2 Core components: Large Language Models, prompting, and agents
This chapter establishes the core building blocks of effective AI agents: large language models as the probabilistic “brain,” prompt engineering as the primary control surface, and an agents SDK to orchestrate roles, tools, and workflows. It frames agents as systems that turn raw language generation into directed, auditable action by combining sound LLM fundamentals with disciplined prompting and structured interfaces. Readers are guided from conceptual grounding to hands‑on construction, assembling a minimal agent and iteratively expanding it with determinism controls, typed I/O, tool use, and execution tracing.
The chapter first demystifies LLMs as token predictors, explaining tokenization, training/inference dynamics, and why input size and format affect cost and uncertainty. It shows how parameters such as temperature, top‑p, and penalties shape variability and length, while stressing that these knobs only influence behavior—true reliability comes from well‑crafted prompts. A practical prompt toolbox follows: define a clear persona, front‑load directives, use delimiters, be specific, add examples, encourage step‑by‑step reasoning, state positive rules, remove ambiguity, pick suitable models/settings, and iterate. It also warns against common pitfalls—overlong or contradictory instructions, micro‑prompt fragmentation, inconsistent delimiters, and over‑specification—encouraging structured, workflow‑oriented prompts that “think like an LLM,” and noting that agents, unlike single LLM calls, can persist through loops and decisions.
Building on this foundation, the chapter uses the OpenAI Agents SDK to implement a minimal research planner, then tunes model settings for consistency and cost control. It introduces strongly typed outputs (via data models) to reduce variability and prevent brittle handoffs between steps, advocating strict schemas over permissive parsing. Execution tracing is highlighted as a cornerstone for debugging and optimization. Finally, the chapter equips agents with tools through lightweight decorators, explains tool‑chaining patterns, and outlines guardrails: limit tool count to cap overhead and complexity, anticipate failures and retries, and grant only the authority you can safely accept. The result is a pragmatic recipe for assembling reliable, extensible agents: prompt‑driven, parameter‑aware, strictly typed, tool‑enabled, and thoroughly traced.
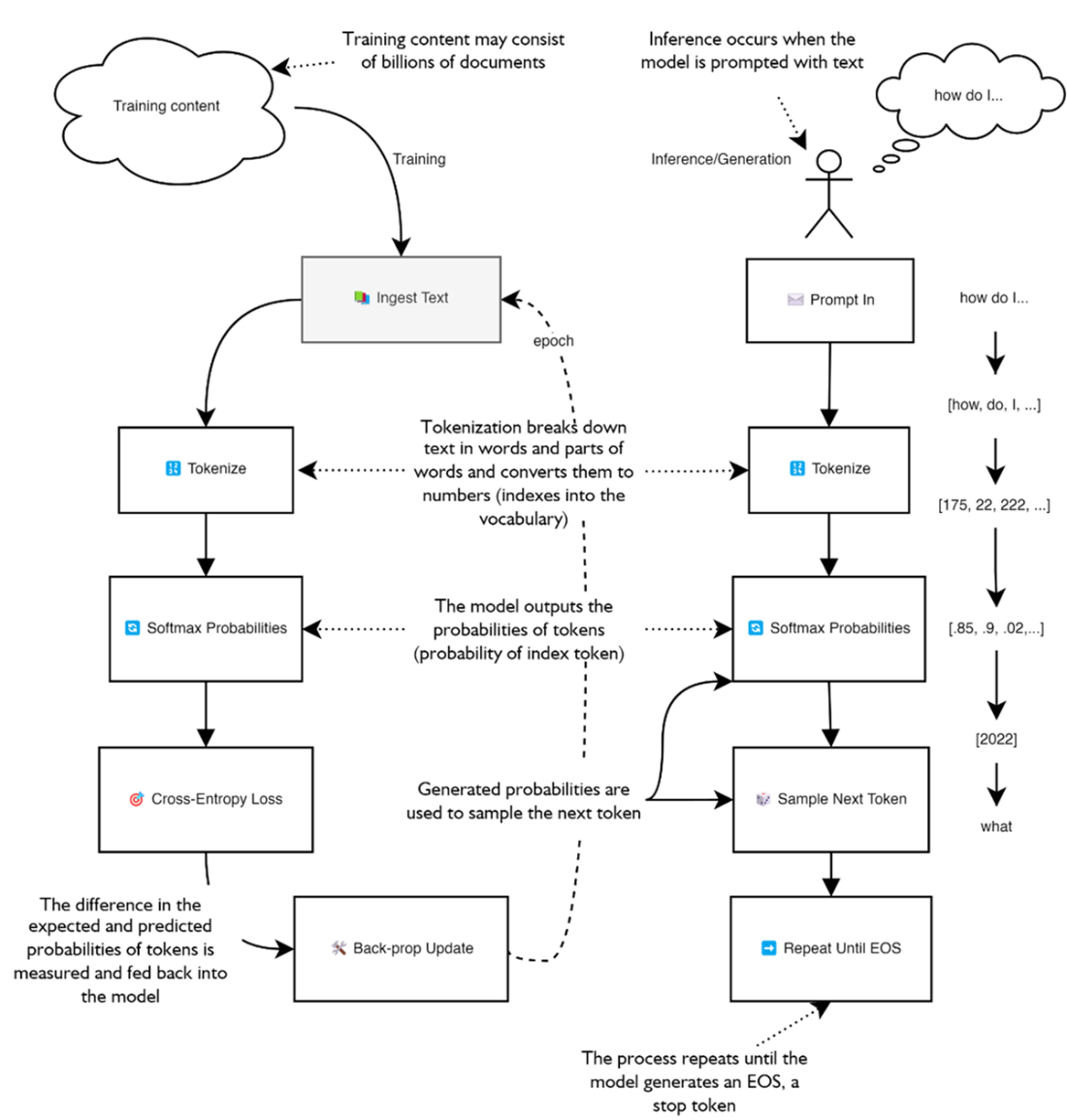
The training cycle and inference/generation process of a large language model. On the left is the training process of the model where documents are ingested to train the LLM in a first pass. On the right, a user enters a prompt which is first tokenized and fed into the model which then outputs probabilities it uses to sample and produce the next token.
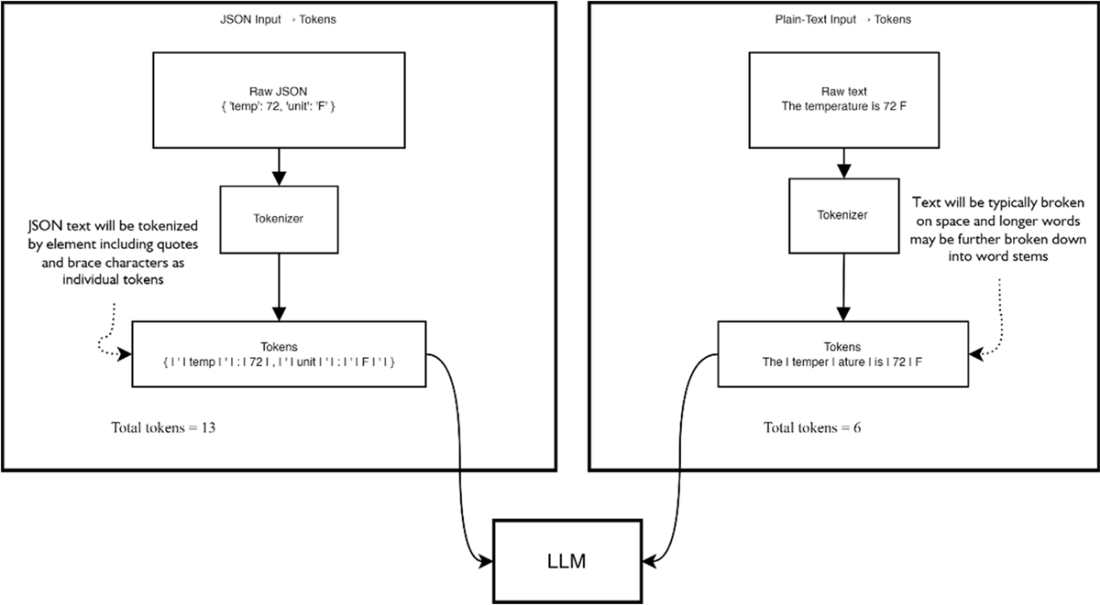
A comparison of tokenization of regular text compared to JSON.
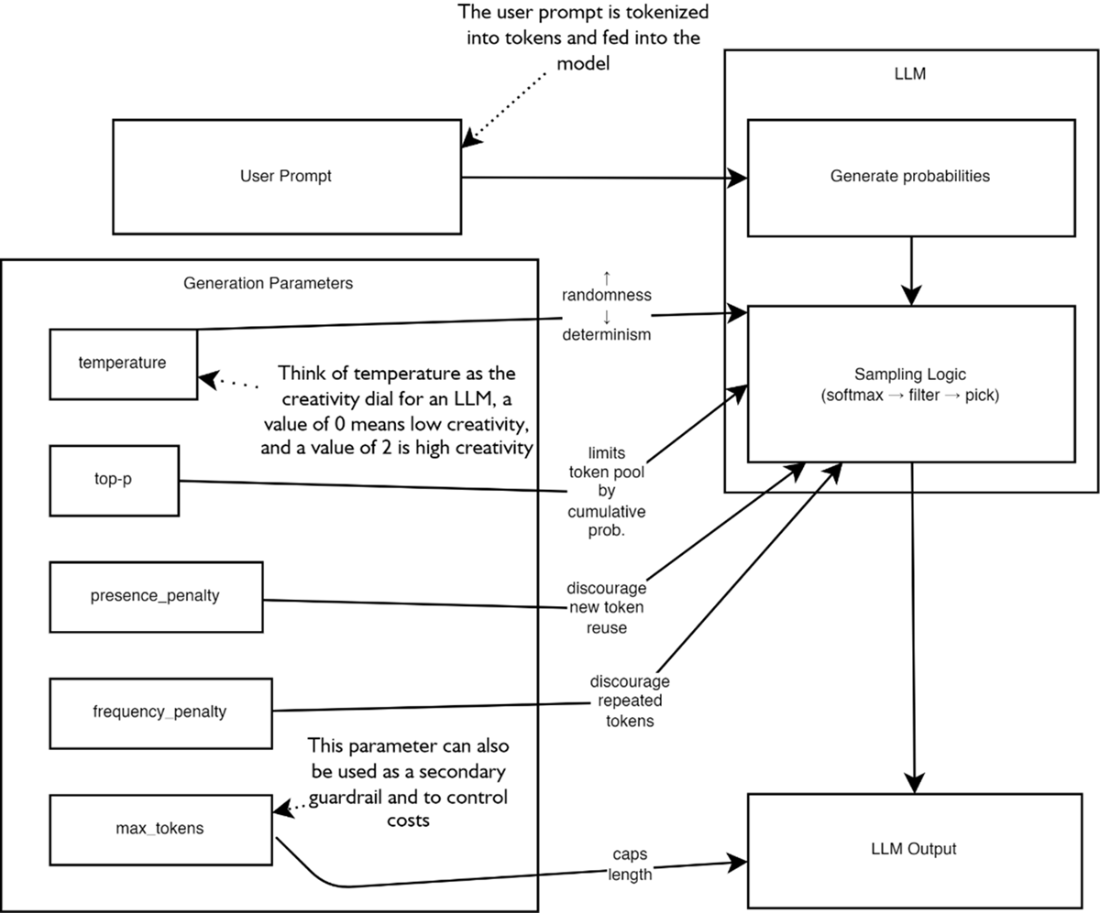
The various parameters that can be used to modify an LLMs output. The right side of the figure provides an expanded view of the models predicting and sampling the tokens to generate output. On the left we see the various parameters that can be used to alter the sampling of the next token within a model.
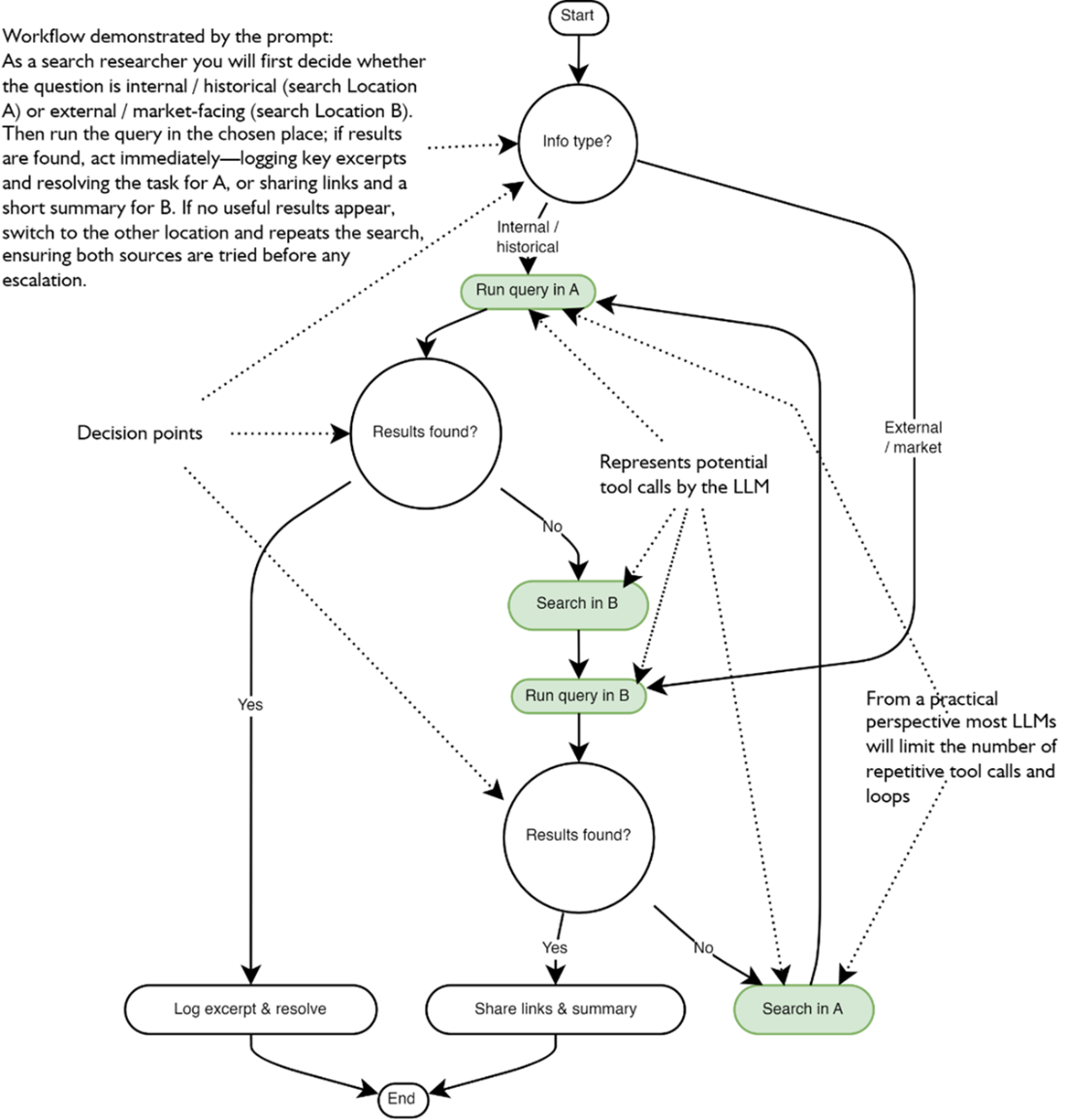
A complex workflow showing what a search researcher may perform. The workflow illustrates the tasks an agent may undertake, complete with decision points (circles) and the flow from one task to another. (The figure is overly complex just to demonstrate the workflow.)In the figure, the workflow illustrates how we want an LLM or agent to perform a series of tasks and how it considers the output to make decisions based on the task results. The workflow details are not critical, and the complexity is used to demonstrate how complex instruction prompts can be constructed by following good prompt engineering practices. (Don’t be alarmed if you can’t follow this figure; it is just a toy example of complexity to the extreme.)
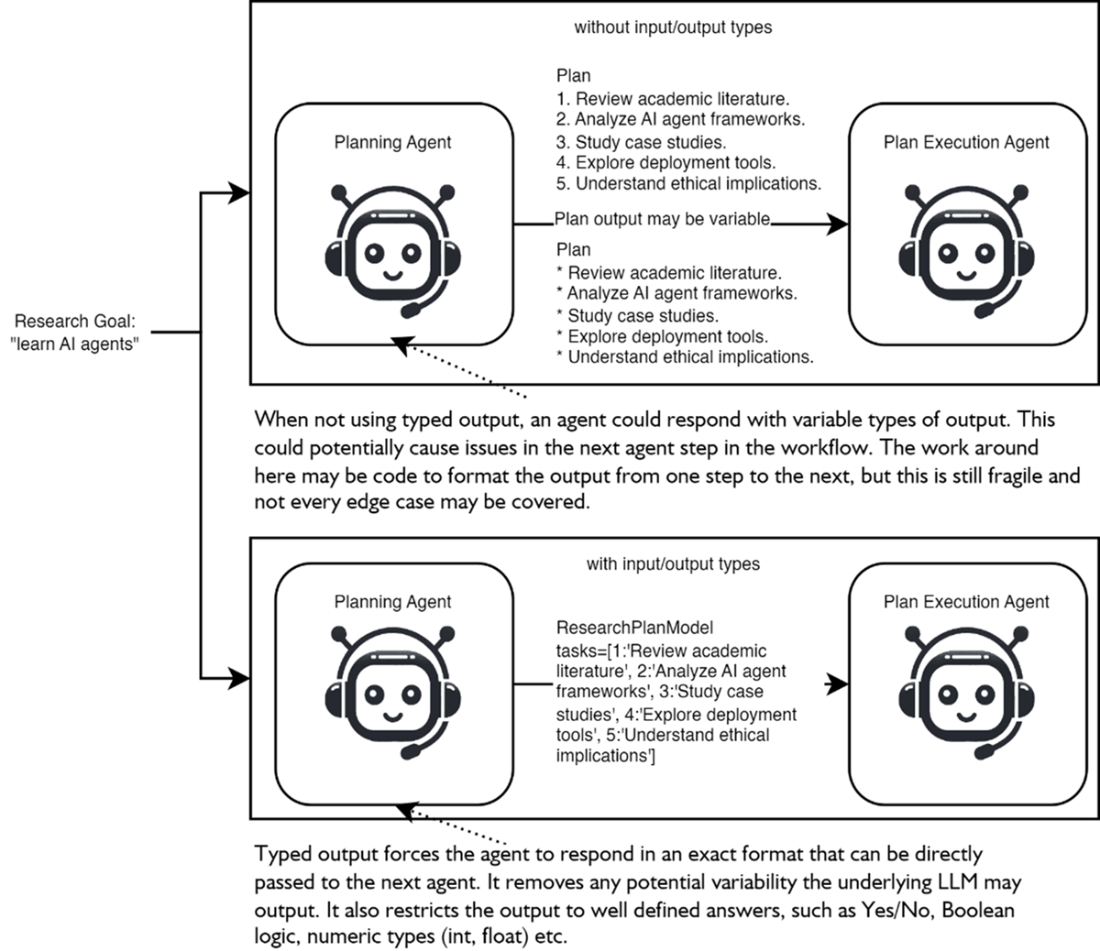
Comparing how an agent workflow may run with and without typed outputs/inputs. At the top the agent does not use strict outputs and could respond in any fashion, increasing variability when passing output to the next agent. Conversly, at the bottom the agent provides strict outputs which reduces variability and improves clarify for agents or processes receiving the output.
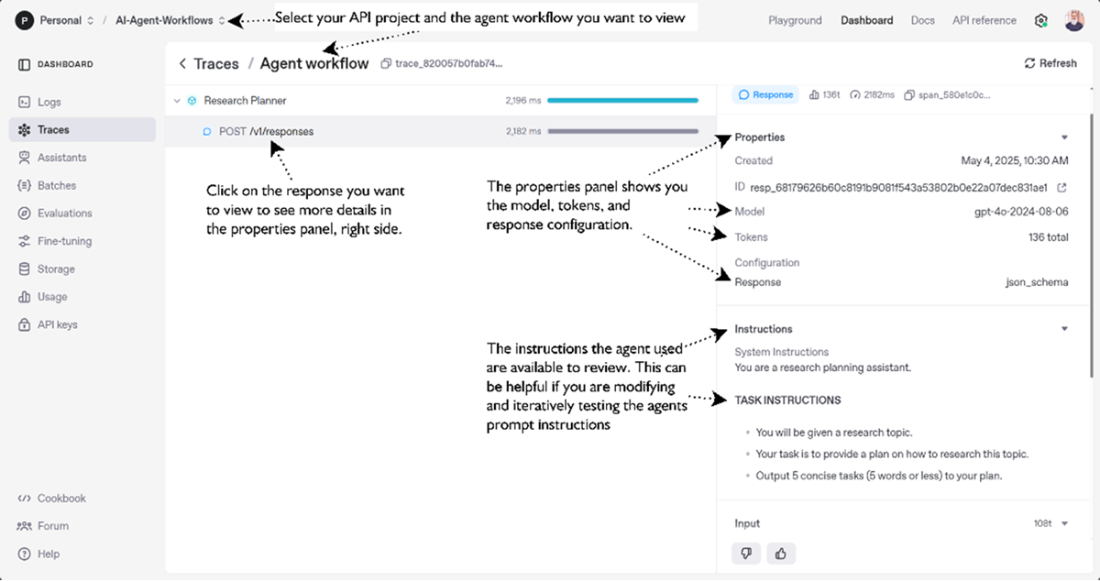
An example of the OpenAI Traces screen for reviewing your agent execution. At top you can see the workflow/trace from the agent and below that the specific details about calls to the underlying LLM including the inputs, model, tokens, instructions and output from the call
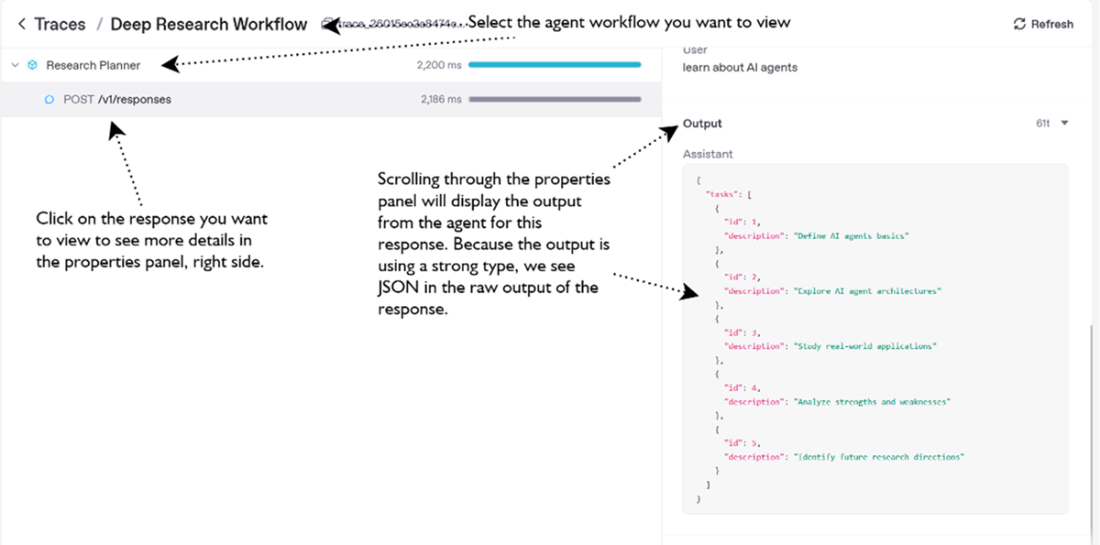
The Traces page for the Deep Research Workflow. This step represents the Research Planner agent making a call to the LLM and receiving a JSON output of a plan (list of tasks) to perform to achieve a research goal.
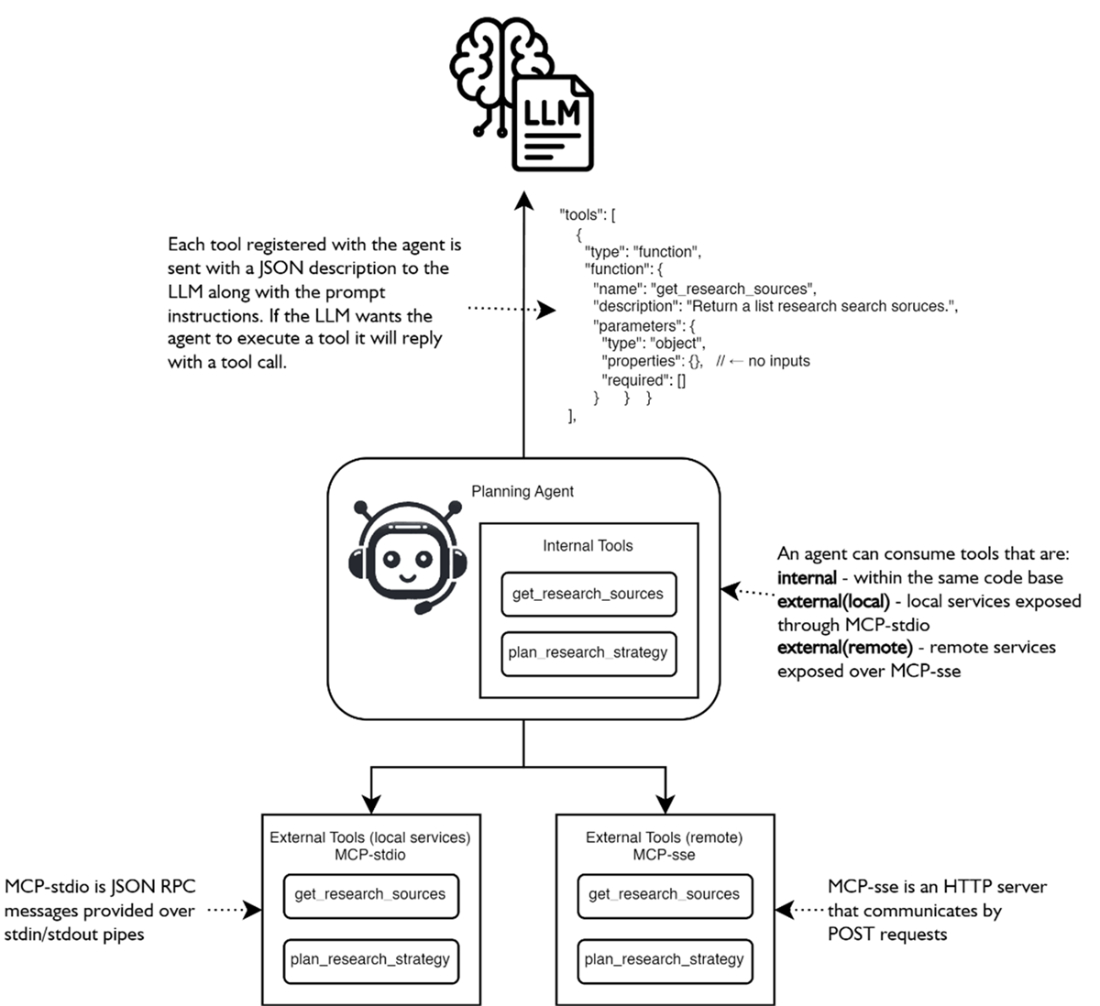
The various patterns for an agent to consume tools. Tools may be internal code functions or external connections to MCP servers, hosted locally or remotely and connected through using MCP protocols.
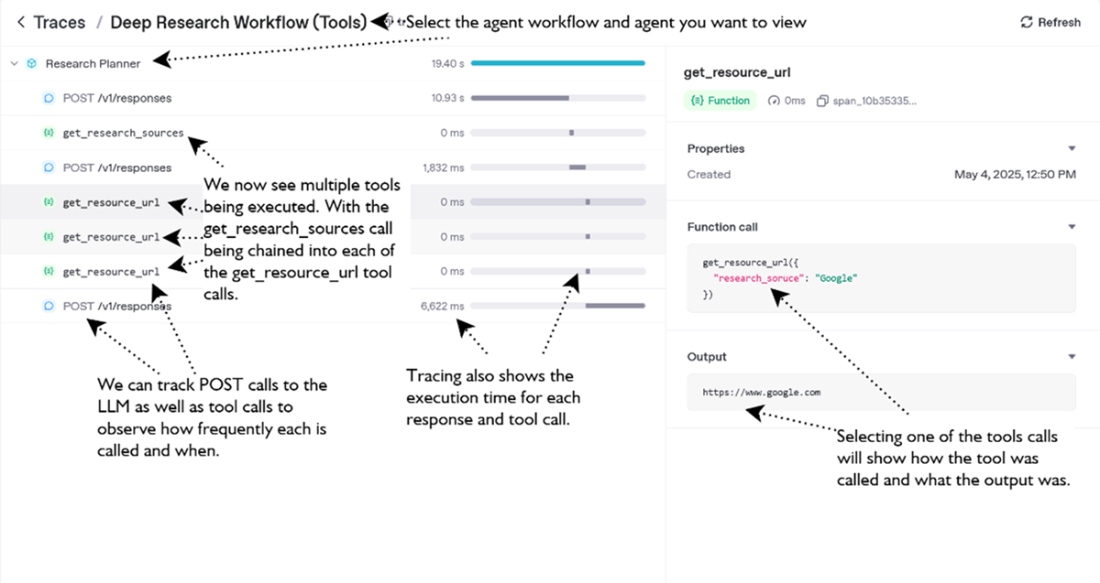
OpenAI Traces page showing the various tool calls and LLM responses executed by the agent
Summary
- Large Language Models are probabilistic token-predictors; understanding tokenization and probability drives effective cost, context, and quality control.
- Text length ≠ token length—measure tokens (e.g., with tiktoken or the Agents SDK telemetry) to keep budgets and context windows in check.
- Generation knobs such as temperature, top-p, max_tokens, and penalty terms let you trade off creativity, consistency, and expense for each agent role.
- Carefully crafted prompts follow the basic rules of clear persona, front-loaded instructions, structured delimiters, few-shot examples, and chain-of-thought, steering LLMs toward reliable, on-spec output.
- Well-structured prompts avoid common pitfalls (over-complexity, contradictions, ambiguous delimiters, or variable output) and make agents safer and cheaper.
- The OpenAI Agents SDK turns a prompt into a runnable agent; you can pin specific models and parameter settings to match the agent’s task profile.
- Typed input/output schemas (Pydantic) eliminate brittle string parsing and keep multi-agent workflows stable despite the LLM’s stochastic nature.
- Built-in tracing in the OpenAI API exposes every LLM interaction and tool invocation, giving vital observability for debugging and optimization.
- Granting agents tools—local functions now, MCP-hosted services later—provides true agency; limit the tool list to reduce token overhead and failure risk.
- Tool chaining lets an agent sequence multiple tool calls autonomously; trace data reveals the decision path and highlights performance bottlenecks.
- Combining prompt engineering, model tuning, typed schemas, tracing, and curated tool sets yields production-ready agents that can confidently plan, reason, and execute deep research tasks.
 AI Agents in Action, Second Edition ebook for free
AI Agents in Action, Second Edition ebook for free