6 Progression of RAG Systems: Naïve to Advanced, and Modular RAG
This chapter motivates the progression from a simple, naïve Retrieval-Augmented Generation pipeline to advanced and modular RAG suitable for production. It diagnoses where naïve RAG breaks down—poor precision and recall in retrieval, redundant and disjointed augmentation constrained by context windows, and generation issues such as hallucination, bias, and over-reliance on retrieved snippets. Framing RAG as two pipelines (indexing and generation), the chapter sets out to improve relevance, faithfulness, and robustness by introducing targeted interventions before, during, and after retrieval.
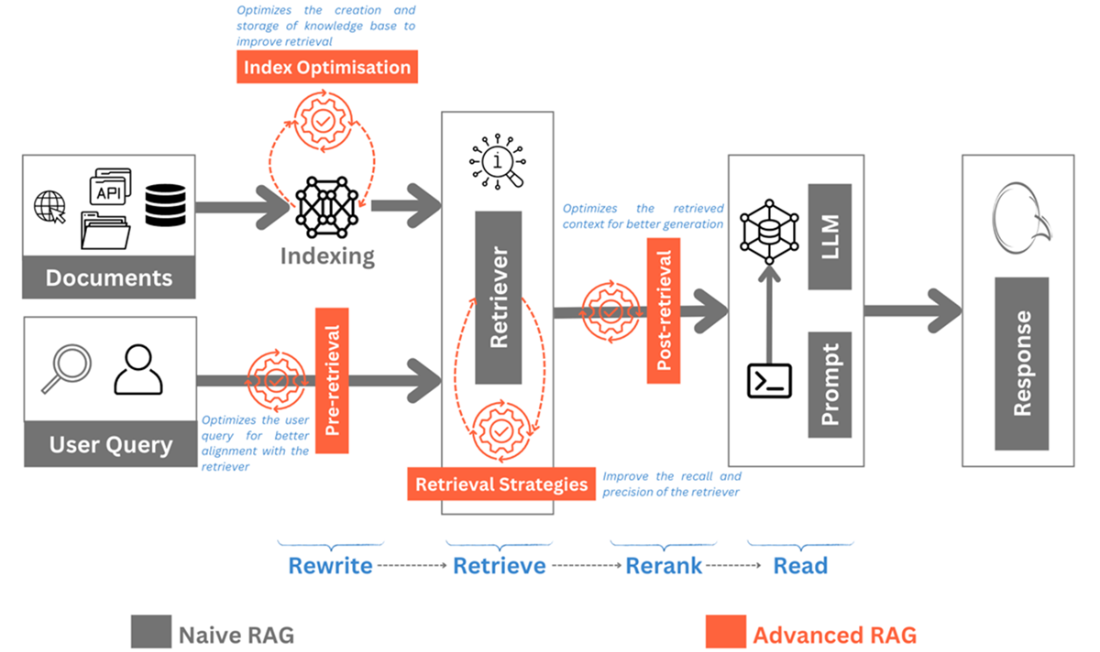
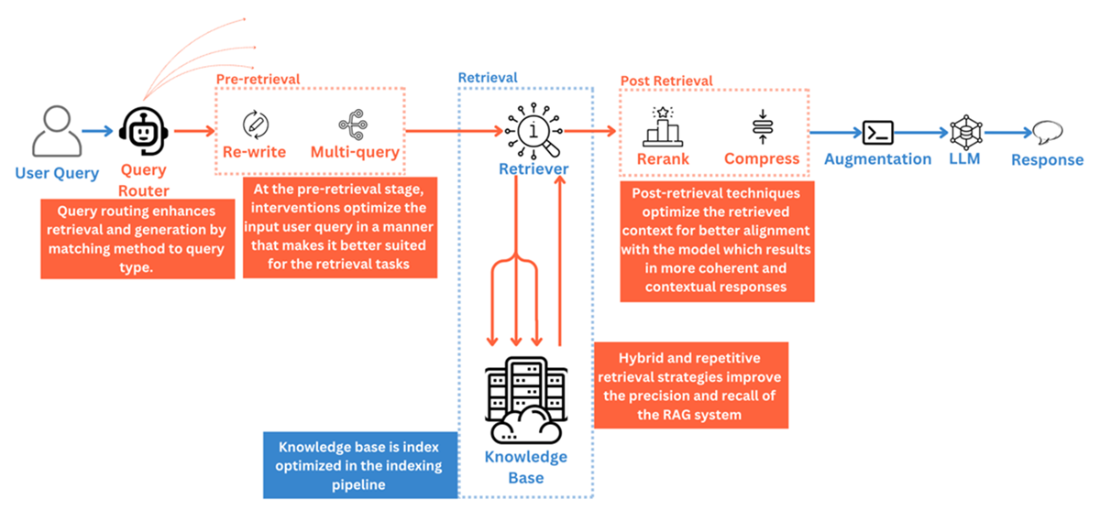
Advanced RAG replaces “retrieve-then-read” with a “rewrite–retrieve–rerank–read” flow and layers techniques across stages. Pre-retrieval emphasizes index optimization (tuning chunk sizes, context-enriched chunking, fetching surrounding chunks, metadata filtering/enrichment, hierarchical and graph-based index structures, and domain-tuned embeddings) and query optimization (multi-/sub-/step-back expansions, rewriting and HyDE-style transformations, and routing via intent, metadata, or semantic similarity). Retrieval improves via hybrid combinations of sparse, dense, and graph search, as well as iterative, recursive, and adaptive strategies that refine or decide retrieval dynamically. Post-retrieval focuses on compression to reduce noise and fit context windows, and reranking to prioritize the most relevant evidence. Throughout, the chapter stresses trade-offs: these gains typically add compute, latency, and system complexity, so choices should be driven by use-case evaluation.
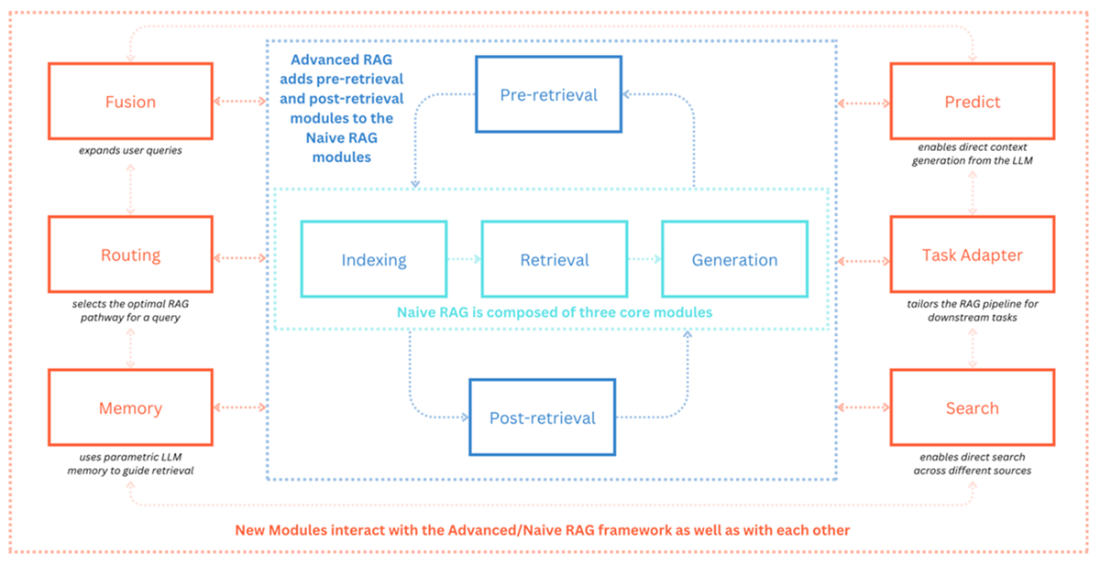
Modular RAG generalizes these ideas into a composable architecture where core components—Indexing, Retrieval, Generation, plus Pre- and Post-retrieval—are interchangeable, and new modules augment capability: Search (source-specific access), Fusion (multi-query expansion and result merging), Memory (judicious use of the model’s parametric knowledge), Routing (path selection across tools and data), and Task Adapters (lightly tailoring for downstream tasks). The chapter positions naïve RAG as a subset of advanced RAG, which itself is a subset of modular RAG, encouraging incremental adoption. While modularity enables rapid experimentation, scalability, and maintainability, it also demands clear interfaces, orchestration, compatibility testing, and careful performance–cost–latency balancing to deliver production-grade systems.
Naïve RAG is a sequential “Retrieve then Read” process.
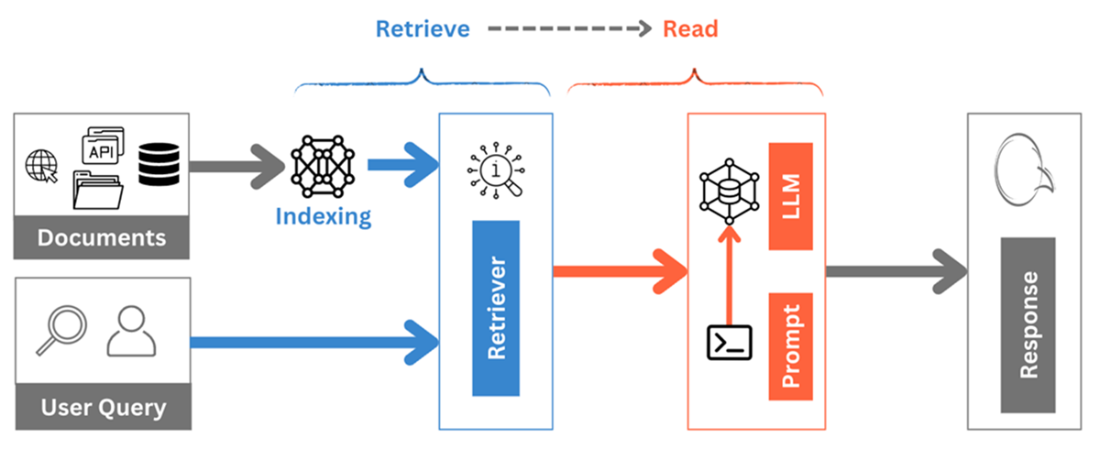
Drawbacks of Naïve RAG at each stage of the process

Advanced RAG is a Rewrite-Retrieve-Rerank-Read process as compared to a Retrieve-Read Naïve RAG process
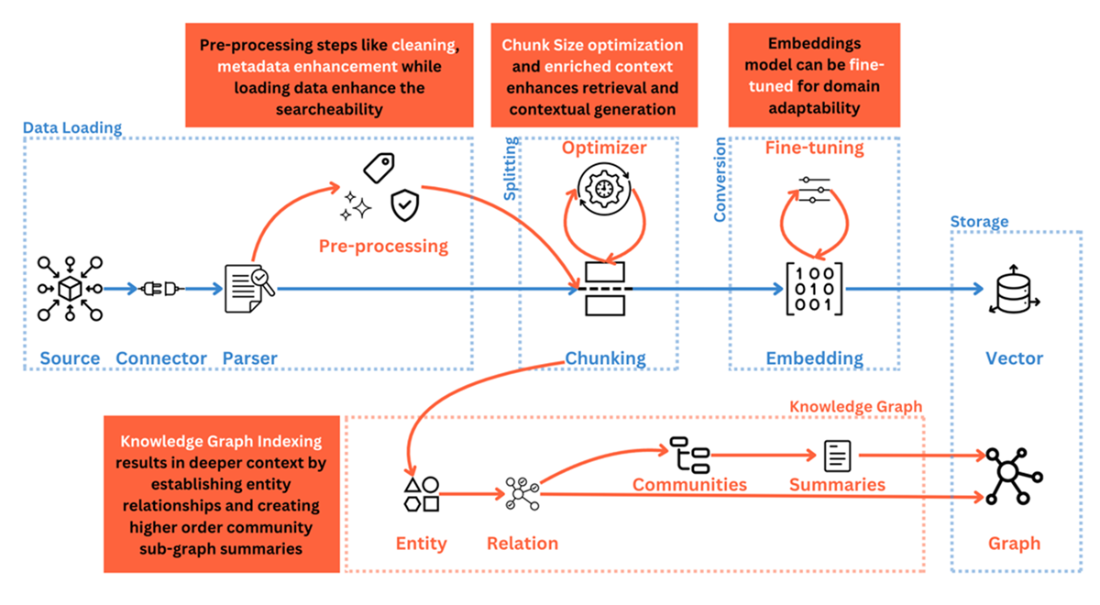
An illustration of an index optimized knowledge base
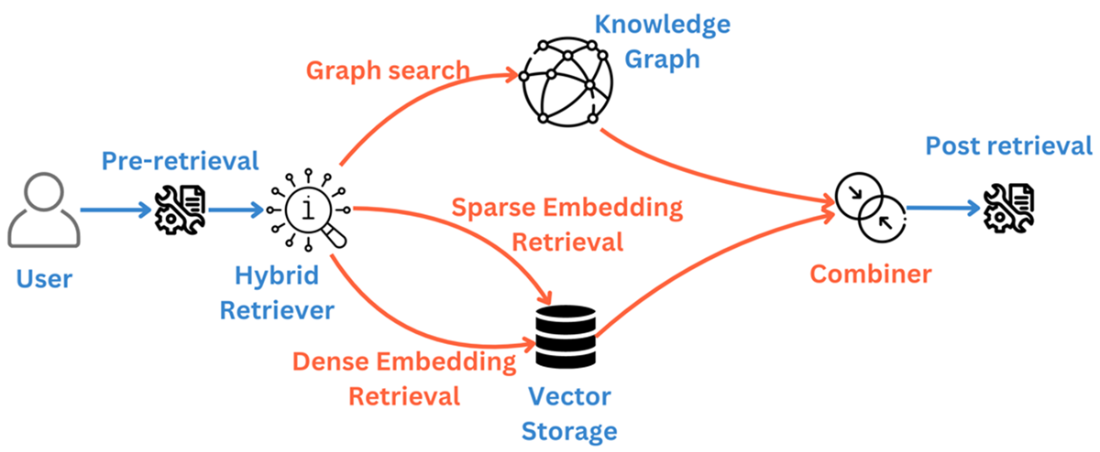
Hybrid retriever employs multiple querying techniques and combines the results
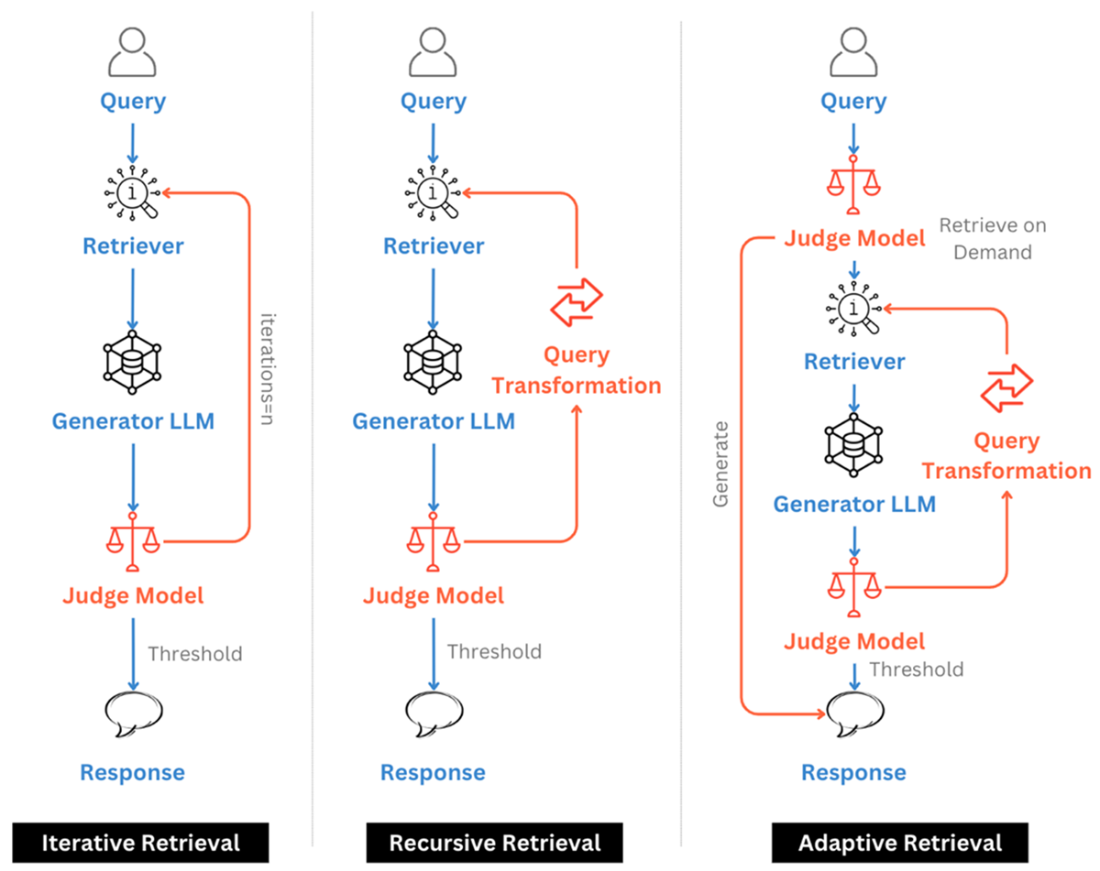
Iterative, Recursive and Adaptive retrieval incorporate repeated retrieval cycles. (Source – Adapted from Retrieval-Augmented Generation for Large Language Models: A Survey, Gao et al)
Illustrative example of advanced generation pipeline.
Naïve, Advanced and Modular approaches to RAG are progressive in nature. Naïve RAG is a sub-component of Advanced RAG which is a sub-component of Modular RAG
FAQ
Why is the Naïve “Retrieve-then-Read” RAG approach inadequate for production?
- Retrieval: Low precision (irrelevant chunks) and low recall (misses relevant info).
- Augmentation: Redundant or overlapping chunks, disjointed context from multiple sources, and limits due to LLM context windows.
- Generation: Hallucinations, bias/toxicity risks, difficulty reconciling conflicting info, and over-reliance on retrieved context over model knowledge.
How does Advanced RAG improve on Naïve RAG?
Advanced RAG shifts from “Retrieve-then-Read” to “Rewrite → Retrieve → Rerank → Read.” It optimizes the query (rewrite/expand/transform), enhances retrieval (hybrid/iterative/recursive/adaptive), reranks results to prioritize relevance, and then generates, leading to higher faithfulness and relevance.
What pre-retrieval index optimization techniques strengthen retrieval?
- Chunk Optimization: Tune chunk size to balance context vs. noise; consider fetching surrounding chunks to preserve flow in long-form content.
- Context-Enriched Chunking: Attach a document or section summary to each chunk for richer context with modest overhead.
- Operational Trade‑offs: Better accuracy vs. higher compute, storage, and latency; reassess as data and use cases change.
How do metadata enhancements and embedding fine-tuning boost searchability?
- Metadata Filtering: Use attributes (timestamp, author, category) to pre-filter before similarity search, reducing noise and avoiding stale content.
- Metadata Enrichment: Add summaries, tags, or synthetic queries (e.g., Reverse HyDE-style prompts) to improve matching.
- Fine-tuning Embeddings: For domain-specific language, fine-tune embedding models to improve semantic similarity and retrieval quality.
Which index structures can improve retrieval, and when should I use them?
- Parent–Child Structure: Retrieve precise child chunks and refer to parent for broader context; helpful when documents are hierarchical.
- Knowledge Graph Index (GraphRAG): Store entities and relations to improve context, reasoning, and explainability; best for large, complex domains despite higher build/maintenance cost.
How can I optimize user queries before retrieval?
- Query Expansion: Generate multiple variants (multi-query), decompose into sub-queries, or “step back” to a higher-level abstraction to boost recall.
- Query Transformation: Rewrite vague inputs into retrieval-suitable queries; use HyDE to create a hypothetical answer and embed it for similarity search.
- Caveats: Avoid over-expansion and drift; ensure intent is preserved.
What is query routing and when is it essential?
Routing selects the best retrieval workflow per query based on intent, domain, language, or complexity.
- Intent Classification: Use a classifier or LLM prompts to pick a retrieval path.
- Metadata Routing: Extract keywords/tags from the query to filter by chunk metadata.
- Semantic Routing: Match the query to representative exemplars for each method and choose the closest.
Use routing when sources and query types vary widely (e.g., support bots handling technical vs. billing queries).
Which retrieval strategies should I consider beyond basic similarity search?
- Hybrid Retrieval: Combine keyword (e.g., BM25), dense vectors, and graphs; union/intersection with weights for precision/recall control.
- Iterative Retrieval: Alternate retrieval and generation to refine searches for multi-hop questions.
- Recursive Retrieval: Transform queries from retrieved evidence to uncover scattered info (e.g., IRCoT).
- Adaptive Retrieval: Let an LLM decide when/what to retrieve during generation (e.g., Self-RAG, FLARE); aligns with agentic AI.
All add compute and latency; tune for your cost/accuracy target.
What post-retrieval techniques help the LLM use context effectively?
- Compression: Remove irrelevant tokens or compress to context embeddings (e.g., COCOM, xRAG) to reduce noise and fit context windows.
- Reranking: Reorder retrieved chunks so the most relevant, task-aligned evidence is prioritized (e.g., LTR/BERT-based or API rerankers).
Balance compression against potential information loss; reranking adds overhead but boosts answer quality.
What is Modular RAG, and what modules does it include?
Modular RAG decomposes RAG into swappable components for flexibility, scalability, and rapid experimentation. Naïve RAG is a subset of Advanced RAG, which is a subset of Modular RAG.
- Core Modules: Indexing (embeddings/vector stores/chunkers), Retrieval (dense/keyword/graph), Generation (LLM choice and augmentation), plus Pre- and Post-retrieval modules.
- New Modules: Search (multi-source), Fusion (RAG-Fusion: multi-query + merge/rerank), Memory (use LLM parametric knowledge, reflection tokens), Routing (pick optimal path), Task Adapter (tailor to tasks like summarization/translation).
Trade-offs: Greater compatibility, interface, and orchestration complexity; potential added latency/cost; requires robust testing of modules individually and in combination.
 A Simple Guide to Retrieval Augmented Generation ebook for free
A Simple Guide to Retrieval Augmented Generation ebook for free