7 Building robust agents with evaluation and feedback
This chapter emphasizes that robust, safe, and debuggable agentic systems depend on rigorous evaluation and feedback woven throughout the lifecycle—not just at production hardening time. It maps internal learning loops and external evaluators, highlighting complementary methods such as red-team and benchmark testing, human feedback, and agent-based evaluators (grounding and critic agents). Results are best funneled into an evaluation/feedback store that powers reporting, alerts, and continuous improvement, often via a dedicated feedback agent. The recommended discipline is to adopt test-driven agent development from the outset so quality gates shape prompts, tools, and policies as the system evolves.
Test-driven agent development follows a Think → Test → Prompt → Refactor loop: define goals and benchmarks (including counterexamples), expect early failure, and make minimal, targeted updates for consistency and latency. Because LLMs are variable, each test should be run multiple times and refactoring kept lean; when benchmarks conflict, teams can allow selective failures, split responsibilities across specialized agents, or rebuild prompts around the hardest goals. A practical walk-through shows a RAG agent maturing from string-match checks to an evaluator agent with typed pass/fail plus feedback, then to a grounding agent that blocks ungrounded output and can serve as a guardrail with tripwire-triggered exceptions. The pattern extends to multi-agent flows where critics guide regeneration and prevent drift, ensuring outputs remain correct, contextualized, and policy-aligned.
For complex, mixed-generation tasks, rubric-based evaluation provides structured, explainable judgments beyond simple accuracy, enabling critic agents to score outputs (for example, images) across criteria and thresholds that govern iterative improvement loops. Strong observability underpins this process: comprehensive logging and tracing capture agent, tool, and LLM spans for diagnosis and analysis. Phoenix augments this with OpenTelemetry-based tracing, session and metadata tagging, datasets built from real traces, experiment runners, evaluators, and annotations to systematize triage and iteration. The chapter’s throughline is clear: combine TDAD, grounding and critic/evaluation agents, and trace-driven operations to close the loop on quality—never promoting agents without concrete evaluation and feedback mechanisms in place.
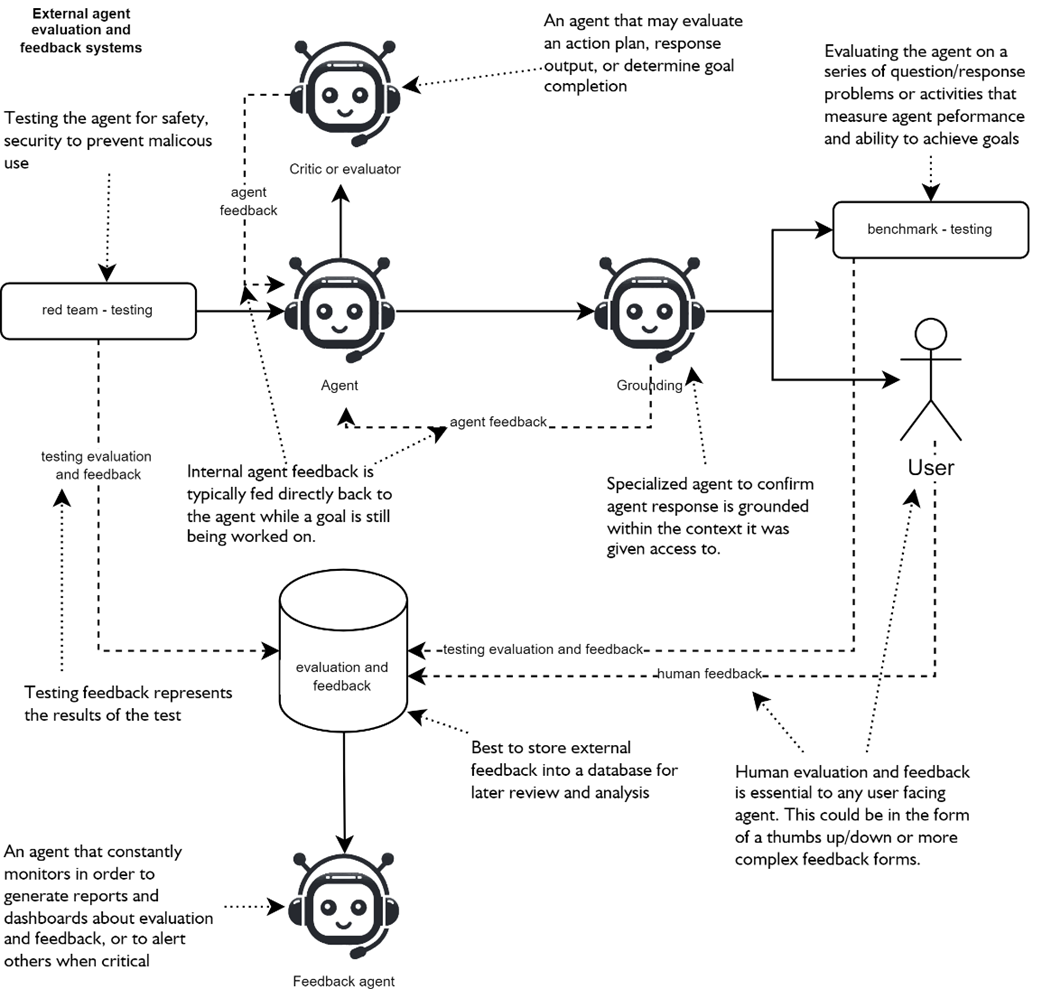
highlights the external agent evaluation and feedback systems for a single user-facing agent. In the figure a generative agent may face evaluation from a critic for general output feedback or a grounding agent for context specific feedback and evalution.
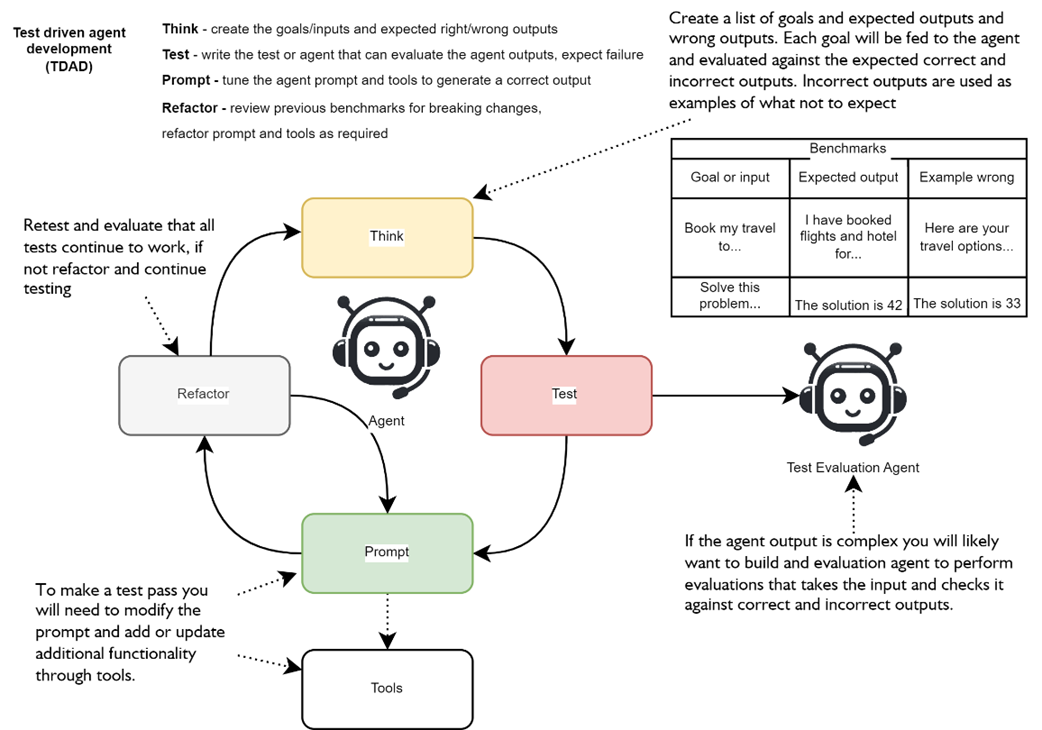
highlights the human process of developing agents using TDAD. Where we first think of goals and benchmarks, then test, develop the prompt, refactor, and then repeat the process.
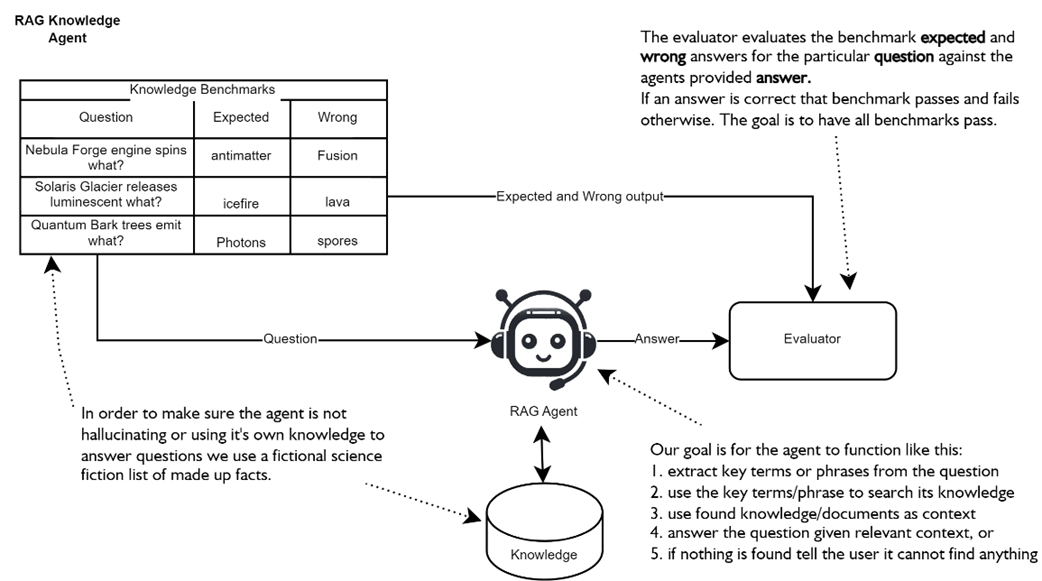
Architecture of a simple RAG Knowledge Agent. The goal of the agent is to answer questions from a benchmark by searching its knowledge base and returning answers. A simple evaluator LLM evaluates the answer based on the expected and wrong answers from the benchmark test. The accurary of the RAG agent can be determined by the percentage of correct answers answered from the benchmark.
Three forms of agents for evaluating agent output: grunding, critic, and evaluation. The grounding is specific to evaluating RAG agent output. The critic agent is designed to critique generated content, and the evaluation agent is used for more complex output.
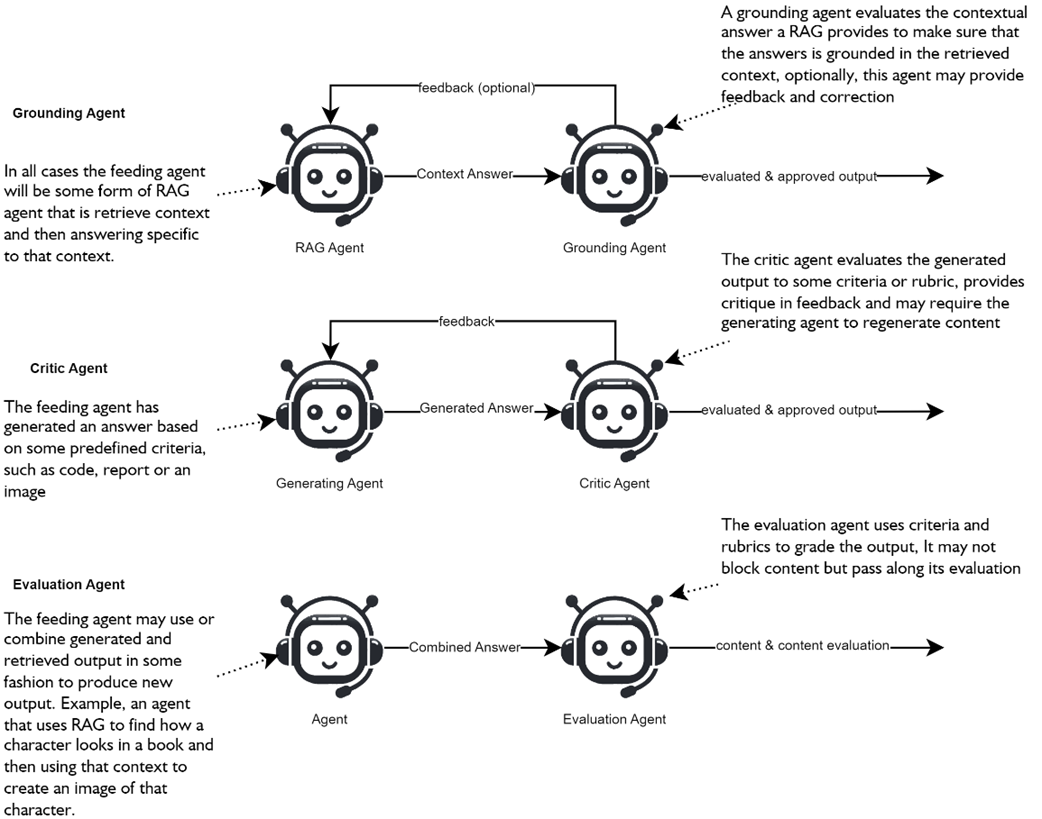
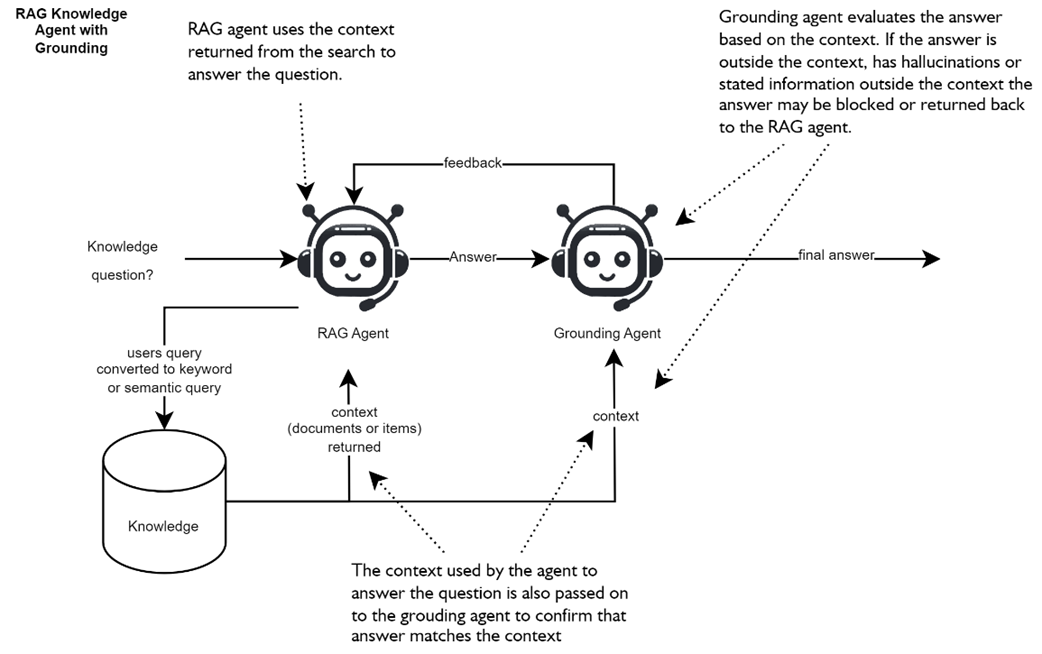
RAG knowledge agent coupled with a grounding agent. Both agents are provided with the same context. The RAG agent generates an answer from the context, and the grounding agent verifies that the answer is grounded by reviewing the same context.
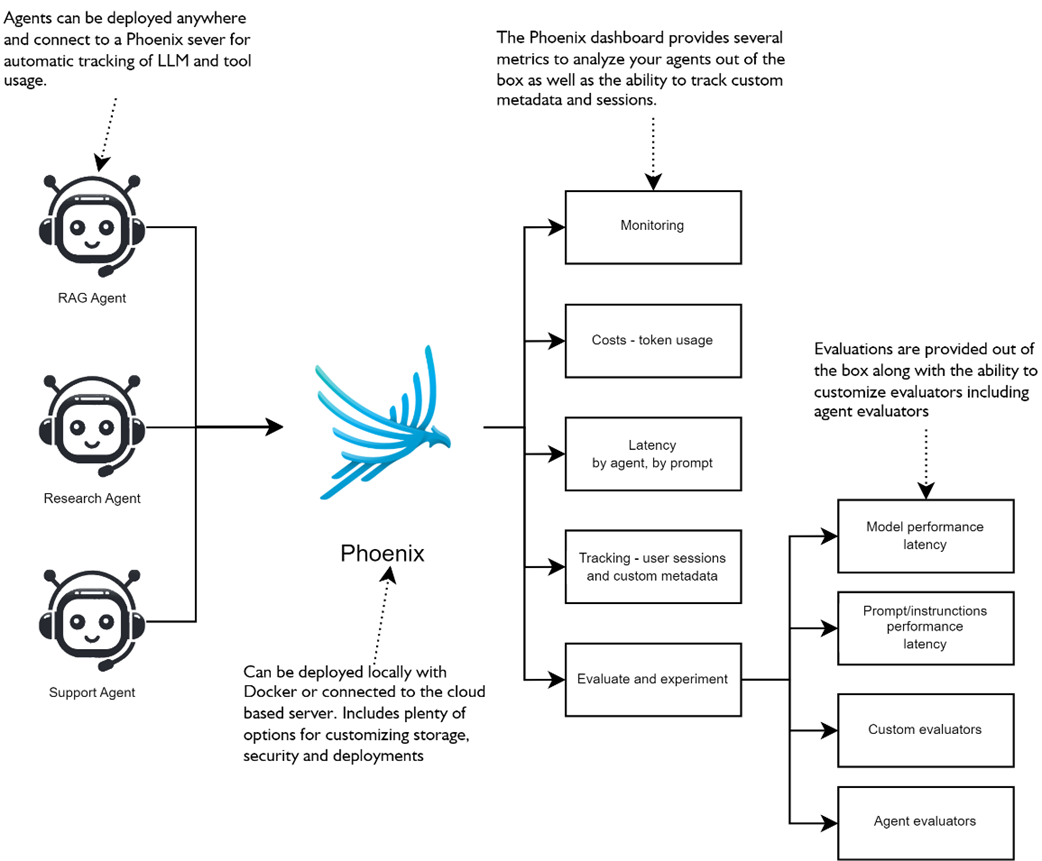
Arize Phoenix deployment patterns and use case methods of tracing, tracking and evaluating agents.
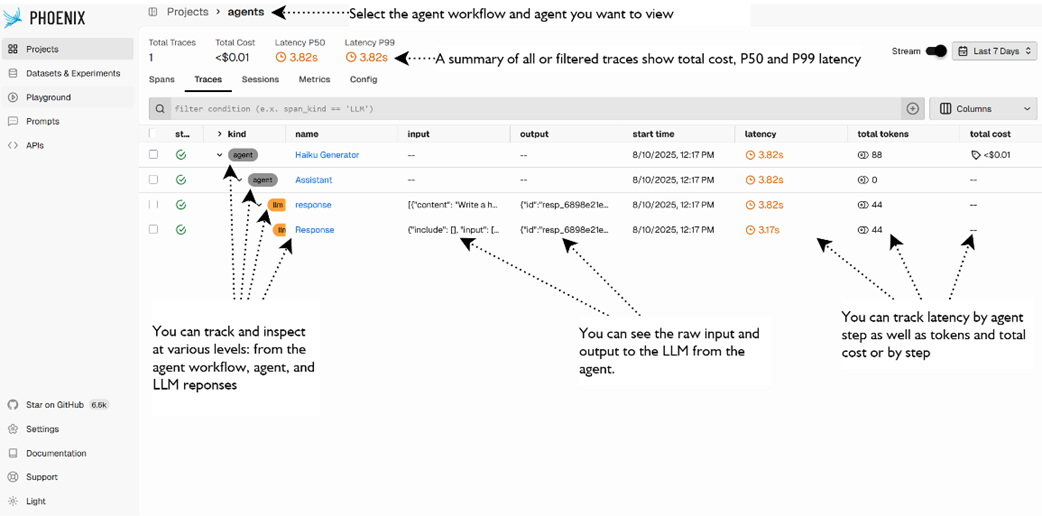
Arize Phoenix projects dashboard showing an agent workflow, agent and LLM activity.
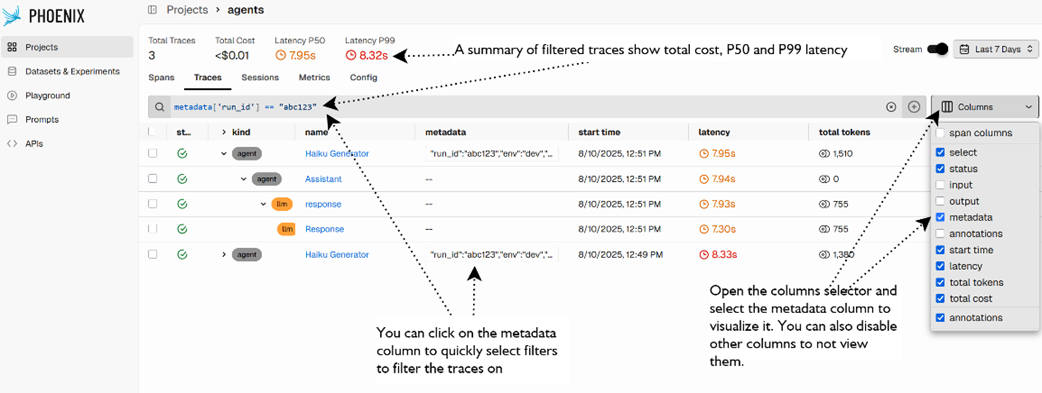
Viewing the metadata column and filtering traces by an attribute.
The process to add spans to a dataset for later experimentation and evaluation.
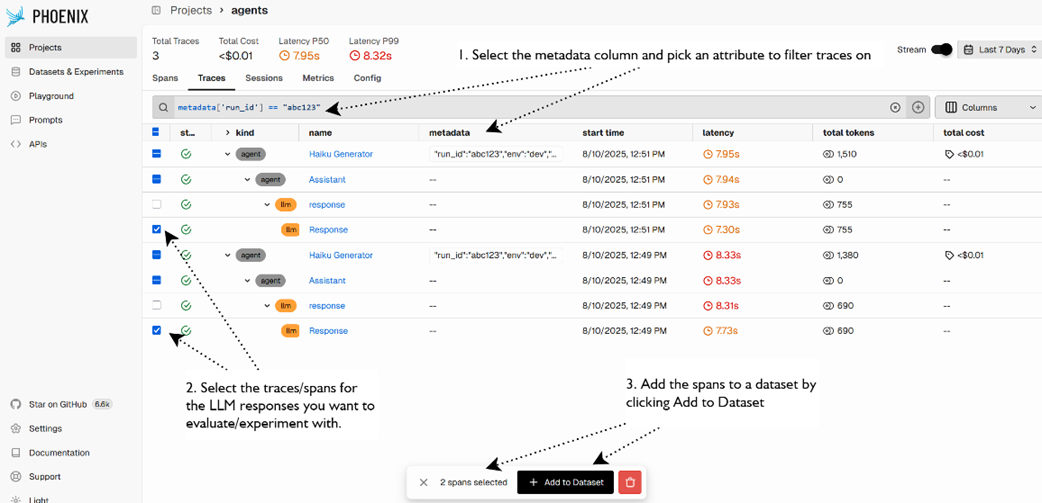
Viewing datasets and then clicking Run Experiment to view the generated code you can copy to a Python file to generate an experiment or evaluation.
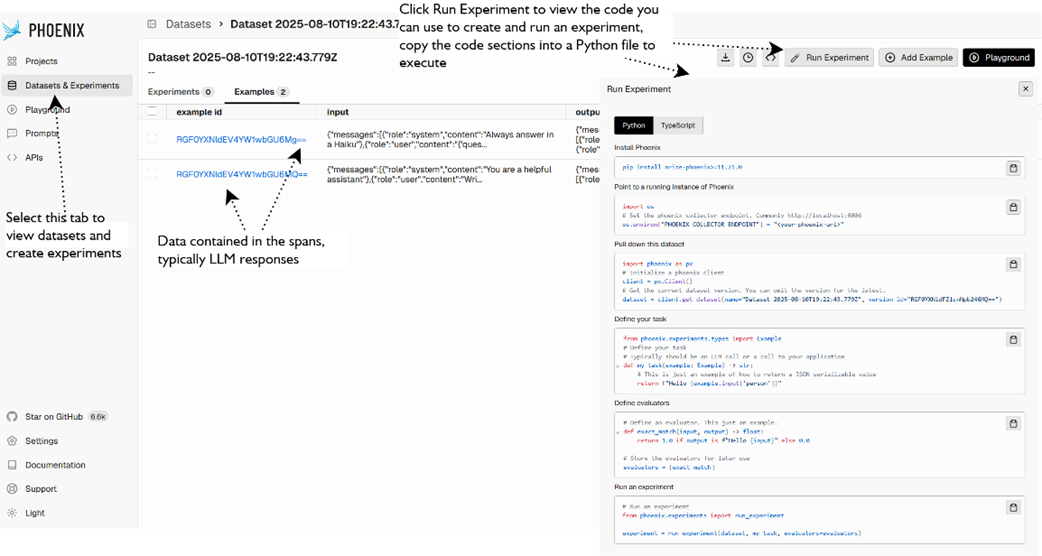
demonstrates how to create a new Annotation in Phoenix.
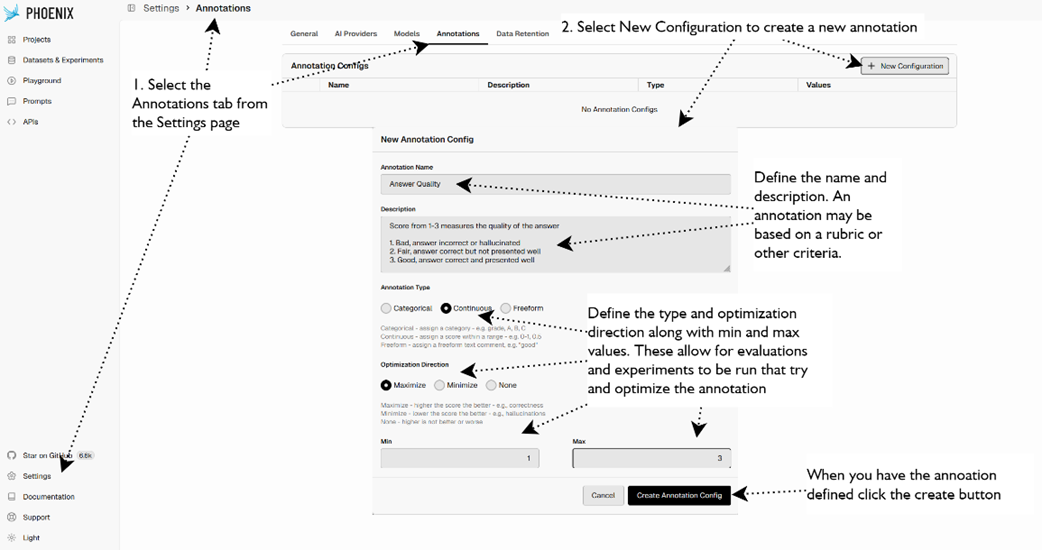
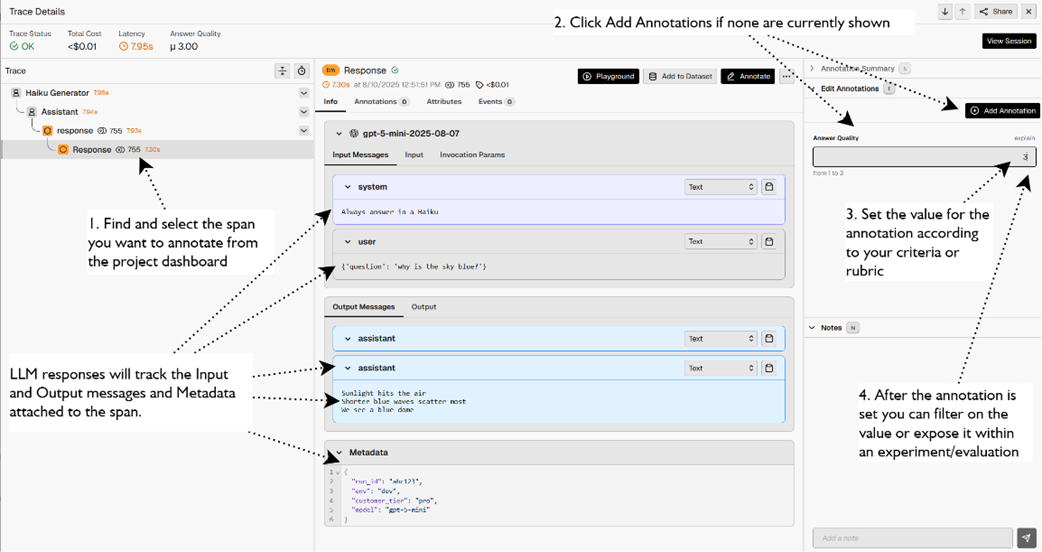
demonstrates how to apply an annotation to an LLM response within an agent workflow, agent, and LLM response spans.
Summary
- Robust agents require evaluation and feedback baked in from the start—tie the Learn step of Sense-Plan-Act-Learn to external evaluators, a feedback store, and (optionally) a monitoring/alerting feedback agent.
- Use a mix of methods: red-team testing for safety breaks, benchmark testing for goal attainment, human feedback (thumbs/comments) with verification to reduce bias, and automated evaluators (grounding/critic/evaluation agents) where appropriate.
- Test-Driven Agent Development (TDAD) flips the process: define benchmarks (incl. wrong examples), expect initial failures, run each test multiple times for consistency, then make the minimum prompt/tool/model changes needed to pass—retest and refactor iteratively.
- When benchmarks conflict, decide explicitly: accept partial pass targets, split into specialized agents (plus triage), or refactor the agent’s instructions from first principles.
- Prefer tool guidance in the tool’s name/docstring over prompt clutter—rename tools and write clear docstrings; keep prompts lean and role-focused.
- Add evaluation agents to score complex, natural-language outputs with typed results (e.g., pass/fail + feedback), avoiding brittle string matching and enabling programmatic gating.
- Grounding agents are essential for RAG—verify answers are supported by provided context/citations; on failure, regenerate, block with a static response, or pass grounded feedback forward.
- Guardrails operationalize grounding—wrap agents with output guardrails that trip on ungrounded answers and surface feedback/flags for policy (retry, block, or annotate).
- Rubrics turn subjective quality into criteria and scales—use them with critic agents for high-variance generation (images, reports, graphs); loop generation ↔ critique until a passing score or attempt limit.
- Because LLMs are stochastic, benchmark for stability—not just accuracy—by rerunning tests and watching variance, latency, and token use.
- Observability is non-negotiable: OpenAI Traces show every tool call and LLM turn; Arize Phoenix (OpenTelemetry) adds projects, sessions, metrics, costs, experiments, and evaluators.
- Instrument Phoenix cleanly—set the collector endpoint, replace default processors, register a tracer, and wrap runs with named traces; attach sessions and metadata for filtering and cohort analysis.
- Build datasets from spans, run experiments/evaluators, and use annotations to capture structured human feedback—feed these signals back into prompts, tools, and policies.
- Production rule: never promote agents without active evaluation/feedback loops—benchmarks, grounding/guardrails, critics with rubrics, tracing, and monitored KPIs (latency, cost, quality) working together.
 AI Agents in Action, Second Edition ebook for free
AI Agents in Action, Second Edition ebook for free