8 Graph, Multimodal, Agentic and other RAG variants
This chapter situates RAG variants as pragmatic adaptations of the standard indexing–retrieval–augmentation–generation loop, created to meet real-world demands such as multimodal inputs, deeper relational reasoning, better accuracy, and lower latency/cost. As RAG moves from simple text search to production settings across domains like healthcare, finance, and software engineering, systems must handle images, audio, video, graphs, and external tools while remaining precise and efficient. The chapter lays out why these variants emerged, what problems they target, how their pipelines change, and the trade-offs they introduce, aiming to equip readers with both conceptual grounding and implementation-oriented guidance.
The three principal variants are Multimodal RAG, Knowledge Graph RAG, and Agentic RAG. Multimodal RAG extends beyond text by introducing modality-aware indexing (specialized loaders and chunkers) and embedding choices—shared multimodal spaces, paired modality models (e.g., image–text, audio–text), or text conversion plus summaries—paired with retrieval strategies that mirror the chosen embedding route and generation via multimodal LLMs; its benefits come with higher complexity, latency, and potential information loss. Knowledge Graph RAG injects structure and relationships through nodes, edges, and triples stored in graph databases, enabling multi-hop reasoning via approaches like hierarchical structure awareness, graph-enhanced vector search, and community detection with summaries; pipelines add entity–relation extraction and graph traversal (e.g., Cypher), but demand careful scoping, cost control, and maintenance. Agentic RAG introduces LLM agents with a core model, memory, planning, and tools to route queries across sources, invoke APIs, adapt retrieval, and iterate retrieval–generation; agents can also enrich indexing (goal-aware chunking, metadata, embedding selection) and generation (dynamic prompting), while requiring safeguards, error containment, and resource budgeting.
Beyond these, the chapter surveys variants that target specific bottlenecks. Corrective RAG (CRAG) evaluates retrieved content, supplements via web search, and refines knowledge to boost factuality. Speculative RAG clusters documents and has small models draft answers in parallel, with a larger verifier selecting the best, cutting latency while preserving quality. Self-RAG trains reflection tokens to decide when to retrieve, assess relevance/support, and critique outputs in real time. RAPTOR builds recursive, tree-structured summaries to capture both granular details and overarching themes for stronger thematic and multi-hop queries. Taken together, these patterns broaden RAG’s applicability: choose based on use-case needs, weigh accuracy against latency and cost, and design for evaluation, governance, and maintainability.
Examples of different data modalities
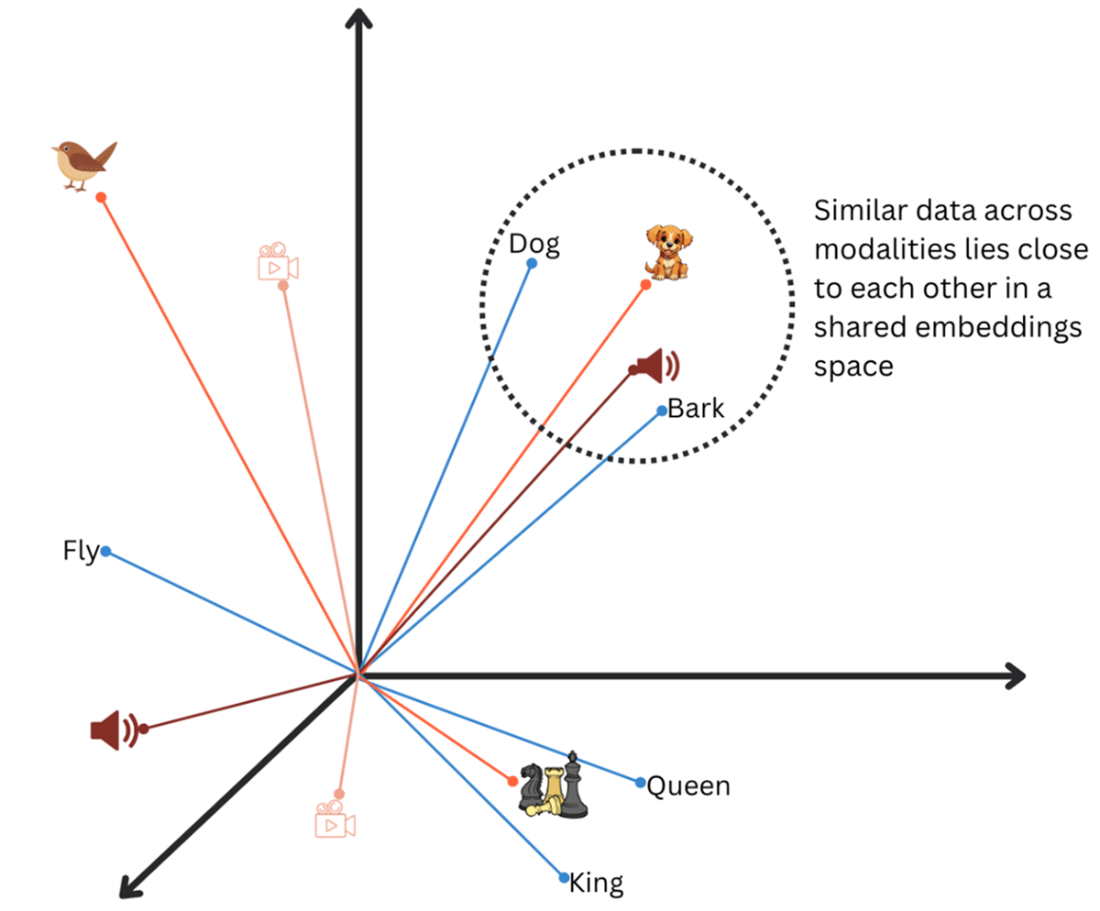
Images, text, video and audio plotted on the same embeddings space. Dog, Bark and Dog’s image close to each other.
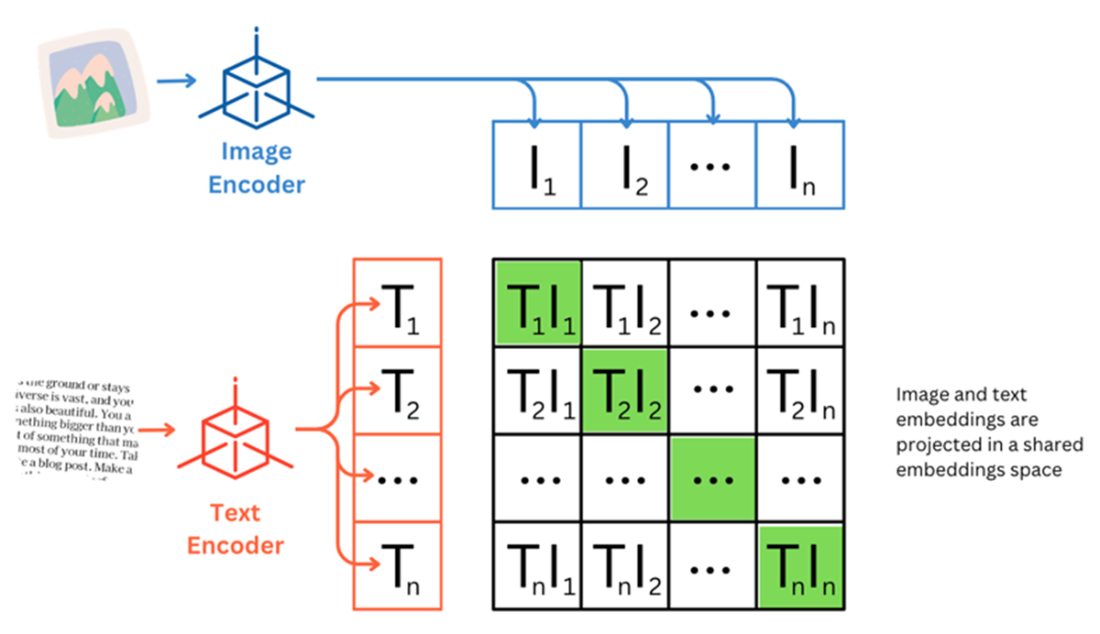
CLIP uses multimodal pre-training to convert classification into a retrieval task, which enables pre-trained models to tackle zero-shot recognition.
Multimodal Indexing pipeline presents three options
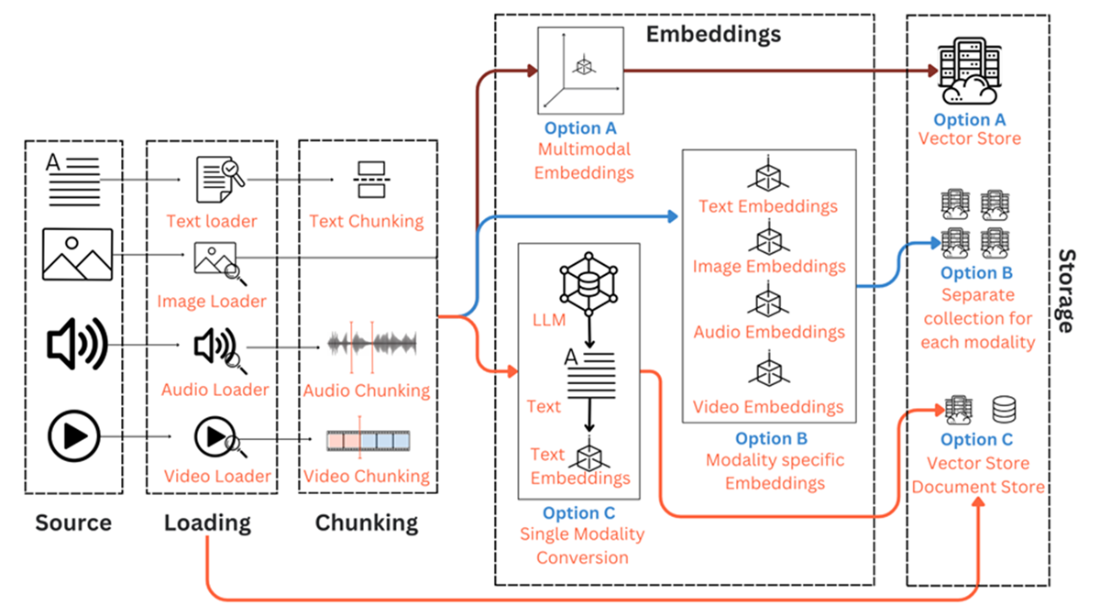
For each of the three approaches, the generation pipeline also adapts
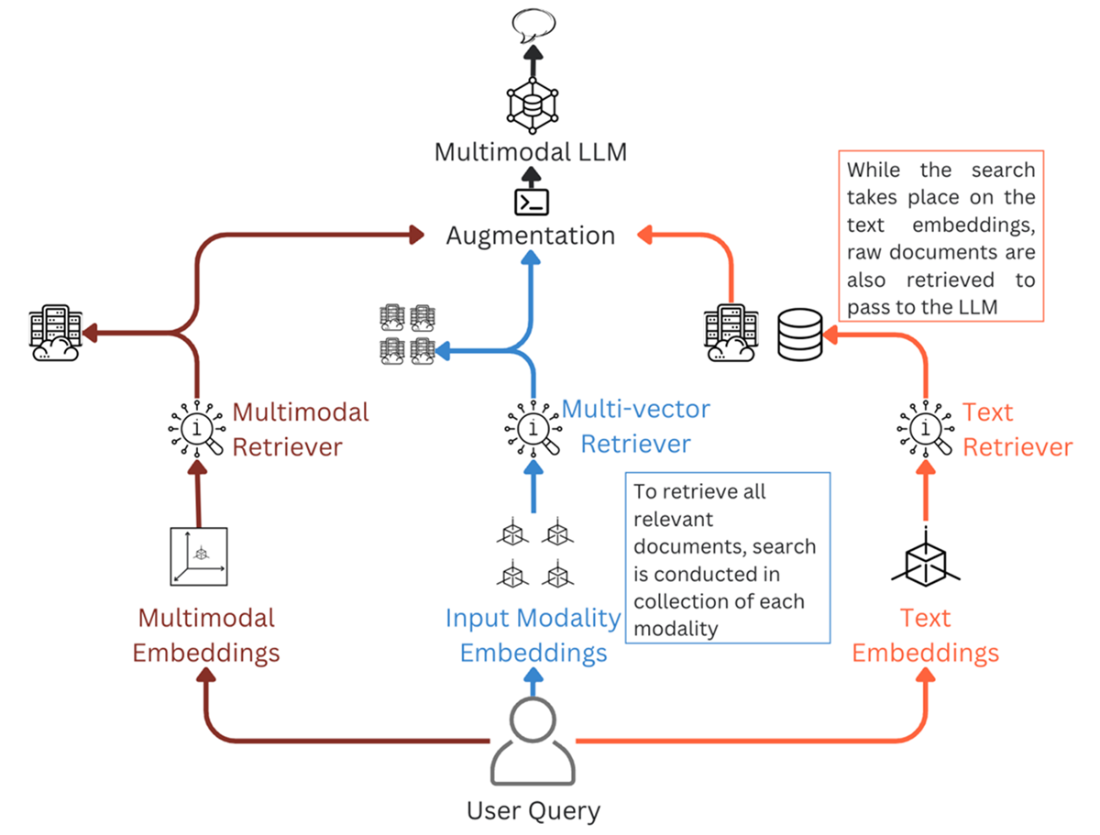
Knowledge Graph representation of customer activity where nodes (circles) represent entities, edges (arrows) represent relationships and attributes (rectangles) are the properties
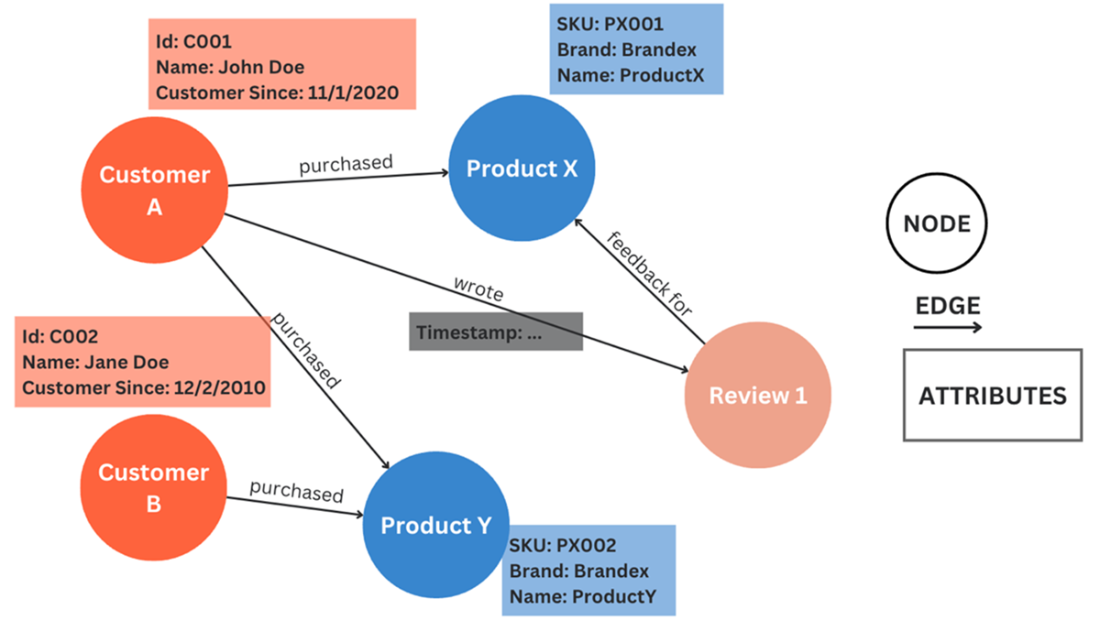
While search in a hierarchical index structure happens at the lowest level, retrieved documents are more contextually complete from a higher level of hierarchy
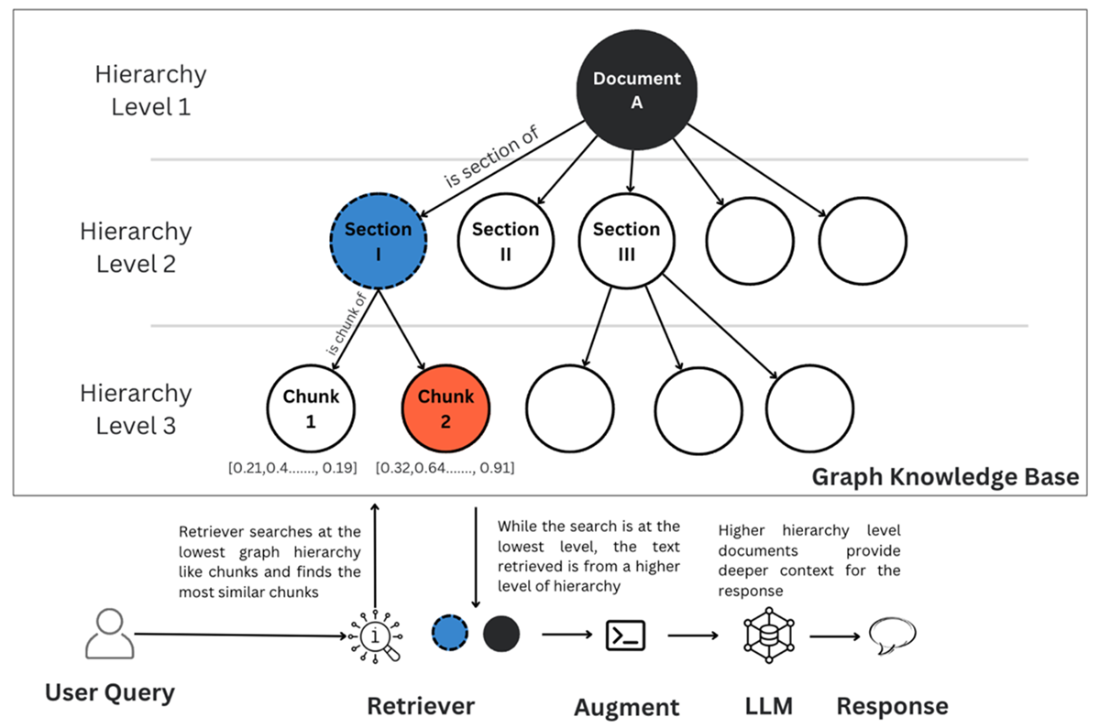
Entities and relationships extracted from the chunks play a crucial role. While chunks that are similar to the user query are retrieved, the chunks that have entities related to the entities of similar chunks are also retrieved.
Communities club entities under a consistent theme and summarize the information at this group level. Since the summaries are created from a high number of thematically related chunks, these summaries can answer broad queries.
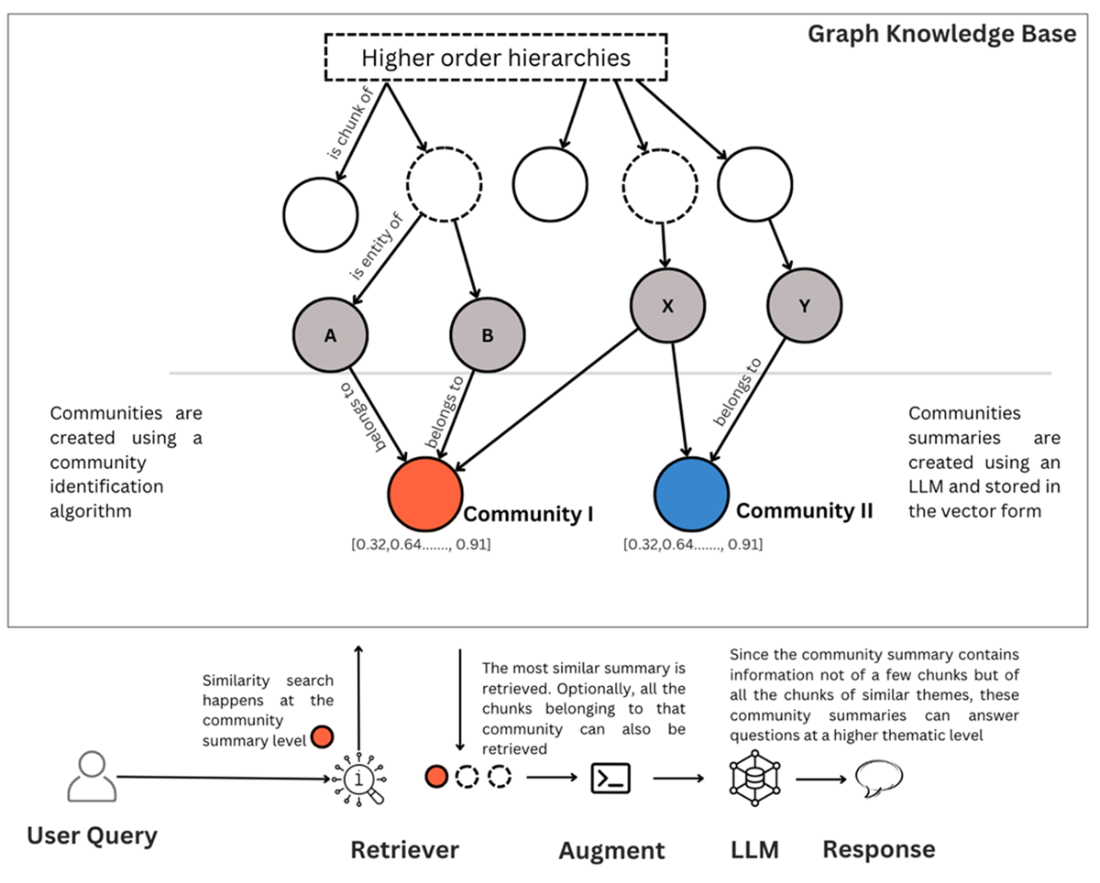
Indexing pipeline for graph RAG. Chunks can directly be stored for simple structure aware indexing and community summaries can be created and stored with the graph
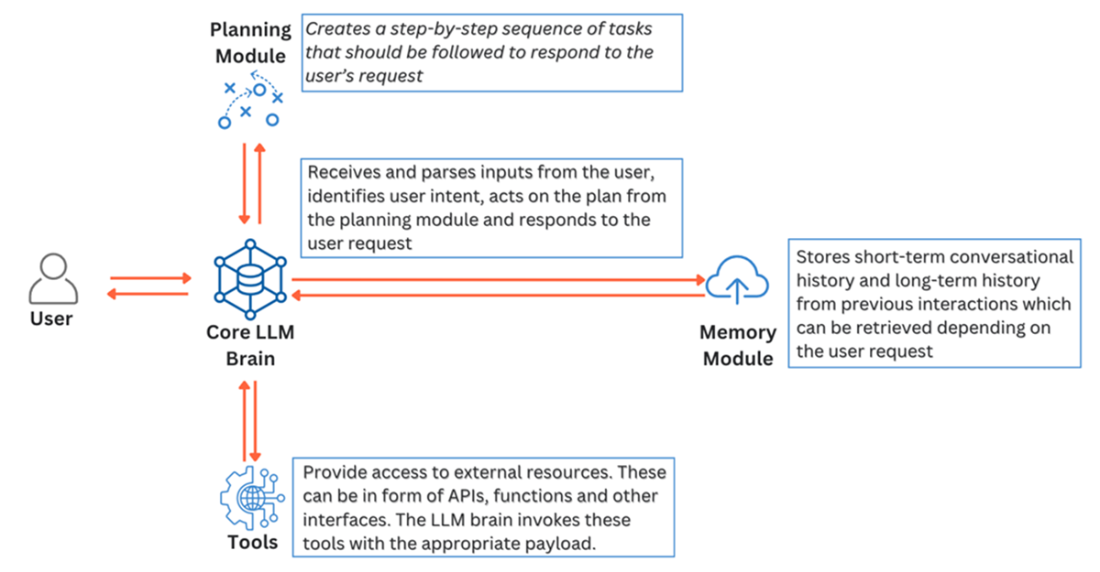
An LLM Agent’s four components break down users query, recall the history of interaction with the user and leverage external tools to accomplish tasks and respond to the user.
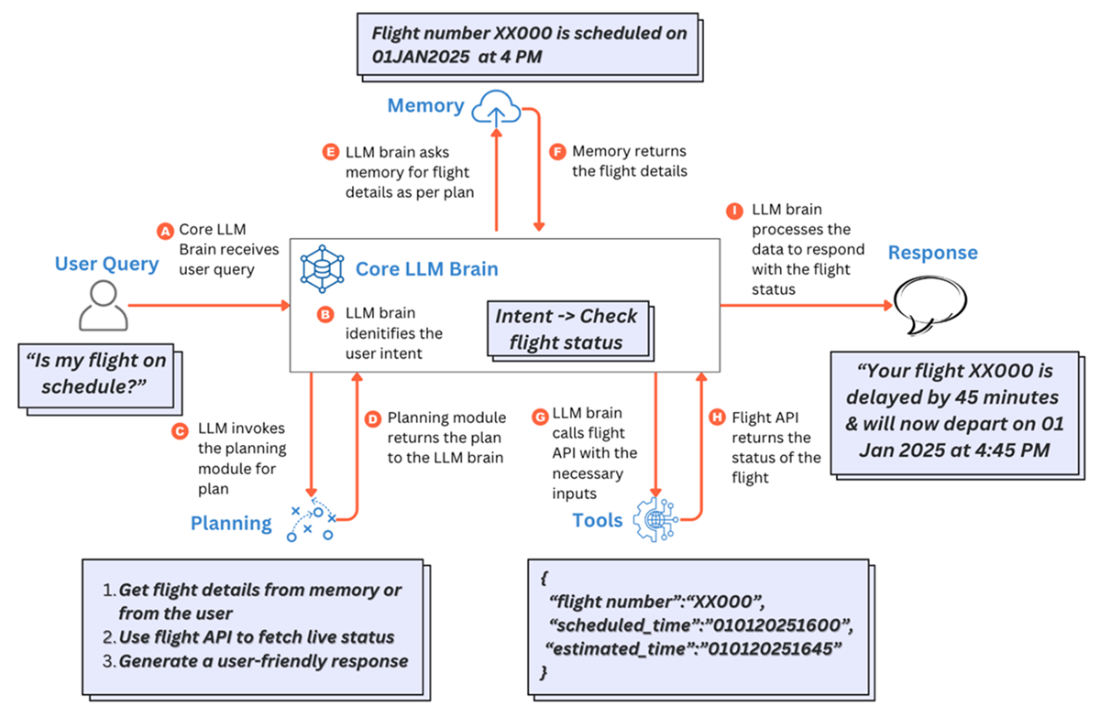
A simple task of responding to user query on flight schedule responded to by an LLM agent by using the planning, memory and tools modules.
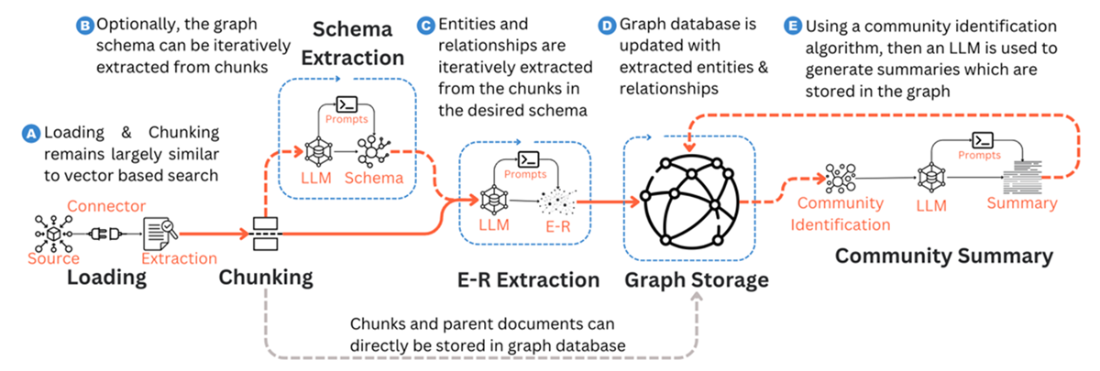
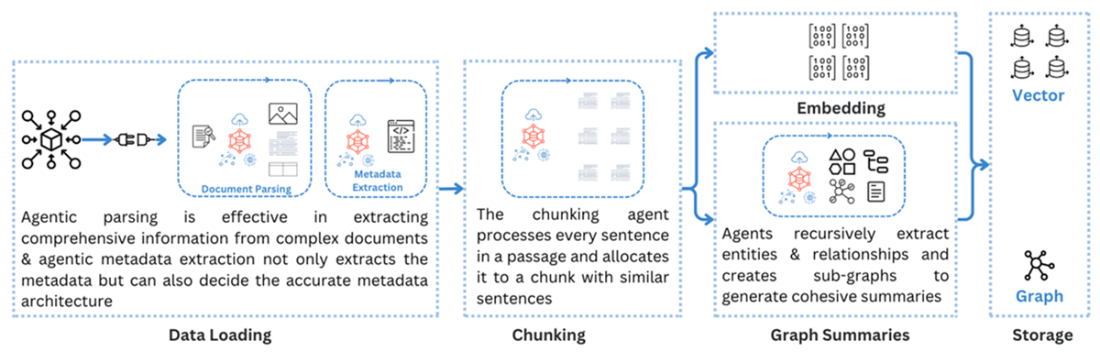
Agentic embellishment to the indexing pipeline enhances the quality of the knowledge base
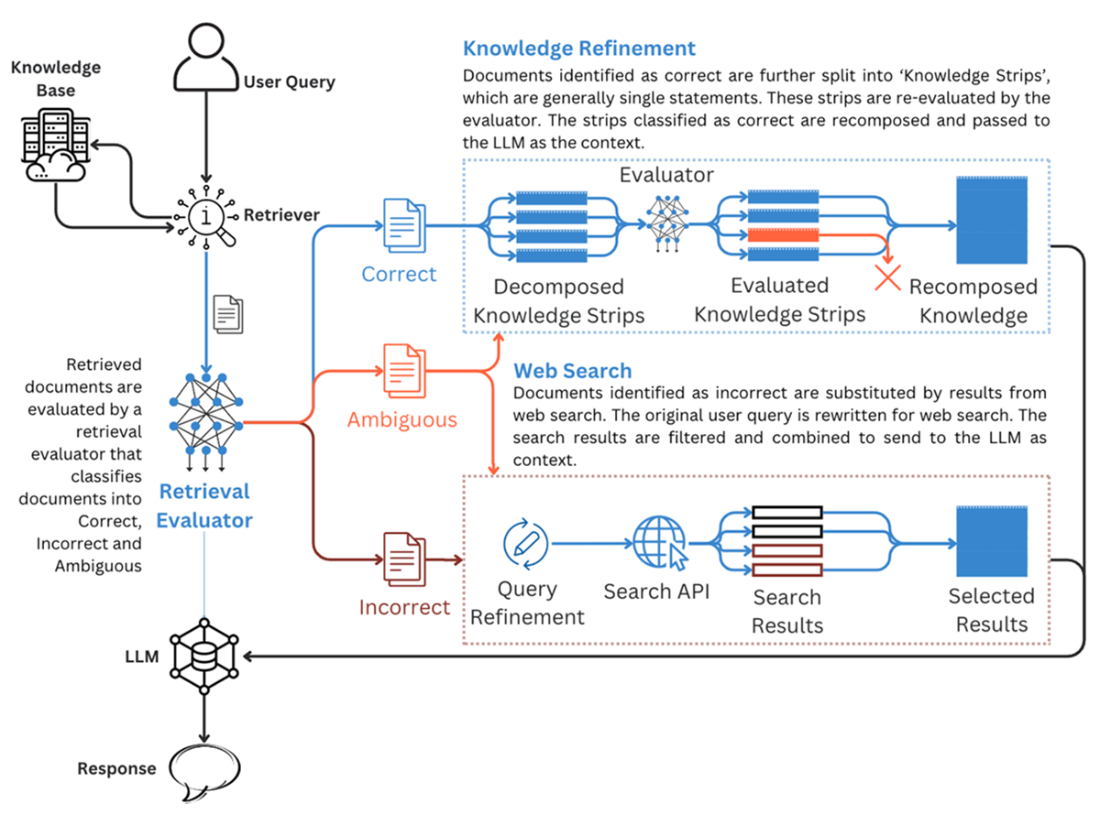
CRAG corrects the knowledge at the most granular level and hence the name Corrective RAG. Source: Corrective Retrieval Augmented Generation (https://arxiv.org/abs/2401.15884)
FAQ
What are RAG variants and why do we need them?
RAG variants are adaptations of the standard RAG pipeline that tailor indexing, retrieval, augmentation, and generation to specific needs. They emerged to handle multimodal data (beyond text), improve relational reasoning across documents, enable adaptive decision-making, and meet production constraints like accuracy, latency, and cost. Key variants in this chapter are Multimodal RAG, Knowledge Graph RAG, and Agentic RAG, plus notable others like CRAG, Speculative RAG, Self RAG, and RAPTOR.How does Multimodal RAG differ from text-only RAG in indexing and generation?
- Indexing: Adds loaders for images/audio/video/tables; uses specialty chunking (e.g., VAD for audio, scene detection for video); introduces multimodal or modality-specific embeddings; stores both vectors and raw files (and mappings if summaries are used).- Generation: Retrieval adapts to embedding strategy (shared-space similarity vs. multi-vector retrieval vs. text-summary retrieval). Prompts include raw files when needed. Uses multimodal LLMs (e.g., GPT‑4o/4o mini, Google Gemini, Llama 3.2, Pixtral) instead of text-only LLMs.
What embedding strategies can I use for multimodal data, and what are the trade-offs?
- Shared (multimodal) embeddings: One vector space for all modalities; enables cross-modal search; simpler ops; can miss fine-grained content (e.g., charts).- Modality-specific (e.g., CLIP image-text, CLAP audio-text): Separate spaces per modality; requires multi-vector retrieval and post-retrieval reranking; better control per modality.
- Convert non-text to text: Transcribe/describe with a multimodal LLM and embed as text; simplest retrieval path but risks information loss. Hybrid variation: retrieve via text summaries, also pass original media to the multimodal LLM at generation time.
What are typical Multimodal RAG use cases?
- Medical diagnosis assistants combining clinical text, tabular labs, and diagnostic images.- Investment analysis across filings, charts, and statements.
- E-commerce buying assistants using product images, specs (tables), and reviews.
- Coding assistants mixing docs and code snippets.
- Equipment maintenance using inspection images/video, sensor data, and reports.
What is Knowledge Graph RAG and when does it help most?
Graph RAG augments vector search with knowledge graphs (nodes, edges, attributes) to capture relationships and support multi-hop reasoning. It helps when answers require connecting information across documents, summarizing themes, disambiguating entities, or traversing complex networks (e.g., treatment interactions, contract dependencies, customer journeys). It’s typically implemented as a hybrid of vectors and graphs, not a replacement.What practical approaches exist to integrate graphs into RAG?
- Structure-aware indexing: Store parent-child (and deeper) hierarchies as a graph; retrieve fine-grained chunks and pull parent context for completeness.- Graph-enhanced vector search: Do a standard similarity search; then traverse the graph to fetch related entities/chunks around initial hits; rerank before generation.
- Community detection and summaries: Detect densely connected subgraphs (e.g., Leiden/Louvain), summarize communities with an LLM, and retrieve at the community level for broad thematic queries.
How do I build a Graph RAG pipeline (tools, storage, and querying)?
- Indexing: Chunk documents; extract entities/relations/attributes with an LLM (e.g., LangChain’s LLMGraphTransformer); iteratively store in a graph DB (e.g., Neo4j via Neo4jGraph). Optionally build community summaries (e.g., graphrag) and store them as vectors for hybrid search.- Retrieval/Generation: Translate natural-language queries into graph queries (Cypher) via templates or LLM-generated queries (e.g., GraphCypherQAChain). Combine graph traversal results with vector hits; augment the prompt with graph-derived text (and community summaries if used).
What is Agentic RAG and what capabilities do agents add?
Agentic RAG embeds LLM-based agents into the pipeline to make autonomous decisions. Capabilities include: query understanding and routing to the most relevant knowledge source; tool usage (web search, SQL, external APIs); adaptive retrieval (iterative reformulation and re-retrieval); dynamic prompting and iterative retrieval-generation (e.g., review and refine answers). Agents can also enhance indexing via smarter parsing, metadata extraction, task-driven chunking, and embedding/storage choices.What are key challenges and best practices for Multimodal, Graph, and Agentic RAG?
- Multimodal: Higher latency/cost; ensure alignment across modalities; include only value-adding modalities; consider text-conversion for simplicity when acceptable.- Graph: Expensive to build/maintain; start narrow and expand; evaluate retrieval accuracy carefully; expect deployment-specific schemas and updates.
- Agentic: Control tool counts and decision scope; add failsafes and guardrails; monitor compounded error rates in multi-agent setups; match autonomy to required accuracy.
Which other RAG variants should I know, and what problems do they target?
- Corrective RAG (CRAG): Evaluates retrieved docs; if weak, triggers web search and knowledge refinement; boosts factual accuracy (adds latency, depends on evaluator quality).- Speculative RAG: Cluster docs; small models draft multiple answers in parallel; a larger model verifies/selects; reduces latency with verification overhead.
- Self RAG: Uses reflection tokens to decide when to retrieve, assess relevance/support, and critique outputs; improves accuracy with extra compute/training needs.
- RAPTOR: Builds a tree of recursive summaries (bottom-up); supports thematic/multi-hop queries with targeted retrieval; computationally heavier and clustering-sensitive.
 A Simple Guide to Retrieval Augmented Generation ebook for free
A Simple Guide to Retrieval Augmented Generation ebook for free