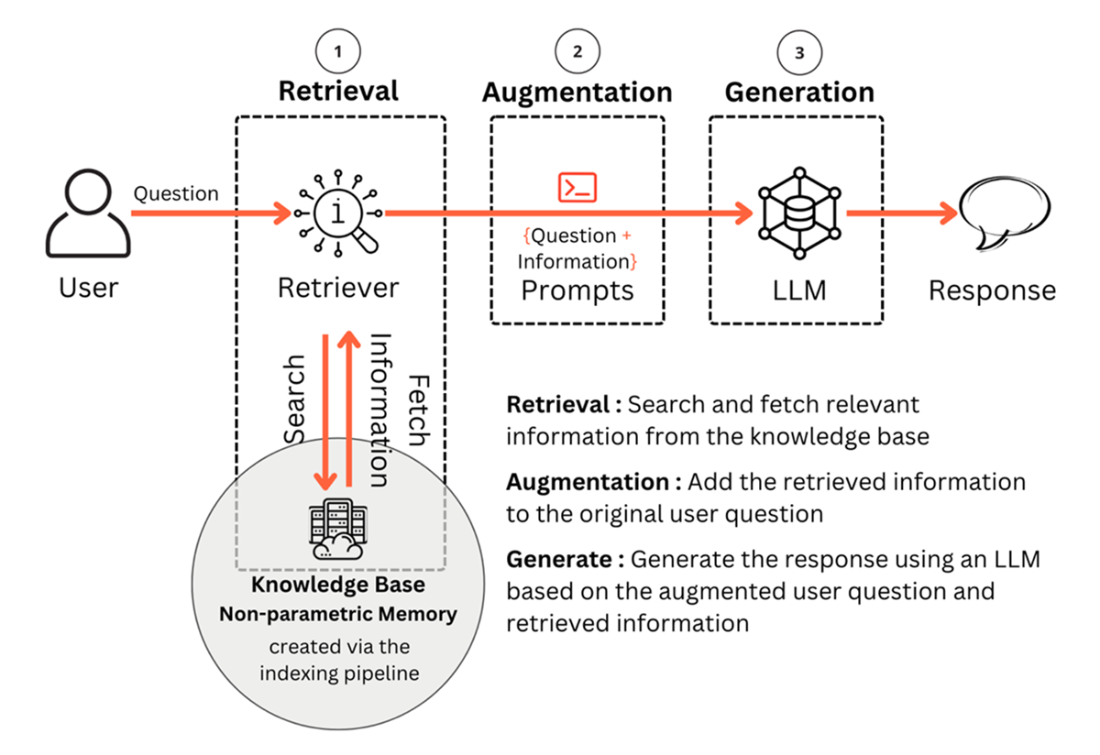
4 Generation Pipeline: Generating Contextual LLM Responses
This chapter explains how a Retrieval Augmented Generation (RAG) system turns a user query into a grounded answer by orchestrating three steps—retrieval, augmentation, and generation—on top of a knowledge base created in the indexing pipeline. It frames the generation pipeline as the bridge between stored non‑parametric knowledge and the LLM, emphasizing that the quality of each step compounds in the final response. Readers are guided from concepts to practice with a compact, end‑to‑end Python walkthrough so they can stand up a basic RAG system and understand the design choices that affect accuracy, cost, and reliability.
The chapter first focuses on retrieval, defining retrievers as components that search a vectorized knowledge base and return the most relevant documents to a query. It traces the evolution from classical IR (Boolean, Bag‑of‑Words, TF‑IDF) to stronger ranking with BM25, and then to embeddings-based search, contrasting static (Word2Vec, GloVe) with contextual embeddings (e.g., transformer-based). It highlights cosine similarity ranking, the tight coupling of indexing and retrieval, and practical options such as vector stores (FAISS, Pinecone, Milvus, Weaviate), cloud search services, and domain sources (e.g., Wikipedia, ArXiv). A simple retriever is implemented using OpenAI embeddings with FAISS similarity search, underscoring that retriever quality largely determines downstream answer quality and that hybrid and reranking strategies are common in production.
Next, augmentation is presented as prompt engineering that fuses the user query with retrieved context, starting with contextual prompting and controlled generation (instructing the model to say “I don’t know” when context is insufficient). It then introduces few‑shot examples for format and style, Chain‑of‑Thought for reasoning, and points to advanced techniques such as self‑consistency, Tree‑of‑Thoughts, and tool‑assisted prompting. The generation section frames model choice for RAG across foundation versus fine‑tuned models, open‑source versus proprietary options, and small versus large model trade‑offs (customization, cost, deployment, reasoning, and context length). The chapter closes by completing the pipeline—feeding the augmented prompt to an LLM (e.g., GPT‑4‑class model)—and reiterating that, with the indexing and generation pipelines in place, readers can build a working RAG system, while recognizing that rigorous evaluation and advanced strategies further improve robustness and fidelity.
Generation Pipeline Overview with the three components i.e. retrieval, augmentation and generation
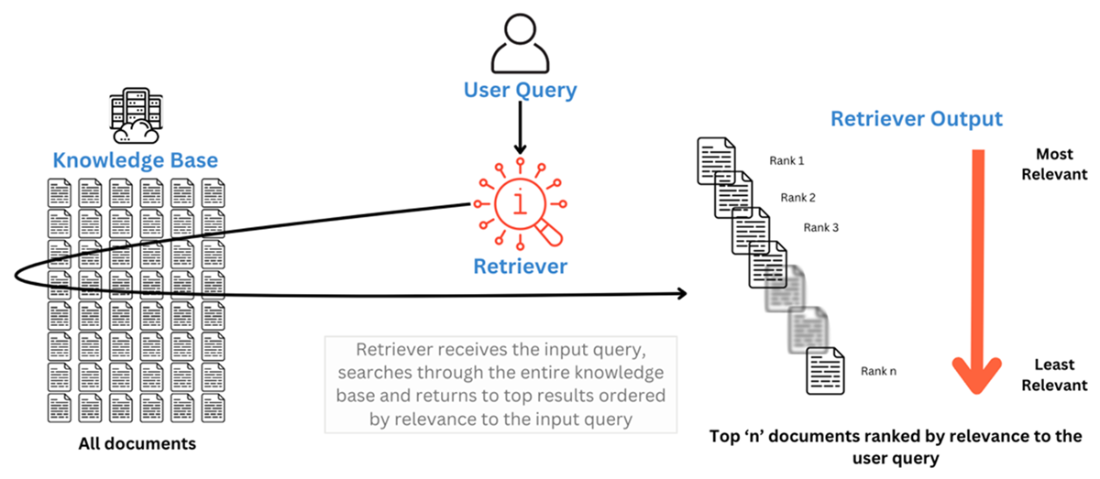
A Retriever searches through the knowledge base and returns the most relevant documents
Calculating TF-IDF to rank documents based on search terms

BM25 also considers the length of the documents

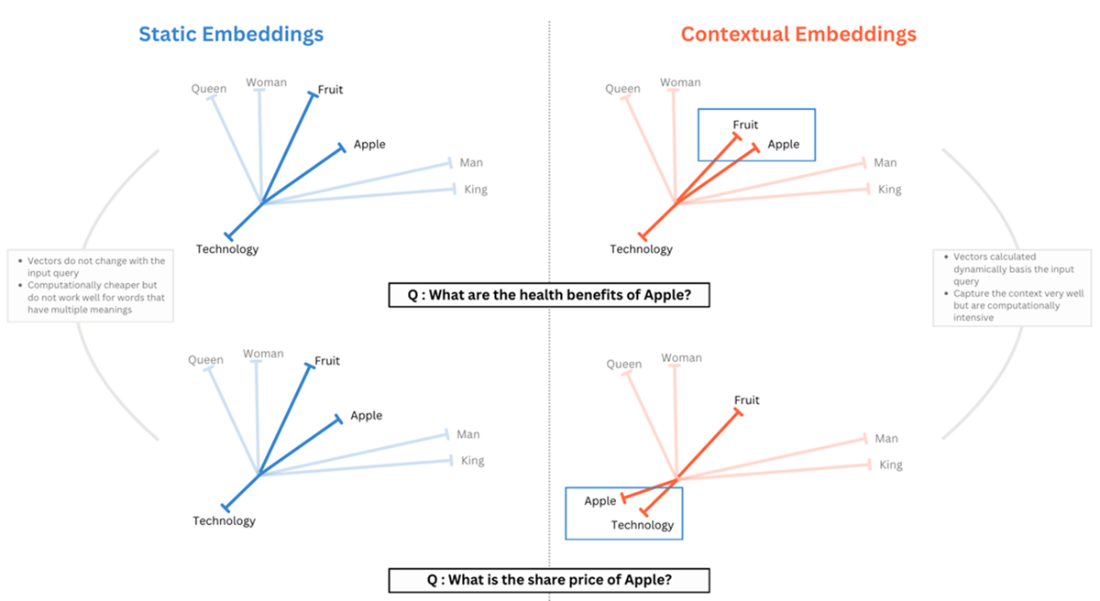
Static Embeddings vs Contextual Embeddings
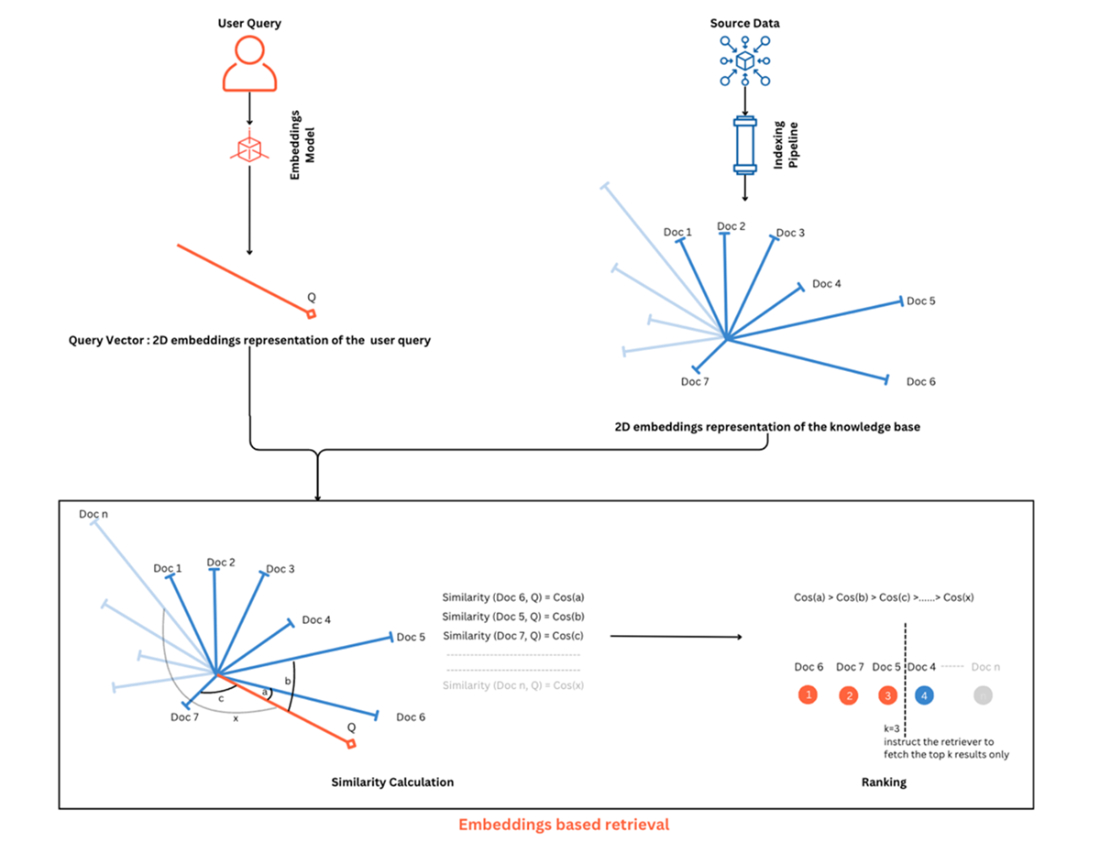
Similarity calculation and results ranking in embeddings-based retrieval technique
Simple augmentation combines the user query with retrieved documents to send to the LLM
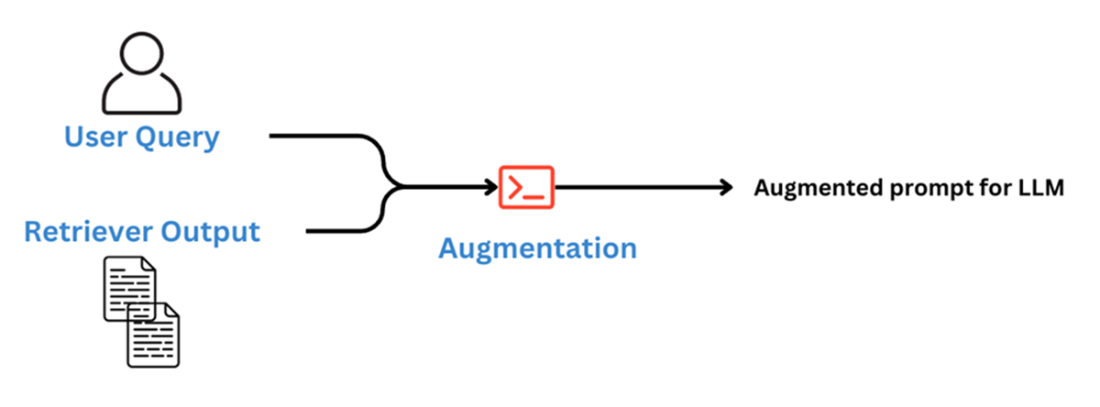
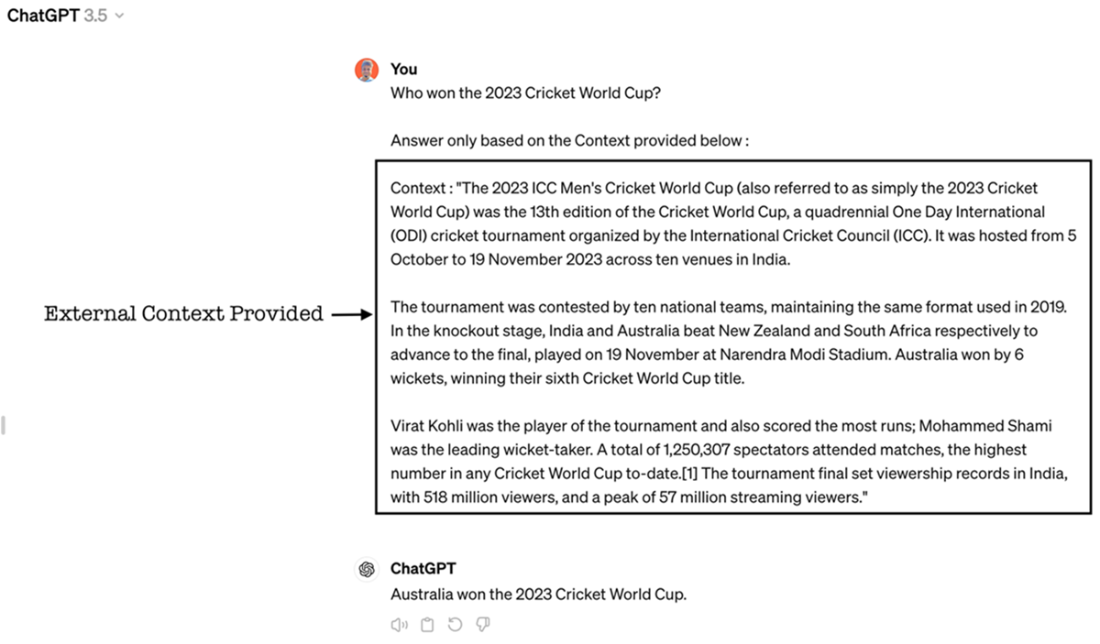
Information augmented to the original question with an added instruction
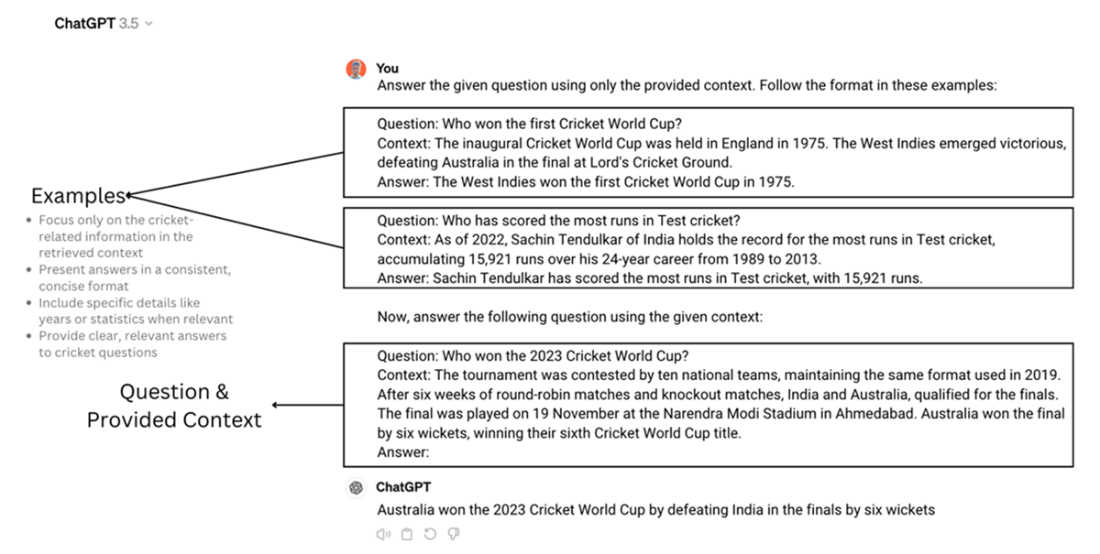
Example of Few Shot Prompting in the context of RAG
Chain-of-Thought (CoT) prompting for reasoning tasks

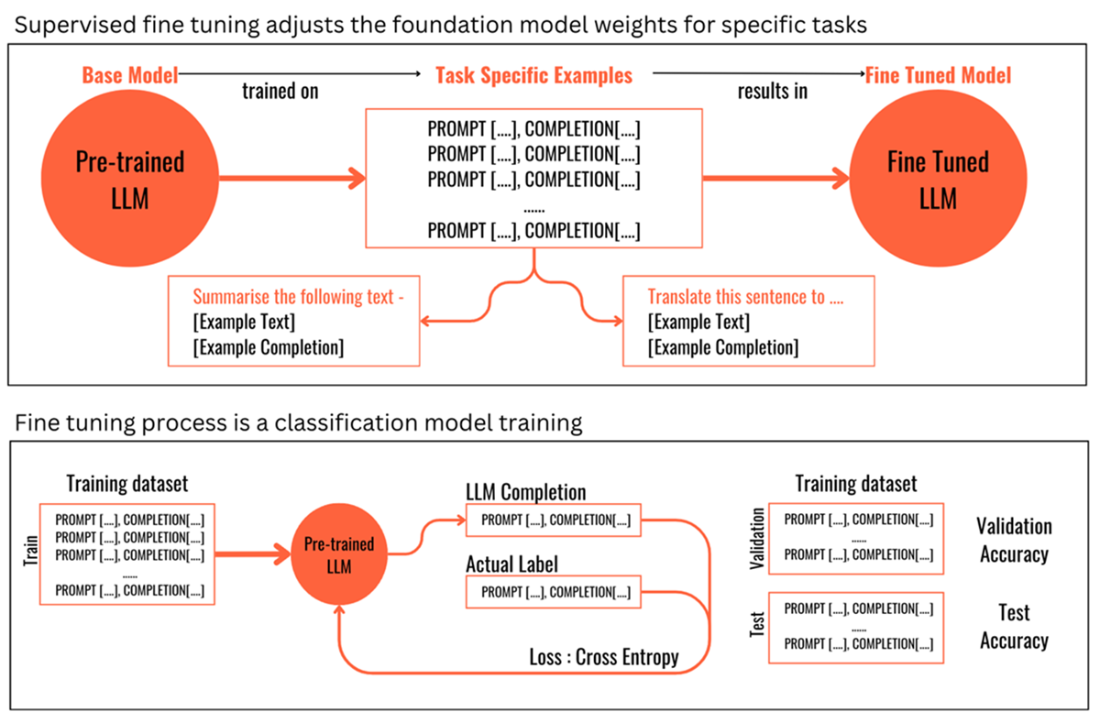
Supervised fine tuning is a classification model training process
 A Simple Guide to Retrieval Augmented Generation ebook for free
A Simple Guide to Retrieval Augmented Generation ebook for free