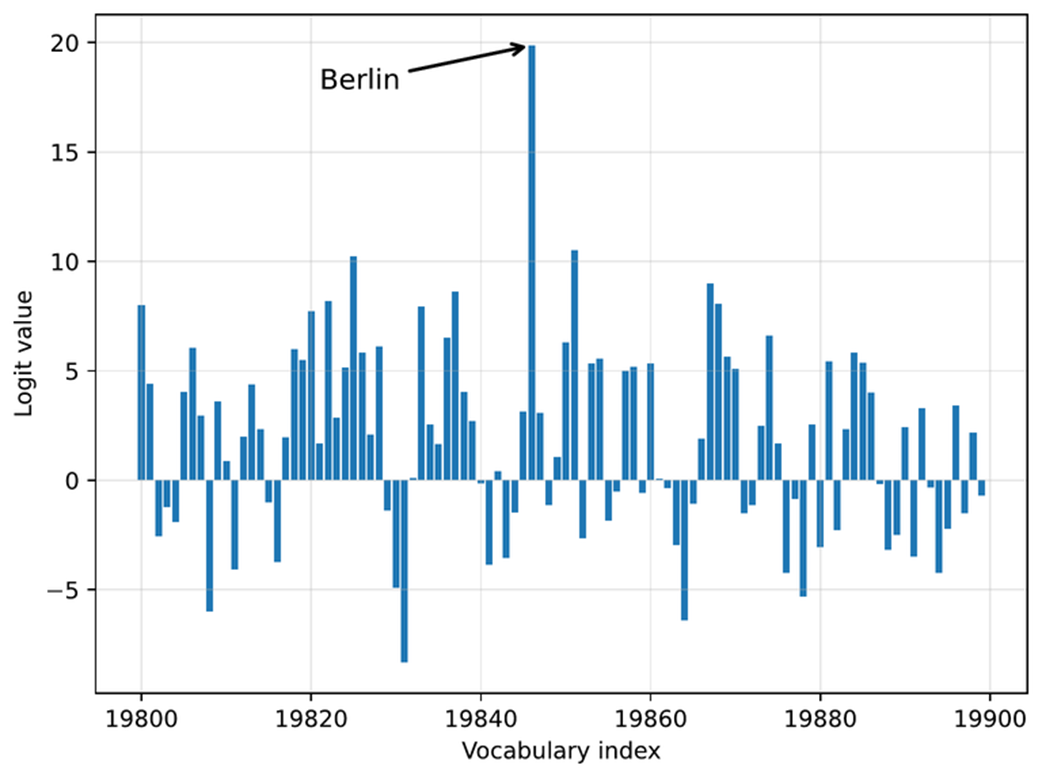
Example of next-token logits for a 100-token slice of a language model's much larger vocabulary. Each bar represents one possible token's score within this slice, with "Berlin" having the highest logit value and being selected as the next token.
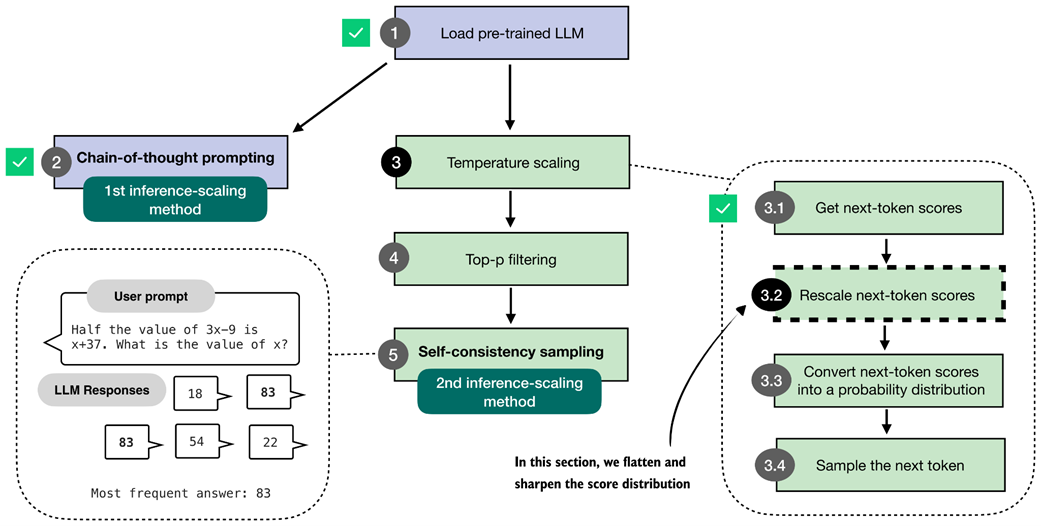
In this section, we implement the core part of temperature scaling (step 3.2), which adjusts the next-token scores. This allows us to control how confidently the model selects its next token in later steps.
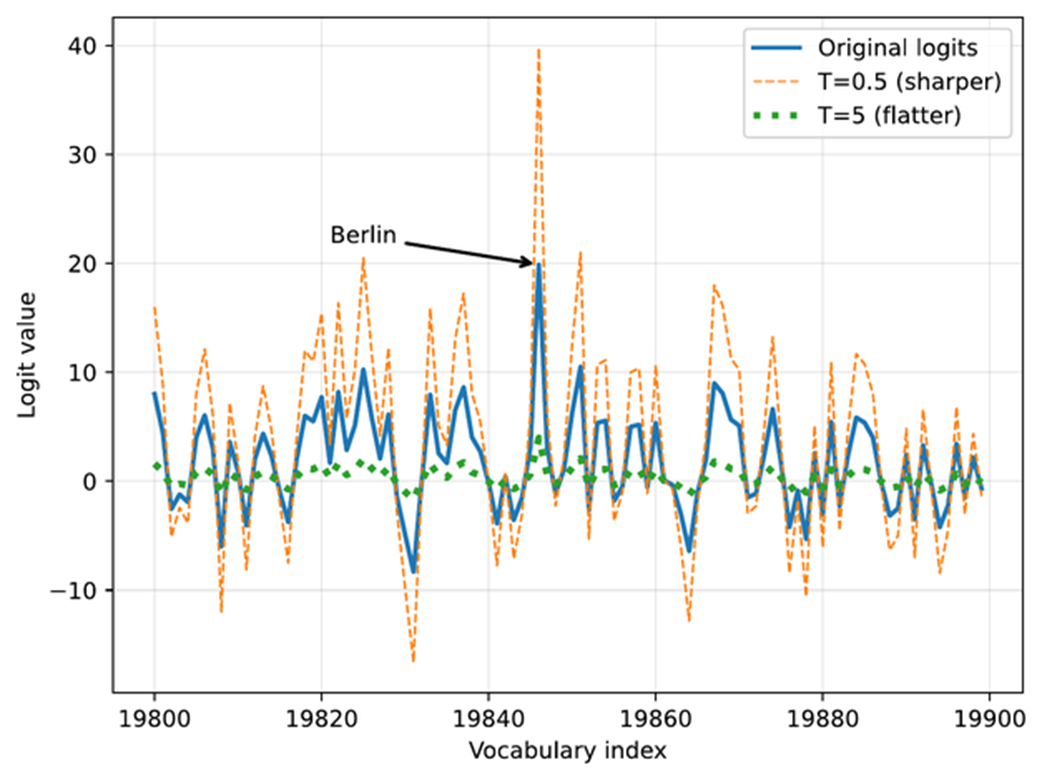
The effect of temperature scaling on logits. Lower temperatures make the distribution sharper, while higher temperatures flatten it. (Please note that this visualization is shown as a line plot for readability, though a bar plot would more accurately represent the discrete vocabulary scores.)
Overview of the sampling process for generating tokens. In this section, we focus on steps 3.3 and 3.4, where the next-token scores are converted into a probability distribution, and the next token is sampled based on that distribution.
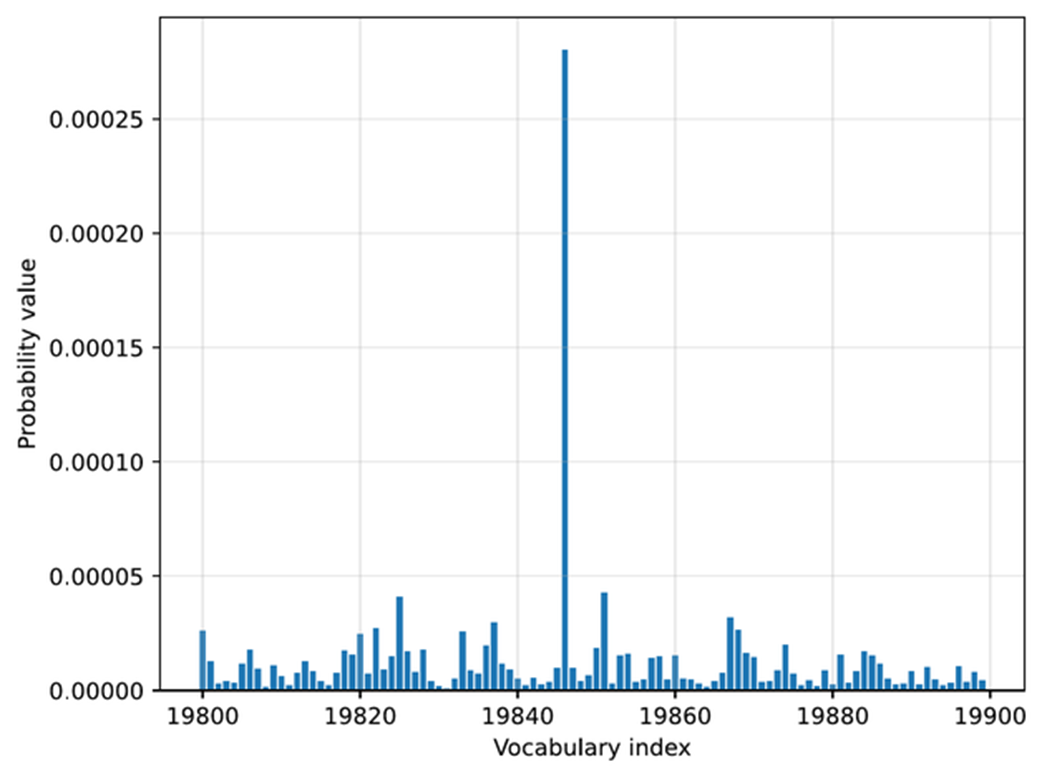
Token probabilities obtained by applying the softmax function to the rescaled logits. The token of the highest probability (corresponding to " Berlin", but with the label omitted for code simplicity) is selected as the next output.
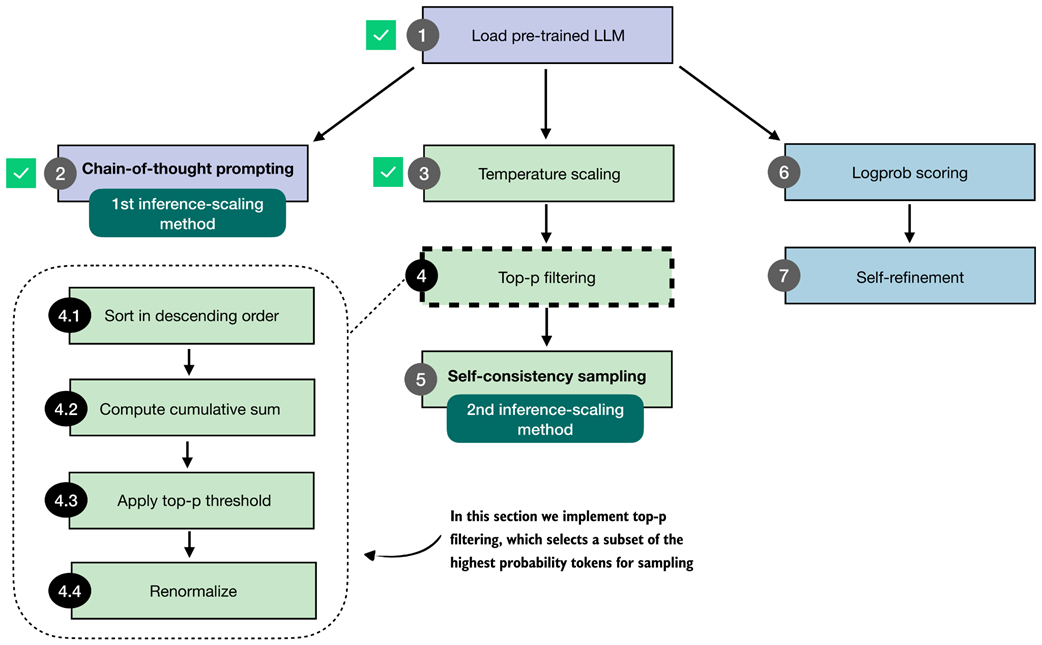
Overview of the top-p filtering process. The filter keeps only the highest-probability tokens by sorting them, applying a cumulative cutoff, selecting the top-p subset, and renormalizing the result.
Example of token probabilities before top-p filtering. The distribution includes many low-probability tokens, which will later be truncated by applying a cumulative probability threshold.
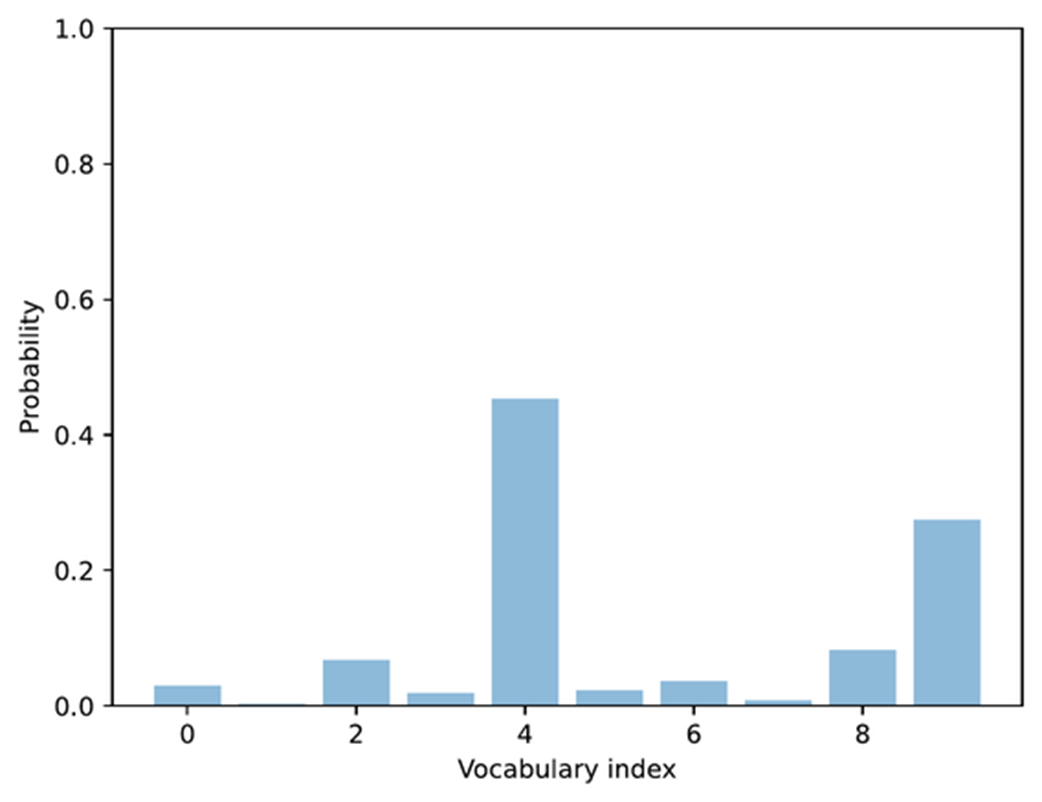
Visualization of sorted token probabilities and their cumulative sum. This step prepares for top-p filtering by showing how probabilities accumulate when ordered from highest to lowest, which helps determine where to set the cutoff threshold.
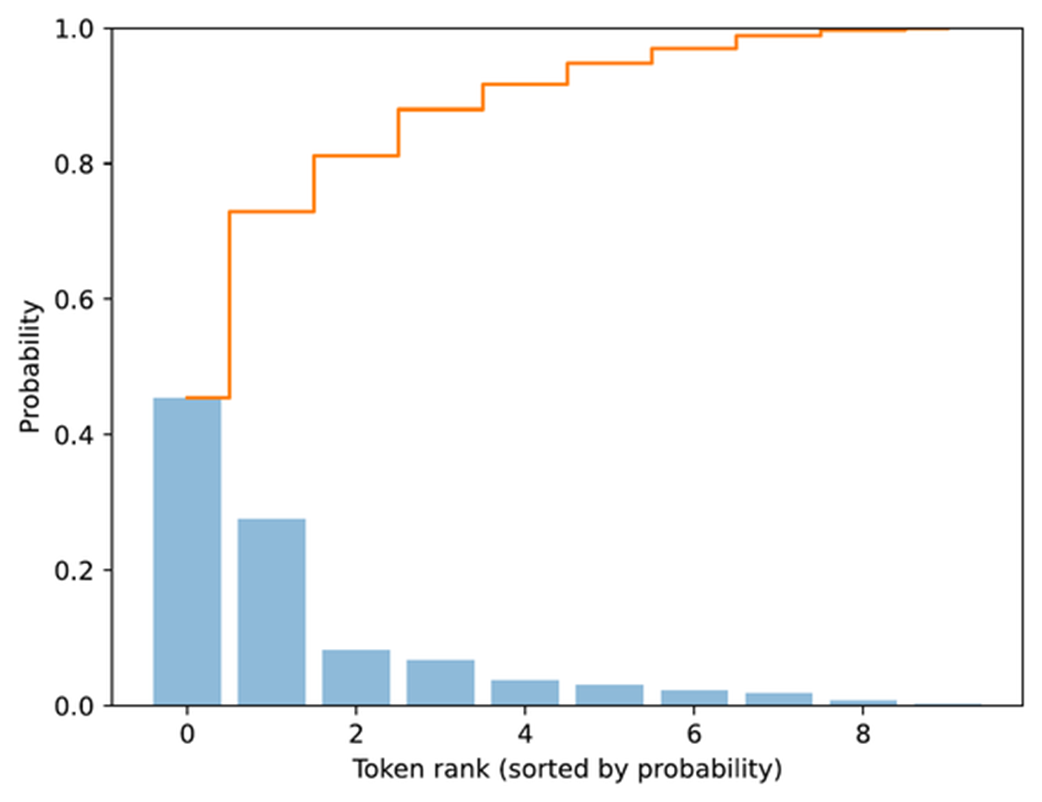
Top-p (nucleus) filtering. Tokens are sorted by probability, and the smallest subset whose cumulative probability exceeds the threshold (p = 0.8) is kept for sampling.
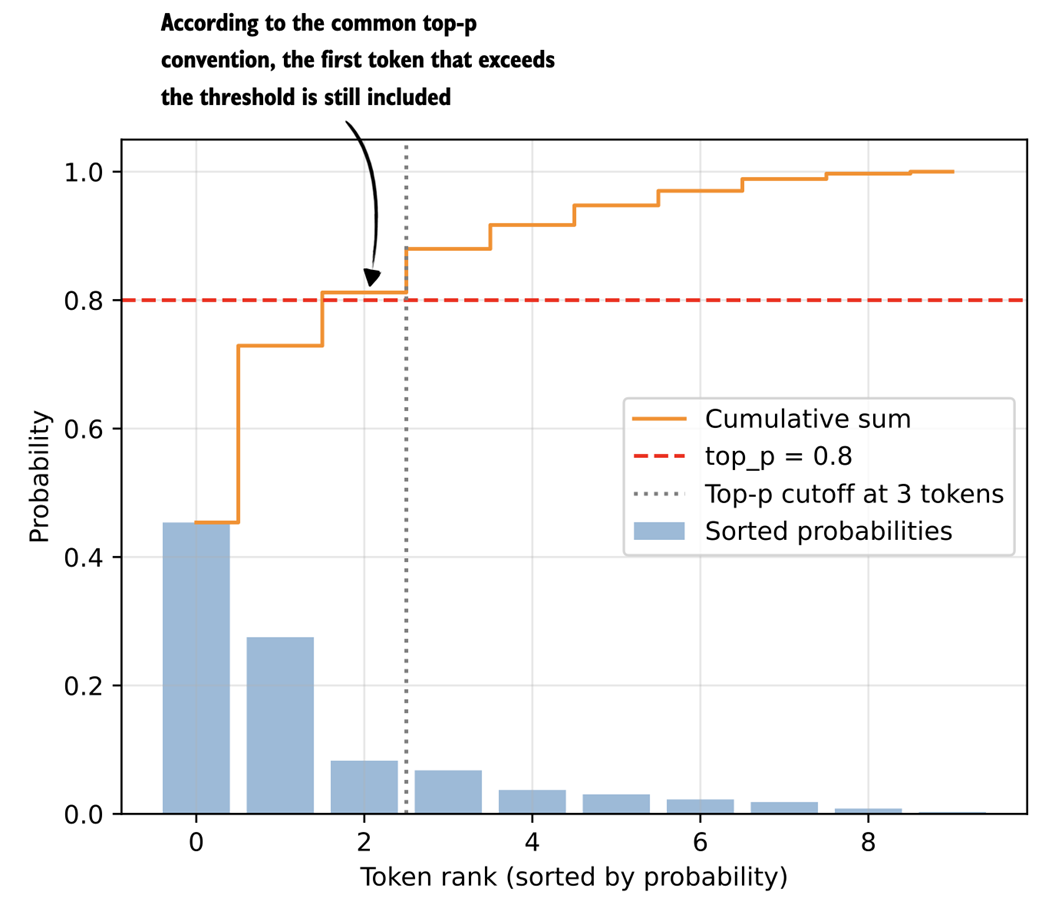
Integrating top-p filtering with temperature scaling. After rescaling the next-token scores, top-p filtering is applied between steps 3.3 and 3.4 to limit sampling to the most probable tokens.
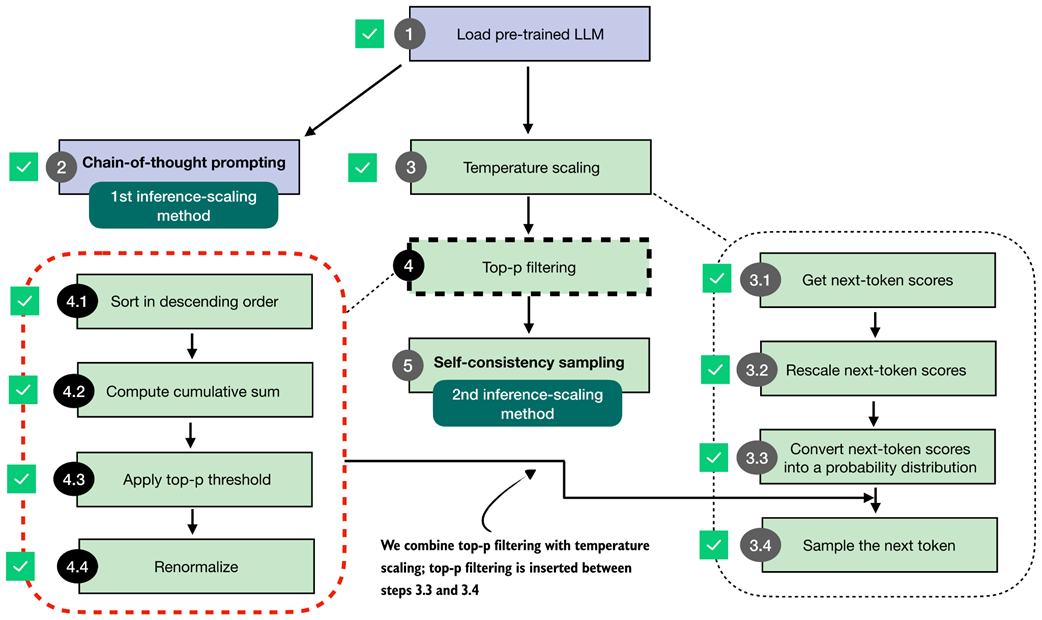
The self-consistency sampling method generates multiple responses from the LLM and selects the most frequent answer, which improves answer accuracy through majority voting across these sampled responses.
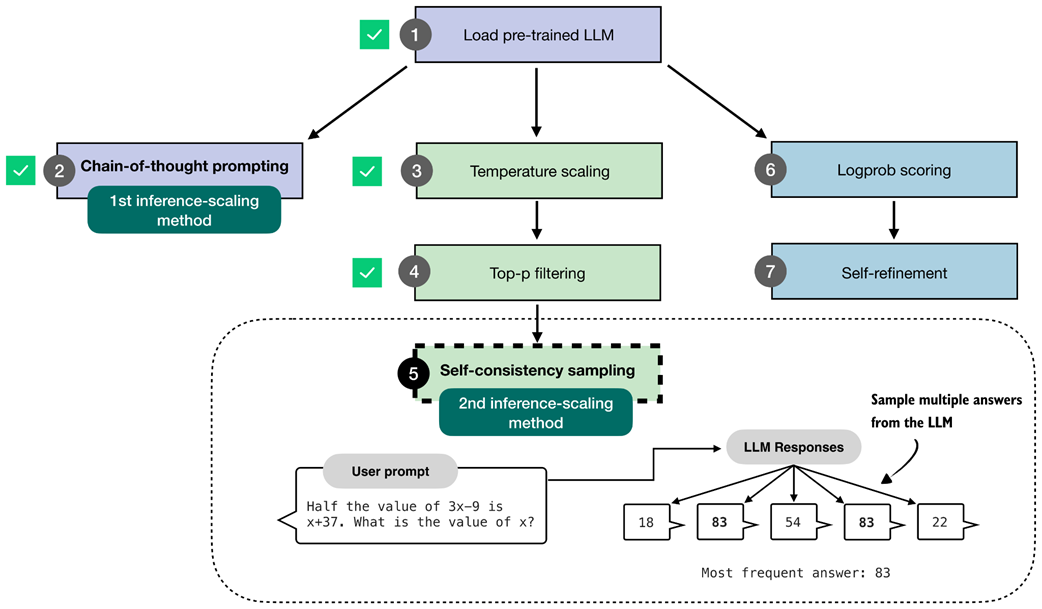
The three main steps for implementing self-consistency sampling. First, we generate multiple answers for the same prompt using a temperature greater than zero and top-p filtering to generate different answers. Second, we extract the final boxed answer from each generated solution. Third, we select the most frequently extracted answer as the final prediction.
Summary of this chapter's focus on inference-time techniques. Here, the text generation function was extended with a voting-based method to improve answer accuracy. The next chapter introduces self-refinement, in which the model iteratively improves its responses.
Summary
- Reasoning abilities and answer accuracy can be improved without retraining the model by increasing compute at inference time (inference-time scaling).
- This chapter focuses on two such techniques: chain-of-thought prompting and self-consistency; a third method, self-refinement, which was briefly described, will be covered in for the next chapter.
- A flexible text generation wrapper (generate_text_stream_concat_flex) that uses different sampling strategies that can be plugged in without changing the surrounding code.
- Next tokens are produced from logits via softmax
- Temperature scaling changes logits to control the diversity of the generated text.
- Top-p (nucleus) sampling filters out low-probability tokens to reduce the chance of generating nonsensical answers
- Chain-of-thought prompting (like "Explain step by step." or similar) often yields more accurate answers by encouraging the model to write out intermediate reasoning, though it increases the number of generated tokens and thus increases the runtime cost.
- Self-consistency sampling generates multiple answers, extracts the final boxed result from each, and selects the most frequent answer via majority vote to improve the answer accuracy.
- Experiments on the MATH-500 dataset show that combining chain-of-thought prompting with self-consistency can substantially boost accuracy compared to the baseline without sampling, at the cost of much longer runtimes.
- The central trade-off of inference-time scaling: higher accuracy in exchange for more compute.
 Build a Reasoning Model (From Scratch) ebook for free
Build a Reasoning Model (From Scratch) ebook for free