5 Agent reasoning and planning
Reasoning and planning are presented as the core capabilities that turn large language models into effective agents. While base LLMs operate as next-token predictors and tend to handle one task at a time, prompt strategies and newer reasoning-centric models enable decomposition of goals into steps and the construction of executable plans. Two practical, low-level patterns anchor this shift: Chain of Thought (CoT), which elicits explicit step-by-step reasoning, and ReAct, which interleaves thinking with tool use and observation. CoT improves transparency and reproducibility but adds tokens and latency; ReAct extends this by letting agents gather evidence via tools, update their thinking, and iteratively pursue a goal.
The chapter then shows how to instruct agents to apply these patterns in practice, first by embedding CoT-style instructions to surface their thought process, and then by enabling ReAct loops with tools so agents can act, observe results, and refine plans. For harder problems, advanced strategies are introduced: Tree of Thought (ToT) explores multiple branching reasoning paths and prunes weaker ones, trading speed for breadth; Reflexion adds a solver–critic loop that learns from mistakes via targeted feedback, improving solutions across attempts. Selecting among CoT, ReAct, ToT, and Reflexion depends on problem complexity, time sensitivity, and computational budget, with guidance on when each pattern fits best.
Finally, the Sequential Thinking MCP server provides a structured scratchpad for multi-step reasoning and planning. Rather than “thinking” for the agent, it records and manages thoughts, revisions, branches, and hypotheses, helping agents maintain a global plan, adjust the number of reasoning steps, and verify solutions. Used alongside tool calls and tracing, it makes ReAct- and ToT-style workflows more controllable and auditable—even though correctness still depends on the underlying model and instructions. The chapter emphasizes combining these techniques judiciously: use lightweight patterns for routine tasks, escalate to branching or feedback-driven loops for ambiguity and depth, and employ the Sequential Thinking server to keep long-horizon plans coherent as agents reason, act, observe, and refine.
compares differences to prompting strategies with reasoning and non-reasoning models
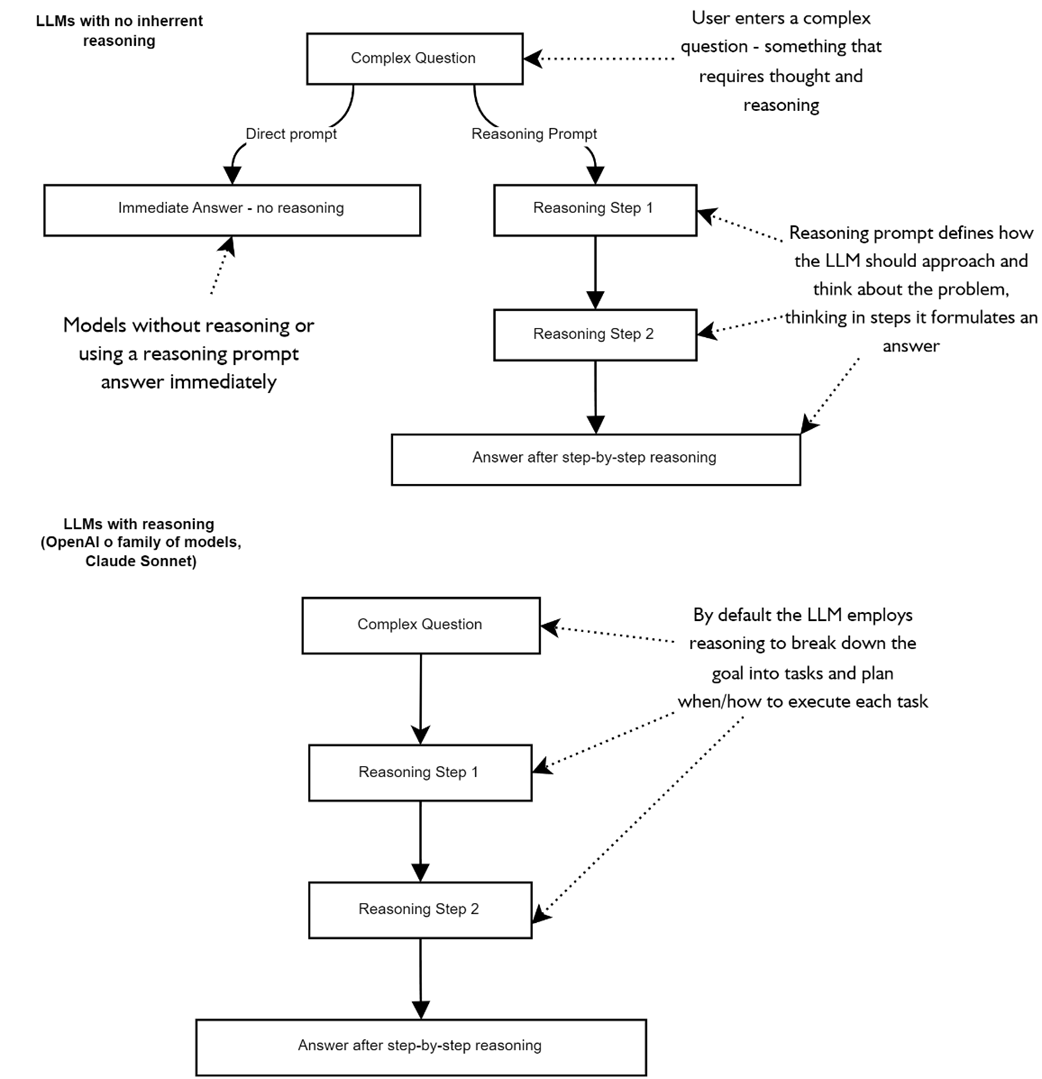
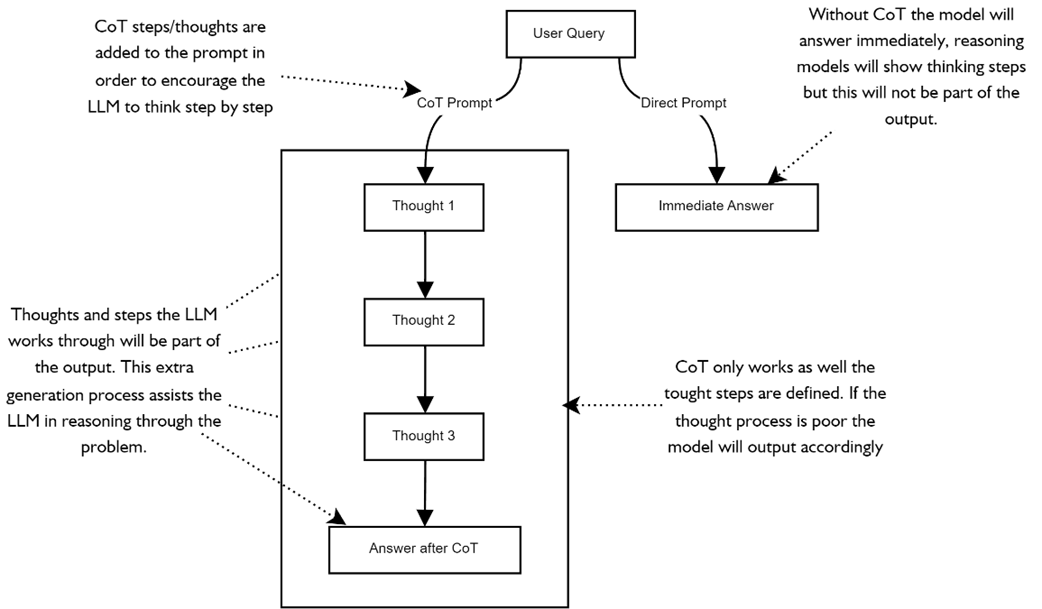
compares the LLM thought process when using CoT prompting on the left and not using any explicit reasoning instructions.
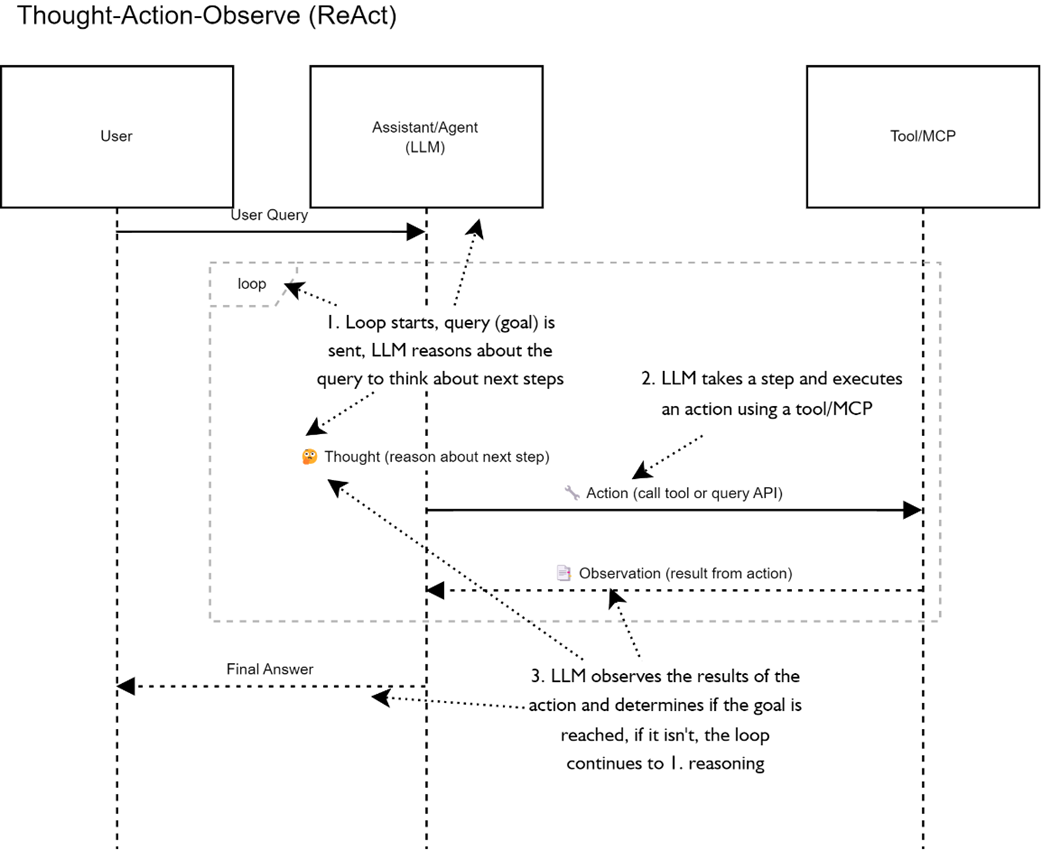
demonstrates the ReAct paradigm of reasoning in a sequential diagram. The agent thought process occurs in the loop where the LLM first reasons, plans and then executes on the plan. After each execution of a task (tool) the LLM observes the output and then reasons if it needs to continue looping or the plan has been completed.
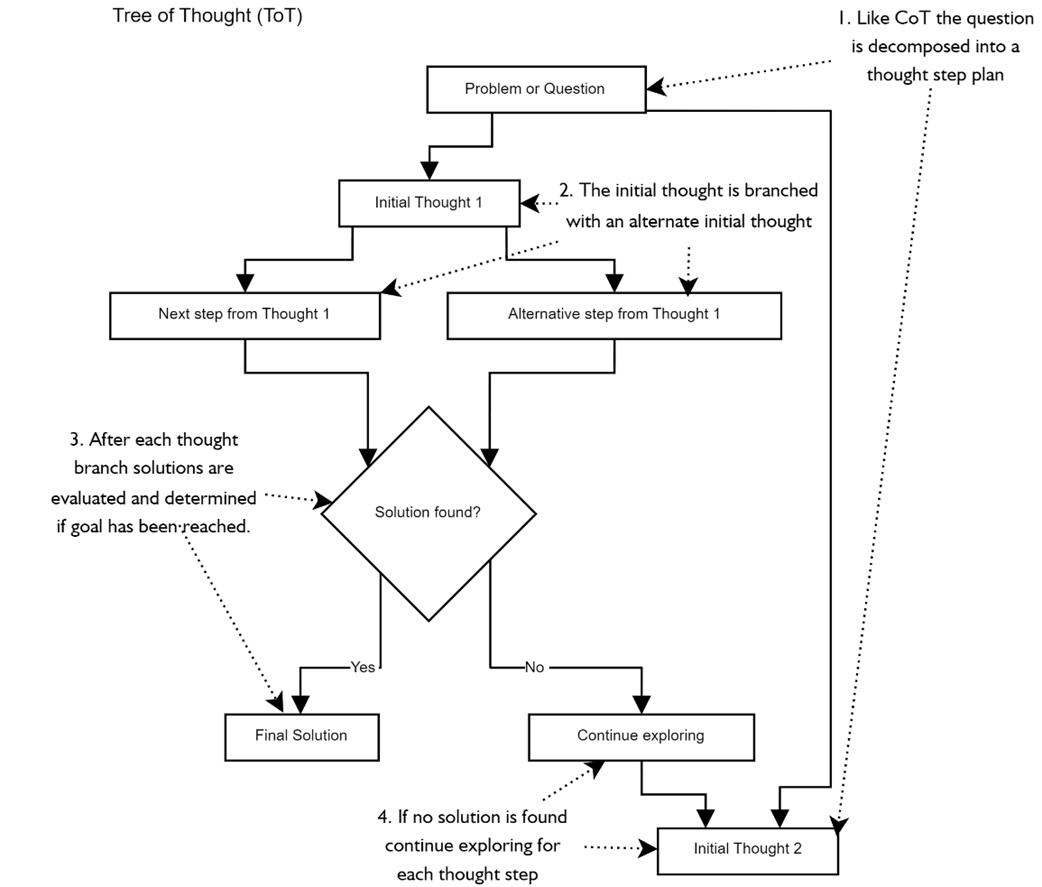
shows a partial workflow of the tree of thought process where thoughts are branched into nodes and each node is executed to determine which is the best path to follow.
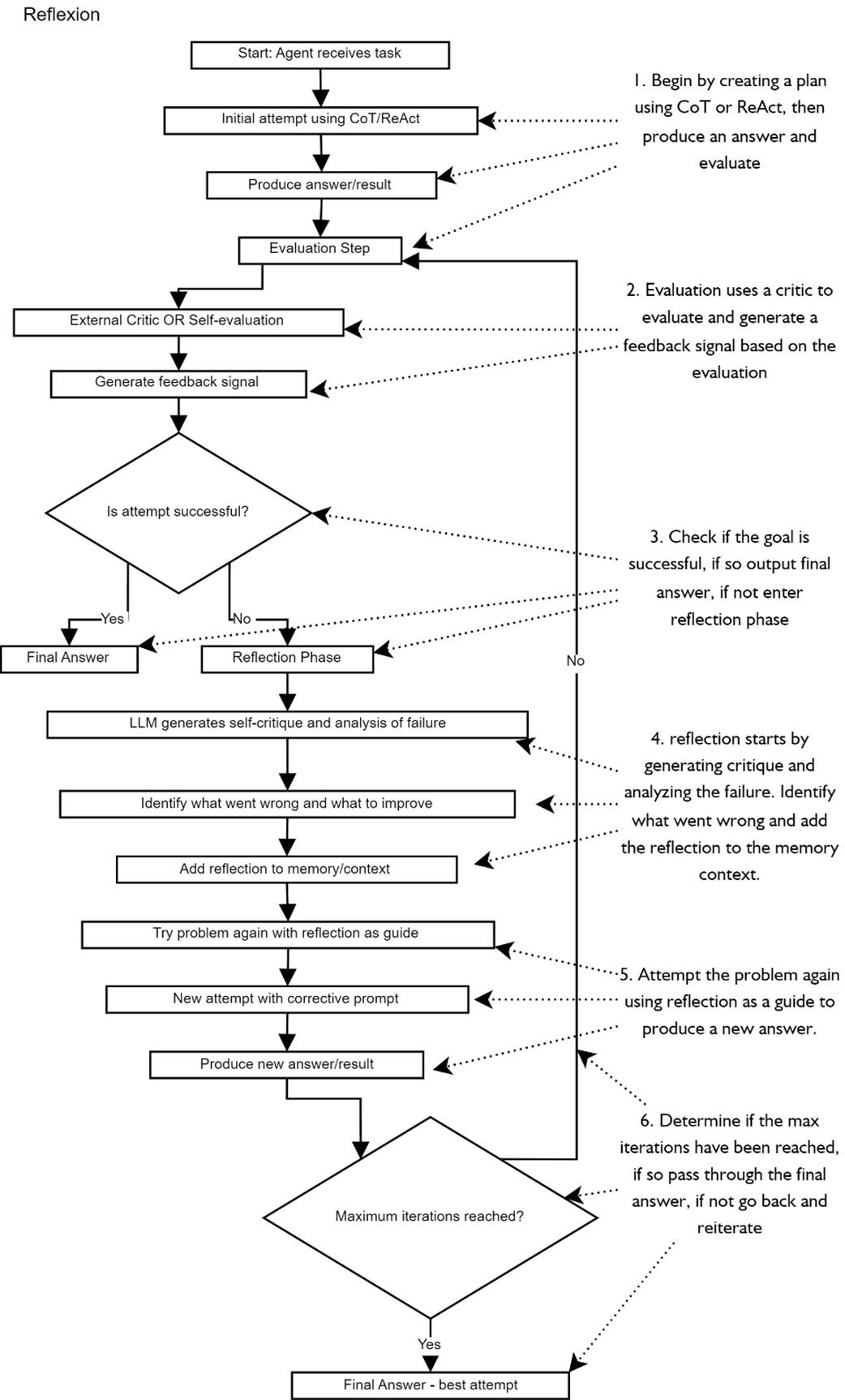
illustrates the Reflexion reasoning strategy in a step-by-step flowchart. Each step in the flow demonstrates a task, decision, or output that can occur in an LLM or deterministic code.
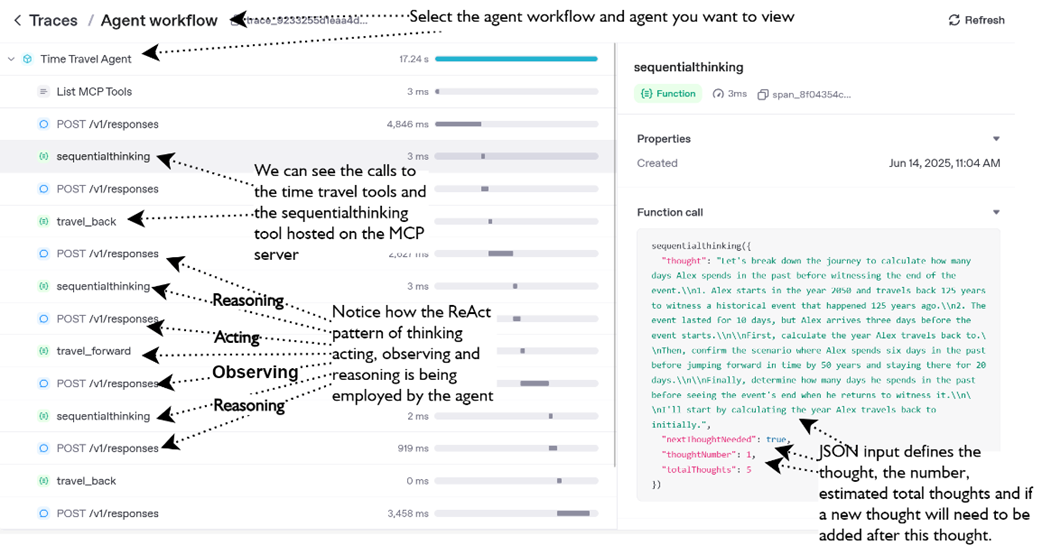
shows the Traces page for the Time Travel Agent execution, from here we can see how the agent goes through the ReAct pattern of reasoning, acting, observing and reasoning again.
Summary
- Large Language Models don’t “think” by default—they’re token-predictors—so agents must inject structured reasoning and planning to achieve multi-step goals.
- Chain-of-Thought (CoT) prompting turns a model’s hidden intuition into explicit, step-by-step thoughts that are easy to debug, at the cost of extra tokens and latency.
- ReAct augments CoT with tool calls: Reason → Act → Observe → Repeat, letting an agent gather information dynamically while iteratively refining its plan.
- High-level planning goes beyond single chains: agents can ask an LLM to draft a strategic outline, then revise it as real-world feedback arrives.
- Tree-of-Thoughts (ToT) explores many branches in parallel, pruning losers and expanding promising paths—powerful for complex search tasks but extremely token-hungry.
- Reflexion wraps a solver–critic loop around any reasoning strategy: the critic provides feedback, the solver revises, and the cycle repeats until the answer passes a self-defined check.
- Choosing a strategy is task-dependent: CoT for logic puzzles, ReAct for tool-heavy look-ups, ToT for deep planning, Reflexion for iterative improvement—mix and match as needs evolve.
- The Sequential Thinking MCP server acts as a universal “scratchpad” tool; agents write, revise, and branch thoughts there while still using ReAct or ToT patterns externally.
- Combining strategies scales up reasoning: e.g. CoT to draft a plan, ReAct+ToT to execute/branch it, Reflexion to self-grade and retry—expect high latency but high reliability.
- Guardrails, schemas, and typed outputs remain essential; reasoning output should be validated just like any other agent I/O to avoid cascading errors.
- Model choice matters: newer reasoning-native models (e.g. GPT-4o family) handle these patterns with fewer prompts, but even base models can reason when coached properly.
- Keep tool lists lean; every additional tool inflates ReAct loops and Sequential Thinking calls—scope each agent to < 10 highly relevant tools.
- A production-ready reasoning agent pairs structured prompts, the right reasoning strategy, Sequential Thinking for thought tracking, and guardrails for validation—yielding plans that can adjust, retry, and successed autonomously.
 AI Agents in Action, Second Edition ebook for free
AI Agents in Action, Second Edition ebook for free