5 RAG Evaluation: Accuracy, Relevance, Faithfulness
This chapter explains why rigorous evaluation is essential for Retrieval-Augmented Generation: it verifies that retrieved context is relevant and that generated answers are grounded and useful. It frames quality along three core dimensions—context relevance, answer faithfulness (groundedness), and answer relevance—and highlights system abilities that matter in practice: noise robustness, negative rejection, information integration, and counterfactual robustness. Beyond accuracy, it urges attention to latency, robustness across query types, and ethical considerations such as bias and toxicity. Because RAG serves diverse applications, the chapter stresses designing use‑case‑specific criteria alongside general measures.
The chapter groups metrics into retrieval metrics (precision, recall, F1, MRR, MAP, nDCG) and RAG‑specific metrics that directly assess the three quality scores. It discusses how human judgments and ground truth datasets anchor evaluations, and how synthetic data can scale this process. Frameworks help automate end‑to‑end assessment: RAGAs offers fast, practical evaluation and synthetic test generation using an LLM-as-judge, while ARES trains classifiers and reports confidence intervals, generating both positive and negative examples. Interpreting metric trends guides improvements—e.g., precision/recall trade‑offs for retrievers, ranking issues indicated by MRR/nDCG, or prompt/LLM adjustments for faithfulness and answer relevance.
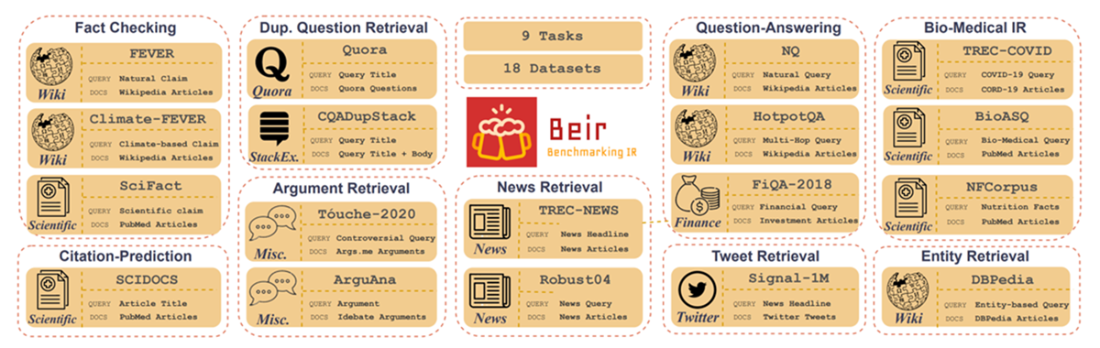
For comparison across systems, the chapter reviews benchmarks: classic QA sets (such as SQuAD, Natural Questions, HotpotQA) and BEIR emphasize retrieval, while newer RAG-focused suites—RGB (robustness and rejection), Multihop RAG (multi-document reasoning and null queries), and CRAG (diverse domains with four-class grading)—provide more holistic coverage. It also outlines current limitations: inconsistent metric definitions, reliance on LLMs as judges (and potential self-reference), static benchmarks that miss evolving knowledge, and scalability/cost concerns. Recommended practices include combining multiple frameworks and metrics, adding human review, tailoring evaluations to domain and task, tracking latency and safety signals, using different judge models, and regularly updating datasets and methods as the field evolves.
Precision and Recall
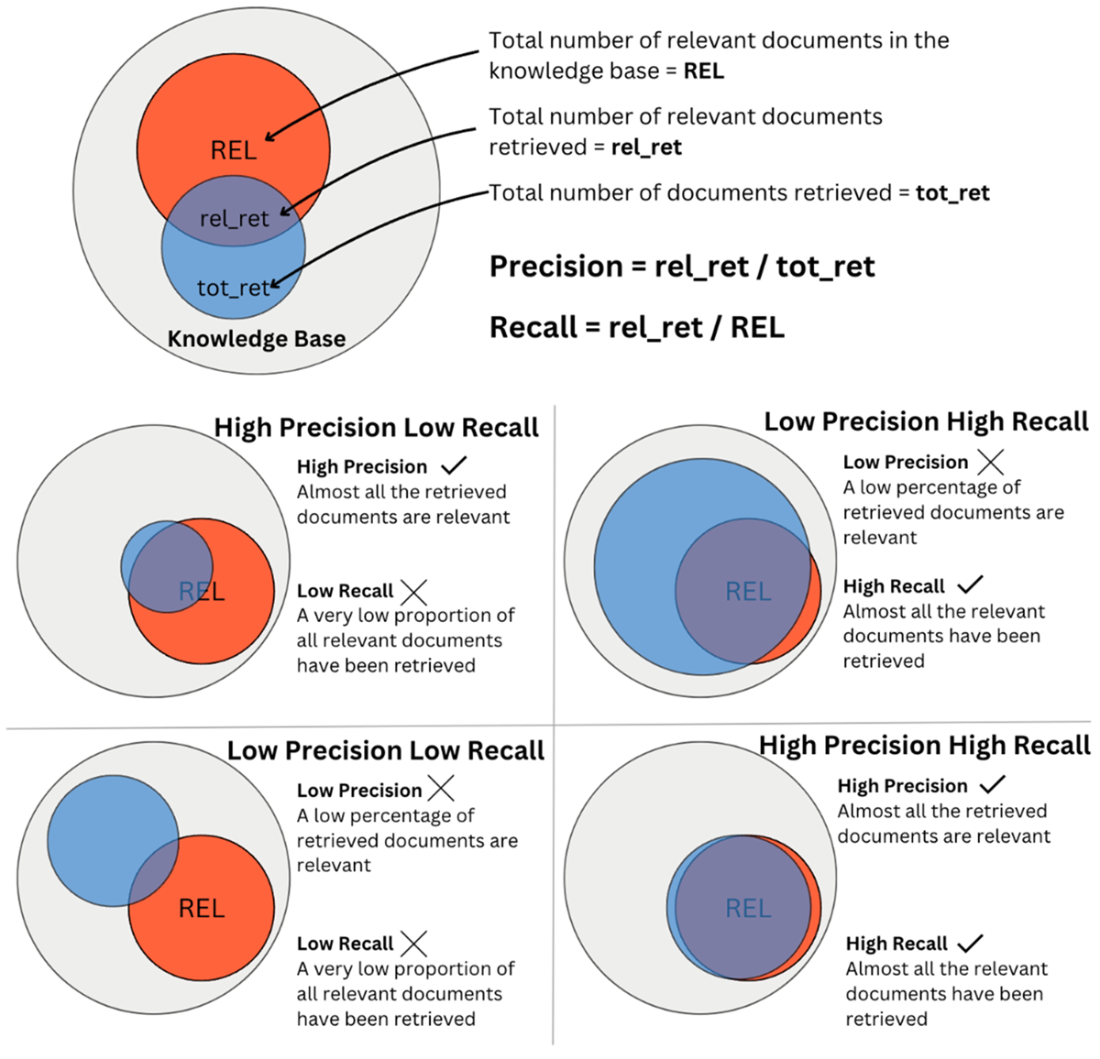
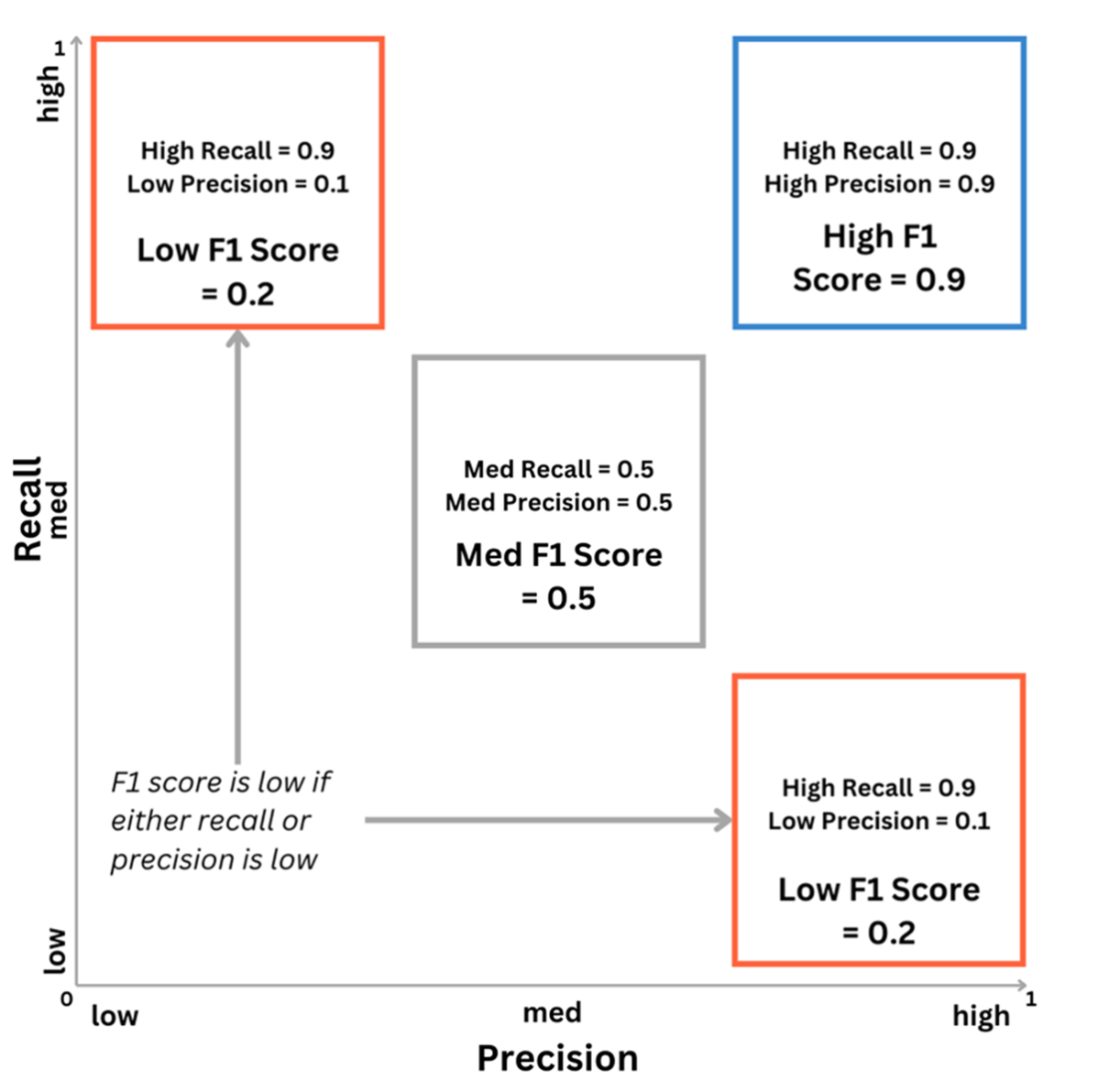
f1-score balances precision and recall. A medium value of both precision and recall gets a higher f1-score than if one value is very high and the other is very low.
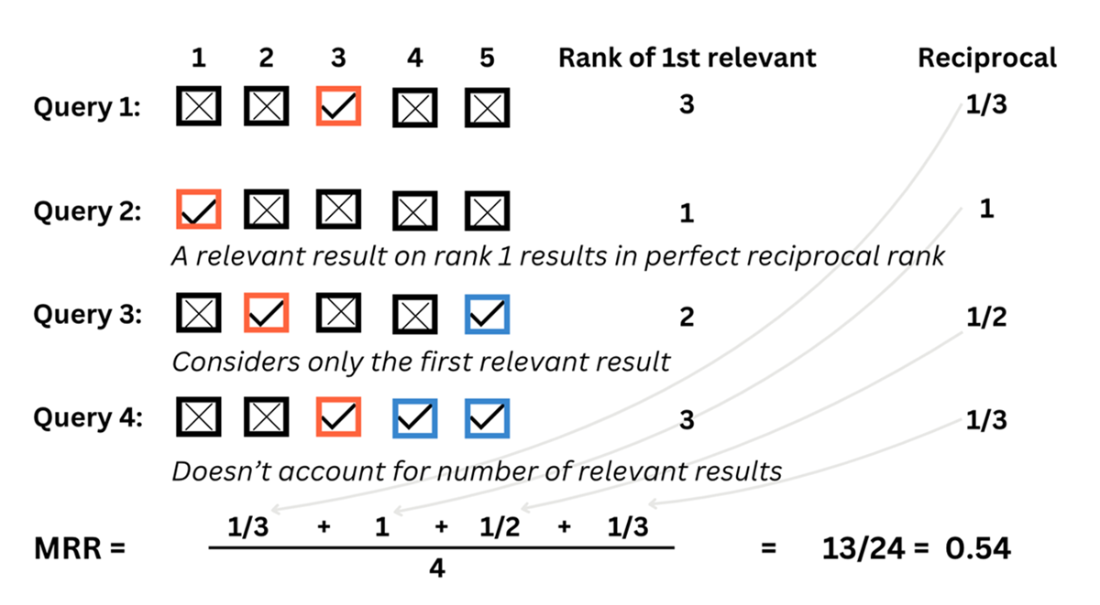
MRR considers the ranking but doesn’t consider all the documents
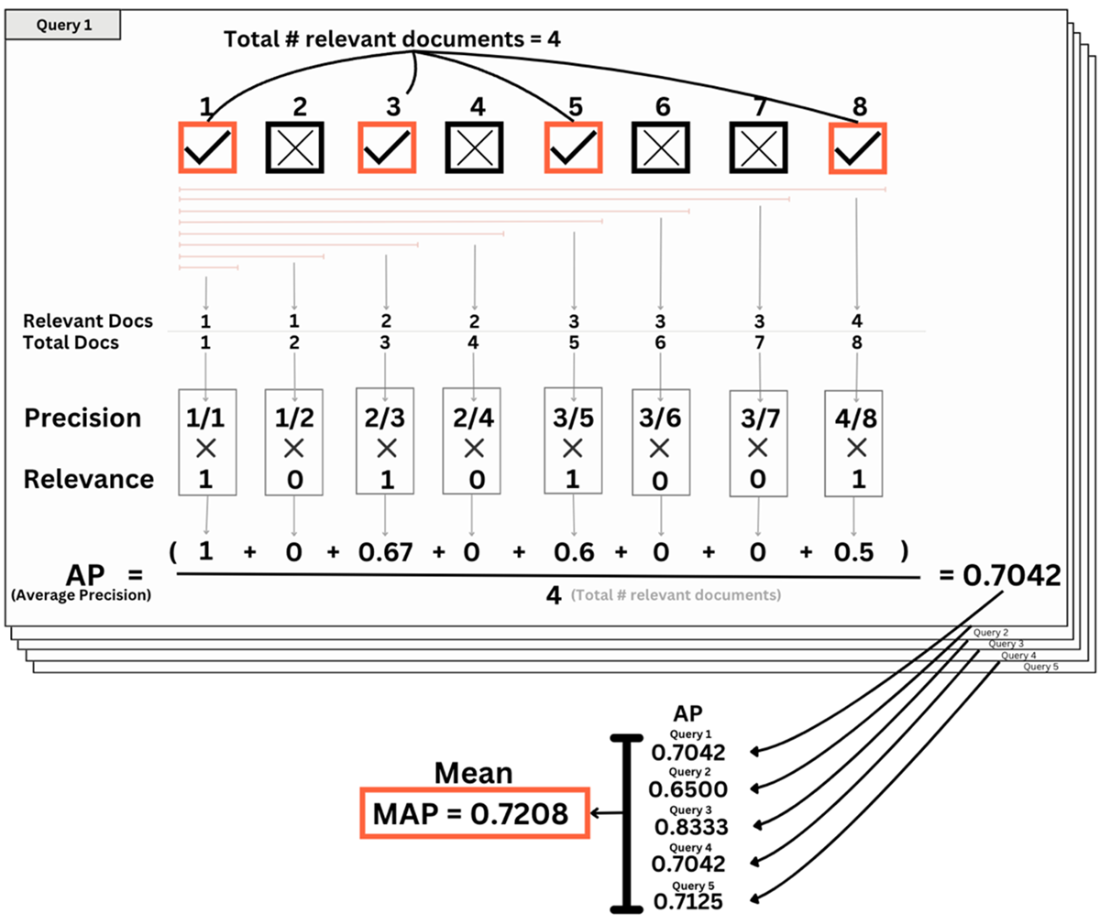
MAP considers all the retrieved documents and gives a higher score for better ranking
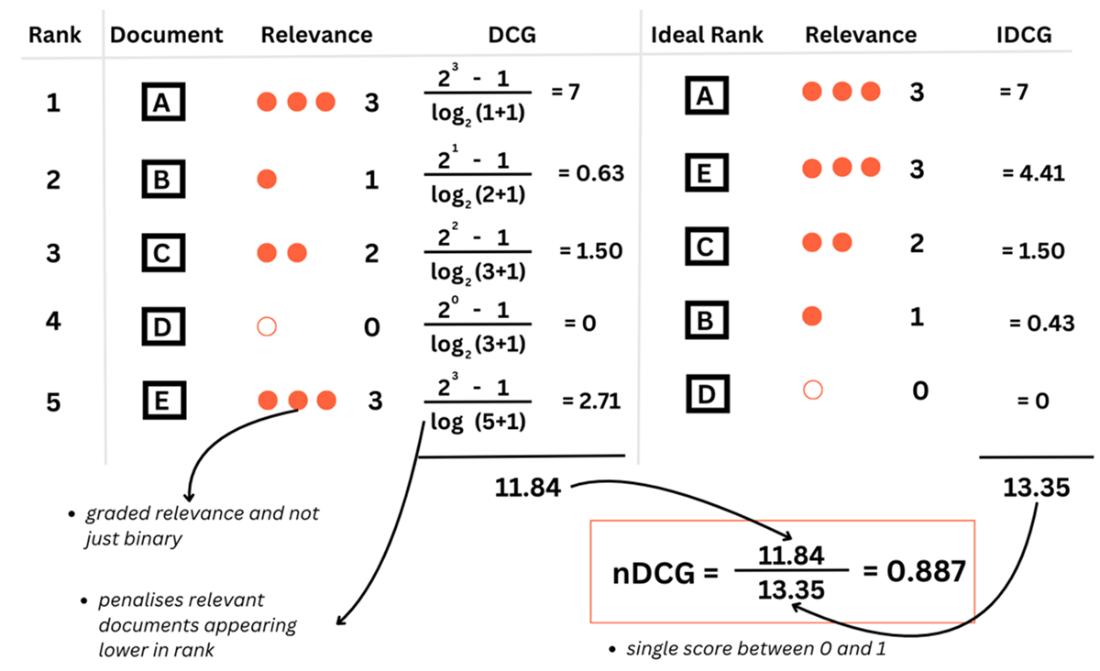
nDCG addresses degrees of relevance in documents and penalizes incorrect ranking
Context relevance evaluates the degree to which the retrieved information is relevant to the query

Answer Faithfulness evaluates the closeness of the generated response to the retrieved context

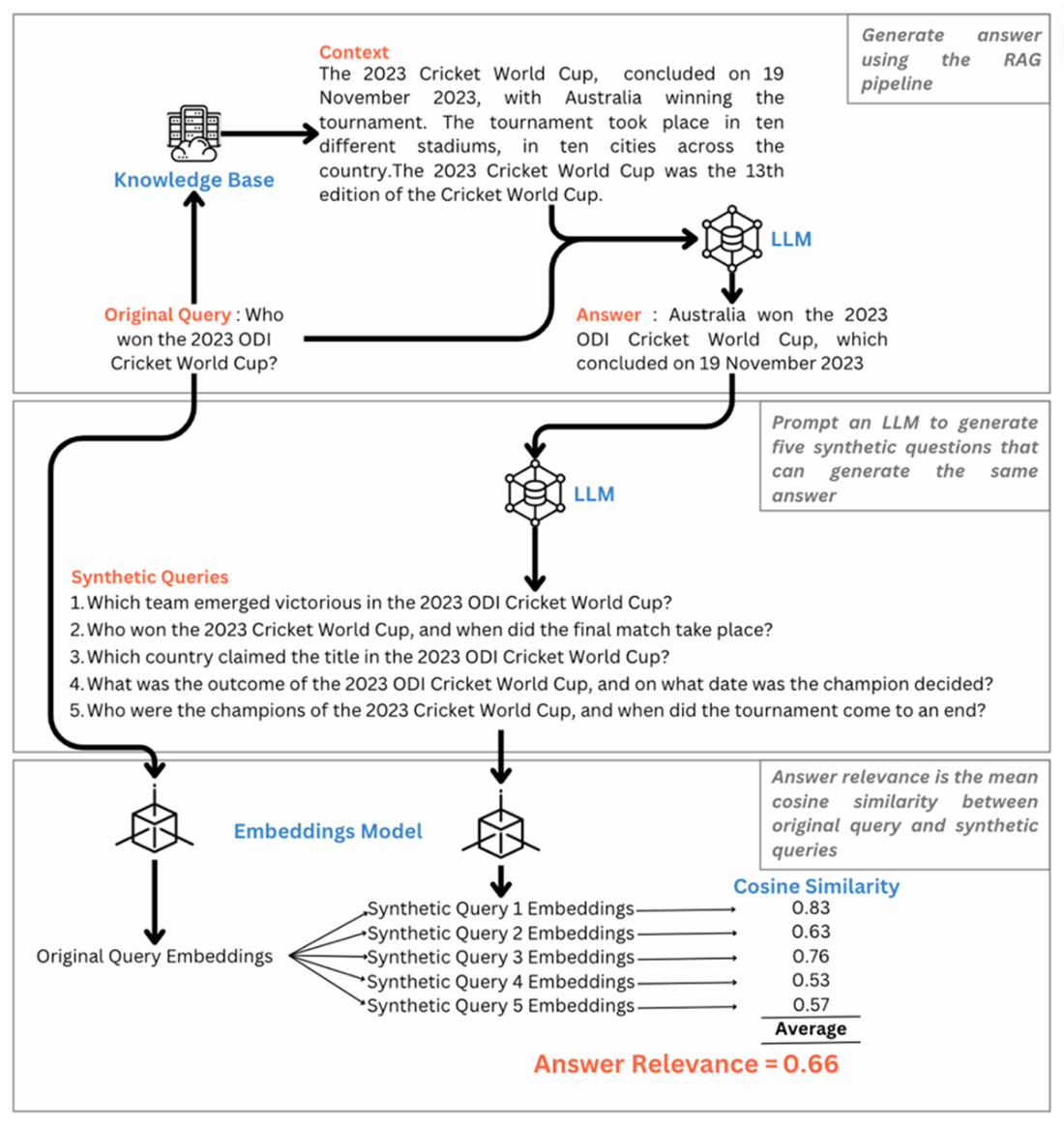
Answer relevance is calculated as mean of cosine similarity between original and synthetic questions.
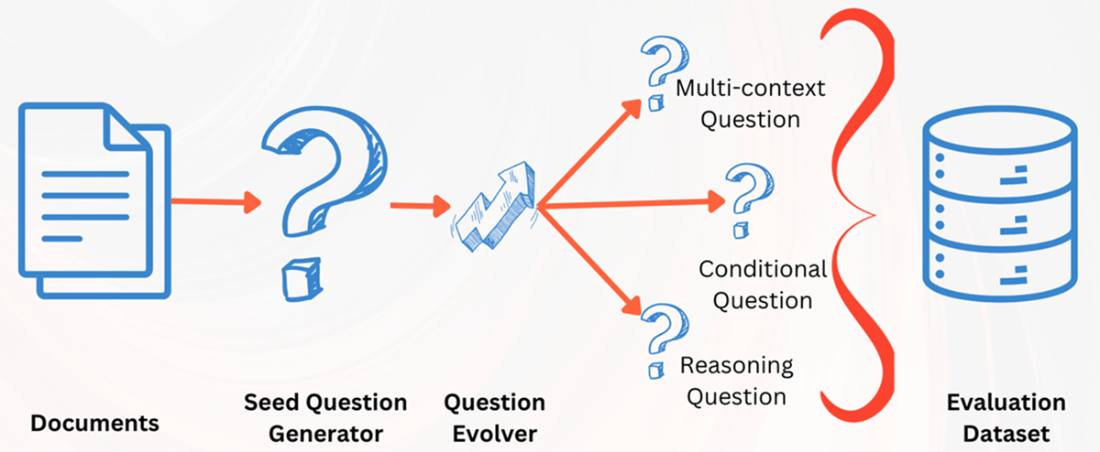
Synthetic ground truths data generation using RAGAs
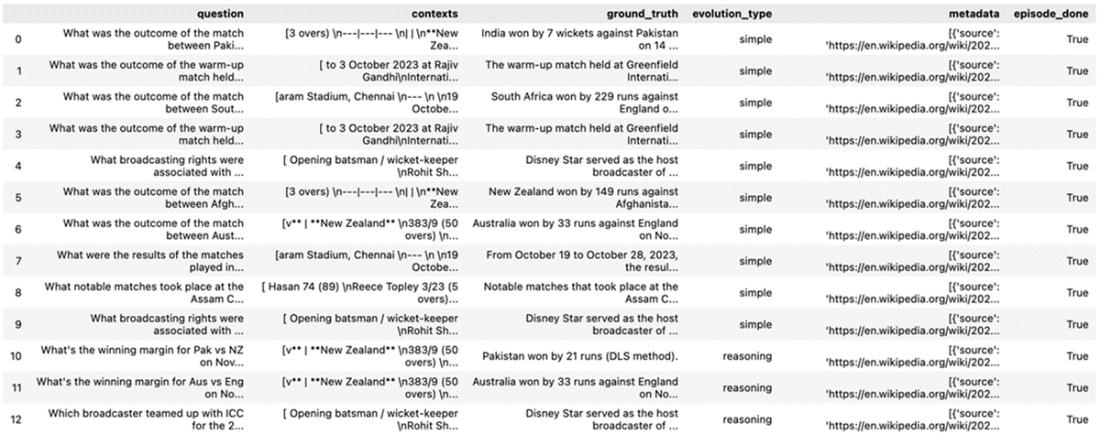
Synthetic test data generated using RAGAs
BEIR – 9 tasks and 18 (of 19) datasets (Source: BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models https://arxiv.org/pdf/2104.08663v4)
Four abilities required of RAG systems (Source: Benchmarking Large Language Models in Retrieval-Augmented Generation, Chen et al - https://arxiv.org/pdf/2309.0143)

8 question types in CRAG.

FAQ
Why evaluate a RAG pipeline at all?
To verify two things: (1) the retriever returns context that is relevant to the query, and (2) the generator produces answers grounded in that context. Evaluation establishes a performance baseline, guides improvements, and enables fair comparison with other systems via standardized metrics, frameworks, and benchmarks.What are the three core RAG quality scores?
- Context Relevance: How well the retrieved passages align with the user query.- Answer Faithfulness (groundedness): Whether the answer’s claims are supported by the retrieved context (lowers hallucinations).
- Answer Relevance: How directly and completely the answer addresses the original query (not the same as truthfulness).
Which abilities should a robust RAG system demonstrate?
- Noise Robustness: Filter out related-but-useless passages.- Negative Rejection: Say “I don’t know” when the KB lacks relevant info.
- Information Integration: Combine evidence across multiple documents.
- Counterfactual Robustness: Detect and reject incorrect or conflicting context.
Which retrieval metrics should I track, and what do they capture?
- Precision / Recall / F1: Basic quality and coverage (don’t consider ranking).- Precision@k: Quality of the top-k results that will feed augmentation.
- MRR: How early the first relevant result appears.
- MAP: Precision across recall levels with ranking sensitivity.
- nDCG: Ranking quality with graded (multi-level) relevance.
How do RAG-specific metrics differ from common NLG metrics like BLEU/ROUGE?
BLEU/ROUGE focus on surface overlap and fluency; they don’t assess grounding in retrieved context. RAG-specific metrics (context relevance, answer faithfulness, answer relevance) explicitly measure whether the system retrieved the right evidence, used it faithfully, and answered the user’s question.How does the “LLM as a judge” approach work, and what are its risks?
An LLM scores relevance/faithfulness by classifying claims or comparing questions/answers. Risks include dependence on the judge model’s quality, potential bias, and “self-reference” if the same model generates and judges. Mitigations: use a different judge LLM, sample and manually spot-check, or ensemble multiple judges.What is RAGAs and when should I use it?
RAGAs is an evaluation framework that: (1) synthetically generates test Q-C-A data from your corpus, (2) computes RAG-specific and related metrics (e.g., context precision/recall, faithfulness, answer relevancy), and (3) supports production monitoring. Use it for quick, practical evaluations without heavy human annotation.What is ARES and how does it differ from RAGAs?
ARES (Stanford/Databricks) also uses LLM-as-judge but: (1) trains a classifier instead of relying solely on prompt heuristics, (2) reports confidence intervals via prediction-powered inference, and (3) builds positive/negative synthetic triples with a human-preference validation set. Use it for deeper, statistically grounded analysis (with more setup).Which benchmarks are popular for RAG and what do they test?
- Retrieval-focused: SQuAD, Natural Questions, HotpotQA, BEIR (ranking via nDCG), mainly test retrieval quality.- RAG-oriented: RGB (noise/negative rejection/integration/counterfactual), Multihop RAG (multi-doc, inference/comparison/temporal/null), CRAG (8 question types, graded scoring). Choose based on the abilities and domains you need.
 A Simple Guide to Retrieval Augmented Generation ebook for free
A Simple Guide to Retrieval Augmented Generation ebook for free