Appendix C. Qwen3 LLM source code
This appendix presents the concise, readable source code for the Qwen3 model used throughout the book, clarifying that “from scratch” refers to the reasoning methods rather than building an LLM end to end. The implementation mirrors a GPT-2–style, decoder-only transformer while adopting modern architectural updates common in contemporary LLMs. Instead of a step-by-step deep dive, the appendix offers a guided overview that connects design choices to code, so readers can see how the major components fit together and reuse the model via the reasoning_from_scratch package.
Key updates over a classic GPT-2 include RMSNorm in place of LayerNorm for lower cost and stable training, and a SwiGLU (SiLU-activated GLU) feed-forward that improves expressivity while often using fewer parameters than the standard two-layer MLP. Positional information is injected with rotary position embeddings (RoPE), implemented in a clear “two-halves” style that rotates query and key vectors. Attention uses grouped query attention (GQA), which shares keys and values across groups of query heads to reduce parameters and KV-cache bandwidth without hurting quality; Qwen3 additionally applies optional QK normalization (RMSNorm on queries/keys) to further steady optimization. KV-cache support is integrated so generation can be accelerated in streaming or incremental decoding scenarios.
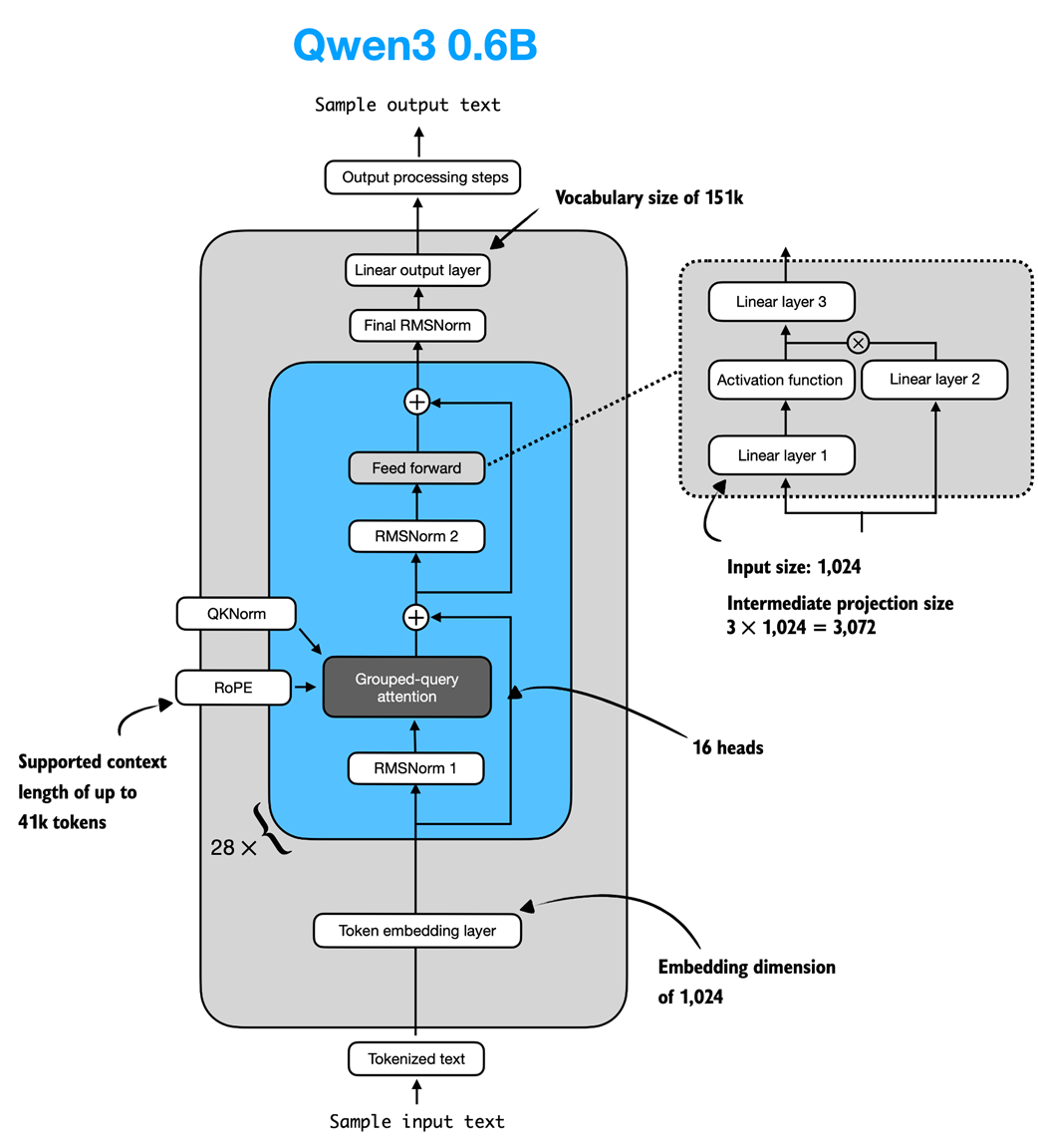
The transformer block combines RMSNorm, RoPE-applied masked GQA, and the SwiGLU feed-forward module with residual connections, and is stacked repeatedly (28 times in the 0.6B variant). The Qwen3Model wraps these blocks with token embeddings, a final RMSNorm, and an output projection, and precomputes RoPE buffers while managing cache-aware causal masks; a small KVCache utility holds per-layer keys and values during generation. A flexible configuration system supports multiple sizes; the 0.6B setup uses 1024-dimensional embeddings, 16 heads with 128 head dimension, 28 layers, a 3072-wide intermediate, 8 KV groups, a large vocabulary, and a long context window. The tokenizer reimplementation mirrors the official behavior, handling numerous special and chat tokens and a hybrid “thinking” mode with intentionally nuanced prompt rules, enabling consistent formatting for both standard and reasoning-style interactions.
Figure C.1 Architectural comparison between Qwen3 and GPT-2. Both models process text through embedding layers and stacked transformer blocks, but they differ in certain design choices.
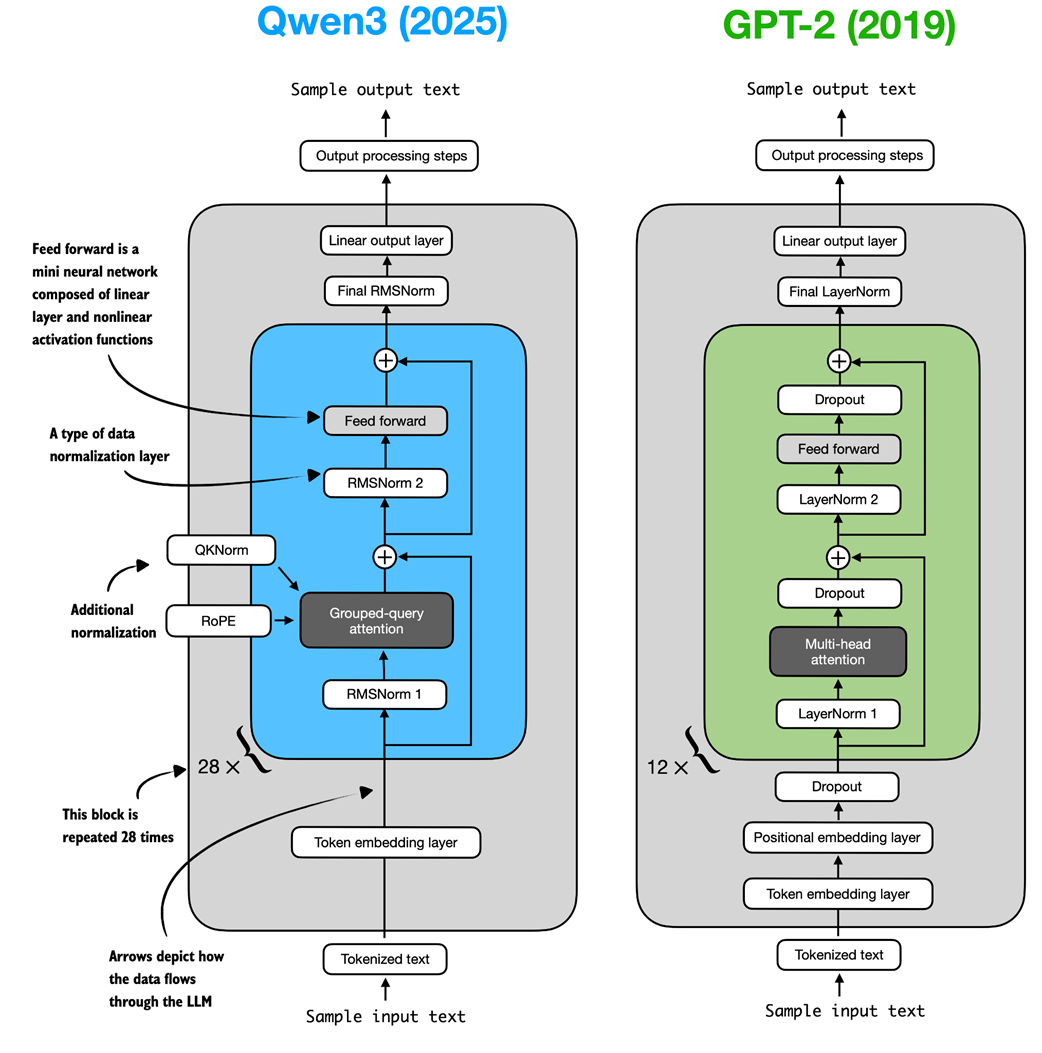
Figure C.2 Comparison of LayerNorm (used in GPT-2) and RMSNorm (used in Qwen3). LayerNorm (left) normalizes activations so that their average value (mean) is exactly zero and their spread (variance) is exactly one. RMSNorm (right) instead scales activations based on their root mean square, which does not enforce zero mean or unit variance, but still keeps the mean and variance within a reasonable range for stable training.
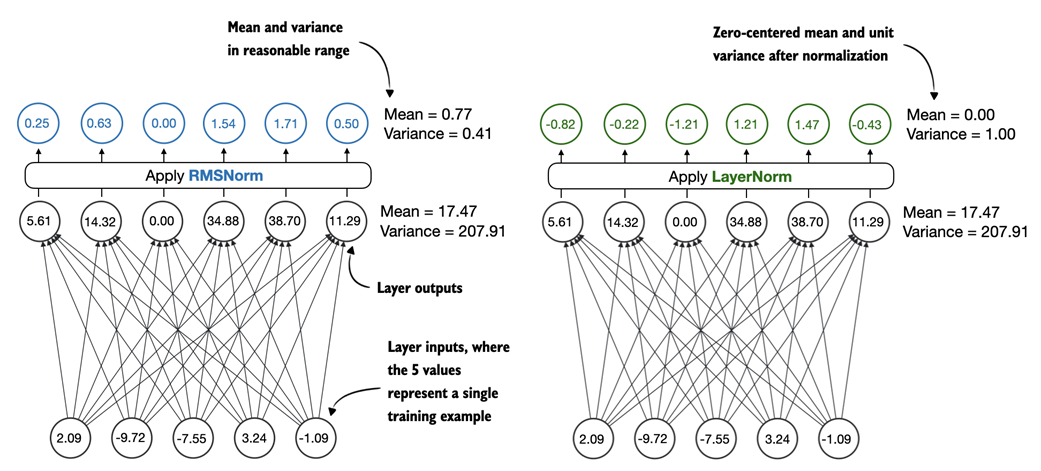
Figure C.3 In GPT-2 (top), the feed forward module consists of two fully connected (linear) layers separated by a non-linear activation function. In Qwen3 (bottom), this module is a gated linear unit (GLU) variant, which adds a third linear layer (linear layer 3) and multiplies the output of this linear layer 3 elementwise with the activated output of linear layer 1.
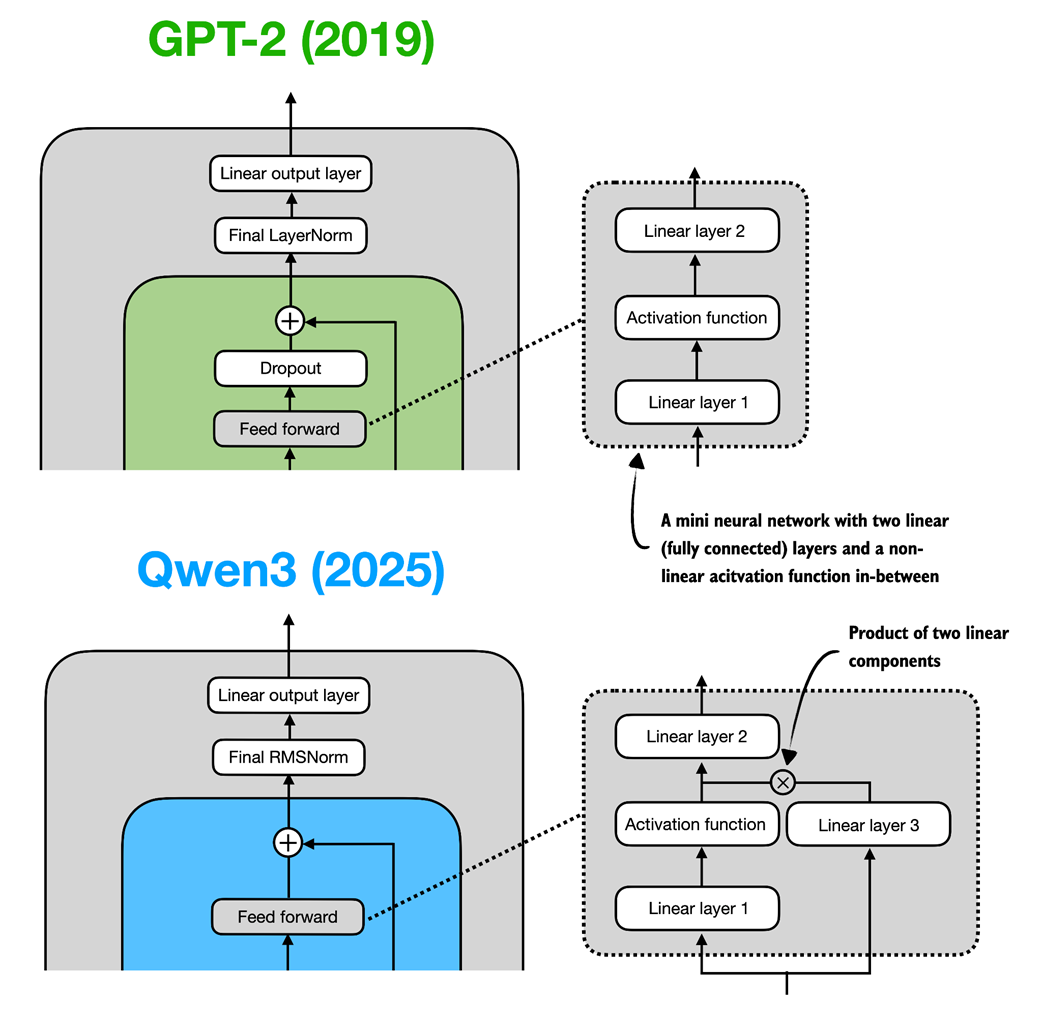
Figure C.4 Different activation functions that can be used in a feed forward module (neural network). GELU and SiLU (Swish) offer smooth alternatives to ReLU, which has a sharp kink at input zero.
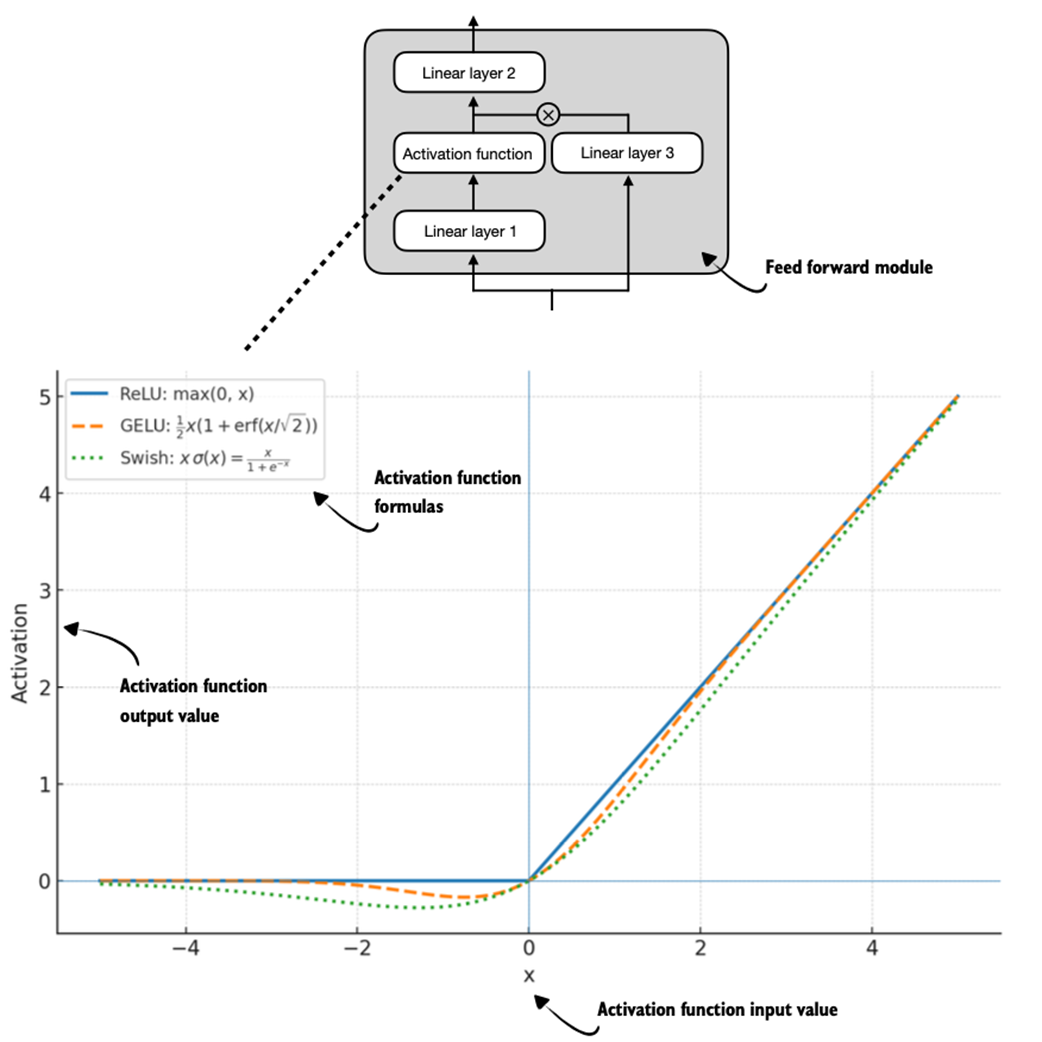
Figure C.5 A comparison between MHA and GQA. Here, the group size is 2, where a key and value pair is shared among 2 queries.
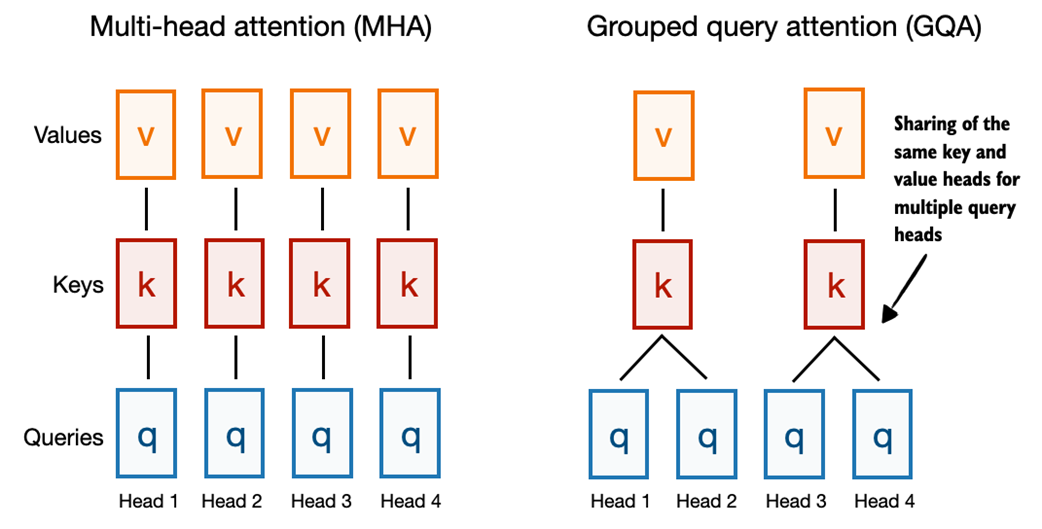
Figure C.6 The Structure of the transformer block in Qwen3. Each block includes RMSNorm, RoPE, masked grouped-query attention, and a feed-forward module, and is repeated 28 times in the 0.6B-parameter model.
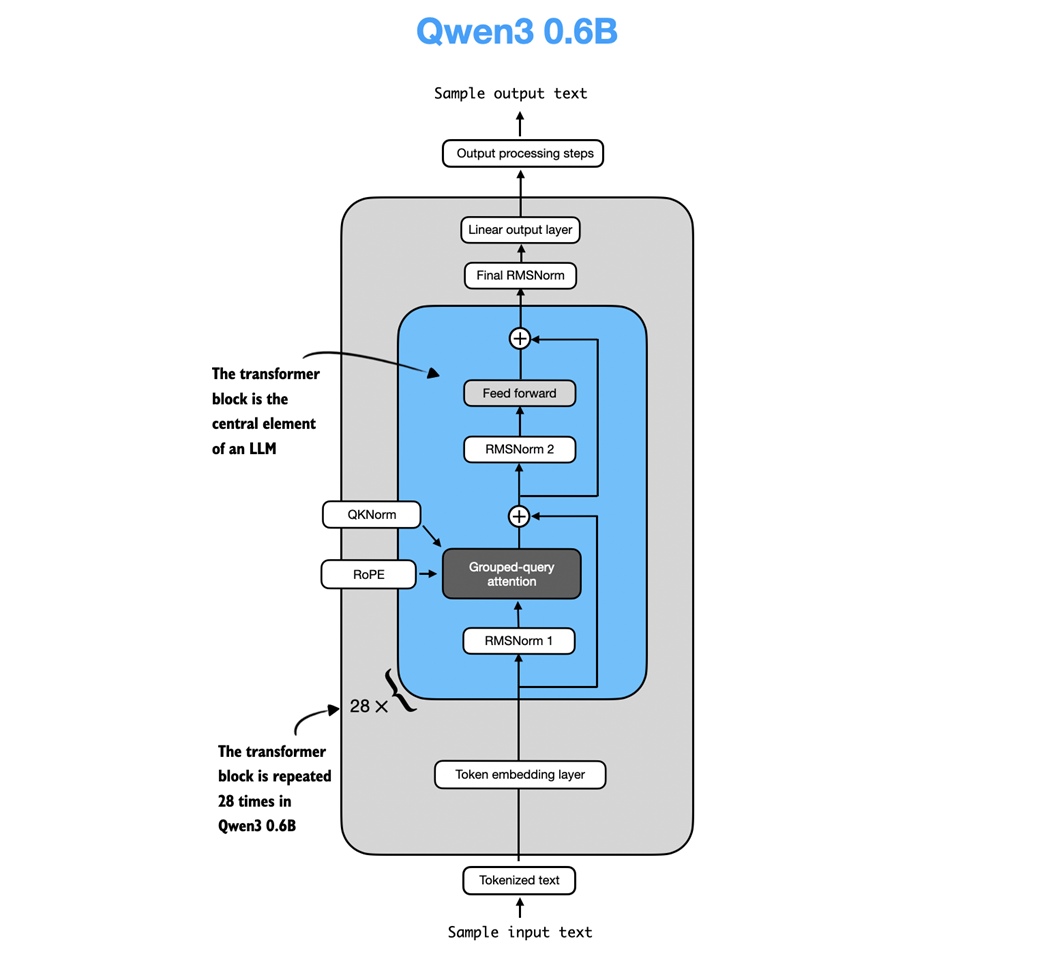
Figure C.7 Architecture of the Qwen3 0.6B model. The model consists of a token embedding layer followed by 28 transformer blocks, each containing RMSNorm, RoPE, QKNorm, masked grouped-query attention with 16 heads, and a feed-forward module with an intermediate size of 3,072.
C.9 Using the model
Let's now instantiate and use the model to confirm that the code works by reusing the text generation approach from chapter 2.
First, we instantiate the model using the pre-trained model weights:
The output shows the structure of the instantiated model, which should match the values we used in the configuration file in listing C.7:
Next, we re-use the text generation functions from chapter 2 to generate text:
Since we used the same prompt as in chapter 2, the generated text matches the generated text from chapter 2 exactly:
While the main chapters use the 0.6-billion-parameter variant of Qwen3 to lower the resource requirements for this book, interested readers can find more information on how to use the larger models in appendix D.
 Build a Reasoning Model (From Scratch) ebook for free
Build a Reasoning Model (From Scratch) ebook for free